





pika在DataVisor的选型及落地
随着DataVisor业务发展越来快,接入的客户越来越多,流量越来越大,之前的数据库在读写性能方面出现了比较大的衰减,已经无法满足业务的需求。所以开始选型新的数据库作服务升级。
我们对数据库的需求
需要存储海量数据,单库需要亿级到百亿级。
数据没有明显的冷热分布,具有随机访问的特性。
部分数据需要自动ttl。
数据查询超时p99不可超过100ms。
在选型数据之前我们做了几个数据库指标的定义
支持海量数据的持久化。
支持数据类型自动ttl。
需要支持KV存储。
在数据量超过内存大小之后仍然可以保持较好的性能。
数据库对系统资源占用可控。
最好是采用非GC语言编写,防止出现不可控的停顿。
方便使用的driver和便于理解的数据结构。
经过长时间稳定运行考验。
在环视一周市面上的KV存储数据库,pika这个数据库开始映入我的眼帘。综合看了pika各种测试指标和在社区内部与其他小伙伴的咨询探讨觉得pika就是我想要的数据库。
虽然我在2016年就了解关注过一段时间的pika,但是由于个人职业方向的变化,对于pika后续的发展并没有继续投入时间和经历做持续关注。本次再次将目光投向pika着实有一种陌生的亲切感。
选型测试
