




目前唯品会计算集群规模已经达到数千台,承载着公司核心ETL任务调度,但这些计算节点中存在着很多cpu核数型号或者内存等异构情况。与此同时,我们关注到Cgroup技术对于cpu、memory资源隔离有着很好的作用,并且yarn container也支持这一特性。
本文会先从整体把握yarn container的生命周期,帮助读者了解yarn在container哪个阶段加入资源检查,cgroup又是在哪些地方起作用,接着从细节上研究cgroup在yarn container中如何发挥作用,最后分享一些我们认为cgroup目前的不足之处。
Cgroup概念
Cgroups 是Linux内核提供的一种可以限制单个或多个进程所使用资源的机制,可以对 cpu、内存等资源实现精细化控制。Cgroup典型的子系统包括cpu子系统和memory子系统等。Cpu子系统主要限制进程的cpu使用率,memory子系统主要限制进程的内存使用率。下图是线上nodemanager 开启cgroup之后所有可用的子系统。

Cgroup如何限制资源使用
了解cgroup概念之后,下面以cpu子系统为例(memory子系统大同小异),我们会介绍如何应用cgroup以达到限制节点上所有container整体使用上限以及限制单个container使用上限的目的。
限制节点使用
先看整体使用上限,cpu子系统下面有cfs_quota_us和cfs_period_us这两个配置,cfs_period_us是指cpu时间周期长度,cfs_quota_us是指该周期长度时间范围内可以使用的cpu时间数,单位都是微秒。用cfs_period_us除以cfs_quota_us 等到就是cpu逻辑核数。Yarn固定cpu周期长度是1000000微秒,假设目前需要限制整体cpu使用上限是节点的85%(可以通过percentage-physical-cpu-limit配置), 节点的逻辑核数是48核,也就是整体最多使用48*0.85即40.8个逻辑核数。有了cpu上限逻辑核数核cpu周期数,继而也就确定了cfs_quota_us的值。在nodemanager启动时, 会把cfs_quota_us和cfs_period_us写到相应mount路径下,例如 sys/fs/cgroup/cpu/hadoop-yarn,并打印一条日志如下所示。
org.apache.hadoop.yarn.server.nodemanager.containermanager.linux.resources.CGroupsCpuResourceHandlerImpl:YARN containers restricted to 40.8 core
限制单个container使用
上面介绍了整体使用限制,接下来看cgroup如何对单个container做限制。首先限制单个container模式分为严格模式和非严格模式,可以通过 yarn.nodemanager.linux-container-executor.cgroups.strict-resource-usage 配置项进行控制。

如果是非严格模式,在container启动时只需要在cpu子系统下的container路径下(例如/sys/fs/cgroup/cpu/hadoop-yarn/container_e87_XXXXXXXX_7128056_01_000506)写入cpu.share的值。cpu.share是用来设置cpu使用的相对值,默认值是1024,假设系统中有两个cgroup,分别是A和B,A的值是1024,B的值是2048,那么A将获得1024/(1024+2048)即33.33%的cpu,B将获得2048/(1024+2048)即66.66%的cpu。如果B不忙的话,可以把剩余cpu时间分配给A。
严格模式相比非严格模式,主要区别在于严格模式会对每个container的使用上限做严格控制,这块和节点使用限制一样,还是依赖cfs_period_us和cfs_quota_us这两个配置。严格模式资源限制更严格,控制container使用的上限,在低负载场景下无法充分利用节点空闲的资源。而非严格模式可以根据container资源申请情况,动态分配资源,这样可以充分利用节点资源,当然运行时间也会不稳定。
container生命周期中的cgroup
上面介绍了单个container限制逻辑,接下来我们看看这些限制是如何加入到一个container生命周期当中的。首先回顾一下container生命周期,container在nodemanager上主要经历以下几个状态转换(省略了一些分支状态,只关注主干):LOCALIZING、SCHEDULED、RUNNING和EXITED_WITH_SUCCESS。如下图所示:

其中从LOCALIZING 到 SCHEDULED ,主要检测是否有可用的resource(cpu,mem等),如果资源满足,接下来就发送 launch事件。状态从scheduled 到 running ,是处理launch事件,先是准备launch container的环境,包括启动命令、环境变量等,一切就绪后,就把该container加入到被containerMonitor线程监控的列表,然后通过LinuxContainerExecutor去启动container。这之后container状态变为running, 直到最后运行成功。
在上述四个生命周期中,cgroup主要作用于launch container 和 containerMonitor这两个过程。先看launch container, 是指在container启动前把container的cpu限制写入cgroup相关路径。下图是整个container启动流程,需要注意到在调用每个resouceHandlerImpl的updateContainer时,这里会真正把对container的限制写入cgroup路径。
