2020年对于国产数据库行业来说是个大年,各种数据库大会上国产数据库已经当上了主角,传统商业数据库Oracle虽然还占有较大的市场份额,而且技术确实领先,但是业内谈及和关注度都在下降。分布式数据库在国内蓬勃发展,是有可能实现弯道超车,逐步替换掉国外商业数据库产品的。
在这么一个背景下,阿里系,腾讯系、华为系、PingCAP系等等都祭出自己的神器,试图在金融级业务场景中分的一杯羹。
因为金融场景是联机交易关系型数据库的必争之地,能够完美适配金融业务场景,那么其他交易型场景都能够轻松适配。
金融场景对数据一致性(C)和可用性(A)要求极高,换句话说就是不能丢数据,发生故障时要最快时间恢复业务,终极目标是能做到RTO=0 & RPO=0。这里就有一个矛盾,CAP理论证明了,发生P时,无法同时满足CA,那么分布式数据库在解决CAP难题时,一定会有取舍。
另外一个背景是主机(390\400)在金融行业中会逐步下迁之开放平台,不同的银行玩法也不尽相同,有的银行采用业务逻辑不变,通过转码的方式,将主机上的代码转换为Java,跑在开放平台;有的银行采用微服务框架进行重构和重写,将复杂的逻辑解耦合,化整为零。
第一种方式还是之前的模型,所有业务场景大集中,这里就非常考验底层数据库的能力,因为单库容量是有限的,以MySQL为例,超过500GB一般就会进行分库;这时候分布式数据库的价值就体现出来了,可以弹性伸缩,维护简单。