接下来我们就讲一下我们如何做数据库的对比测试。主要考虑以下几点。
测试数据库在不同数据负载下写入读取tps
测试服务卡在不同数据负载下写入读取的latency
测试不同大小value在系统中的表现。(根据实际的业务需求制定)
测试环境
CPU 4 Cores
Memory 16 GiB
SSD: Aliyun ESSD 300GiB (16800IOPS, 200MB/s)
写入测试,value 4KB
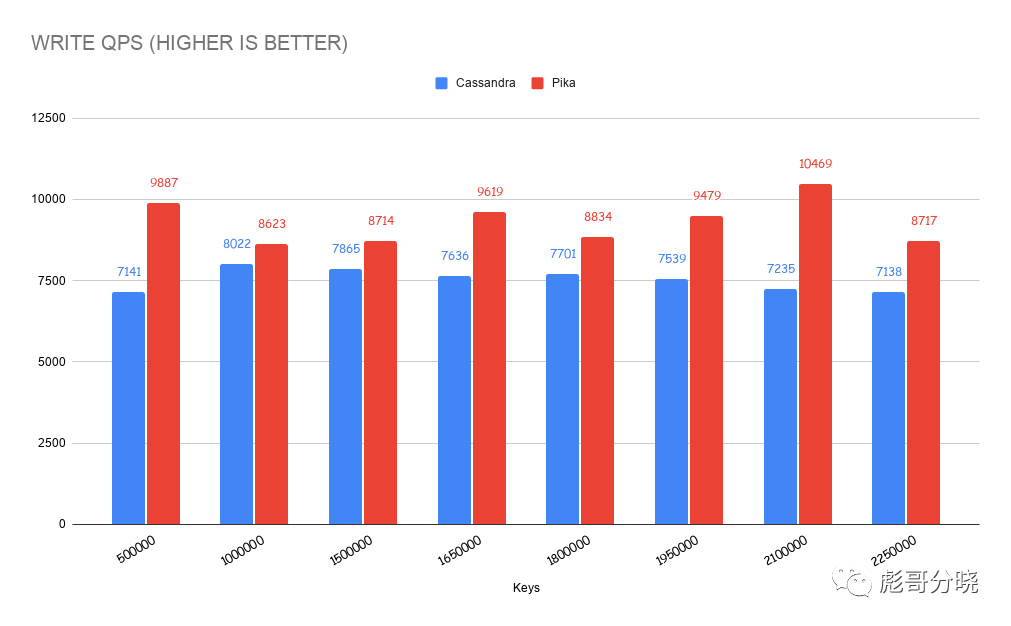
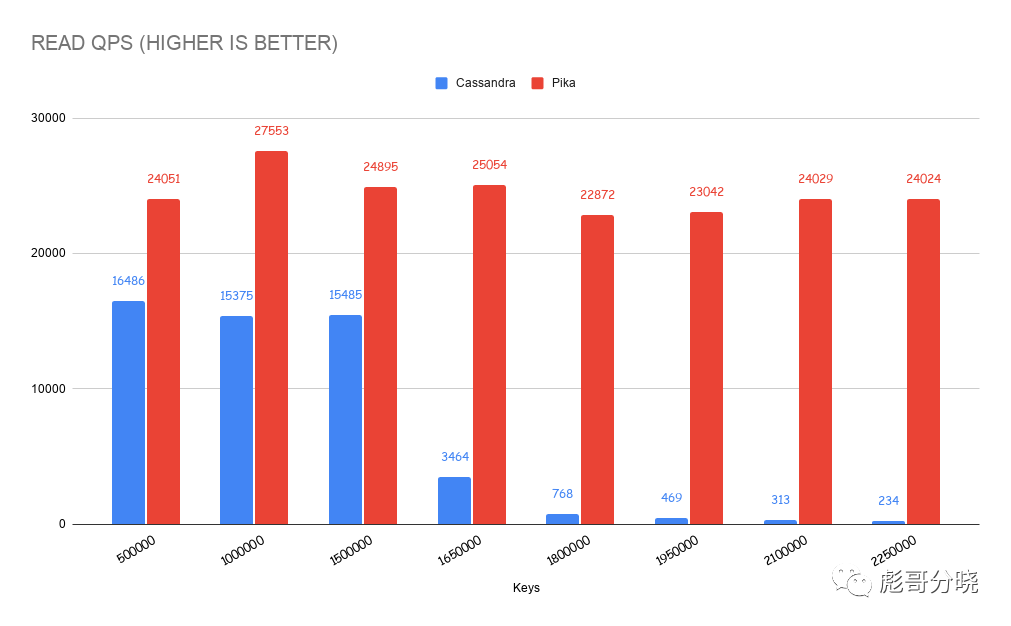
读取测试,value 4KB
其中在数据量超过1500K 的时候cassandra的读性能出现了明显的下降。甚至衰落到了只有几百tps的量级。继续看lantency的图可以看出在同样的时间节点cassandra latency也开始变高。究其原因是因为数据在这个节点时超过了机器所在内存大小,导致了数据无法被系统cache住,系统开始做大量的数据换入换出。理论解释可以参考《BPF之巅》这本书的一段描述。
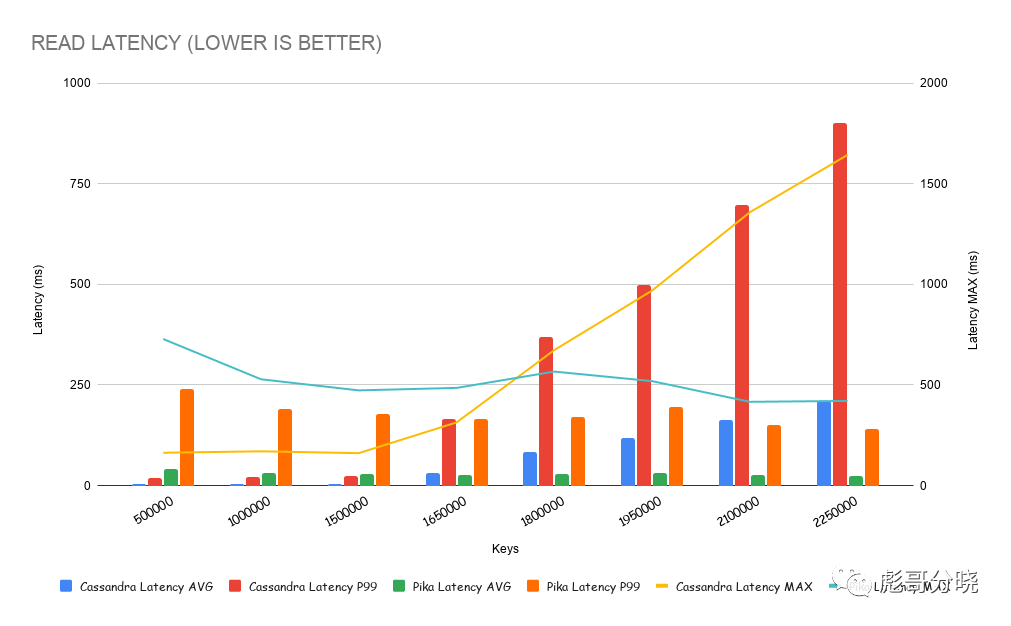
ps: 《BPF之巅》这本书还是挺不错的,适合拿来垫显示器哦!
