




点击关注上方“知了小巷”,
设为“置顶或星标”,第一时间送达干货。
前文回顾:
前文已经学习到如何保障数据中台的数据质量,让数据做到“准确”。除了“快”和“准”,数据中台还离不开“省”,要考虑成本。特别是随着数据规模越来越大,投入的成本会越来越高,如果不能合理控制成本,可能数据的应用价值还没被挖掘出来,企业的利润就已经被消耗完了(夸张了)。
所以,能否做到精细化的成本管理,关乎数据中台项⽬的成败。
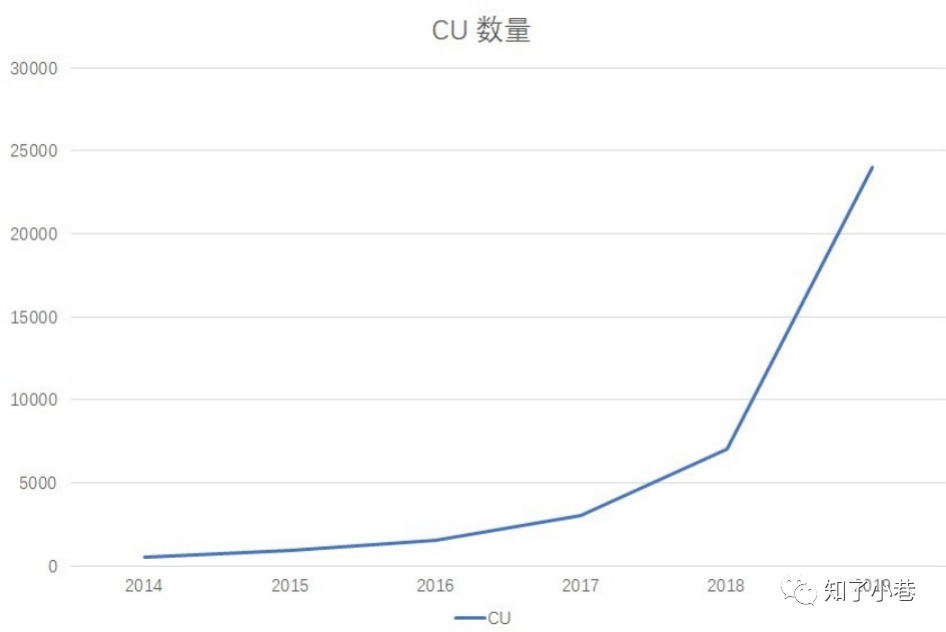
这张图展⽰了某电商平台的⼤数据资源消耗增⻓趋势,尤其值得关注的是,到了2019年,全年的资源规模已经达到了25000CU,全年机器预算达到了3500W。对⼀个在创业的企业来说,这显然是⼀笔不⼩的开⽀。
终于有⼀天,数据团队的负责⼈李好看(化名)就被CEO叫到了办公室,CEO问了⼏个问题:
1. 这3500W花在什么业务上?
2. 你们做了哪些成本优化的举措,效果如何?
⼀系列的灵魂拷问,直接把李好看问懵了,他⼼想:团队的成本是按机器⼜不是数据应⽤核算的。在数据中 台中,数据应⽤之间的底层数据是复⽤的,那具体每个数据产品或者报表花了多少钱,⾃⼰没有这样的数据 啊,怎么可能知道。
可对CEO来说,这些问题很重要,因为资源总是有限的,他必须确保资源都⽤在战略⽬标的关键节点上。⽐如,对于电商团队,今年的核⼼KPI是提升单个注册会员在平台的消费额,那从⽼板⻆度来讲,他必须确保资源都投⼊与KPI相关业务中,例如基于数据对注册会员进⾏精准化营销,来提升会员在平台的消费额。
数据部⻔是企业的成本中⼼,如果要展现⾃⼰的价值,⼀⽅⾯是⽀撑好业务,获得业务的认可;另外⼀⽅⾯就是精简成本,为公司省钱。
数据中台的精细化成本管理
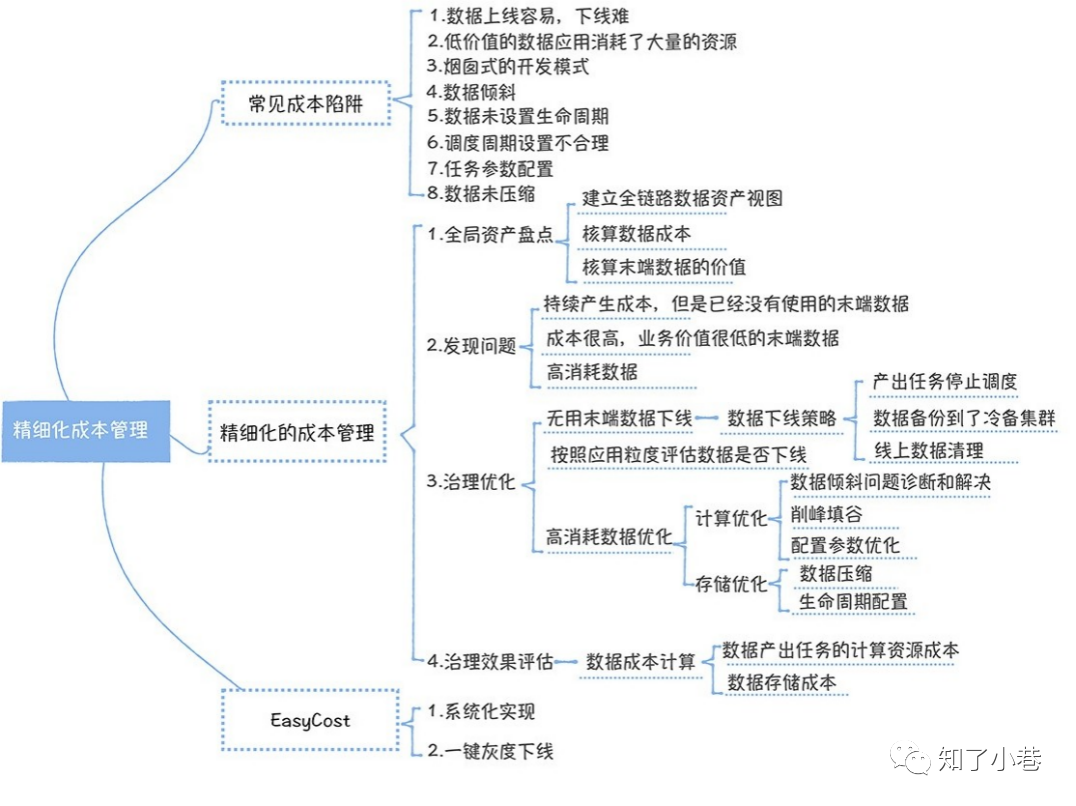
</> 有哪些成本的陷阱?
在⼀开始建设数据中台时,往往会关注新业务的接⼊,数据的整合,数据价值的挖掘上,忽略成本管控的问题,从⽽落⼊陷阱中,造成成本爆炸式的增⻓。所以,有必要深⼊了解⼀下有哪些陷阱,从⽽尽量在⽇常开发中避免。
这里总结了8种陷阱,其中:
1~3是⼴泛存在,但是容易被忽略的,需要格外注意;