第二种方式采用是微服务模式,采取应用层面的分布式,因此天生就具备扩展性,每个微服务数据库是独立的,微服务内部也会采用分库分表策略,但是微服务拆分带来的维护工作量比第一种方式要高,好处也很明显,鸡蛋没有放在一个篮子里。
金融行业关系民生大计,安全可控相对其他行业要求更高,也是触发金融行业多方考察国产数据库的原因。
基于上述背景,我这里从三种架构来阐述分布式数据库选型的考虑点,这里不会去评价国产数据库,而是从数据库内核和使用角度来分析。
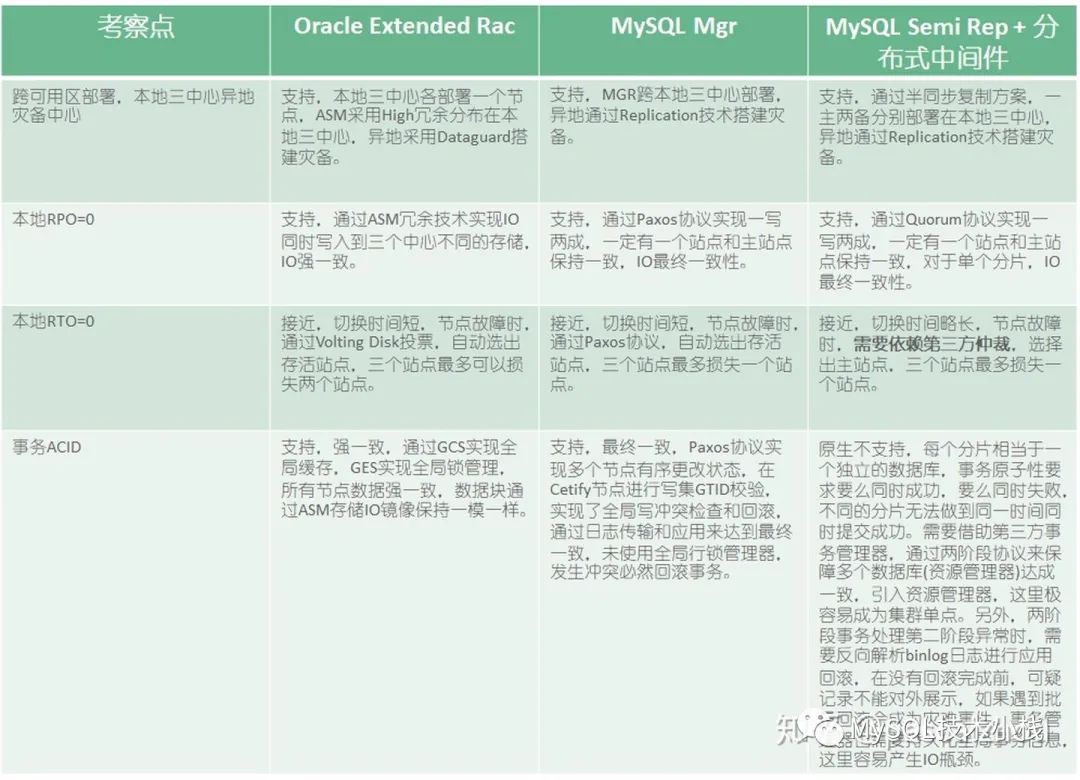
