




目前容器数据库平台在测试环境、开发环境的规模已经增长到了一千多台物理机节点,近两万个数据库及其他类型容器,主要有以下几个技术痛点:
l K8s集群数量多
l 监控项多
l 监控实时性要求高
当前Prometheus已经成为云原生监控的最佳实践,但面临跨k8s集群的多套Prometheus监控,还是需要进一步的提高监控体系的规模化管理能力,因此,数据库容器云平台最终选用了Prometheus-operator 管理多套Prometheus的技术方案;
Prometheus是CNCF基金会开源的一套云原生监控系统,其核心为Prometheus-server,通过TSDB时序数据库存储数据;通过刮取(scrape)的方式,从各种符合规范的exporter中获取并存储数据;使用rules规则实现告警,并通过AlertManager进行告警管理和告警信息推送;使用Grafana进行数据图表展示。
Prometheus 的整体架构以及生态系统组件如下图所示:
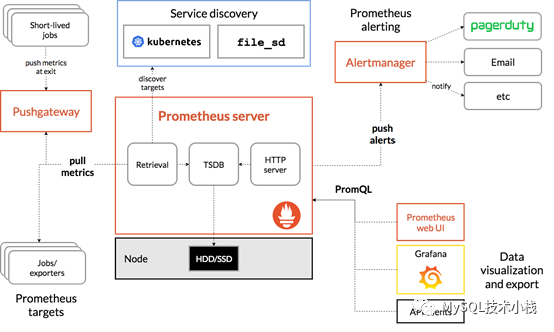
1、灵活的数据模型:在 Prometheus 里,监控数据是由值、时间戳和标签表组成的,其中监控数据的源信息是完全记录在标签表里的;同时 Prometheus 支持在监控数据采集阶段对监控数据的标签表进行修改,这使其具备强大的扩展能力;
2、强大的查询能力:Prometheus 提供有数据查询语言 PromQL。从表现上来看,PromQL 提供了大量的数据计算函数,大部分情况下用户都可以直接通过 PromQL 从 Prometheus 里查询到需要的聚合数据;
3、健全的生态:Prometheus 能够直接对常见操作系统、中间件、数据库、硬件及编程语言进行监控;并对Kubernetesd原生支持,可以原生实现服务发现、自动纳管等功能;
4、良好的性能:Prometheus 提供了 PromBench 基准测试,从最新测试结果来看,在硬件资源满足的情况下,Prometheus 单实例在每秒采集 10万条监控数据的情况下,在数据处理和查询方面依然有着不错的性能表现;
5、更契合的架构:采用推模型的监控系统,客户端需要负责在服务端上进行注册及监控数据推送;而在 Prometheus 采用的拉模型架构里,具体的数据拉取行为是完全由服务端来决定的。服务端是可以基于某种服务发现机制来自动发现监控对象,多个服务端之间能够通过集群机制来实现数据分片。推模型想要实现相同的功能,通常需要客户端进行配合,这在微服务架构里是比较困难的。
Operator 是 Kubernetes 的扩展软件,它利用CRD(定制资源)的方式管理应用及其组件。相较于Helm,operator更适合用于部署复杂性较低,但数量较多的有状态 应用,例如ETCD-operator、mysql-operator都是业界内成功的operator实现;
Prometheus-operator是针对Prometheus开发的一套operator,其主要功能是实现了Prometheus的配置和rules等配置的对象化,将Prometheus体系的各种配置通过kubernetes中的crd对象或secret对象注入到容器化运行的Prometheus中;
Prometheus-Operator的架构图如下:
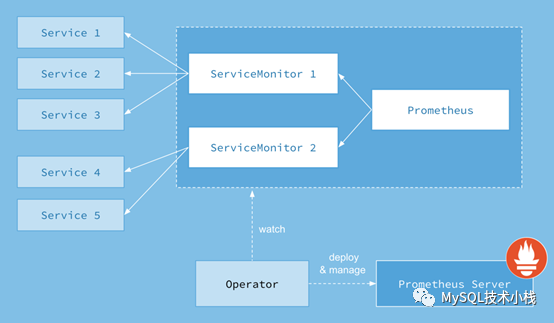
Prometheus-operator主要是通过servicemontior等crd对象实现配置注入;因此Prometheus-operator适合用于多套k8s集群的Prometheus监控;
1、配置解耦:只需要使用k8s api对特定的crd对象进行修改和维护,即可免重启维护多套k8s中的Prometheus;
2、配置分离:可以将多种复杂的配置,通过不同的crd对象进行维护,实现监控配置分开管理,适合大规模集群下的多对象监控;
3、自动管理:可以实现对Prometheus的自动管理;

运行Prometheus-operator
参考Prometheus-operator项目(https://github.com/prometheus-operator/prometheus-operator),需要执行相关的crd定义文件、rbac权限配置、deployment即可运行Prometheus-operator ,过程较为复杂,不在赘述。
运行Prometheus-server
Prometheus-operator使用Prometheus对象定义每套Prometheus,定义多个prometheus对象,可以实现同一套operator管理多套Prometheus;同时,还需要对相应的rbac进行授权,Prometheus才能正常运行;
Prometheus-scrape-config配置注入
Prometheus-job通过两种方式注入Prometheus,这两种方式均符合Prometheus默认的job定义格式,只是注入方式有所不同
①使用ServiceMonitor自定义crd对象进行注入,以Prometheus监控为例,servicemonitor定义如下:
将该对象apply到Kubernetes中,Prometheus-operator会自动将该配置注入到Prometheus的config中;
②Prometheus对象中的additionalScrapeConfigs字段,通过配置名为auto_discover_exporter.yaml的secret对象,将文件注入到Prometheus的config中;该配置文件定义在Prometheus对象中;
Prometheus-rules注入
rules通过PrometheusRules自定义crd对象进行注入,管理rules告警规则时,可以将不同的监控对象的告警规则定义成不同的对象,下面以ETCD告警为例:
将该配置apply到k8s中,rules会被Prometheus自动注入到Prometheus的rules配置;
Prometheus-operator高可用
Prometheus-operator使用deployment部署,当liveness探针或Readness探针探测到Prometheus-operator容器运行出现问题,则会kill掉旧的pod,自动启动新的pod,实现operator的高可用;
Prometheus高可用
由于Prometheus的TSDB时序数据库并未实现分布式方案,因此,Prometheus的高可用只能使用多副本方案实现高可用,即运行两个配置完全相同的Prometheus-server实例,并分别从exporter中刮取数据进行保存;
实际上,这种对等多副本的方案并不是一个完美的解决方案,因为刮取周期可能略有不同,因此记录的数据可能略有不同,这意味着相同指标相同时间点的值可能略有不同。但是由于告警是对周期时间的监控值进行判断,所以告警不会受到太大影响。
而且,运行N个副本,exporter的被访问次数就会提高N倍,对网络带宽占用也会变大,因此,生产环境中一般使用2副本Prometheus-server。
AlertManager高可用
alertmanager的高可用原理非常简单,就是通过各个节点暴露出来的端口来交换自己机器上收到的报警请求,看看是不是有重复报警。Alertmanager引入了Gossip机制。Gossip机制为多个Alertmanager之间提供了信息传递的机制。确保及时在多个Alertmanager分别接收到相同告警信息的情况下,也只有一个告警通知被发送给Receiver。
1、不同模块监控数据的同义label统一定义,这可以高效率进行后续的告警等开发;
2、复杂的指标可以编写成record,占用少量存储空间,节约大量内存使用空间;