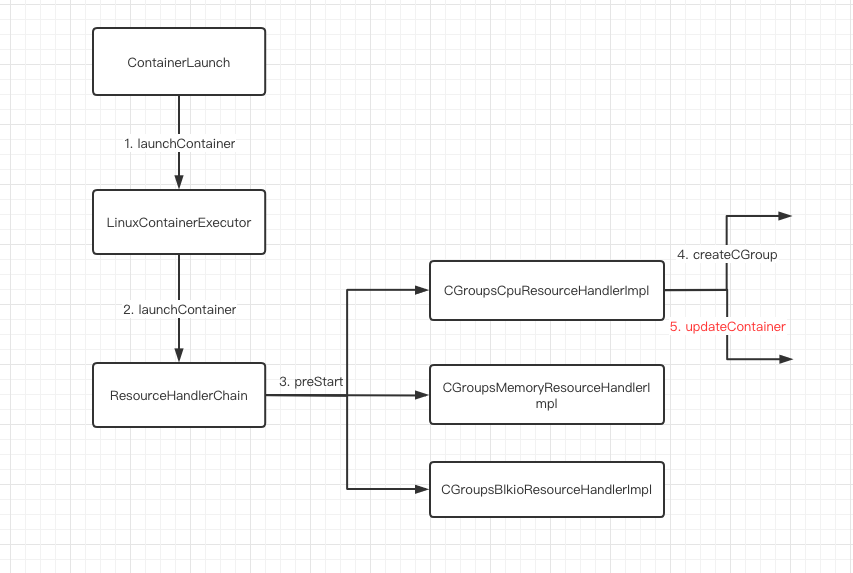
以CGroupcpuResourceHandlerImpl为例,下面是updateContainer 的逻辑,省去了一些旁支和异常。相比非严格模式, 严格模式除了要写入cpuShares,还要依赖cfs_period_us和cfs_quota_us这两个配置,把这两个配置写到cgroup的每个container路径下。
@Overridepublic List<PrivilegedOperation> updateContainer(Container container)throws ResourceHandlerException {.......int cpuShares = CPU_DEFAULT_WEIGHT * containerVCores;cGroupsHandler.updateCGroupParam(CPU, cgroupId,CGroupsHandler.CGROUP_CPU_SHARES,String.valueOf(cpuShares));if (strictResourceUsageMode) {if (nodeVCores != containerVCores) {float containerCPU =(containerVCores * yarnProcessors) / (float) nodeVCores;int[] limits = getOverallLimits(containerCPU);cGroupsHandler.updateCGroupParam(CPU, cgroupId,CGroupsHandler.CGROUP_CPU_PERIOD_US, String.valueOf(limits[0]));cGroupsHandler.updateCGroupParam(CPU, cgroupId,CGroupsHandler.CGROUP_CPU_QUOTA_US, String.valueOf(limits[1]));}......}
控制每个container使用上限需要确定单个container可使用的逻辑核数。其计算公示如下:
containerCPU = containerVCores nodeVCores * yarnProcessors
其中containerCPU就是单个container可使用的逻辑核数, containerVCores来自container启动时申请的vcore数量,nodeVCore即这台节点总共可使用的vcore数量, yarnProcessors即此节点的真实cpu逻辑核数。 所以这里的containerCPU 就是基于containerVCores和节点VCores的比例,计算出的此Container可以用的真实逻辑核数。
在container running 之前,需要启动container相应的监控线程即containerMonitor线程,其run方法如下所示。主要逻辑分两块,记录container的资源使用包括cpu、memory 以及检查是否超出限制,如果超出可能要会杀死container。
@Overridepublic void run() {while (!stopped && !Thread.currentThread().isInterrupted()) {......for (Entry<ContainerId, ProcessTreeInfo> entry : trackingContainers.entrySet()) {ContainerId containerId = entry.getKey();ProcessTreeInfo ptInfo = entry.getValue();try {String pId = ptInfo.getPID();initializeProcessTrees(entry);......ResourceCalculatorProcessTree pTree = ptInfo.getProcessTree();pTree.updateProcessTree(); // update process-treelong currentVmemUsage = pTree.getVirtualMemorySize();long currentPmemUsage = pTree.getRssMemorySize();float cpuUsagePercentPerCore = pTree.getCpuUsagePercent();recordUsage(containerId, pId, pTree, ptInfo, currentVmemUsage,currentPmemUsage, trackedContainersUtilization);checkLimit(containerId, pId, pTree, ptInfo,currentVmemUsage, currentPmemUsage);} catch (Exception e) {// Log the exception and proceed to the next container.LOG.warn("Uncaught exception in ContainersMonitorImpl "+ "while monitoring resource of " + containerId, e);}}
最后如果container成功运行结束,相应地发送CONTAINER_EXITED_WITH_SUCCESS事件,最终由ContainerCleanup线程去处理,清理相应的临时目录,包括上面cgroup限制目录。至此整个cgroup在yarn上的流程就全部介绍完毕。
当前我们面临的问题