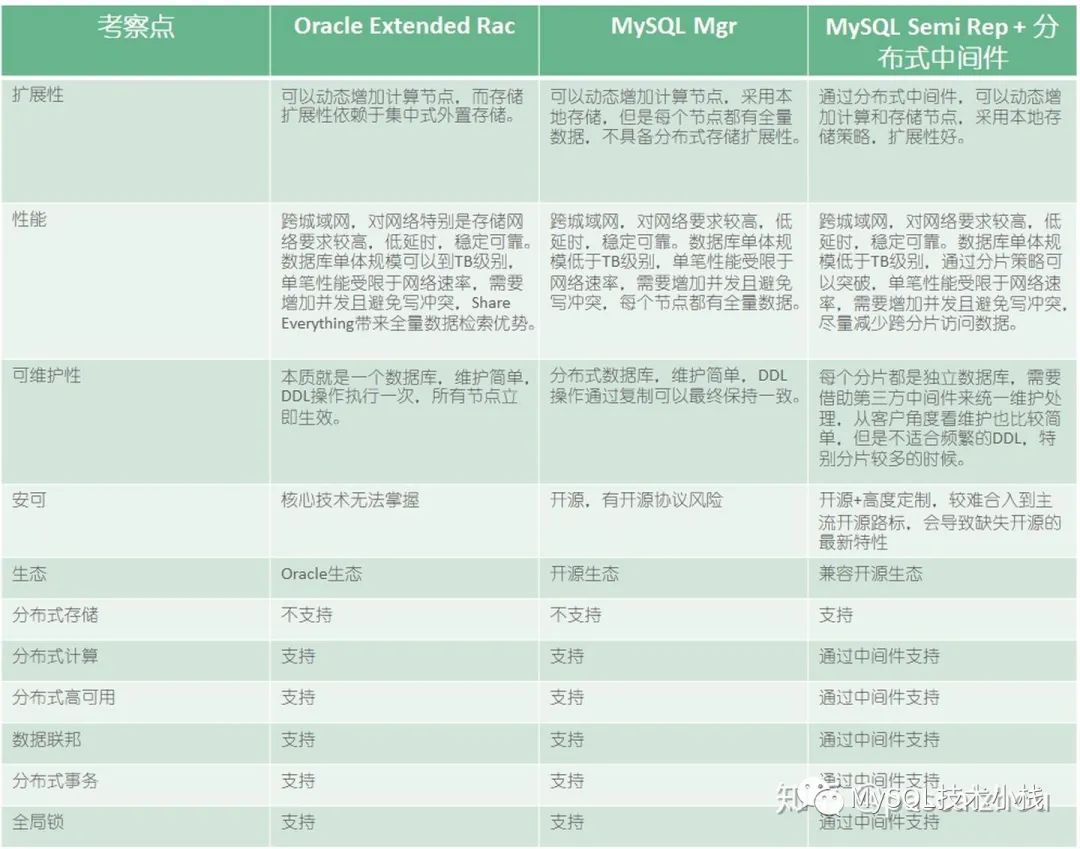
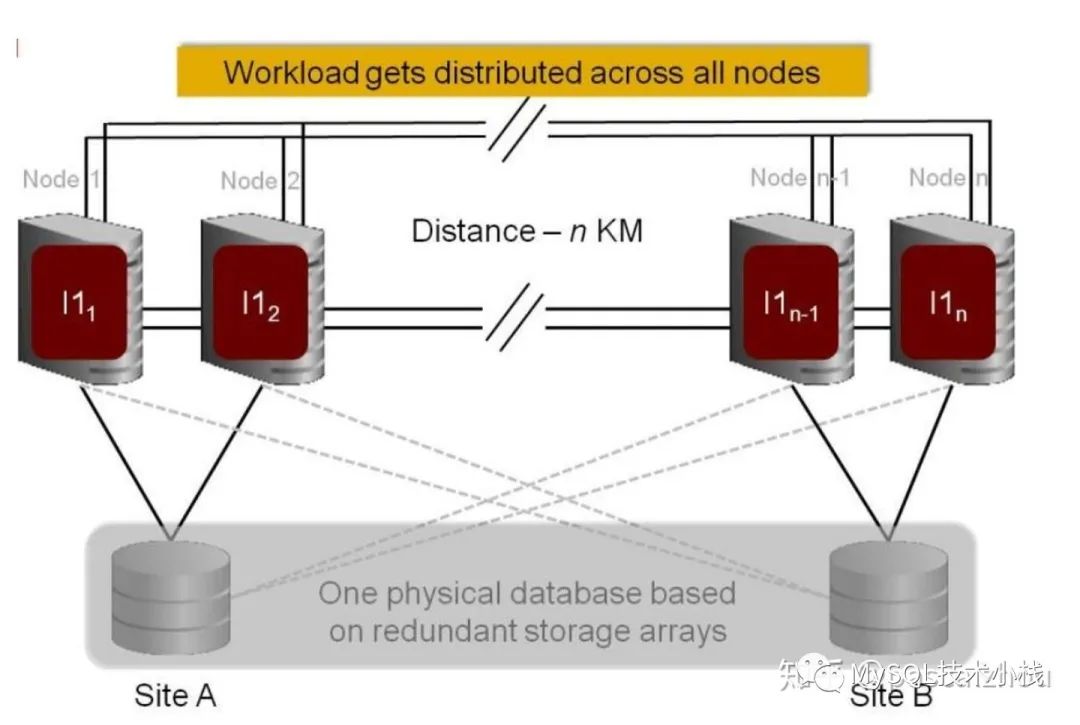
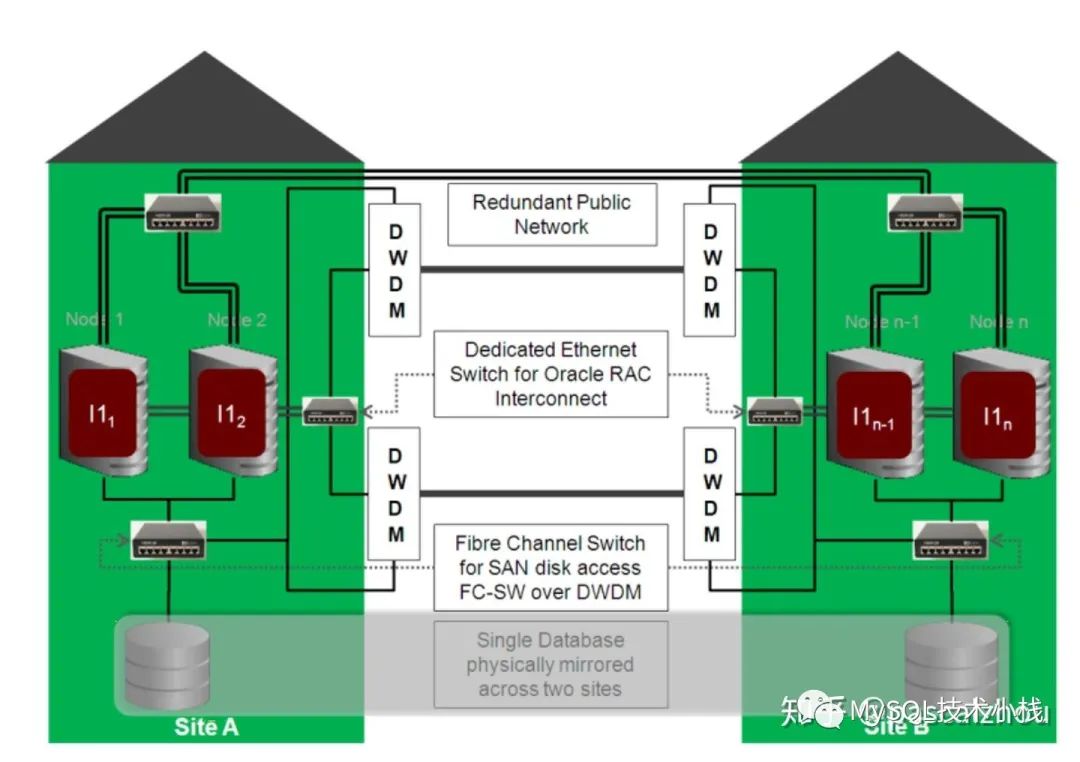
架构一:Oracle Extended RAC,追求CA。
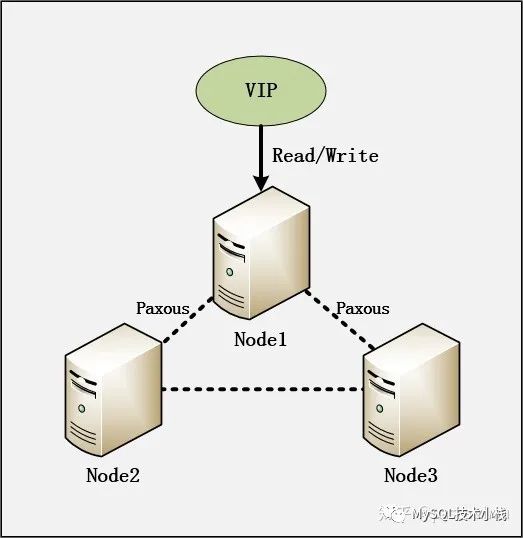
