




RDP简介
高可用、低延时、可追溯的MySQL数据订阅基础组件
RDP的全称是Real-Time Data Pipeline,是一个从关系数据库MySQL实时同步数据到NoSQL系统的数据管道。正如这个名字一样,RDP不生产数据,只是数据的“搬运工”。谈到数据传输管道,有几个基本的特性是使用方最关注的:
可用性:也就是系统可以对使用方提供什么样的SLA。在系统所承诺的SLA之外,使用方可以通过自己额外的设计、Workaround来达成它们自己对其它系统(或者业务指标)的SLA承诺。
实时性: 作为搬运工,”送货“时效如何?系统使用方注重总体端到端的延时。系统开发者,除了端到端,我们还关心每一个环节的延时,以及各个环节间交互是否合理、是否高效。
追溯性: 作为“管道”,爬进管子里面去调查问题,或者凭经验规律揣测,显然都是比较不友好的体验。比较理想的状况是系统通过自证和他证两个方面,来达到可以让系统使用方、系统维护者可以轻松准确地找到问题所在。
高可用、低延时和可追溯是RDP的主要特性。本系列我们将分三个片段来分享我们在设计/实现RDP的过程中,所遇到的困难和解决方案,让更多人了解这个组件,也期望为业务系统带来便利并产生价值。RDP还在不断迭代,团队也在不断地努力学习,我们虚心倾听大家的建议、需求和吐槽~~~
RDP之高可用篇
本文是RDP介绍系列的第一篇,我们首先从RDP团队理解高可用的视角,来分解RDP中关于高可用部分的设计及关键实现。在我们的理解中,高可用意味着两个维度的含义:系统的持续服务能力和服务的质量。
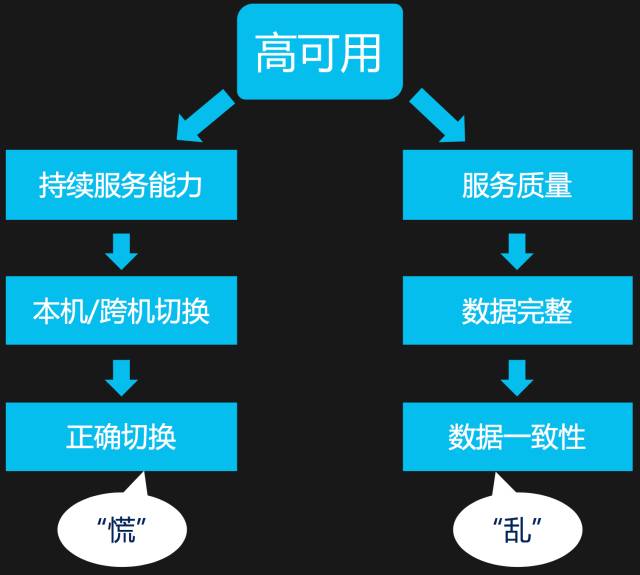
图:高可用特性分解
持续服务能力比较容易理解,也比较切题,就是RDP要尽可能地缩短别的系统用不了的时间、降低使用不了的概率。服务质量是在持续服务的基础上附加的一些基本要求,比如服务提供出来的数据不能错、不能乱。通俗地说,我们就是要解决系统不可用时“慌”(因为不知道发生了什么)的问题,以及数据不一致所带来“乱”(因为不知道怎么办)的问题,紧接着我们分开来讲这两点。
RDP如何解决数据一致性的问题?