container可使用逻辑核数问题
在严格模式下,我们需要确定单个container可使用的逻辑核数即containerCPU,目前的计算逻辑在线上集群存在一个问题。具体来说,是线上集群存在超卖的情况,而且在资源紧张的高峰期,甚至还会做动态资源的调整,来压榨机器的cpu和memory。如下图所示,假设node的vcore是7,每个container申请2个vcore,实际使用1个物理core,那么node此时可以启动三个container。如图A所示,但其实节点资源并没有充分利用,节点物理cpu还有富余。现在调大node vcore,设置为8个core,如图B所示,这样在不超过节点物理core的情况下,可以启动4个container。

如上所示,单个节点可运行container数量变多,吞吐量也上去了,但是每个container申请的vcore并没有变化,再观察一下计算containerCPU的公式:
containerCPU = (containerVCores * yarnProcessors) nodeVCores
其实通过把containerVCores/nodeVCores固定为一个可动态刷新的配置变量, 就能与动态超配nodeVCores解耦,将不会影响单个container的计算能力。与此同时,在这种场景下超卖资源,我们重写了nodemanager判断是否有足够资源启动container的逻辑, 简单来说即引入container queue length,该queue里是等待启动的container, 如果queue length可以消化,我们就可以认为在保证吞吐量的前提下,节点资源也得到了充分利用。当然上述讨论都是基于开启严格模式的。
ContainersMonitor线程耗cpu问题
在集群cgroup上线一段时间后,我们观察到NodeManager进程存在耗cpu的情况,其中耗cpu比较多的线程居然有ContainersMonitor线程,堆栈信息如下:
load: 20.10, 15.36, 14.76type: java%CPU: 165.0command:%CPU RSS PID PPID USER GROUP TIME STARTED ELAPSED COMMAND100 12948352 48347 1 yarn yarn 5-08:31:17 Fri Oct 30 19:36:12 2020 5-08:24:50 xxxxx/hadoop -Dhadoop.id.str=yarn -Dhadoop.policy.file=hadoop-policy.xml org.apache.hadoop.yarn.server.nodemanager.NodeManagerthreads:0x1b4ab:99.90xc0c3:5.9"Container Monitor" #36 prio=5 os_prio=0 tid=0x00007fd089829800 nid=0x1b4ab runnable [0x00007fd087ffe000]java.lang.Thread.State: RUNNABLEat java.io.FileInputStream.close0(Native Method)at java.io.FileInputStream.access$000(FileInputStream.java:49)at java.io.FileInputStream$1.close(FileInputStream.java:336)at java.io.FileDescriptor.closeAll(FileDescriptor.java:212)- locked <0x0000000704934f18> (a java.io.FileDescriptor)at java.io.FileInputStream.close(FileInputStream.java:334)at sun.nio.cs.StreamDecoder.implClose(StreamDecoder.java:378)at sun.nio.cs.StreamDecoder.close(StreamDecoder.java:193)- locked <0x0000000704934e38> (a java.io.InputStreamReader)at java.io.InputStreamReader.close(InputStreamReader.java:199)at org.apache.hadoop.yarn.util.ProcfsBasedProcessTree.constructProcessInfo(ProcfsBasedProcessTree.java:557)at org.apache.hadoop.yarn.util.ProcfsBasedProcessTree.updateProcessTree(ProcfsBasedProcessTree.java:211)at org.apache.hadoop.yarn.server.nodemanager.containermanager.monitor.ContainersMonitorImpl
这是因为集群开启了cgroup, 但是资源计算还是用的ProcfsBasedProcessTree 这个类。这个类需要先去获取节点上的所有进程, 再遍历每个进程的/proc/pid/stat文件里的信息,最后去更新ProcessInfo对象的属性。这段遍历会不断地去文件系统获取信息还是很耗cpu的。可以单独通过以下配置切换使CGroupsResourceCalculator。
