





1)查准率 Precision:尽可能返回较少的无关文档; 2)查全率 Recall:尽可能返回较多的相关文档; 3)排序 Ranking:是否能按相关性排序。
tf(t in d) = √frequency 词 t 在文档 d 的词频( tf )是该词在文档中出现次数的平方根。
idf(t) = 1 + log ( numDocs (docFreq + 1)) 词 t 的逆向文档频率( idf )是:索引中文档数量除以所有包含该词的文档数,然后求其对数。 注意: 这里的log是指以e为底的对数,不是以10为底的对数。
norm(d) = 1 √numTerms 字段长度归一值( norm )是字段中词数平方根的倒数。
score(q,d) =
queryNorm(q)
· coord(q,d)
· ∑ (
tf(t in d)
· idf(t)²
· t.getBoost()
· norm(t,d)
) (t in q)
score(q,d) 文档d对查询q的相关性得分 queryNorm(q) 查询的规范化因子 coord(q,d) 协调因子 ∑ 文档d的查询q中每个词t的权重之和 tf(t in d) 文档d中t词的词频(出现次数) idf(t) t词的逆文档频率 t.getBoost() 已应用于查询的boost norm(t,d) 是字段长度归一值,与检索时字段的Boost (如果存在)相结合。
虽然现在es的相关性评分算法改为了BM25,但对于该公式,我们还是应该掌握,这有利于我们理解后续对相关度的控制。
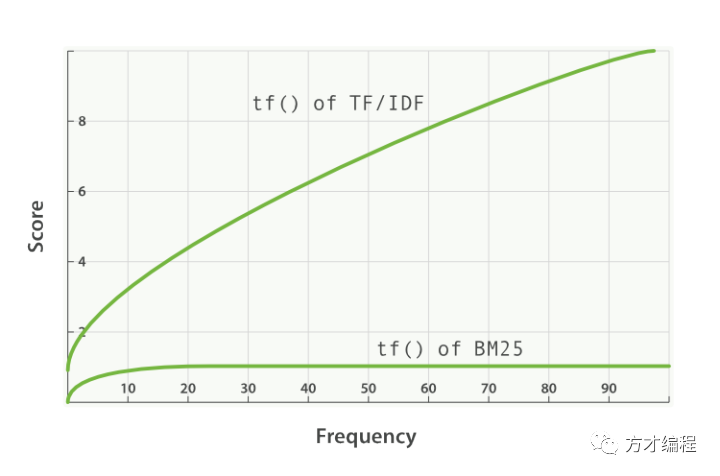
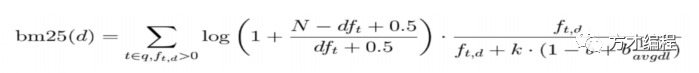
k1:这个参数控制着词频结果在词频饱和度中的上升速度。默认值为1.2。值越小饱和度变化越快,值越大饱和度变化越慢。 b:这个参数控制着字段长归一值所起的作用,0.0会禁用归一化,1.0会启用完全归一化。默认值为0.75。
该公式"."的前部分就是 IDF 的算法,后部分就是 TF+Norm 的算法。
#创建index
PUT blogs_index
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 1
}
},
"mappings": {
"_doc": {
"dynamic": false,
"properties": {
"id": {
"type": "integer"
},
"author": {
"type": "keyword"
},
"title": {
"type": "text",
"analyzer": "ik_smart"
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"tag": {
"type": "keyword"
},
"influence": {
"type": "integer_range"
},
"createAt": {
"type": "date",
"format": "yyyy-MM-dd HH:mm"
}
}
}
}
}
# 导入数据
POST _bulk
{"index":{"_index":"blogs_index","_type":"_doc","_id":"1"}}
{"id":1,"author":"方才兄","title":"es的相关度","content":"这是关于es的相关度的文章","tag":[1,2,3],"influence":{"gte":10,"lte":12},"createAt":"2020-05-24 10:56"}
{"index":{"_index":"blogs_index","_type":"_doc","_id":"2"}}
{"id":2,"author":"方才兄","title":"相关度","content":"这是关于相关度的文章","tag":[2,3,4],"influence":{"gte":12,"lte":15},"createAt":"2020-05-23 10:56"}
{"index":{"_index":"blogs_index","_type":"_doc","_id":"3"}}
{"id":3,"author":"方才兄","title":"es","content":"这是关于关于es和编程的必看文章","tag":[2,3,4],"influence":{"gte":12,"lte":15},"createAt":"2020-05-22 10:56"}
{"index":{"_index":"blogs_index","_type":"_doc","_id":"4"}}
{"id":4,"author":"方才","title":"关注我,系统学习es","content":"这是关于es的文章,介绍了一点相关度的知识","tag":[1,2,3],"influence":{"gte":10,"lte":15},"createAt":"2020-05-24 10:56"}
GET blogs_index/_search
{
"query": {
"match": {
"title": "es的相关度"
}
},
"explain": true
}
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 2.5933092,
"hits": [
{
"_shard": "[blogs_index][0]",
"_node": "VAAU48LMQ_iQfscqT2gjLA",
"_index": "blogs_index",
"_type": "_doc",
"_id": "1",
"_score": 2.5933092,
"_source": {
"id": 1,
"author": "方才兄",
"title": "es的相关度",
"content": "这是关于es的相关度的文章",
"tag": [
1,
2,
3
],