我们先来讨论一下RDP中如何处理数据一致性问题。首先RDP作为数据管道,其依赖的基础还是MySQL主从复制机制,而MySQL主从复制原理的方法学,其实是一种Log Ship的方法。如下图所示:
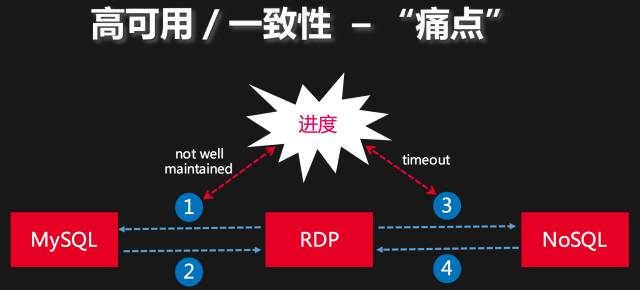
图:一致性(数据质量)的痛点
我们把数据管道的工作分解为四个步骤,分别是:
1、RDP以某个进度信息作为同步数据的“开始位置”,向MySQL发起Dump请求;
2、MySQL从请求的位置开始,将Binlog发送给RDP;
3、RDP解析收到的Binlog,打包并发送给下游的NoSQL系统;
4、NoSQL系统收到数据并处理后,回应给RDP进程。
这样一来我们很容易看到,步骤2和步骤4都是比较稳定和成熟的技术环节,所以如果一个数据管道的数据出现了一致性问题,那么通常都会发生在步骤1和步骤3,而步骤1也是遵循MySQL复制协议的,所以协议层面也不会存在问题,那唯一可能出现问题的点就是我们告诉MySQL的“开始位置”不对。同样的道理,步骤3中,下游系统的API通常都是成熟稳定的实现,唯一可能出现问题的点是API返回了timeout状态,这种状态下,NoSQL系统可能已经成功处理了请求,也可能并没有成功处理请求。这类问题在分布式系统中是常态,也是一个我们必须要面对的问题,因为分布式系统本身就是建立在一个异步通讯模型的基础之上。
在理清问题的关键所在之后,RDP就比较容易对症下药。RDP定时将已经成功提交到下游NoSQL系统数据的GTID集合和下游系统中这个GTID集合数据对应的Offset作为一个Checkpoint,存储到分布式存储系统中,我们的实现中这就是Zookeeper。在RDP恢复的过程中,我们首先从Zookeeper中找到最新的Checkpoint,从Checkpoint中的Offset位置开始,扫描数据直到最后一条数据。在扫描的过程中,把数据中包含的GTID累计到Checkpoint中的基数GTID集合。通过一轮扫描,我们就得到了下游NoSQL系统已经成功处理的完整数据集合,以这个集合作为本次请求的“开始位置”。如此以来,无论RDP进程在何种情况下退出,也无论退出是否优雅(是否对一些信息进行了正确的持久化操作),都不会破坏数据的一致性。
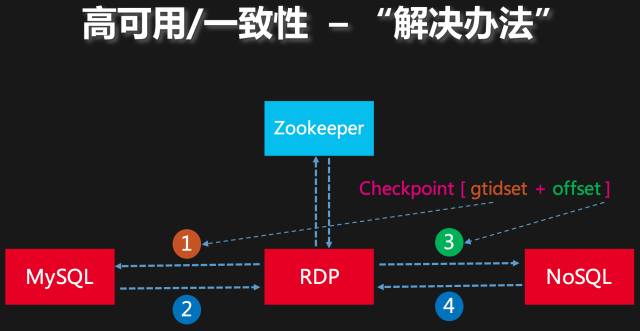
图:一致性的解决办法
RDP如何正确切换?
如何正确切换,这个话题已经被讨论很多次了,如下图所示,比较主流的解决办法就是:通过在多个节点部署多个实例副本,副本间通过分布式的协调服务来进行Leader Election。
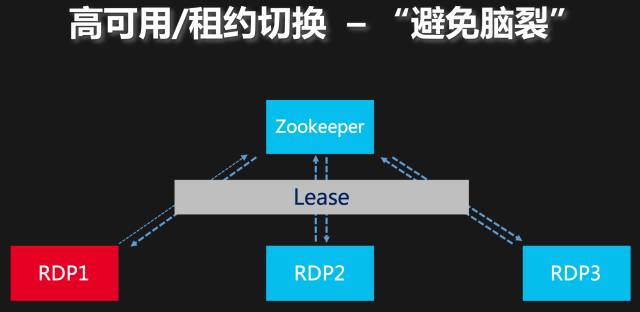
图:避免脑裂的常规手段
我们也是采用Zookeeper的Session timeout机制来实现Leader Election。比如Zookeeper Session的timeout设置为N秒,Zookeeper C API在2*N/3时间范围内无法向Zookeeper Server成功发送并收到heartbeat回应,C API就会触发通讯异常的callback。RDP进程会在收到这样的异常callback后,“敏感”地退出进程。这里我们也不考虑退出是否优雅,前面已经提到过,结合Checkpoint和Crash recovery手段,不论RDP进程退出时是否持久化了必要的进度信息,都可以保证数据的一致性。当然Zookeeper Server对这个Session授予的Lease还是N秒,N秒到期后Zookeeper Server才会删除相应的临时ZNode,进而其他RDP Follower进程收到callback触发选主流程。
从上面的分析可以看出,只要旧Leader进程在N/3秒时间内完整地退出,那么这个基于Zookeeper的Leader Election流程是没问题的。但是除了这个前提,还有一个前提是RDP进程所在节点和Zookeeper Server所在节点的时钟不会出现极端的偏差或跳变,因为本质上说,所有基于Lease和timeout这类手段的故障检测,其实都对时钟的偏差和跳变做了一些假设,才能推导出最终的正确结论。下面举一个GC可能引起“多主”的具体例子:
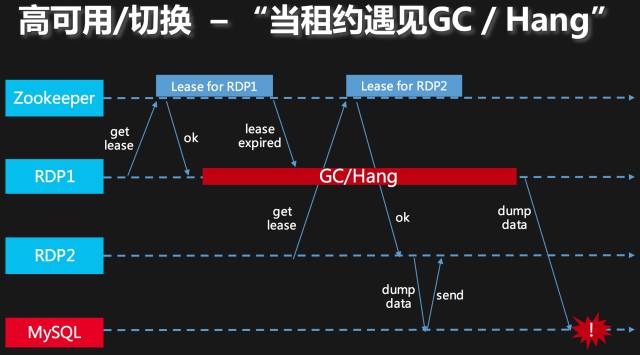
图:常规分布式锁服务的不足
如上图所示,由于GC/hang/其他IO调用异常(我们无法避免一次刷盘、一次网络IO调用阻塞这些极端情况),一个旧Leader可能会踢掉正确的Leader,也可能新旧Leader同时对一个资源进行读写,这样数据的乱问题一定会出现(RDP中,从MySQL拉取数据的进度乱了,发到下游系统的消息自然也就乱了)。但我们清楚,在这个问题中,我们的共享资源是MySQL数据库,Fencing的方法就是我们在MySQL内核内置一个Fencing Token,这个Fencing Token只允许从小变大,在RDP和MySQL数据库建立主从复制的过程中,我们使用每一个Leader Election周期的epoch作为自己的Token。而基于Zookeeper Session Timeout的选主中,每一个Leader Election周期都会递增ZNode的CVersion,我们把这个当作选举周期的epoch。
问题理到这里,我们的方法也比较简单:我们信任Zookeeper,但不完全依赖,RDP自己再做一些验证,来确保无论遭遇系统级别异常还是时钟极端偏差和跳变,RDP依然可以正常工作。具体的方法就是Fencing,Fencing在传统的共享存储体系用于共享资源的互斥、Apache HDFS NameNode HA实现、Apache Bookkeeper中都有应用。具体方法描述如下:
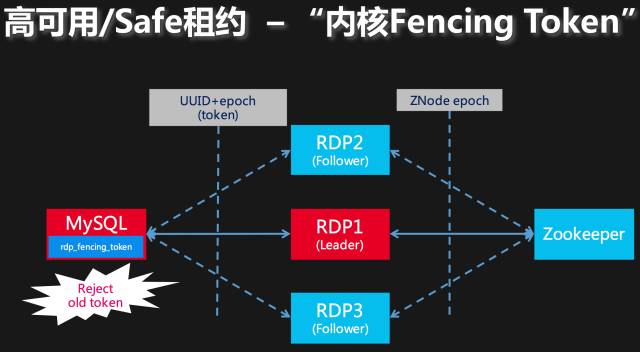
图:解决管道“上游”的方法
