




点击关注上方“知了小巷”,
设为“置顶或星标”,第一时间送达干货。
前文回顾:
我要转型、我要建设数据中台,那到底咋做呢?对于“如何建设数据中台“这个问题,各方观点如下:
## 有的观点说,数据中台是⼀种数据建设的⽅法论,按照数据中台设计⽅法和规范实施就可以建成数据中台了;
## 也有观点认为,数据中台的背后是数据部⻔组织架构的变更,把原先分散的组织架构整合起来形成⼀个统⼀的中台部⻔,就建成了数据中台;
## 除此之外,有⼀些⼤数据公司可能会说,他们可以卖⽀撑数据中台建设的产品技术,甚至直接销售“数据中台”。
那数据中台到底如何建设呢?先看⼀个生活中盖房子的例⼦。
盖房⼦之前,是不是先得有设计图纸,知道如何去盖这个房⼦?然后还必须要有⼀个好⽤的⼯具(⽐如⽔泥搅拌机、钢筋切割机)帮我们盖好这个房⼦。当然了,盖房⼦离不开⼀个靠谱的施⼯队伍,这⾥⾯涉及很多⻆⾊(泥⽡⼯、⽊⼯、⽔电⼯等等),这些⼈必须⾼效协作,最终才能盖出⼀个好的房⼦。
如果我们把建数据中台⽐作是盖房⼦,那么设计图纸就是数据中台建设的⽅法论;⼯具是数据中台的⽀撑技术;施⼯队伍就是数据中台的组织架构。这三者缺⼀不可。
下面就以全局的视⻆,从宏观上了解如何建设⼀个企业级的数据中台。
# 数据中台建设⽅法论
早在2016年,阿⾥巴巴就提出了数据中台建设的核⼼⽅法论:OneData和OneService。经过这么多年,很多公司都进⾏了实践,但很难找出⼀个准确的定义去描述这些⽅法论,下面是结合⽹易数据中台建设的经验,对⽅法论进⾏了系统化的定义,值得借鉴参考。
OneData
⽤⼀句话定义OneData的话,就是所有数据只加⼯⼀次。这个概念具体是啥意思呢?我们来看⼀个例⼦。
例如基于业务系统-仓储管理系统(WMS)构建大数据平台。
对于供应链部门,从原始库存表==>库存明细表(清洗后)==>汇总商品粒度库存表==>商品库存。
对于仓储部门,从原始库存表==>库存明细表(清洗后)==>汇总商品粒度库存表==>商品库存。
不同部门链路相同。
电商业务建设数据中台之前,每个部⻔内部都会有⼀些⼩的数仓去完成本部⻔的数据分析需求。
有⼀天,供应链团队接到⼀个数据需求,那就是计算“商品库存”指标,供应链的运营需要根据每个商品的库存制订商品采购计划,部⻔的数据开发从业务系统同步数据,进⾏数据清洗、聚合、深度加⼯,最终,产出这个指标花了1周的时间。
⽽恰逢全年最重要的⼤促节⽇,市场部⻔也需要根据每个商品的库存,制订商品的促销计划。该数据开发接 到这个紧急的需求(与供应链团队类似)从需求开发到上线,也⾜⾜花费了1周的时间。同部⻔的运营会抱 怨说,为什么数据需求开发这么慢,根本⽆法满⾜⼤促期间⾼频的市场运营决策。⽽对公司⽽⾔,等待1周意味着遭受巨⼤损失,该促销的商品没有促销,不该促销的却低价卖了。
如果你是这个公司的⽼板,肯定会问,既然供应链团队已经计算出来了商品库存的数据,为什么市场部⻔不直接⽤,还要从头再计算⼀遍呢?这个看似很傻的⾏为,却处处出现在我们⽇常的数据建设中。
⽽数据中台就是要在整个电商业务形成⼀个公共数据层,消灭这些跨部⻔的⼩数仓,实现数据的复⽤,所以 强调数据只加⼯⼀次,不会因为不同的应⽤场景,不同的部⻔数据重复加⼯。
那具体来说,如何去做才能实现数据只加⼯⼀次呢?有这样五点:
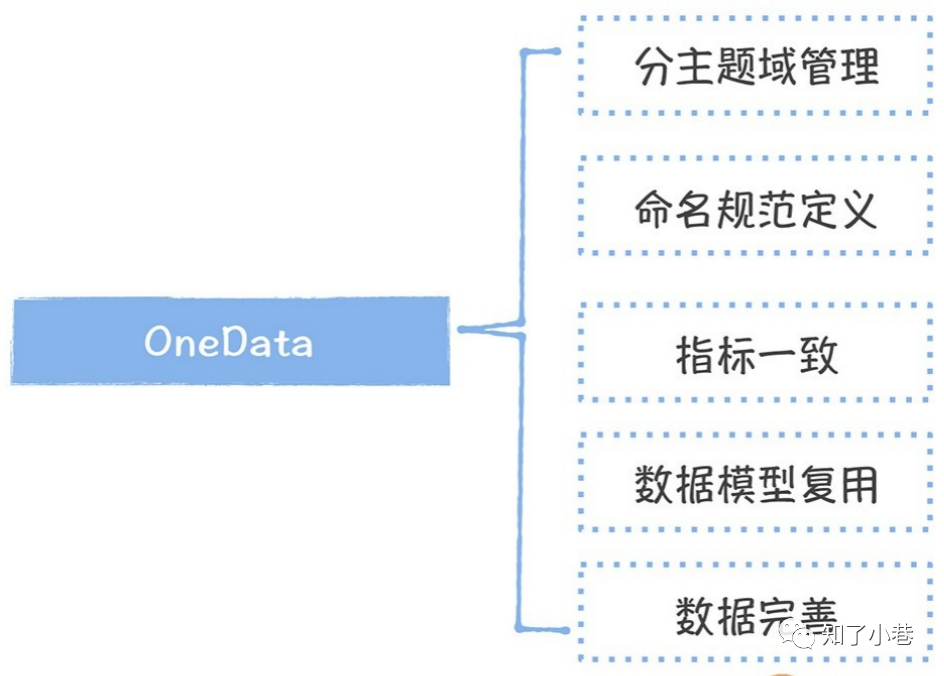
试想⼀下,现在你构建了数据中台,但存在⼏万张表,同时⼜有⼏⼗个数据开发维护这些表,如何来确保这些表的管理效率? 我建议你选择划主题域。
我们可以将这⼏万张表划到不同的主题域中,⽐如在电商业务中,商品、交易、流量、⽤⼾、售后、配送、 供应链都可以作为主题域。好的主题域划分,是相对稳定,尽可能地覆盖绝⼤多数的表。
除此之外,还要对表的命名进⾏规范化统⼀, 表的名称中最好能够携带表的主题域、业务过程、分层以及分区信息。⽐如,对于仓储域下的⼀张⼊库明细表,规则命名可以这样:

接着你还必须构建全局的指标字典,确保所有表中相同指标的⼝径必须⼀致。
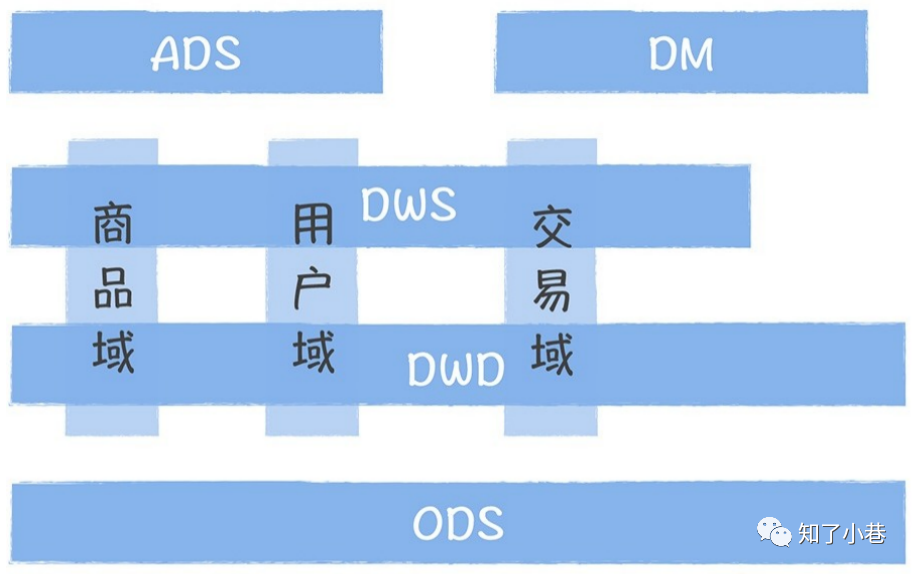
另外,为了实现模型的复⽤,数据中台适合采⽤分层的设计⽅式,常⻅的分层包括:ODS 原始数据层, DWD 明细数据层,DWS 轻度汇总数据层,ADS/DM 应⽤数据层/数据集市层。最后,数据中台的数据必须 尽可能的覆盖所有的业务过程,数据中台中每⼀层的数据也要尽可能完善,让数据使⽤者尽可能的使⽤汇总后的数据。
OneData 体系的⽬标是构建统⼀的数据规范标准,让数据成为⼀种资产,⽽不是成本。资产和成本的差别在于资产是可以沉淀的,是可以被复⽤的。成本是消耗性质的、是临时的、⽆法被复⽤的。
OneService
OneService,数据即服务,强调数据中台中的数据应该是通过API接⼝的⽅式被访问。
这⾥有个问题:为什么数据⼀定要通过API接⼝的⽅式被访问,不通过API 接⼝,直接提供数据表给⽤⼾⼜存在哪些问题呢?
如果你是数据应⽤开发,当你要开发⼀个数据产品时,⾸先要把数据导出到不同的查询引擎上:
## 数据量⼩的使⽤MySQL;
## ⼤的可能⽤到HBase;
## 需要多维分析的可能需要Greenplum;
## 实时性要求⾼的需要⽤到Redis;
总的来说,不同的查询引擎,应⽤开发需要定制不同的访问接⼝。
如果你是⼀个数据开发,当某个任务⽆法按时产出,发⽣异常时,想要了解这个表可能会影响到下游的哪些 应⽤或者报表,但是却发现单纯依赖表与表的⾎缘⽆法触及应⽤,根本⽆法知道最后的这些表被哪些应⽤访问。与此同时,当你想下线⼀张表时,因为不知道谁访问了这张表,⽆法实施,最终造成了“上线容易,下线难”的窘境。
⽽API接⼝⼀⽅⾯对应⽤开发屏蔽了底层数据存储,使⽤统⼀标准的API接⼝查询数据,提⾼了数据接⼊的速度。另⼀⽅⾯,对于数据开发,提⾼了数据应⽤的管理效率,建⽴了表到应⽤的链路关系。那如何来实现数据服务化呢?
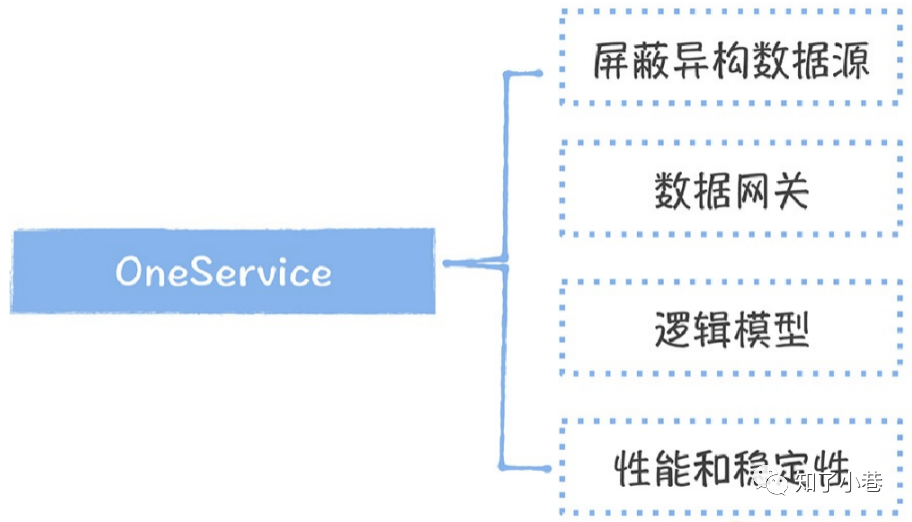
屏蔽异构数据源:数据服务必须要能够⽀撑类型丰富的查询引擎,满⾜不同场景下数据的查询需求,常⻅的 有MySQL、HBase、Greenplum、Redis、Elasticsearch等。
数据⽹关:要实现包括权限、监控、流控、⽇志在内的⼀系列管控能⼒,哪个应⽤的哪个⻚⾯访问了哪个模型,要做到实时跟踪,如果有⼀些模型⻓时间没有被访问,应该予以下线。使⽤数据的每个应⽤都应该通过accesskey和secretkey实现⾝份认证和接⼝权限的管理。另外,访问⽇志可以⽅便在访问出现问题时,加快排查速度。
逻辑模型:从⽤⼾的视⻆出发,屏蔽底层的模型设计的实现,⾯向⽤⼾提供逻辑模型。什么是逻辑模型呢?熟悉数据库的同学应该知道,数据库中有⼀个视图的概念,视图本⾝并没有真实的数据,⼀个视图可以关联⼀张或者多张表,每次在查询的时候,动态地将不同表的查询结果聚合成视图的查询结果。逻辑模型可以类⽐视图,它可以帮助应⽤开发者屏蔽底层的数据物理实现,实现相同粒度的数据构造⼀个逻辑模型,简化了数据接⼊的复杂度。
性能和稳定性:由于数据服务侵⼊到⽤⼾的访问链路,所以对服务的可⽤性和性能都有很⾼的要求,数据服务必须是⽆状态的,可以做到横向扩展。
OneService 体系的⽬标是提⾼数据的共享能⼒,让数据可以被⽤得好,⽤得爽。
# 数据中台⽀撑技术
讲完⽅法论,我们接着要来讲数据中台的⽀撑技术,因为⼀个好⽤的⼯具,可以让你的数据中台建设事半功倍。

这个图完整地描述了数据中台⽀撑技术体系,它的底层是以Hadoop为代表的⼤数据计算、存储基础设施, 提供了⼤数据运⾏所必须的计算、存储资源。
以HDFS为代表的分布式⽂件系统,以YARN/Kubernates为代表的资源调度系统,以Hive、Spark、Flink为代表的分布式计算引擎,都属于基础设施范畴。如果把数据中台⽐作是⼀个数据⼯⼚,那可以把它们⽐作是这 个⼯⼚的⽔、电。
在Hadoop之上,浅绿⾊的部分是原有⼤数据平台范畴内的⼯具产品,覆盖了从数据集成、数据开发、数据测试到任务运维的整套⼯具链产品。同时还包括基础的监控运维系统、权限访问控制系统和项⽬⽤⼾的管理系统。由于涉及多⼈协作,所以还有⼀个流程协作与通知中⼼。
灰⾊的部分,是数据中台的核⼼组成部分:数据治理模块。它对应的⽅法论就是OneData体系。以元数据中⼼为基础,在统⼀了企业所有数据源的元数据基础上,提供了包括数据地图、数仓设计、数据质量、成本优化以及指标管理在内的5个产品,分别对应的就是数据发现、模型、质量、成本和指标的治理。
深绿⾊的部分是数据服务,它是数据中台的⻔⼾,对外提供了统⼀的数据服务,对应的⽅法论就是OneService。数据服务向下提供了应⽤和表的访问关系,使数据⾎缘可以延申到数据应⽤,向上⽀撑了各种数据应⽤和服务,所有的系统通过统⼀的API接⼝获取数据。
在数据服务之上,是⾯向不同场景的数据产品和应⽤,包括⾯向⾮技术⼈员的⾃助取数系统;⾯向数据开发、分析师的⾃助分析系统;⾯向敏捷数据分析场景的BI产品;活动直播场景下的⼤屏系统;以及⽤⼾画像相关的标签⼯⼚。
这套产品技术⽀撑体系,覆盖了数据中台建设的整个过程,配合规范化实施,就可以搭建出“⼀个”数据中台。
# 组织架构
分散的业务部门会使得各个部⻔各自存在⼀些⼩的数仓,为什么会存在这些分散的⼩数仓?归根结底是因为建设这些数仓的⼈分散在各个业务部⻔。所以,如果要建设数据中台,单纯有⽅法论和⽀撑技术还不够,还必须要有⼀个独⽴于业务部⻔的中台团队。
数据中台提供的是⼀个跨业务部⻔共享的公共数据能⼒,所以,承担数据中台建设职责的部⻔⼀定是⼀个独⽴于业务线的部⻔。这个部⻔的负责⼈应该直接向公司的CTO汇报⼯作,当然这个也要取决于数据中台建设的层次,比如企业有多个产品线,如果数据中台的建设层次是在产品级别,不同产品线会分别有一个数据中台,并分别向各自产品线的CTO汇报。
⽽独⽴部⻔的最⼤⻛险是与业务脱节,所以我们对数据中台的组织定位是:懂业务,能够深⼊业务,扎根业务。数据中台要管理所有的指标,⽽每个业务线之间的指标既有差异,也有交叉,要理解指标的⼝径定义, 就必须要了解业务的过程。同时,当我们要制定⼀些新的指标时,必须要了解各个业务线新的业务⽬标,指标的本质还是为业务⽬标服务的。
综合来讲,什么样的组织架构是适合数据中台建设的呢?
## 数据产品部⻔:负责数据中台、数据产品的体系规划、产品设计、规范制定、应⽤效果跟进,指标⼝径的定义和维护(有的部⻔是由分析师管理)。
## 数据平台部⻔:负责研发⽀撑数据中台构建的产品,例如指标系统、元数据中⼼、数据地图等。
## 数据开发团队:负责维护数据中台的公共数据层,满⾜数据产品制定的数据需求。
## 应⽤开发团队:负责开发数据应⽤产品,⽐如报表系统、电商中的供应链系统、⾼层看板、经营分析。
⽽且,中台组织的绩效⽬标⼀定是要与业务落地价值绑定的,⽐如在电商中,我们提供了供应链决策系统,有智能补货的功能,会根据商品的库存,各个地区的历史销售情况,⽣产加⼯周期,⾃动⽣成补货决策,由⼈⼯审核以后,直接推送给采购系统。那我们评估价值时,我们会拿由系统⾃动⽣成的采购计划占整体采购计划的⽐例来衡量数据的应⽤价值。
最后,数据中台的组织架构改⾰涉及原有各个部⻔的利益,所以这个是数据中台构建最难⼜不得不做的地⽅,必须要取得⾼层领导的⽀持和重视。
总结
## 适合数据中台的组织架构是建设数据中台的第⼀步,数据中台组织⼀定是独⽴的部⻔,同时要避免与业务脱节,深⼊业务,要与业务⽬标绑定。
## 数据中台⽀撑技术⼤规模落地,需要有成熟的系统⼯具作为⽀撑,同时要注意这些系统⼯具之间的联动和打通。
## 数据中台的⽅法论可以借鉴,但是不能完全照搬,每个公司的数据应⽤⽔平和当前遇到的问题都不相同,可以针对这些问题,分阶段制定数据中台的建设计划,选择性的应⽤⼀些技术,例如当前最主要的问题是数据质量问题,那就应该优先落地数据质量中⼼,提升质量。
对于如何建设数据中台,⽅法论、⽀撑技术和组织架构,三者缺⼀不可。另外,数据中台的建设绝对不是为了建中台⽽建中台,数据中台的建设⼀定要结合落地场景,可以先从从⼀些⼩的场景开始,但是规划⼀定是要有顶层设计。
往期推荐:
Kafka消息送达语义说明
Hadoop YARN:ApplicationMaster向ResourceManager注册AM源码调试
Apache Hadoop YARN:Client<-->ResourceManager源码解析
Apache Hadoop YARN:Client<-->ResourceManager源码DEBUG
Hadoop YARN:ApplicationMaster与ResourceManager交互源码解析
Hive-DML(Data Manipulation Language)数据操作语言
Hive-DDL(Data Definition Language)数据定义


