





最近公司接入的征信系统越来越多,并且需要从中查询一些数据,做统计分析。分析人员对MONGODB 的查询语法不是太“灵光”。所以经常会问我怎么查一些数据,我只好在下班,或边边角角的时间来“满足”他们的需求。
起初我单纯的认为是,分析人员不会语法导致的,但是后面我发现问题没有那么“简单”。这里以 鹏元的某些反馈的征信数据为例,这样的MONGODB 的“表”设计的确是不得不吐槽。
我们看看我们要查的数据的格式是怎样布局的,由于一个document 的数据太大,所以我先画一个图让大家了解一下我要查询数据的到底在第几层

下面来截图看一下具体的数据 数据的查询层次是从 data 开始的,然后到了cisReport
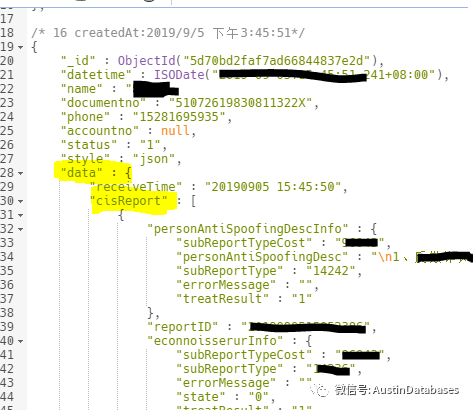
到 historySimpleQueryInfo ----- items ------ 查询

需要查询 items 中 消费金融公司中的 三个月前 是否贷过款

我们以结果为导向,看看到这条查询怎么写能达到,下面查询的效果
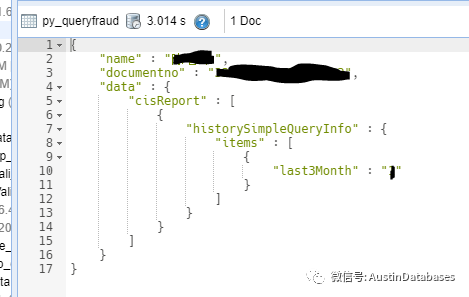
db.py_queryfraud.find({"name":"XXX","data.cisReport.historySimpleQueryInfo.items.unitMember":"XX金融公司"},{"data.cisReport.historySimpleQueryInfo.items":{"$slice":-1}"_id":0,"name":1,"documentno":1,"data.cisReport.historySimpleQueryInfo.items.last3Month":1})
通过上面的语句可以达到查询的效果,但硬伤是需要查询的数据必须在数组的最后一个。
同时我也请教了我们原来公司的 MONGODB 大咖,最后通过聚合来解决了问题,但我在想,到底是我们查询写的不溜,还是设计有问题,导致查询这么麻烦。
个人认为,设计上是有问题的,
1 MongoDB 虽然可以一行(准确的说一个 document)容纳 16MB 的内容,但是这不意味着,一行越大越好,一般控制在几个KB之内的效率是比较高的。试想你要是把一堆东西都塞在一行,你查询的性能是有多高。
2 使用数组时,创建大量的元素,并且进行UPDATE 的情形下,相关的数据的存储的位置是进行变换的,这就会影响相关创建的index,这些INDEX 如要reindex 这是因为每个数组元素都有一个单独的索引项,当插入或删除文档时,就会触发reindex。
3 嵌套太多的情况下,里面又使用数组加嵌套的情况,则单独定位某个数据是很困难的,例如我上面的例子。
那如何来进行设计则是一个需要考虑和讨论的问题,或许之前很多开发人员把MONGODB 当成开发者的数据库,但实际上随着业务的复杂度和卷入的人员越来越多,则MONGODB的设计也是越来越提上桌面。
例如上面的信息只要稍微变化以下,就可以顺利的查询出来,例如图中的数据如果不使用数组,直接使用嵌套,并且这些信息通过 key 来表明他是属于商业银行,还是互联网金融,还是某些特殊的金融公司,将这些标识添加在 last24month ---- last3Month 这些KEY 中,则查询就会好很多。

所以这里感觉到 数组的滥用和想当然,而不考虑后续的数据的提取,则是当初数据设计时的败笔。
所以以前所说的MONGODB 根本不用设计,想怎么存就怎么存,这句话仅仅是针对你的数据没人查,没人检索,而这样的话放在传统数据库也是可以的,只要没人查,那怎么写不是写。
所以MONGODB 也是需要精心的设计,尤其前期要想好数据的提取,千万别变成,写好写,读不好读的典范。