部署在多个节点的RDP进程使用同一个UUID作为MySQL Slave和MySQL集群进行Binlog的拉取,因为在MySQL内核实现中,同一个UUID只允许存在一个Dump线程,这从大方向上保证了不会有多个RDP进程消费同一个数据源的情况。也就是“脑裂”时不会存在多个RDP Leader。通过这个方法,我们做到了,无论“脑裂”,时钟频率极端差异,RDP进程所在节点IO异常等情况,最多只有一个RDP进程在消费MySQL数据源,也就避免了“多主”消费同一个数据源的情况。
但是很遗憾,到目前为止,我们只解决了RDP数据管道入口端的“多主”问题。出口端的“多主”问题如何避免呢?最理想的情况是下游系统也具备某种Fencing功能,我们附带着全局单调递增的Token下去就万事大吉了!可是我们生产上主流的下游NoSQL,无论Kafka、Redis还是Memcached,Fencing功能要么不具备,要么不完善。这是我们在RDP出口端解决“多主”问题的最大挑战,目前我们并不完美的解决方法是:
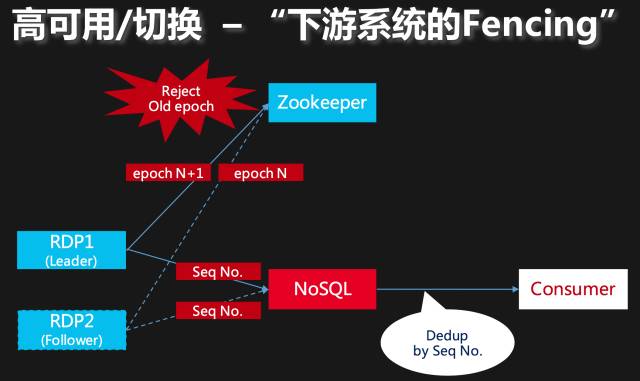
图:解决管道“下游”的方法
每一个RDP消息附带一个全局的Sequence No.(Msg ID),这样消费者可以通过Sequence No.来去重,去重后至少解决了数据乱序的问题。这个全局的Sequence No.并不随着某个RDP进程的重启而清零,前面提到过我们的Crash recovery流程,这个过程中RDP不仅会找到已经正确处理的数据GTID集合,同时还会找到已经处理过数据的最大Sequence No.。去重是有代价的,如何去降低这个代价呢?RDP会周期性地对数据处理进度做Checkpoint,在做Checkpoint的时候,我们使用Checkpoint ZNode节点的Version来做Versioned Update操作(Zookeeper的setData方法),同样也是不允许低Version覆盖高Version。出现这种失败,说明出现多个RDP进程在往下游系统写数据,Versioned Update操作失败的进程应该立即验证自己是否是新的Leader(判断自己持有的Leader Election CVersion和当前选主ZNode的CVersion是否匹配),旧Leader应该立即记录日志并退出进程(同时触发告警)。我们并没有选择降级RDP进程为Follower,而是简单地直接退出进程再重启,将这个问题简单化。通过这些手段,我们算是完整地解决了数据管道生命周期中所有可能出现的“多主”情况,在这些情况下RDP也可以正确工作并恢复到一致的状态。
本篇总结
总的来说,RDP通过内置MySQL内核Fencing Token功能、更新Checkpoint时使用Checkpoint ZNode的CVersion来做Versioned Update来判断是否出现了多主的情况、消费端按全局Sequence No.只增不减(可以等于)的规则来去重这三个手段,确保了无论硬软件故障/环境如何,整个系统的高可用得到了比较有力的保障。也就是回答了如何正确切换的问题,同时还保证了数据服务的质量!值得注意的一点是,在下游系统中,可能出现具有相同Sequence No.的消息,其内容是相同的,但epoch不同,下游系统可以简单地根据Sequence No.来去重。所以也可以得出另外一个结论:在让系统做自动化failover的前提下,要让一个数据管道或者消息系统提供exactly once语义,是十分困难的。有很多书籍讲到系统实现exactly once语义,其实有一个假设是每一个唯一的Client ID只会有一个进程实例副本在运行,但实际上在分布式环境中,这个假设有时并不成立,甚至很难保证。
下期预告
RDP之“实时性”
篇
唯品会支付轻量级前后端分离 – lite

Spark在唯品会财务系统重构中的实践总结
“唯技术”一档专为技术人发声的公众号
欢迎投稿!!
只要是技术相关的文章尽管砸过来!

