排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
首页
/
Prometheus和AlertManager规则和告警
Prometheus和AlertManager规则和告警
小张的科学日记
2020-11-01
1208
Prmetheus代码可读性还是很高的,高内聚低耦合,并且除了tsdb外的component代码量都不大,了解后进行二次开发的难度很低,再仔细想想tsdb也就是个列式存储,还是可以战略上藐视一下的。
因为我们现在用的prometheus是在2.16基础上添加了一点feature,也引入了一些问题,在处理这些问题的时候过了一下prometheus和alertmanager的告警流程。
考虑到罗列代码会影响可读性,这次写的抽象一些。
背景
prometheus不支持remote rule,只能修改文件然后reload,这种方式主要是不方便,看起来不那么时尚。
规则组对应的manager的ApplyConfig方法(之前写过prometheus的各个component,每个组件都有自身的ApplyConfig方法供reload动作使用)中,本地文件规则组(即配置文件)来源下并列提供了一个http的来源,并启动协程定时更新规则,当然现在的实现也是存在问题的,每次调用reload就会启动新的协程,我们也可以使用一个标志位避免这种情况,但是最好还是和现有discover机制结合起来,实现无缝合感的feature新增。
简述下这次异常,是当修改规则提高告警阈值的时候,旧有的告警发出了一封恢复邮件,期望是这种告警恢复静默掉,原因初步判断是在新旧规则组交替时,继承旧状态(copyState)的问题,基本能确定是设计如此,但还是跟踪一下。
只是大致写一下,很多细节,很多配置,比较枯燥,都用注释标注,有时间发个注释版代码链接。
先启动规则组件
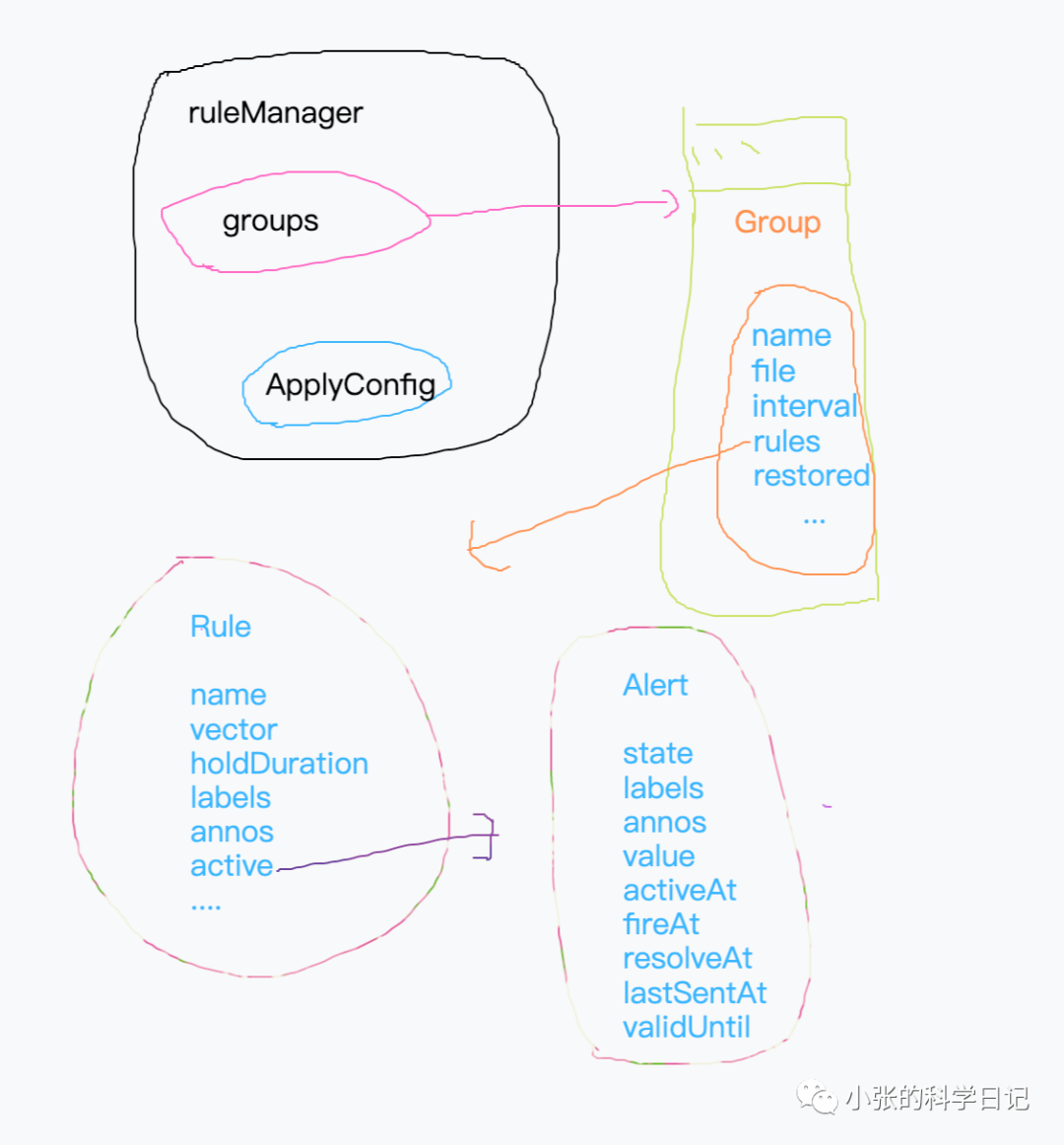
规则部分核心实体就这几个,其流程一目了然,在Prometheus启动后创建ruleManager,之后通过ApplyConfig方法,将我们配置文件中的规则组定义变成如上图所示的具体对象。