4~8涉及数据开发中⼀些技能,在开发过程中注意⼀下就可以了。
第⼀,数据上线容易下线难。
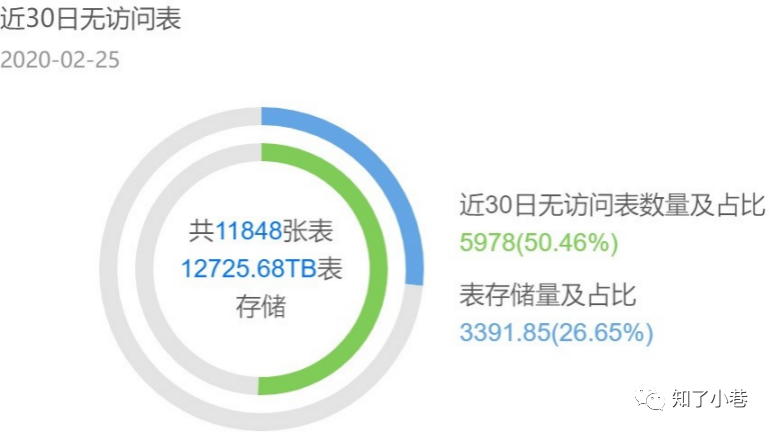
先看⼀组统计数据,这是某数据中台项⽬,表相关的使⽤统计。从中可以发现,有⼀半的表在30天内都没有访问,⽽这些表占⽤了26%的存储空间。如果我们把这些表的产出任务单独拎出来,在⾼峰期需要消耗5000Core CPU的计算资源,换算成服务器需要125台(按照⼀台服务器可分配CPU 40Core计算),折合成本⼀年接近500W。
是不是觉得⾃⼰竟然有这么多没⽤的数据?可以把数据⽐作⼿机中的图⽚,我们总是不断地拍照,⽣成图⽚,却懒得清理,最终⼿机⾥⾯的存储经常不够⽤(深有感触)。
对于⽆法及时清理数据,数据开发其实也有苦衷。小伙伴通常并不知道⼀个表还有哪些任务在引⽤,还有哪些⼈在查询,⾃然不敢停⽌这个表的数据加⼯,这样造成的后果就是数据上线容易,下线难。
第⼆,低价值的数据应⽤消耗了⼤量的资源。
我们的数据看上去每天都在被访问,但究竟产出了多少价值,投⼊和产出是否匹配呢?作为⼀个数据部⻔,我们要问⼀问⾃⼰。
我们曾经有⼀个宽表(拥有很多列的表,经常出现在数据中台下游的汇总层数据中),算上上游加⼯链路的任务,每天加⼯这张宽表要消耗6000块钱,⼀年要200W,可追查后我们发现,这张宽表实际每天只有⼀个⼈在使⽤,还是⼀个运营的实习⽣。显然,投⼊和产出极不匹配。
这其实间接说明,数据部⻔⽐较关注新的数据产品带给业务的价值,却忽略了已经存在的产品或者报表是否还存在价值,最终导致低价值的应⽤仍然在⼤量消耗资源。
第三,烟囱式的开发模式。
烟囱式的开发不仅会带来研发效率低的问题,同时因为数据重复加⼯,还会存在资源浪费的问题。我们来算⼀笔账,⼀张500T的表,加⼯这张表,计算任务需要⾼峰期消耗300Core,折合7台服务器(按照⼀台服务器可分配CPU 40Core计算),再加上存储盘的成本(按照0.7 元/TB*天计算),⼀年需要消耗40W。
⽽这张表每复⽤⼀次,就可以节省40W的成本。所以通过模型复⽤,还可以实现省钱的⽬的。
第四,数据倾斜。
数据倾斜会让任务性能变差,也会浪费⼤量的资源,那什么是数据倾斜呢?
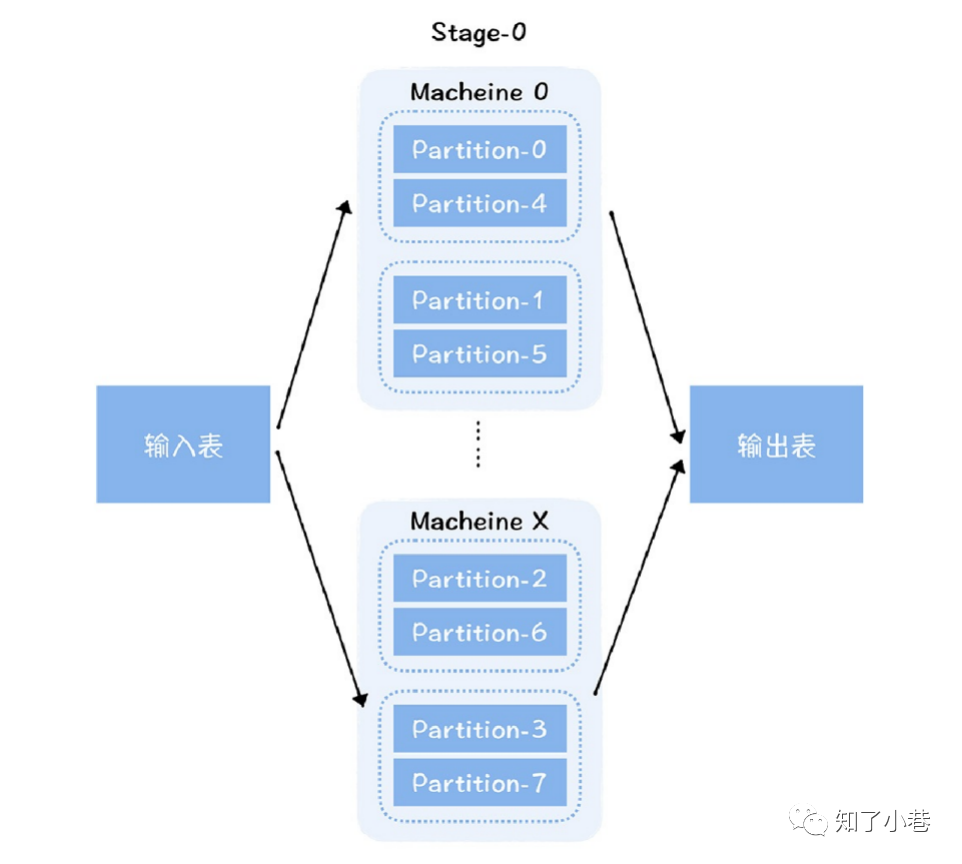
众所周知的⽊桶效应,⼀个⽊桶装多少⽔,主要取决于最短的那块板。对于⼀个分布式并⾏计算框架来说,这个效应同样存在。对于Spark计算引擎来说,它可以将海量的数据切分成不同的分⽚(Partition),分配到不同机器运⾏的任务中,进⾏并⾏计算,从⽽实现计算能⼒⽔平扩展。
但是整个任务的运⾏时⻓,其实取决于运⾏最⻓的那个任务。因为每个分⽚的数据量可能不同,每个任务需要的资源也不相同。由于不同的任务不能分配不同的资源,所以,总任务消耗资源=max{单个任务消耗的资源} * 任务数量。这样⼀来,数据量⼩的任务会消耗更多的资源,就会造成资源的浪费。
举个电商场景的例⼦。
假设我们需要按照商⼾粒度统计每个商⼾的交易⾦额,此时,我们需要对订单流⽔表按照商⼾进⾏group by计算。在平台上,每个商⼾的订单交易量实际差距很⼤,有的订单交易量很多,有的却⽐较少。

利⽤Spark SQL完成计算过程。

在上图中,任务A 读取了左边某个分⽚的数据,按照供应商进⾏聚合,然后输出给下⼀个Stage的B、C、D 任务。
可以看到,聚合后,B、C和D任务输⼊的数据量有很⼤的不同,B处理的数据量⽐C和D多,消耗的内存⾃然更多,假设单个Executor需要分配16G,⽽B、C、D不能设置不同的内存⼤⼩,所以C和D也都设置了16G。可实际上,按照C和D的数据量,只需要4G就够了。这就造成了C和D 任务资源分配的浪费。
第五,数据未设置⽣命周期。
⼀般原始数据和明细数据,会保留完整的历史数据。⽽在汇总层、集市层或者应⽤层, 考虑到存储成本,数据建议按照⽣命周期来管理,通常保留⼏天的快照或者分区。如果存在⼤表没有设置⽣命周期,就会浪费存储资源。
第六,调度周期不合理。
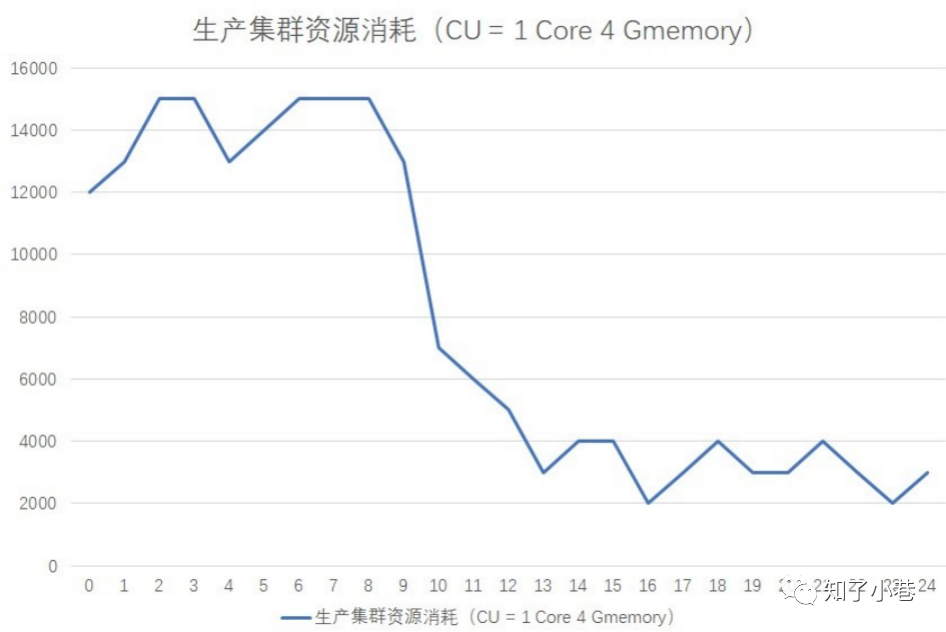
通过这张图可以看到,⼤数据任务的资源消耗有很明显的⾼峰和低⾕效应,⼀般晚上12点到第⼆天的9点是⾼峰期,9点到晚上12点,是低⾕期。
虽然任务有明显的⾼峰低⾕效应,但是服务器资源不是弹性的,所以就会出现服务器在低⾕期⽐较空闲,在⾼峰期⽐较繁忙的情况,整个集群的资源配置取决于⾼峰期的任务消耗。所以,把⼀些不必要在⾼峰期内运⾏任务迁移到低⾕期运⾏,也可以节省资源的消耗。
第七,任务参数配置。
任务参数配置的不合理,往往也会浪费资源。⽐如在Spark中,Executor内存设置的过⼤;CPU设置的过多;还有Spark没有开启动态资源分配策略,⼀些已经运⾏完Task的Executor不能释放,持续占⽤资源,尤其是遇到数据倾斜的情况,资源浪费会更加明显。
第⼋,数据未压缩。
Hadoop的HDFS 为了实现⾼可⽤,默认数据存储3副本,所以⼤数据的物理存储量消耗是⽐较⼤的。尤其是对于⼀些原始数据层和明细数据层的⼤表,动辄500多T,折合物理存储需要1.5P(三副本,所以实际物理存储5003),⼤约需要16台物理服务器(⼀台服务器可分配存储按照128T计算),如果不启⽤压缩,存储资源成本会很⾼。
另外,在Hive或者Spark计算过程中,中间结果也需要压缩,可以降低⽹络传输量,提⾼Shuffle(在Hive或者Spark计算过程中,数据在不同节点之间的传输过程)性能。
</> 如何实现精细化成本管理?
成本治理应该遵循全局盘点、发现问题、治理优化和效果评估四个步骤。
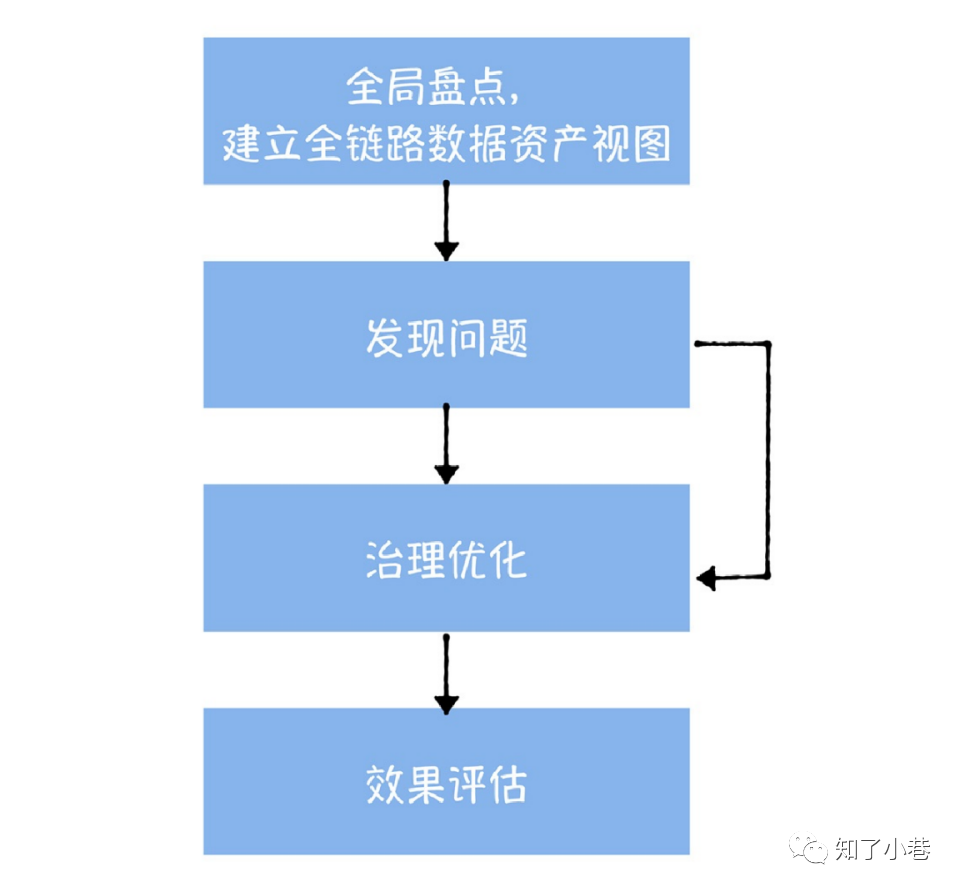
全局资产盘点
精细化成本管理的第⼀步,就是要对数据中台中,所有的数据进⾏⼀次全⾯盘点,基于元数据中⼼提供的数据⾎缘,建⽴全链路的数据资产视图。
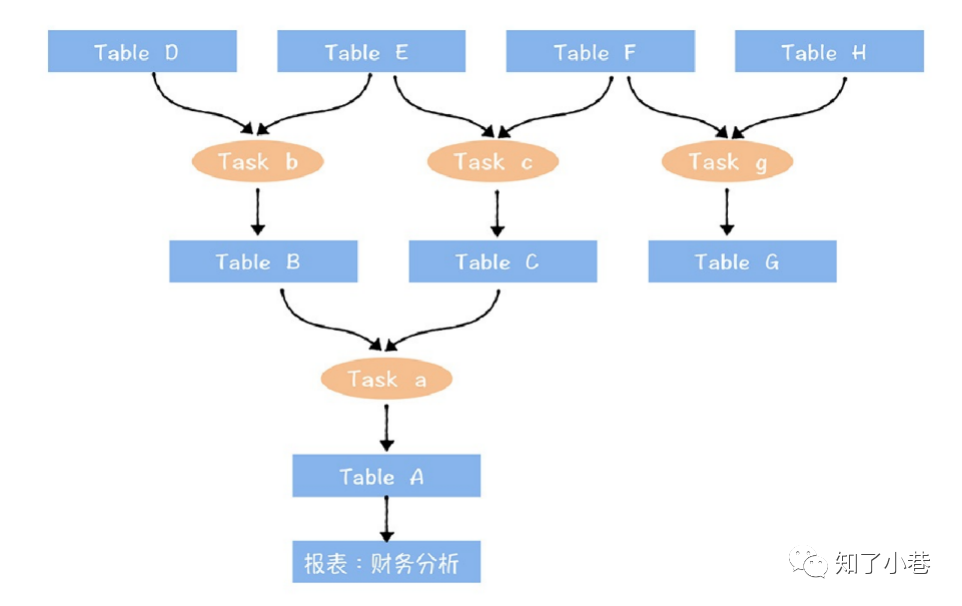
从这个图中可以看到,全链路数据资产视图的下游末端关联到了数据应⽤(报表:财务分析),⽽上游的起点是刚进⼊数据中台的原始数据。数据之间通过任务进⾏连接。
接下来,我们要计算全链路数据资产视图中,末端数据的成本和价值(末端数据就是加⼯链路最下游的表,例如图中TableA,Table G)。
为什么⼀定要从末端开始呢?因为中间数据,在计算价值的时候,还要考虑下游表被使⽤的情况,⽐较难计算清楚,所以选择从末端数据开始。这与下线表的顺序也是⼀致的,如果数据的价值很低,成本很⾼,也是从末端数据开始下线的。
数据成本如何计算?
要对上图中财务分析报表核算成本,这个报表上游链路中涉及到a,b,c,3个任务,A,B,C,D, E,F, 6张表,那么:
这张报表的成本=3个任务加⼯消耗的计算资源成本+6张表消耗的存储资源的成本。
另外,需要注意的是,如果⼀个表被多个下游应⽤复⽤,那这个表的存储资源成本以及产出任务消耗的成本,需要分摊给多个应⽤。
价值如何计算?
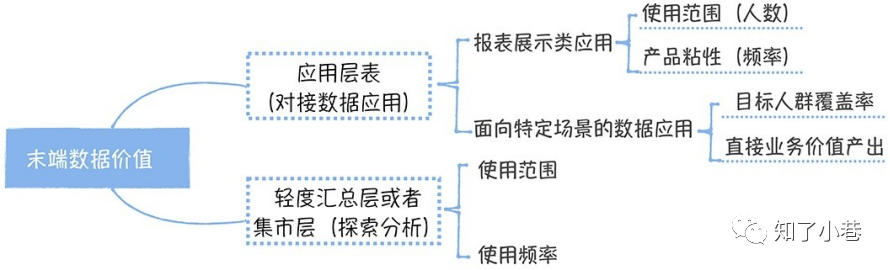
如果末端数据是⼀张应⽤层的表,它对接的是⼀个数据报表,那衡量这个数据的价值,主要是看报表的使⽤范围和使⽤频率。在计算使⽤范围时,通常⽤周活来评估,同时还要考虑不同管理级别的⼈权重,对于⽼板,他⼀个⼈的权重可以相当于1000个普通员⼯。
之所以这样设计,是考虑到管理级别越⾼,做出的商业决策影响就越⼤,⾃然这个价值也就越⼤。使⽤频率⼀般使⽤单个⽤⼾每周查看报表的次数来衡量,次数越⾼,说明报表价值越⼤。
如果末端数据对接的不是⼀个数据报表,⽽是⾯向特定场景的数据应⽤(⽐如之前提到过的供应链分析决策系统,它⾯向的⼈群主要是供应链部⻔)。衡量这类产品的价值,主要考虑⽬标⼈群的覆盖率和直接业务价值产出。什么是直接业务价值产出呢?在供应链决策系统中,就是通过系统⾃动⽣成的采购订单占所有采购订单的⽐例。
除此之外,末端数据,可能还是⼀张集市层的表,它主要⽤于提供给分析师做探索式查询。这类表的价值主要看它被哪些分析师使⽤,使⽤频率如何。同样,在使⽤范围评估时,要对分析师按照级别进⾏加权。
</> 发现问题
全局盘点,为我们发现问题提供了数据⽀撑,需要重点关注下⾯三类问题:
1. 持续产⽣成本,但是已经没有使⽤的末端数据(“没有使⽤”⼀般指30天内没有访问);
2. 数据应⽤价值很低,成本却很⾼,这些数据应⽤上游链路上的所有相关数据;
3. ⾼峰期⾼消耗的数据。
为什么要关注这三类数据呢?
其实第⼀类就是没有使⽤,但⼀直在消耗成本的表,对应的就是上面提到的陷阱1。
第⼆类其实就是低价值产出,⾼成本的数据应⽤,对应的是陷阱2。
第三类⾼成本的数据,对应的就是陷阱4〜8。

陷阱3实际是在《数据模型无法复用,归根结底还是设计问题》模型设计中解决的。
</> 治理优化
针对这三类问题,需要制订相应的策略。
对于第⼀类问题,应该对表进⾏下线。 数据下线要谨慎,可以参考下面这张数据下线的执⾏过程图:

末端数据删除后,原先末端数据的上游数据会成为新的末端数据,同样还要按发现问题到治理优化进⾏重复,直到所有的末端数据都不满⾜下线策略为⽌。
对第⼆类问题,需要按照应⽤粒度评估应⽤是否还有存在的必要。对于报表,可以按照30天内没有访问的应⽤⾃动下线的策略,先对报表进⾏销毁,然后对报表上游的表进⾏下线,如果该表还被其他的应⽤引⽤,就不能下线。下线步骤可以参考前⾯的下线步骤。
第三类问题,主要是针对⾼消耗的数据,⼜具体分为产出数据的任务⾼消耗和数据存储⾼消耗。对于产出任务⾼消耗,⾸先要考虑是不是数据倾斜。具体怎么判断呢?可以通过MR或者Spark⽇志中,Shuffle的数据量进⾏判断。如果有某⼀个Task数据量⾮常⼤,其他的很少,就可以判定出现了数据倾斜。

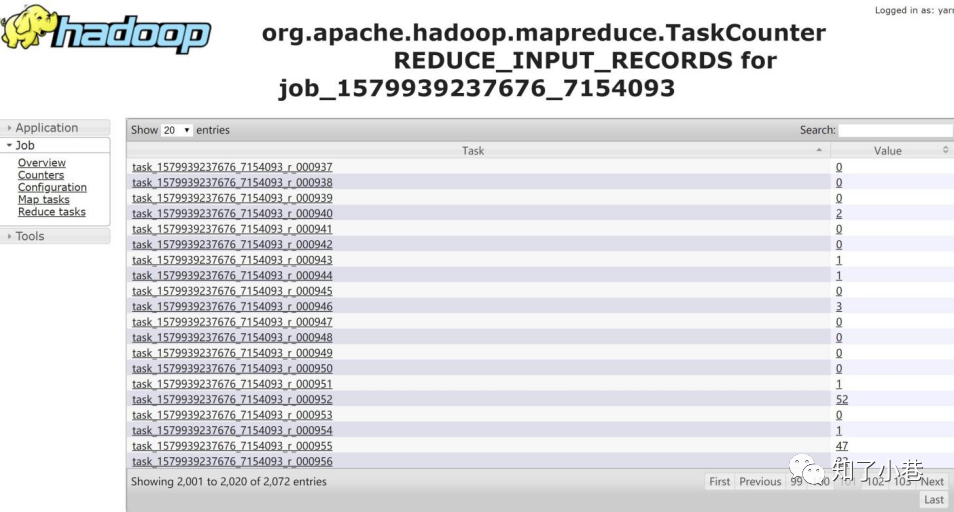
如果出现数据倾斜,该如何处理?
数据倾斜的处理⽅法有很多,不同的场景有⼀些适⽤的解决⽅案:⽐如在⼀些⼤表和⼩表关联时,Key分布不均造成的数据倾斜,可以使⽤mapjoin的⽅式解决;另外还有⼀些⽐较通⽤的处理⽅式,例如把热点的Key进⾏单独的处理,然后对剩下的Key进⾏处理,然后对结果进⾏并集。
除了数据倾斜,还应该检查任务的配置参数。例如对于Spark执⾏引擎,Executor个数是否开的过⼤,executor-cores和executor-memory是否开的过多,利⽤率⽐较低。⼀般来说,executor-memorty设置为4G-8G为宜,executor-cores设置为2-4个为宜(这是实践过利⽤率最⾼的配置选项)。
另外,还要考虑任务是否真的有必要在⾼峰期执⾏,可以根据集群的负载情况,尽量将任务迁移到⾮⾼峰期执⾏,这个步骤称为“削峰填⾕”。
上⾯⼏点是产出任务⾼消耗的情况,那么对于存储消耗⽐较⼤的任务,⾸先要考虑是否要压缩,尤其是对于原始数据层和明细数据层,建议压缩,压缩的⽅式有这样⼏种:

整体来看,对于⼩⽂件的压缩,不考虑split,gzip⽐较合适;对于⼤⽂件,推荐使⽤lzo,⽀持split,在保证压缩效率的前提下,有着相对稳定的压缩⽐。
除此之外,还需要考虑⽣命周期是否设置:
1. 对于ODS原始数据层和DWD明细数据层,⽐较适合⽤永久保留的策略;
2. 对于⼀些商品、⽤⼾维表,可以考虑3年或者5年的保留策略。
整体上,底层表都是⻓期保留的。所以关注重点应该是汇总层以上的表(包括汇总层),⼀般可以根据数据的重要性,制订7天或1个⽉的保留策略。
</> 治理效果评估
现在,通过上述方法,已经能够节省⼤量的资源消耗,接下来是如何量化治理成果?
五个字:省了多少钱。不过,如果直接拿服务器的数量来衡量,其实并不能真实地反应治理效果,因为还要考虑业务增⻓的原因。业务不是停⽌不动的,所以可以围绕任务和数据的成本考虑这样⼏点:
1. 下线了多少任务和数据;
2. 这些任务每⽇消耗了多少资源;
3. 数据占⽤了多少存储空间。
拿这些资源来计算成本,这样就能够算出来省了多少钱。任务A 运⾏时⻓3个⼩时,在运⾏过程中,共消耗5384503 cpu*s,37007892 GB *s, 假设我们1个CU (1 cpu, 4g memeory)⼀年是1300元成本,折合每天为3.5元(计算公式为1300/365)。
不论是优化或者下线任务,只统计⾼峰时间段内,因为优化低峰时间,并不能实际节省资源。
⾼峰时间段为8个⼩时,那折合每秒的费⽤为0.00012153, 那该任务的费⽤为max{5384503*0.00012153, 37007892/4 * 0.00012153} = max{654, 1124} = 1124 。那下线这个任务后,就节省1124元,再加上表A占⽤的存储空间⼤⼩乘以每GB的成本,就可以得出数据表A下线节省的费⽤。
</> 成本治理中⼼
成本治理不是⼀劳永逸的⼯作,需要持之以恒,不断发现问题,然后治理优化,建⽴⻓久运⾏机制的前提是必须降低成本治理的⻔槛,下面是⽹易的成本治理的平台,EasyCost。
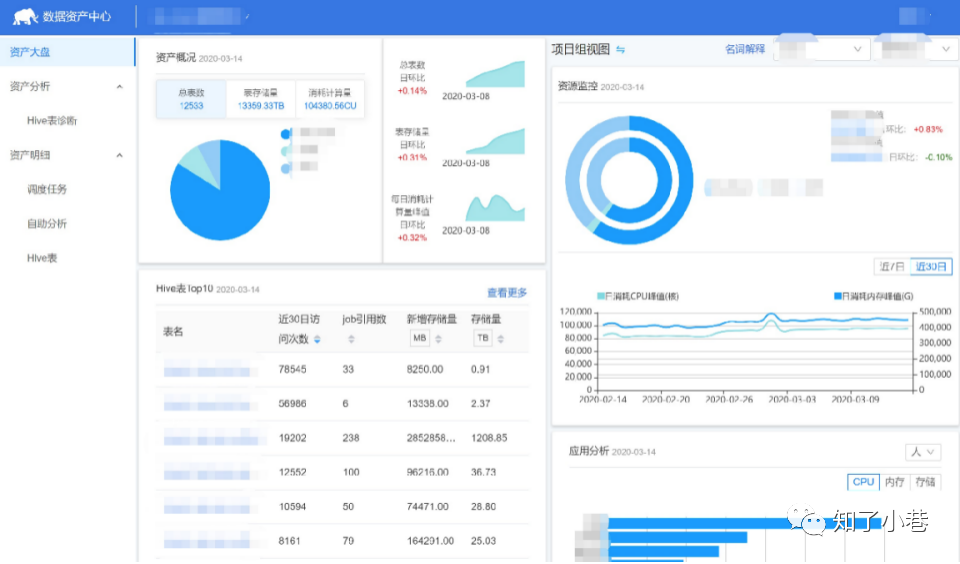
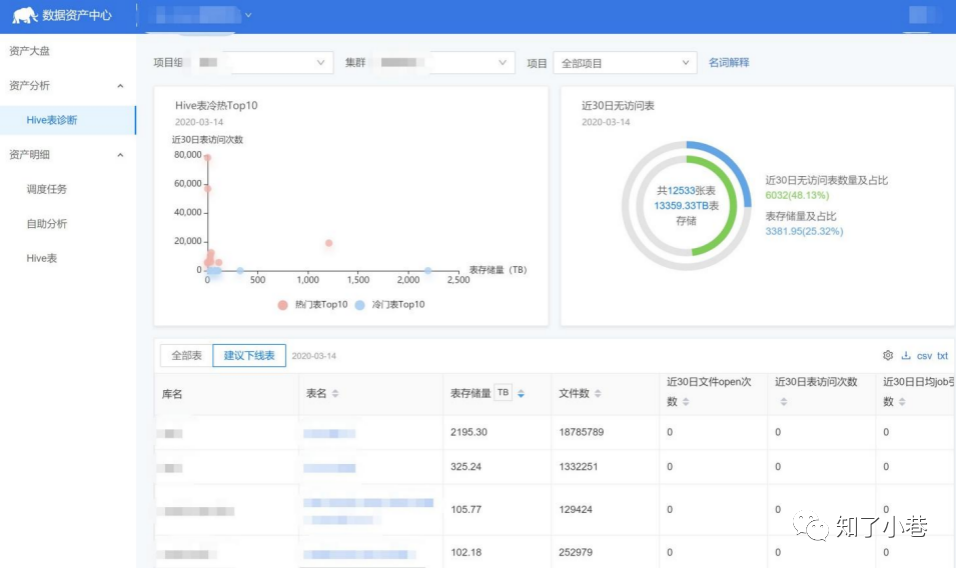
系统提供了数据诊断的功能,可以按照访问时间、访问频率、关联的应⽤,设置下线策略,⽀持⼀键灰度下线,⼤幅提⾼了管理的效率。
精细化成本管理,其实可以通过系统化的⽅式沉淀到产品中,然后通过产品提⾼管理的效率,从⽽实现治理机制的⻓久落地。
总结
总的来说,通过数据中台,⼀⽅⾯可以获得⼤数据作为资产中⼼带来的红利,另⼀⽅⾯,也有可能陷⼊成本的深渊,为野蛮增⻓的⼤数据费⽤买单。
⼏个可能忽略的点:
1. ⽆⽤数据的下线应该从全链路数据资产视图的末端⼊⼿,然后抽丝剥茧,⼀层⼀层,向数据加⼯链路的上游推进。
2. 应⽤层表的价值应该以数据应⽤的价值来衡量,对于低价值产出的应⽤,应该以应⽤为粒度进⾏下线。
3. 对⾼消耗任务的优化只要关注集群⾼峰期的任务,项⽬的整体资源消耗只取决于⾼峰期的任务消耗,当然,如果使⽤的是公有云的资源,可以⾼峰和低⾕实施差异化的成本结算,那低⾕期的也是要关注的。
思考
在数据中台的集市层,会存在⼀些⼤的宽表,这些宽表可能存在⼏百个字段,上游可能有数⼗个表,如果要 计算这个表的成本会⾮常⾼。在这个表中,字段的访问频率是不相同,有的字段频率很⾼,有的字段频率很 低,如果要对这张宽表做优化,如何来做?
根据字段访问频率和指标时效性,通常优化⼤宽表的思路有:
⼀、优化访问频率低并且时效性低的字段:对宽表的任务进⾏拆分,将这些字段拆出来⼀个或多个任务单 独跑,根据实际情况设置每个任务执⾏计划cron的频率。这些任务会⽣成临时表,保留最近的数据。在宽 表任务中进⾏字段合并union all,拆出来的字段就不需要再计算。
⼆、优化时效性⾼的字段,例如客流量越实时越好。同样拆出来单独任务跑数据,⽣成临时表,设置⾼频率任务执⾏计划,根据⼀致的维度,对宽表进⾏字段更新。
往期推荐:

