





这是CDH/HDP/Apache Hadoop迁移到CDP系列的第二篇博客,如对迁移感兴趣,请关注该系列之前博客《使用 Replication Manager 迁移到CDP 私有云基础》、《将数据迁移到CDP 私有云基础的数据迁移用例》。
处理语法更改
处理表引用语法
查找具有问题表参考的表。
用反引号将数据库名称和表名称括起来。
CREATE TABLE `math`.`students` (name VARCHAR(64), age INT, gpa DECIMAL(3,2));
向表引用添加反引号
查找具有问题表参考的表。
math.students
用反引号将数据库名称和表名称括起来。
CREATE TABLE `math`.`students` (name VARCHAR(64), age INT, gpa DECIMAL(3,2));
LOCATION 和 MANAGEDLOCATION 子句
创建表位置的外部表限制
CREATE EXTERNAL TABLE my_external_table (a string, b string)ROW FORMAT SERDE 'com.mytables.MySerDe'WITH SERDEPROPERTIES ( "input.regex" = "*.csv")LOCATION '/warehouse/tablespace/external/hive/marketing';
表 MANAGEDLOCATION 子句
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name[COMMENT database_comment][LOCATION external_table_path][MANAGEDLOCATION managed_table_directory_path][WITH DBPROPERTIES (property_name=property_value, ...)];
识别语义变化和解决方法
转换时间戳
> SELECT CAST(1597217764557 AS TIMESTAMP);| 2020-08-12 00:36:04 |
> SELECT CAST(1597217764557 AS TIMESTAMP);| 2020-08-12 07:36:04.557 |
转换无效日期
> SELECT CAST ('0000-00-00' as date) , CAST ('000-00-00 00:00:00' AS TIMESTAMP) ;...------------_c0_c1------------NULLNULL------------1 row selected (0.154 seconds)
> SELECT CAST ('0000-00-00' as date) , CAST ('000-00-00 00:00:00' AS TIMESTAMP) ;...-----------------------------------+_c0_c1-----------------------------------+00002-11-30 00:00:00.0-----------------------------------+1 row selected (5.291 seconds)
更改不兼容的字段类型
创建表
创建符合 ACID 的表,这是 CDP 中的默认值 支持简单的写入和插入 写入多个分区 在单个 SELECT 语句中插入多个数据更新 无需分桶。
升级到 CDP 之前
执行以下一项或多项操作:
配置旧的 CREATE TABLE 行为(参见下一节)以默认创建外部表。 要从 Spark 读取 Hive ACID 表,请使用 Hive Warehouse Connector (HWC) 或 HWC Spark Direct Reader 连接到 Hive。要将 ACID 表从 Spark 写入 Hive,您可以使用 HWC 和 HWC API。当您不使用 HWC API 时,Spark 会创建一个具有清除属性的外部表。有关更多信息,请参阅 HWC Spark 直接读取器和 Hive 仓库连接器。 为表设置 Ranger 策略和 HDFS ACL。有关更多信息,请参阅 HDFS ACL 和 HDFS ACL 权限。
处理关键字APPLICATION
> select f1, f2 from application
SELECT field1, field2 FROM `application`;
禁用分区类型检查
SET hive.typecheck.on.insert=false;
删除分区
处理最大函数和最小函数的输出
SELECT greatest(nvl(col1,default value incase of NULL),nvl(col2,default value incase of NULL));
重命名表
外部表上的 TRUNCATE TABLE
Error: org.apache.spark.sql.AnalysisException: Operation not allowed: TRUNCATE TABLE on external tables
Hive 配置属性更改
Hive 配置属性值
升级前:
升级前:
hive\.auto\..*hive\.cbo\..*hive\.convert\..*hive\.exec\.dynamic\.partition.*hive\.exec\..*\.dynamic\.partitions\..*hive\.exec\.compress\..*hive\.exec\.infer\..*hive\.exec\.mode.local\..*hive\.exec\.orc\..*hive\.exec\.parallel.*hive\.explain\..*hive\.fetch.task\..*hive\.groupby\..*hive\.hbase\..*hive\.index\..*hive\.index\..*hive\.intermediate\..*hive\.join\..*hive\.limit\..*hive\.log\..*hive\.mapjoin\..*hive\.merge\..*hive\.optimize\..*hive\.orc\..*hive\.outerjoin\..*hive\.parquet\..*hive\.ppd\..*hive\.prewarm\..*hive\.server2\.proxy\.userhive\.skewjoin\..*hive\.smbjoin\..*hive\.stats\..*hive\.strict\..*hive\.tez\..*hive\.vectorized\..*mapred\.map\..*mapred\.reduce\..*mapred\.output\.compression\.codecmapred\.job\.queuenamemapred\.output\.compression\.typemapred\.min\.split\.sizemapreduce\.job\.reduce\.slowstart\.completedmapsmapreduce\.job\.queuenamemapreduce\.job\.tagsmapreduce\.input\.fileinputformat\.split\.minsizemapreduce\.map\..*mapreduce\.reduce\..*mapreduce\.output\.fileoutputformat\.compress\.codecmapreduce\.output\.fileoutputformat\.compress\.typeoozie\..*tez\.am\..*tez\.task\..*tez\.runtime\..*tez\.queue\.namehive\.transpose\.aggr\.joinhive\.exec\.reducers\.bytes\.per\.reducerhive\.client\.stats\.countershive\.exec\.default\.partition\.namehive\.exec\.drop\.ignorenonexistenthive\.counters\.group\.namehive\.default\.fileformat\.managedhive\.enforce\.bucketmapjoinhive\.enforce\.sortmergebucketmapjoinhive\.cache\.expr\.evaluationhive\.query\.result\.fileformathive\.hashtable\.loadfactorhive\.hashtable\.initialCapacityhive\.ignore\.mapjoin\.hinthive\.limit\.row\.max\.sizehive\.mapred\.modehive\.map\.aggrhive\.compute\.query\.using\.statshive\.exec\.rowoffsethive\.variable\.substitutehive\.variable\.substitute\.depthhive\.autogen\.columnalias\.prefix\.includefuncnamehive\.autogen\.columnalias\.prefix\.labelhive\.exec\.check\.crossproductshive\.cli\.tez\.session\.asynchive\.compathive\.exec\.concatenate\.check\.indexhive\.display\.partition\.cols\.separatelyhive\.error\.on\.empty\.partitionhive\.execution\.enginehive\.exec\.copyfile\.maxsizehive\.exim\.uri\.scheme\.whitelisthive\.file\.max\.footerhive\.insert\.into\.multilevel\.dirshive\.localize\.resource\.num\.wait\.attemptshive\.multi\.insert\.move\.tasks\.share\.dependencieshive\.support\.quoted\.identifiershive\.resultset\.use\.unique\.column\.nameshive\.analyze\.stmt\.collect\.partlevel\.statshive\.exec\.schema\.evolutionhive\.server2\.logging\.operation\.levelhive\.server2\.thrift\.resultset\.serialize\.in\.taskshive\.support\.special\.characters\.tablenamehive\.exec\.job\.debug\.capture\.stacktraceshive\.exec\.job\.debug\.timeouthive\.llap\.io\.enabledhive\.llap\.io\.use\.fileid\.pathhive\.llap\.daemon\.service\.hostshive\.llap\.execution\.modehive\.llap\.auto\.allow\.uberhive\.llap\.auto\.enforce\.treehive\.llap\.auto\.enforce\.vectorizedhive\.llap\.auto\.enforce\.statshive\.llap\.auto\.max\.input\.sizehive\.llap\.auto\.max\.output\.sizehive\.llap\.skip\.compile\.udf\.checkhive\.llap\.client\.consistent\.splitshive\.llap\.enable\.grace\.join\.in\.llaphive\.llap\.allow\.permanent\.fnshive\.exec\.max\.created\.fileshive\.exec\.reducers\.maxhive\.reorder\.nway\.joinshive\.output\.file\.extensionhive\.exec\.show\.job\.failure\.debug\.infohive\.exec\.tasklog\.debug\.timeouthive\.query\.id
hive\.auto\..*hive\.cbo\..*hive\.convert\..*hive\.druid\..*hive\.exec\.dynamic\.partition.*hive\.exec\.max\.dynamic\.partitions.*hive\.exec\.compress\..*hive\.exec\.infer\..*hive\.exec\.mode.local\..*hive\.exec\.orc\..*hive\.exec\.parallel.*hive\.exec\.query\.redactor\..*hive\.explain\..*hive\.fetch.task\..*hive\.groupby\..*hive\.hbase\..*hive\.index\..*hive\.index\..*hive\.intermediate\..*hive\.jdbc\..*hive\.join\..*hive\.limit\..*hive\.log\..*hive\.mapjoin\..*hive\.merge\..*hive\.optimize\..*hive\.materializedview\..*hive\.orc\..*hive\.outerjoin\..*hive\.parquet\..*hive\.ppd\..*hive\.prewarm\..*hive\.query\.redaction\..*hive\.server2\.thrift\.resultset\.default\.fetch\.sizehive\.server2\.proxy\.userhive\.skewjoin\..*hive\.smbjoin\..*hive\.stats\..*hive\.strict\..*hive\.tez\..*hive\.vectorized\..*hive\.query\.reexecution\..*reexec\.overlay\..*fs\.defaultFSssl\.client\.truststore\.locationdistcp\.atomicdistcp\.ignore\.failuresdistcp\.保留\.statusdistcp\.保留\.rawxattrsdistcp\.sync\.foldersdistcp\.delete\.missing\.sourcedistcp\.keystore\.resourcedistcp\.liststatus\.threadsdistcp\.max\.mapsdistcp\.copy\.strategydistcp\.skip\.crcdistcp\.copy\.overwritedistcp\.copy\.appenddistcp\.map\.bandwidth\.mbdistcp\.dynamic\..*distcp\.meta\.folderdistcp\.copy\.listing\.classdistcp\.filters\.classdistcp\.options\.skipcrccheckdistcp\.options\.mdistcp\.options\.numListstatusThreadsdistcp\.options\.mapredSslConfdistcp\.options\.bandwidthdistcp\.options\.overwritedistcp\.options\.strategydistcp\.options\.idistcp\.options\.p.*distcp\.options\.updatedistcp\.options\.deletemapred\.map\..*mapred\.reduce\..*mapred\.output\.compression\.codecmapred\.job\.queue\.namemapred\.output\.compression\.typemapred\.min\.split\.sizemapreduce\.job\.reduce\.slowstart\.completedmapsmapreduce\.job\.queuenamemapreduce\.job\.tagsmapreduce\.input\.fileinputformat\.split\.minsizemapreduce\.map\..*mapreduce\.reduce\..*mapreduce\.output\.fileoutputformat\.compress\.codecmapreduce\.output\.fileoutputformat\.compress\.typeoozie\..*tez\.am\..*tez\.task\..*tez\.runtime\..*tez\.queue\.namehive\.transpose\.aggr\.joinhive\.exec\.reducers\.bytes\.per\.reducerhive\.client\.stats\.countershive\.exec\.default\.partition\.namehive\.exec\.drop\.ignorenonexistenthive\.counters\.group\.namehive\.default\.fileformat\.managedhive\.enforce\.bucketmapjoinhive\.enforce\.sortmergebucketmapjoinhive\.cache\.expr\.evaluationhive\.query\.result\.fileformathive\.hashtable\.loadfactorhive\.hashtable\.initialCapacityhive\.ignore\.mapjoin\.hinthive\.limit\.row\.max\.sizehive\.mapred\.modehive\.map\.aggrhive\.compute\.query\.using\.statshive\.exec\.rowoffsethive\.variable\.substitutehive\.variable\.substitute\.depthhive\.autogen\.columnalias\.prefix\.includefuncnamehive\.autogen\.columnalias\.prefix\.labelhive\.exec\.check\.crossproductshive\.cli\.tez\.session\.asynchive\.compathive\.display\.partition\.cols\.separatelyhive\.error\.on\.empty\.partitionhive\.execution\.enginehive\.exec\.copyfile\.maxsizehive\.exim\.uri\.scheme\.whitelisthive\.file\.max\.footerhive\.insert\.into\.multilevel\.dirshive\.localize\.resource\.num\.wait\.attemptshive\.multi\.insert\.move\.tasks\.share\.dependencieshive\.query\.results\.cache\.enabledhive\.query\.results\.cache\.wait\.for\.pending\.resultshive\.support\.quoted\.identifiershive\.resultset\.use\.unique\.column\.nameshive\.analyze\.stmt\.collect\.partlevel\.statshive\.exec\.schema\.evolutionhive\.server2\.logging\.operation\.levelhive\.server2\.thrift\.resultset\.serialize\.in\.taskshive\.support\.special\.characters\.tablenamehive\.exec\.job\.debug\.capture\.stacktraceshive\.exec\.job\.debug\.timeouthive\.llap\.io\.enabledhive\.llap\.io\.use\.fileid\.pathhive\.llap\.daemon\.service\.hostshive\.llap\.execution\.modehive\.llap\.auto\.allow\.uberhive\.llap\.auto\.enforce\.treehive\.llap\.auto\.enforce\.vectorizedhive\.llap\.auto\.enforce\.statshive\.llap\.auto\.max\.input\.sizehive\.llap\.auto\.max\.output\.sizehive\.llap\.skip\.compile\.udf\.checkhive\.llap\.client\.consistent\.splitshive\.llap\.enable\.grace\.join\.in\.llaphive\.llap\.allow\.permanent\.fnshive\.exec\.max\.created\.fileshive\.exec\.reducers\.maxhive\.reorder\.nway\.joinshive\.output\.file\.extensionhive\.exec\.show\.job\.failure\.debug\.infohive\.exec\.tasklog\.debug\.timeouthive\.query\.idhive\.query\.tag
客户化关键的 Hive 配置
hive.conf.hidden.list hive.conf.restricted.list hive.exec.post.hooks hive.script.operator.env.blacklist hive.security.authorization.sqlstd.confwhitelist hive.security.command.whitelist
设置 Hive 配置覆盖
在Cloudera Manager > Clusters 中选择 Hive on Tez 服务。单击 Configuration,然后搜索 hive-site.xml。 在 hive-site.xml 的 Hive 服务高级配置片段(安全阀)中,单击 +。