之后manager管理groups,负责group的增删变化等,每个group启动后固定interval时长调用Eval方法计算告警,Eval则会遍历调用自身持有的所有rule的Eval方法,rule的Eval方法使用一个即时查询找到满足自身规则的结果,处理这些结果产生Alert(这时候用的label和annotation都是此时的rule的),放到active中,这些刚产生的Alert状态都是pending,后续经过一些处理才会发送到alertmanager。
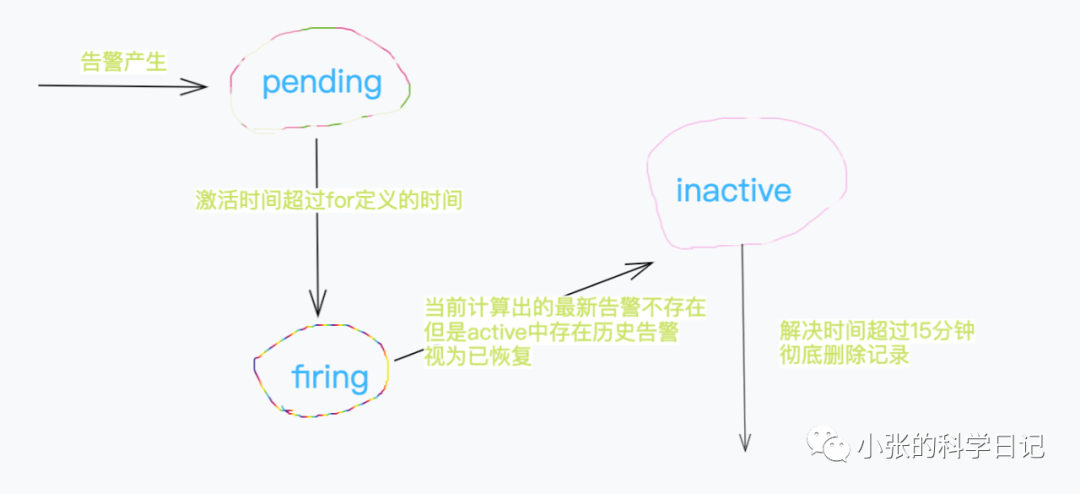
告警状态的变化
发送告警到AlertManager
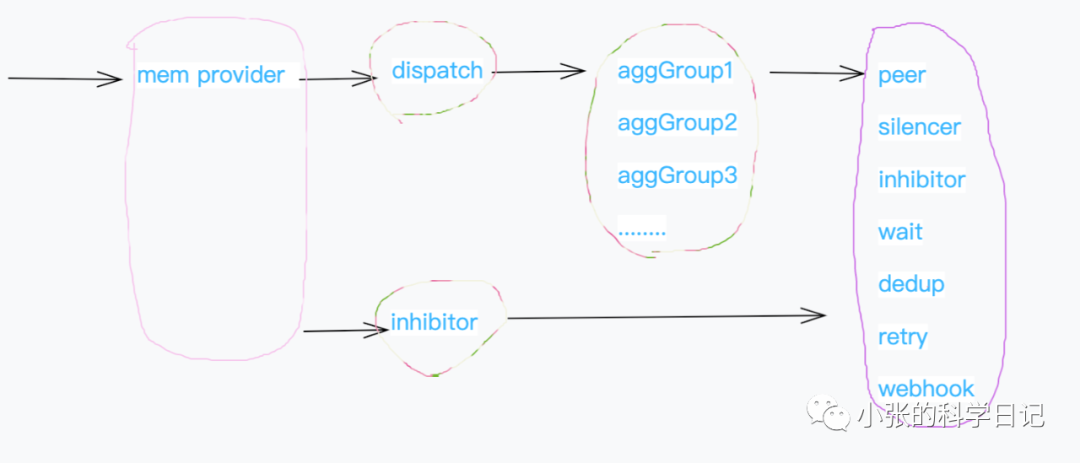
对于firing以及resolved状态的告警,就需要通知notifierManager这个组件发送给AlertManager了, 可视为一次http调用。
alertManager接收这些报警,并通过内存的provider保存到内存中,然后通知所有的listener有新数据来了(就是放到channel中,listener监听channel),这里可以实现不同存储的provider来做告警的持久化。
dispatch就是其中一个listener,也是最重要的一个,它根据我们定义的route,将alert分配给对应的aggGroup,由aggGroup对alert进行集群、沉默、抑制、发送等操作。
最后
问题就比较清楚了,我们修改后的新规则copy旧规则的状态的时候,将active即激活告警列表也原样拷贝了,所以产生一次恢复,并且active中alert的annotation仍然是旧规则的annotation,数据有一点偏差,看起来是设计如此,但因为我们业务原因,就不能原样拷贝了,而是需要在拷贝的时候做判断,将不满足条件的丢弃,
同时也需要将alertmanager中aggGroup保留的状态清理掉,暂时清理规则想的是2 * interval < endat < time.now(),可以保证这条告警确实是无效的而不是恢复的(不确定,看代码实现是需要删除aggGroup的缓存,测试反馈不用删除,后面再确认,天色已晚)
,或者从业务上做处理更简单。
数据库
文章转载自
小张的科学日记
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