local-ssd vs 云盘
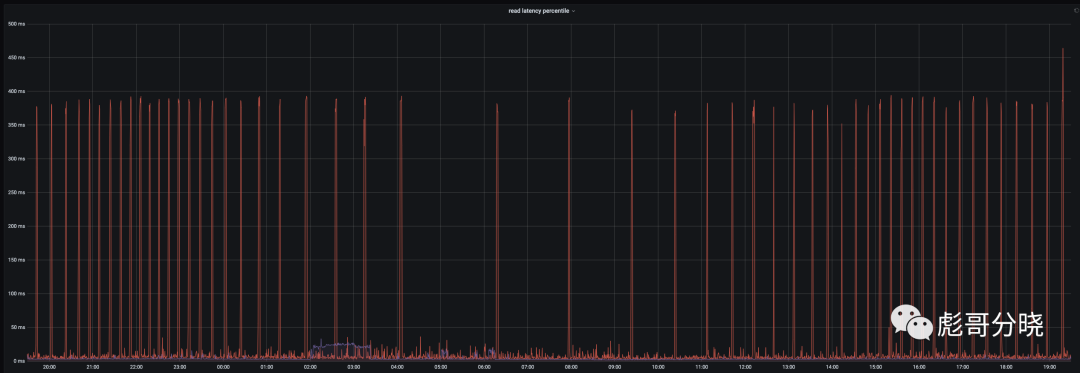
localssd/云盘总览图
local ssd 图
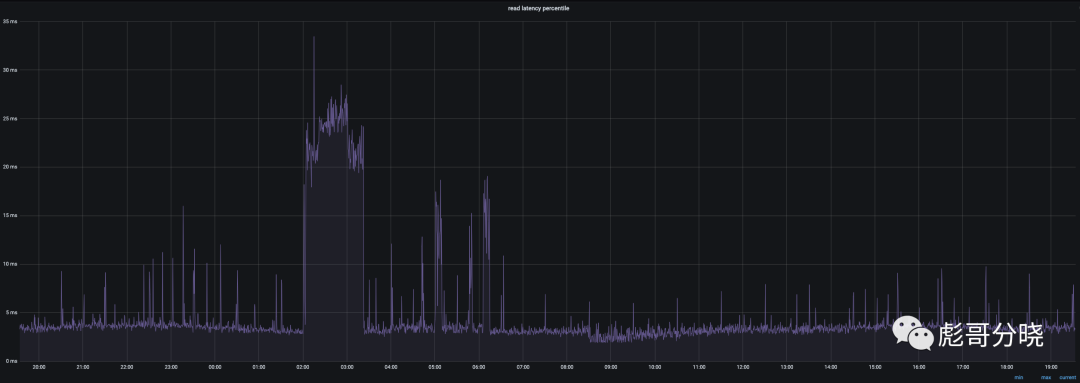
从图中可以看到云盘的监控图上有大量的毛刺而且毛刺还非常尖锐,高达500ms了,究其原因就是云盘总带宽限制(云上的虚拟机都有类似的限制)导致数据无法快速刷到磁盘导致的,相对在local ssd就会好很多,正常可以在10ms以内返回,及时是compact的时候也可以保证在50ms以内返回。
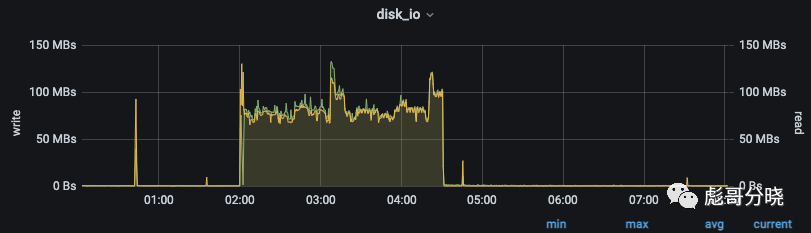
云盘compact的磁盘带宽
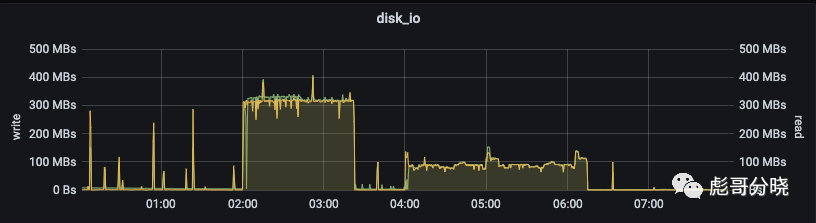
local-ssd compact的磁盘带宽
落地
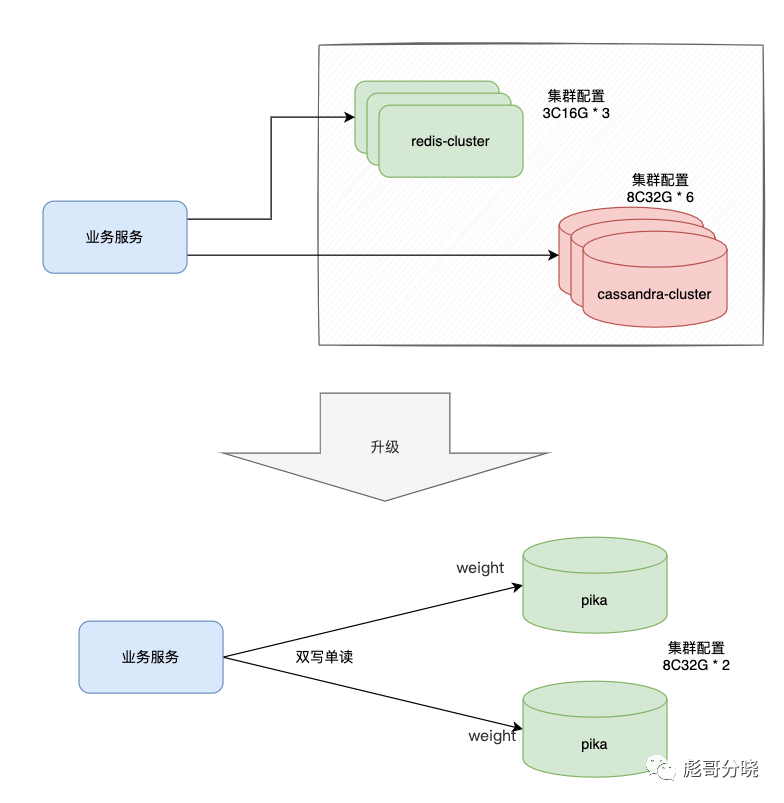
原先的服务架构在cassandra-cluster之前还挡了一层redis-cluster做数据的读取来降低cassandra-cluster的读压力。redis-cluster虽然性能非常好,但是毕竟内存容量较小而且还要比磁盘贵不少钱。redis中也只能存储一些比较新的数据或者是最近常访问的数据。对于我们的业务来说仅能解决一些就近数据查询问题,对于随机数据查询还是需要直接查询cassandra-cluster,导致cassandra的查询压力一直处于超时的边缘。业务经常需要处理cassandra查询的报警。