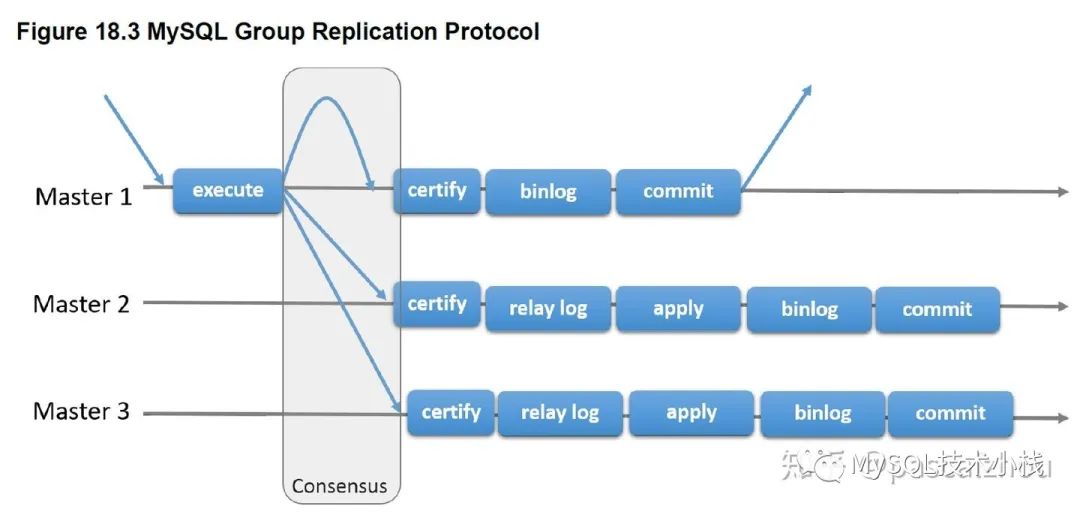
架构二:MySQL MGR,追求CA。
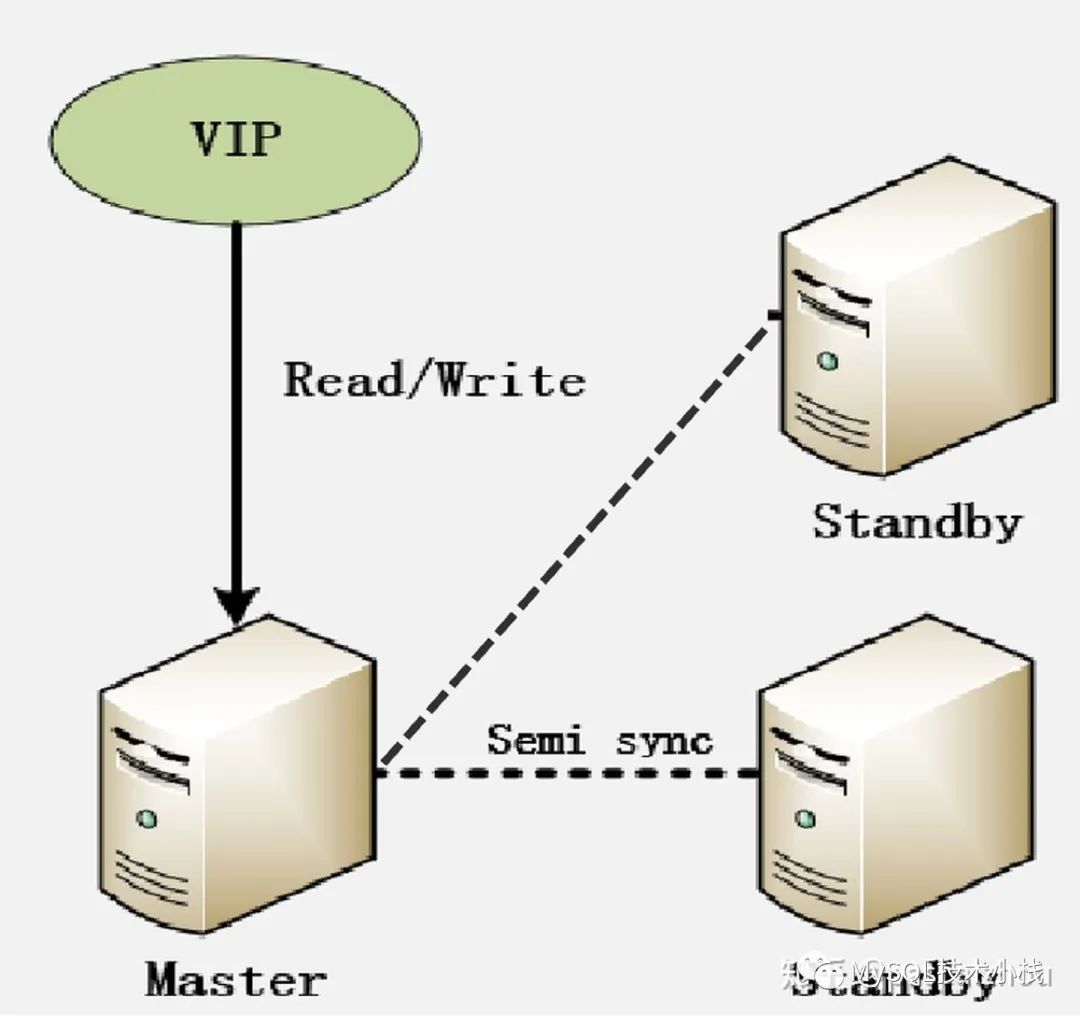
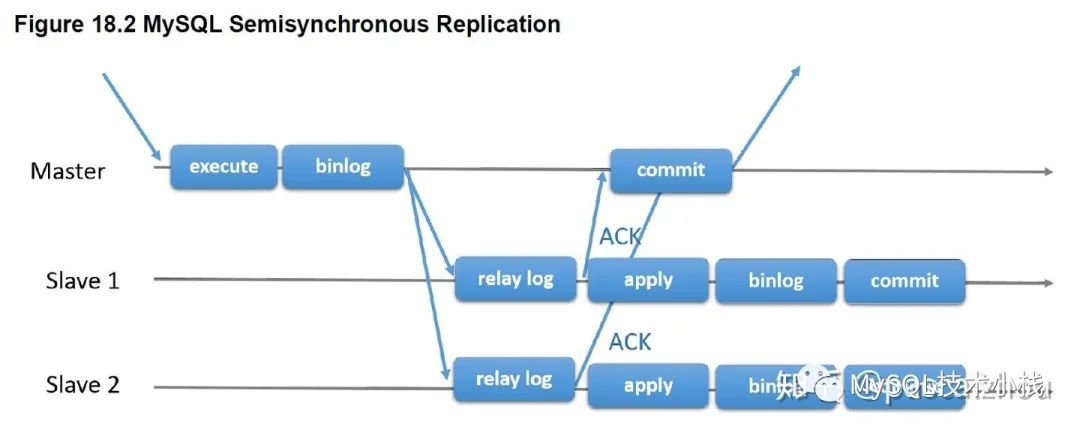
架构三:MySQL半同步+分布式中间件,追求AP。
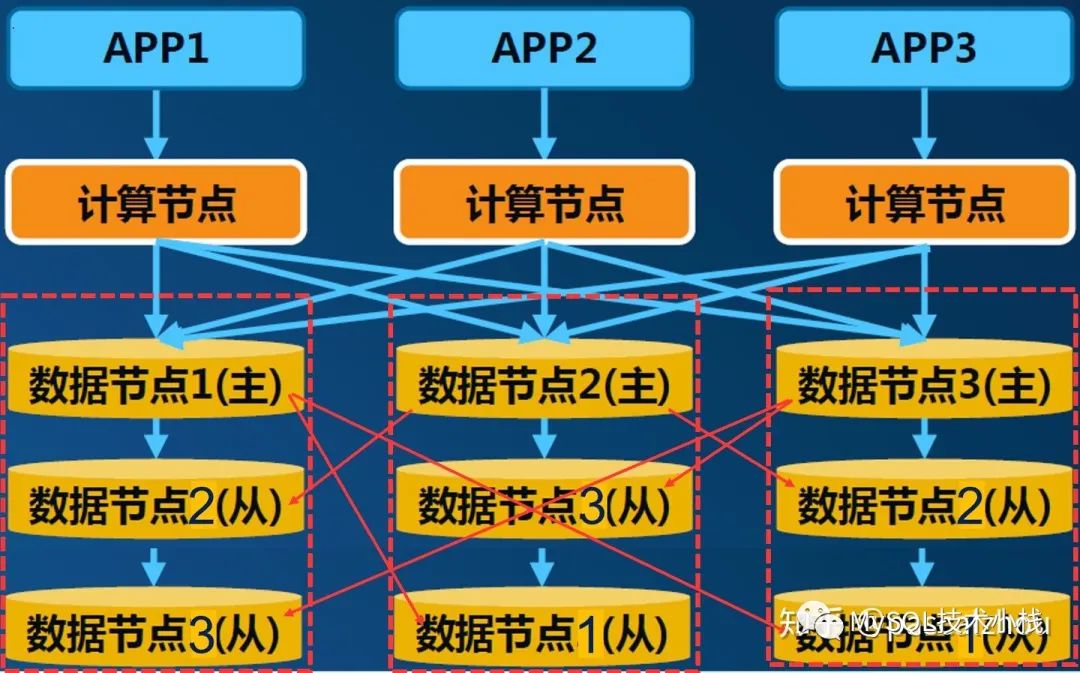
各架构考察点如下: