





Apache Kudu 是一个开源存储层,可以为 Hadoop 生态系统提供一个能够对快速数据进行快速分析的数据库功能。
Kudu 不需要像复杂的 Lambda 架构那样将数据处理分为速度层和批处理层,而是组合在一个数据层中。该数据架构的简化使得 Hadoop 生态系统可作为各种用例的一种低成本替代方案,适用实例包括时间序列数据、机器数据分析、在线报告和预测性物联网(IoT)等。
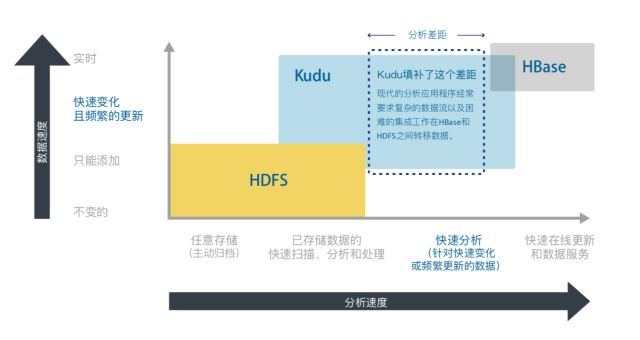
解决 Hadoop 存储层中的鸿沟
原先的 Hadoop 存储层是 HDFS – Hadoop 分布式文件系统。HDFS 能够摄取大量的批量数据,并且能够分析这些数据的趋势和其它洞察。对这些数据进行快速分析扫描的能力是 HDFS 的特点所在。
Apache HBase ™️是在 HDFS 之后推出的,旨在为操作型用例提供所要求的类似NoSQL 的快速读取和写入功能。HBase 支持重用特定值及保持实时数据集更新以备特定查询使用的使用案例。
Kudu 通过将快速摄取数据的能力与对这些数据进行广泛分析扫描的能力相结合,填补了原有 Hadoop 存储层之间的差距。这种本地 Hadoop 存储引擎提供了一个充分利用新一代硬件的简化数据架构。消除了创建复杂 Lambda 架构的障碍,Kudu 可以更轻松地发布新的实时分析应用程序,并支持分析工作负载所需的全面更新功能。
Kudu 用例
使用 Kudu,用户可以对实时的、可更新的数据进行分析查询。与 Apache Hadoop 生态系统的其他组件结合使用时,Kudu 可以提供广泛的数据库解决方案 :
分析型数据库 :与 Apache Impala 一起,Kudu 可以创建一种可实时分析的数据库,使用户能够对数据进行处理的同时仍然可以通过相应的决策来影响最终的结果。Impala 领先的分析型 SQL 性能与 Kudu 的可更新列式存储功能相结合,提供了一个现代分析数据库,将高性能商业智能(BI)和分析引入到大数据中。
操作型数据库 :Apache Spark ™️与 Kudu 相集成,通过 Cloudera 的操作型数据库提供实时应用程序。Kudu 与 Spark 一起为这些应用程序提供了超越基于规则的洞察力以及数据检索服务的能力,具有更高价值的分析能力能够产生更佳结果。
除了能提供分类数据库解决方案之外,Kudu 在处理某些特定的用例上特别有效 :
时间序列数据 :如果能够分析并实时更改结果,时间序列数据可以非常有价值。使用 Kudu,时间序列数据可以在其到达时进行插入 更新操作,通过分析扫描可以在最新的时间序列数据中找到趋势,通过随机读取可以使分析人员能够及时访问发生事件的时间点。
机器数据分析 :Kudu 的通过分析扫描功能分析趋势的能力,结合实时数据插入功能,意味着可以在发生网络问题之前识别该问题。使用 Kudu,可以保护您的网络安全性,确保网络健康和应用程序性能。
在线报告 :在线报告通常受到数据量和分析能力的限制,这意味着只有最近的数据才能进行细粒度的查询。而 Kudu 通过在分析扫描的同时启用随机读 / 写来改变这种模式,从而改变了操作型数据存储的能力。
Kudu 包含在 Cloudera 企业数据中心版本
Cloudera 对 Kudu 的开发,以及随后对 Apache 软件基金会所作出的贡献不仅表明了对该项目郑重的投入承诺,同时也在解决新出现的不断变化的客户用例。Kudu 与 Impala、Spark、MapReduce 的集成点将继续不断扩展,包括在 Cloudera 企业数据中心版本中的全套组件,以及用户所需的管理、治理和安全功能。
请通过以下地址下载并试用 Kudu
http://www.cloudera.com/downloads/beta/kudu.html

请点击“阅读全文”进入微站