经过以上对pika和cassandra的性能对比测试,我们计划将redis + cassandra cluster 整体替换为 pika来解决问题。
其中pika我们并没有采用pika + codis的方式部署集群是因为
pika单节点的性能已经满足了目前业务需求。
pika + codis的部署复杂度较高、维护复杂度也较高。
pika双活部署方式
采用两个单机实例的pika做双写单读模式。其中一台pika配置local ssd(确保写入读取速度),另外一台配置云盘(确保数据不会丢失)。给每个不同的pika实例配置不同的权重,将更多的读写倾向于local-ssd的pika,进一步降低读写耗时。
如下就是本次系统替换数据的简要逻辑图
成本
由 3台 4C16G 机器的redis集群 + 6台 8C32G的 cassandra 集群 替换为两台 8C32G的 pika双活集群。硬件成本降低了70%,运维人员的心智负担与运维成本也降低了好多。同时数据库吞吐量有了将近10倍的提高,延时降低至原先的20-30%。
结论
pika性能远超cassandra,尤其是在数据量超过内存量之后仍然可以保持较高的读写性能。
使用pika替换cassandra之后可以节约数据库服务器资源。降低整个整个系统的运行成本。
pika开源协议友好。
后续规划
计划在公司内部的其他产品中继续推广pika的使用,以降低整个存储成本。
计划基于pika现有逻辑一起协助社区的小伙伴推出pika的cluster版本。
计划推进pika的lua-script脚本支持。