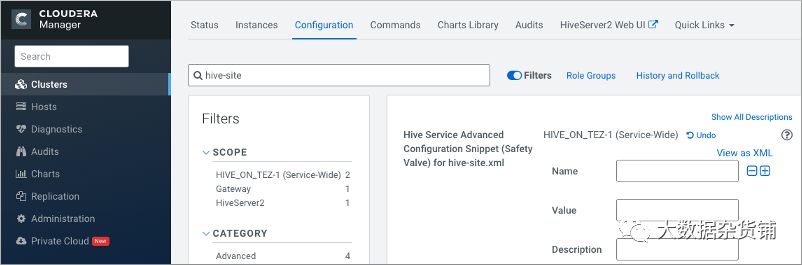
在名称中,添加hive.conf.hidden.list属性。 在值中,添加您的自定义列表。 自定义其他关键属性:hive.conf.restricted.list、 hive.exec.post.hooks、 hive.script.operator.env.blacklist、 hive.security.authorization.sqlstd.confwhitelist、 hive.security.command.whitelist。 保存更改并重新启动 Hive 服务。 查看配置要求和建议以了解保留或不保留哪些覆盖。
Hive 配置要求和建议
要求和建议
Set After Upgrade列:升级到 CDP 后需要手动配置的属性。升级后不会保留预先存在的自定义值。 默认推荐列:升级过程更改为新值的属性,强烈建议您使用。 Impacts Performance列:由您设置以调整性能的升级过程更改的属性。 安全值覆盖列:升级过程如何处理安全阀覆盖。 忽略:升级过程会从新的 CDP 配置中删除任何旧的 CDH 安全阀配置片段。 保留意味着升级过程将任何旧的 CDH 片段转移到新的 CDP 配置。 不适用意味着保留旧参数的值。 在 CM列中可见:升级后属性在 Cloudera Manager 中可见。
属性 | 升级后设置 | 默认推荐值 | 影响性能 | 新功能 | 安全阀覆盖 | Visible in CM |
datanucleus.connectionPool.maxPoolSize | ✓ | 保留 | ||||
datanucleus.connectionPoolingType | ✓ | 忽略 | ||||
hive.async.log.enabled | 忽略 | ✓ | ||||
hive.auto.convert.join.noconditionaltask.size | 不适用 | ✓ | ||||
hive.auto.convert.sortmerge.join | 保留 | |||||
hive.auto.convert.sortmerge.join.to.mapjoin | 保留 | |||||
hive.cbo.enable | 忽略 | ✓ | ||||
hive.cbo.show.warnings | 忽略 | |||||
hive.compactor.worker.threads | ✓ | 忽略 | ✓ | |||
hive.compute.query.using.stats | ✓ | 忽略 | ✓ | |||
hive.conf.hidden.list | ✓ | 忽略 | ||||
hive.conf.restricted.list | ✓ | 忽略 | ||||
hive.default.fileformat.managed | 忽略 | ✓ | ||||
hive.default.rcfile.serde | ✓ | 保留 | ||||
hive.driver.parallel.compilation | 忽略 | ✓ | ||||
hive.exec.dynamic.partition.mode | 忽略 | |||||
hive.exec.max.dynamic.partitions | 保留 | |||||
hive.exec.max.dynamic.partitions.pernode | 保留 | |||||
hive.exec.post.hooks | ✓ | 忽略 | ||||
hive.exec.reducers.max | ✓ 或其他数字 | 不适用 | ✓ | |||
hive.execution.engine | 忽略 | |||||
hive.fetch.task.conversion | ✓ | 不适用 | ✓ | |||
hive.fetch.task.conversion.threshold | ✓ | 不适用 | ✓ | |||
hive.hashtable.key.count.adjustment | ✓ | 保留 | ||||
hive.limit.optimize.enable | ✓ | 忽略 | ||||
hive.limit.pushdown.memory.usage | ✓ | 不适用 | ✓ | |||
hive.mapjoin.hybridgrace.hashtable | ✓ | ✓ | 忽略 | |||
hive.mapred.reduce.tasks.speculative.execution | ✓ | 忽略 | ||||
hive.metastore.aggregate.stats.cache.enabled | ✓ | ✓ | 忽略 | |||
hive.metastore.disallow.incompatible.col.type.changes | 忽略 | |||||
hive.metastore.dml.events | 忽略 | ✓ | ||||
hive.metastore.event.message.factory | ✓ | 忽略 | ||||
hive.metastore.uri.selection | ✓ | 忽略 | ||||
hive.metastore.warehouse.dir | 保留 | ✓ | ||||
hive.optimize.metadataonly | ✓ | 忽略 | ||||
hive.optimize.point.lookup.min | 忽略 | |||||
hive.prewarm.numcontainers | 忽略 | |||||
hive.script.operator.env.blacklist | ✓ | 忽略 | ||||
hive.security.authorization.sqlstd.confwhitelist | ✓ | 忽略 | ||||
hive.security.command.whitelist | ✓ | 忽略 | ||||
hive.server2.enable.doAs | 忽略 | ✓ | ||||
hive.server2.idle.session.timeout | 不适用 | ✓ | ||||
hive.server2.max.start.attempts | 保留 | |||||
hive.server2.parallel.ops.in.session | 保留 | |||||
hive.server2.support.dynamic.service.discovery | ✓ | 忽略 | ✓ | |||
hive.server2.tez.initialize.default.sessions | ✓ | 忽略 | ||||
hive.server2.thrift.max.worker.threads | 不适用 | ✓ | ||||
hive.server2.thrift.resultset.max.fetch.size | 保留 | |||||
hive.service.metrics.file.location | 忽略 | ✓ | ||||
hive.stats.column.autogather | ✓ | 忽略 | ||||
hive.stats.deserialization.factor | ✓ | 忽略 | ||||
hive.support.special.characters.tablename | ✓ | 忽略 | ||||
hive.tez.auto.reducer.parallelism | ✓ | 忽略 | ✓ | |||
hive.tez.bucket.pruning | ✓ | 忽略 | ✓ | |||
hive.tez.container.size | ✓ | 忽略 | ✓ | |||
hive.tez.exec.print.summary | ✓ | 忽略 | ✓ | |||
hive.txn.manager | ✓ | 忽略 | ✓ | |||
hive.vectorized.execution.mapjoin.minmax.enabled | ✓ | 忽略 | ||||
hive.vectorized.execution.mapjoin.native.fast.hashtable.enabled | ✓ | 忽略 | ||||
hive.vectorized.use.row.serde.deserialize | ✓ | 忽略 |
使用 YARN 队列为 ETL 配置 HiveServer
在 Cloudera Manager 中,单击集群> Hive >配置。 搜索hive-site.xml设置的Hive 服务高级配置片段(安全阀)。 在hive-site.xml设置的Hive 服务高级配置片段(安全阀)中,单击+。 在名称中输入属性 hive.server2.tez.initialize.default.sessions并在值中输入false。 在名称中输入属性 hive.server2.tez.queue.access.check并在值中输入 true。 在名称中输入属性 hive.server2.tez.sessions.custom.queue.allowed并在值中输入true。
移除Hive on Spark配置
配置对表的授权
在 Ranger 中设置 Hive HDFS 策略(推荐)以包含外部表数据的路径。 放置一个 HDFS ACL。将外部文本文件(例如逗号分隔值 (CSV) 文件)存储在 HDFS 中,该文件将用作外部表的数据源。
org.apache.hadoop.hive.ql.ddl.DDLTask. MetaException(message:No privilege 'Create' found for outputs { database:DATABASE_NAME, table:TABLE_NAME})
使 Ranger 的 Hive 插件可见
hive.security.authorization.enabled hive.security.authorization.manager hive.security.metastore.authorization.manager
单击Clusters > Ranger > Ranger Admin Web UI > Audit > Plugin Status检查 Hive 插件是否可见。
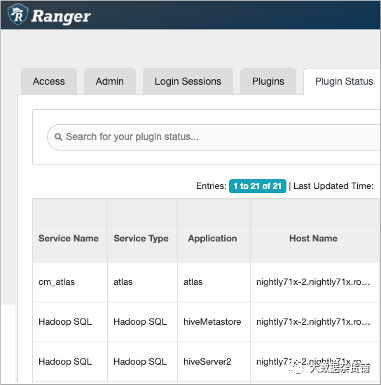
使用 Cloudera Manager 安全阀,为 HMS API-Ranger 集成设置以下属性和值: hive.metastore.pre.event.listeners
hive.security.authenticator.manager
如果 Hive 和 Hive Metastore 的 Hadoop SQL 服务类型和相应应用程序未出现,请从 hive-site.xml 中删除上面列出的 Hive 和 Hive on Tez 服务的属性。
设置访问控制列表
配置加密区域的安全
执行以下任一操作: 将自签名 SSL 证书安装到所有主机上的 cacerts 文件中,然后跳过以下步骤。 建议:执行以下步骤。 将 ssl-client.xml 复制到所有主机上都可用的目录。 在 Cloudera Manager 中,单击集群> Hive on Tez>配置。集群 > Hive on Tez> 配置。 搜索hive-site.xml设置的Hive 服务高级配置片段(安全阀)。 在hive-site.xml设置的Hive 服务高级配置片段(安全阀)中,单击+。 在名称中输入属性tez.aux.uris并在值中输入 path-to-ssl-client.xml。
将 HWC/Spark Direct Reader 用于 Spark 应用程序/ETL
配置 HiveServer HTTP 模式
单击Cloudera Manager >集群> HIVE_ON_TEZ >配置 在搜索中,键入transport。 在 HiveServer2 传输模式中,选择 http。
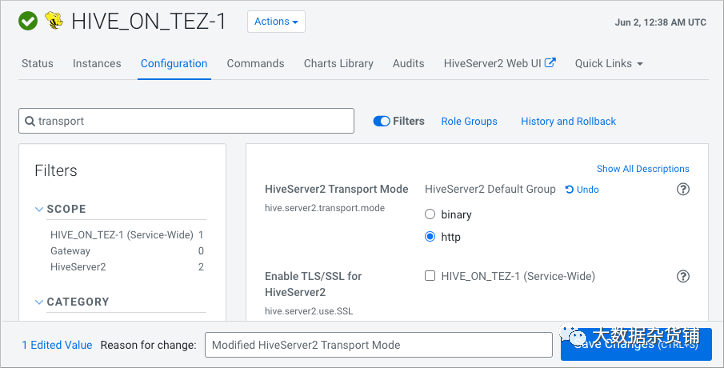
在 Tez 上保存并重新启动 Hive。
配置 HMS 以实现高可用性
在 Cloudera Manager 中,单击集群> Hive >配置。 采取以下措施之一: 如果您有一个由 Kerberos 保护的集群,请搜索 Hive Delegation Token Store 它指定 Kerberos 令牌的存储,如下所述。 如果您有一个不安全的集群,请跳过下一步。 选择org.apache.hadoop.hive.thrift.DBTokenStore,然后保存更改。

单击实例>操作>添加角色实例
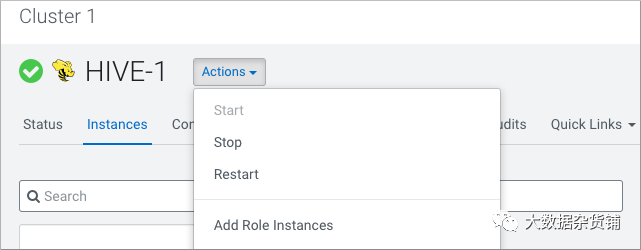
在分配角色中,在 Metastore 服务器中,单击选择主机。 在 Hosts Selected 中,滚动并选择要用作备份 Metastore 的主机,然后单击 OK。 单击继续,直到退出向导。 从“操作”菜单启动主机上的 Metastore 角色。
要检查或更改hive.metastore.uri.selection 属性,请转到Clusters > Hive > Configurations,然后搜索 Hive Service Advanced Configuration Snippet (Safety Valve) for hive-site.xml。 添加属性和值(SEQUENTIAL 或 RANDOM)。
修正统计数据
运行 DESCRIBE FORMATTED <table>,并检查 numrows的值。
对表和列运行 ANALYZE 以修复统计信息。
ANALYZE TABLE credit_card_01.cc_acct COMPUTE STATISTICS[FOR COLUMNS];
不支持的接口和功能
不支持的接口
Druid Hcat CLI Hive CLI(由 Beeline 替换) HiveView LLAP(仅在 CDP 公共云中可用) MapReduce 执行引擎(替换为 Tez) Pig S3 用于存储表(仅在 CDP 公共云中可用) Spark 执行引擎(由 Tez 替代) Spark Thrift server
SQL 标准授权 基于存储的授权 (SBA) Tez视图 WebHCat
基于存储的授权
不支持的功能
指定托管表位置的 CREATE TABLE
CREATE INDEX 和相关的索引命令在 Hive 3 中被删除,因此在 CDP 中不受支持。
CDH 中的 Hive Metastore (HMS) 高可用性 (HA) 负载平衡
不支持的连接器使用
CDH Hive 表的更改
升级过程将hive.metastore.warehouse.dir属性设置为 /warehouse/tablespace/managed/hive,将其指定为托管表的 Hive 仓库位置。您在 CDP 中创建的新托管表存储在 Hive 仓库中。新的外部表存储在 Hive 外部仓库中 /warehouse/tablespace/external/hive。
Hive > Action Menu > Create Hive Warehouse Directory Hive > Action Menu > Create Hive Warehouse External Directory
从 Cloudera Manager Actions 为 Hive 仓库目录和 Hive 仓库外部目录设置目录。
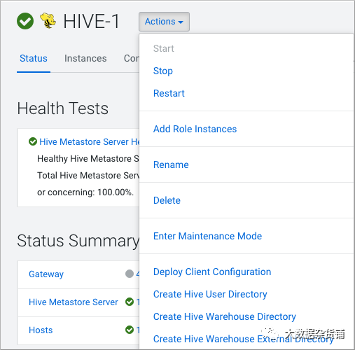
在 Cloudera Manager 中,单击Clusters > Hive(Hive Metastore 服务)> Configuration,并将 hive.metastore.warehouse.dir 属性值更改为您为新 Hive 仓库目录指定的路径。 将 hive.metastore.warehouse.external.dir 属性值更改为您为 Hive 仓库外部目录指定的路径。 配置 Ranger 策略或设置 ACL 权限以访问目录。
对 HDP Hive 表的更改
旧表或分区目录/apps/hive/warehouse在升级前不在其默认位置 。 旧表或分区与新仓库目录位于不同的文件系统中。 旧表或分区目录与新仓库目录位于不同的加密区域。
修改表的引用使用点表示法
对 ACID 属性的更改
原生和非原生的存储格式
原生:在 Hive 中具有内置支持的表,例如以下文件格式的表: 文本 序列文件 RC文件 AVRO 文件 ORC Parquet文件 非原生:使用存储处理程序的表,例如 DruidStorageHandler 或 HBaseStorageHandler
CDP 升级对 HDP 表类型的更改
HDP 2.x | CDP | ||||
|---|---|---|---|---|---|
表类型 | ACID v1 | 格式 | Hive 表文件的所有者(用户) | 表类型 | ACID v2 |
外部表 | 不 | 原生或非原生 | Hive或非Hive | 外部表 | 不 |
受管表 | 是的 | ORC | Hive或非Hive | 托管表,可更新 | 是 |
受管表 | 不 | ORC | Hive | 托管表,可更新 | 是 |
非Hive | 外部表,带数据删除 | 不 | |||
受管表 | 不 | 原生(但非 ORC) | Hive | 托管表,仅插入 | 是 |
非Hive | 外部表,带数据删除 | 不 | |||
受管表 | 不 | 非原生 | Hive或非Hive | 外部表,带数据删除 | 不 |
Cloudera中国
更多资讯,点击阅读原文
长按扫码关注我们