<property><name>yarn.nodemanager.container-monitor.process-tree.class</name><value>org.apache.hadoop.yarn.server.nodemanager.containermanager.linux.resources.CGroupsResourceCalculator</value></property>
CGroupsResourceCalculator 为每个container进程构建了cpu信息文件,即Cgroup为每个cgroup进程都统一收集了信息,不需要再直接访问每个进程的proc文件系统信息,只需要遍历每个进程相关的cgroup文件信息,如下所示:
cat /sys/fs/cgroup/cpu/hadoop-yarn/container_e83_1603365939677_12991059_01_000012/cpuacct.statuser 3715system 559
切换成CGroupsResourceCalculator,containerMonitor耗cpu从夜间每小时4到7次降到了整晚1到2次左右。但是别急,cgroup的文件信息收集其实也有问题,下面就讲。
内存统计问题
上文讲到在默认实现里YARN是根据/proc/${pid}/stat来计算总内存,默认统计内存公式为
RssMemorySize=totalPages * PAGE_SIZE
以container_xxxx_9875_01_000302 为例,查看运行时的stat文件
[root@sd-bigdata-hadoop-bip-dn-049 ~]# cat proc/34644/stat34644 (java) S 34482 34482 34482 0 -1 1077944320 297624 1259 0 0 609 108 0
可以看到totalPages为273480,节点PAGE_SIZE为4096,根据公式统计内存就是1120174080。
而在切换成CGroupsResourceCalculator后,但是夜间高峰期有部分hive作业遭遇了oom导致task被杀,但是却不是由jvm报出而是通过cgroup机制,查看当时系统日志/var/log/messages,发现在oom时确实超出了memory.usage_in_bytes的值,cgroup oom控制器依据的就是该值,如果这个值超过limit时container就会被杀,它的计算方式如下:
memory.usage_in_bytes= total_cache + total_rss + memory.kmem.usage_in_bytes
依然以container_xxxx_9875_01_000302 为例,中间省略部分日志(如下):
2021-01-18 19:21:32,924 INFO [Container Monitor] org.apache.hadoop.yarn.server.nodemanager.containermanager.monitor.ContainersMonitorImpl: Resource usage of ProcessTree 34482 for container-id container_xxxx_9875_01_000302: 1418231808 of 6764573184 virtual memory used; 1418354688 of 3221225472 physical memory used;Request Vcore:1 ,used CPU:175.590286 CPU/core:2.7435982021-01-18 19:22:54,063 INFO [Container Monitor] org.apache.hadoop.yarn.server.nodemanager.containermanager.monitor.ContainersMonitorImpl: Resource usage of ProcessTree 34482 for container-id container_xxxx_9875_01_000302: 2109358080 of 6764573184 virtual memory used; 2109358080 of 3221225472 physical memory used;Request Vcore:1 ,used CPU:171.162170 CPU/core:2.6744092021-01-18 19:23:00,068 INFO [Container Monitor] org.apache.hadoop.yarn.server.nodemanager.containermanager.monitor.ContainersMonitorImpl: Resource usage of ProcessTree 34482 for container-id container_xxxx_9875_01_000302: 1845673984 of 6764573184 virtual memory used; 1845673984 of3221225472 physical memory used;Request Vcore:1 ,used CPU:100.233101 CPU/core:1.
可以看到这两块内存统计方式有很大区别,统计逻辑可能存在问题,目前我们认为这部分问题可能和系统kernel部分相关,还在测试当中。
总结
本文简单介绍了cgroup概念,重点阐述了cgroup作用于yarn container的实现, 并例举唯品会在使用cgroup上遇到的一些问题。后续针对这些问题,我们会持续投入进行优化。最后也希望这篇文章能对在yarn集群使用cgroup有一定借鉴意义。
推荐阅读:【唯实践】CapacityScheduler在唯品会的迁移及应用
“唯技术”一档专为唯品技术人发声的公众号
欢迎投稿!!
只要是技术相关的文章尽管砸过来!