"influence": {
"gte": 10,
"lte": 12
},
"createAt": "2020-05-24 10:56"
},
"_explanation": {
"value": 2.593309,
"description": "sum of:",
"details": [
{
"value": 0.31387395,
"description": "weight(title:es in 0) [PerFieldSimilarity], result of:",
"details": [
{
"value": 0.31387395,
"description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:",
"details": [
{
"value": 0.35667494,
"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) (docFreq + 0.5)) from:",
"details": [
{
"value": 3,
"description": "docFreq",
"details": []
},
{
"value": 4,
"description": "docCount",
"details": []
}
]
},
{
"value": 0.88,
"description": "tfNorm, computed as (freq * (k1 + 1)) (freq + k1 * (1 - b + b * fieldLength avgFieldLength)) from:",
"details": [
{
"value": 1,
"description": "termFreq=1.0",
"details": []
},
{
"value": 1.2,
"description": "parameter k1",
"details": []
},
{
"value": 0.75,
"description": "parameter b",
"details": []
},
{
"value": 3,
"description": "avgFieldLength",
"details": []
},
{
"value": 4,
"description": "fieldLength",
"details": []
}
]
}
]
}
]
},
{
"value": 1.059496,
"description": "weight(title:的 in 0) [PerFieldSimilarity], result of:",
"details": [
……………………………………………………
1)"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) (docFreq + 0.5)) from:",根据该公式,docCount = 4,docFreq = 3,计算出 value = log10/7 = ln 10/7 = 0.3566749440 2)"description": "tfNorm, computed as (freq * (k1 + 1)) (freq + k1 * (1 - b + b * fieldLength avgFieldLength)) from:", 根据details的信息,计算出 value = (1*(1.2+1)/(1+1.2 *(1-0.75+0.75*4/3)))= 0.88 3)BM25(es)= idf * tfNorm = 0.3566749440 * 0.88 = 0.3138739947 4)同理得到 BM25(的)= 1.059496,BM25(相关)= 0.6099695,BM25(度)= 0.6099695; 5)根据"description": "sum of:",当检索【es的相关度】,文档1的_score = BM(es)+ BM25(的)+ BM25(相关)+ BM25(度)= 2.5933092

GET blogs_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": {
"query": "es",
"boost": 2
}
}
},
{
"match": {
"content": "es"
}
}
]
}
},
"explain": true
}
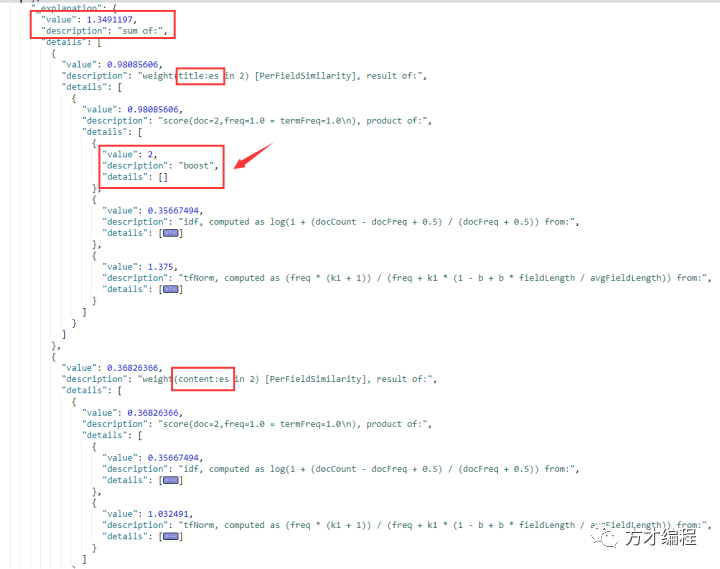
根据结果,我们可以看到:对应文档的_score = BM25(es in title) + BM25(es in content);其中BM25(es in title)= boost * idf * tfNorm
boost>1 相关度相对性提升 0<boost<1,相对性降低 boost<0,贡献负分
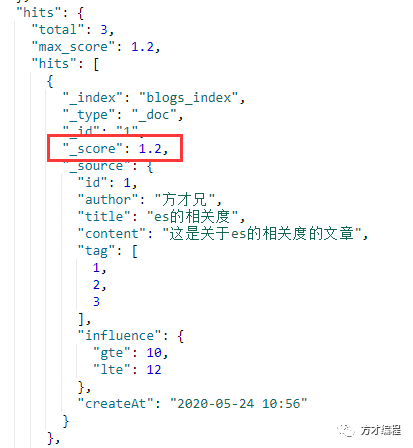
GET blogs_index/_search
{
"query": {
"constant_score" : {
"filter" : {
"term" : { "title": "es"}
},
"boost" : 1.2
}
}
}
GET blogs_index/_search
{
"query": {
"function_score": {
"query": {
"match_all": {}
},
"boost": "5",
"functions": [
{
"filter": {
"match": {
"title": "es"
}
},
"random_score": {},
"weight": 23
},
{
"filter": {
"match": {
"title": "相关度"
}
},
"weight": 42
}
],
"max_boost": 42,
"score_mode": "max",
"boost_mode": "multiply",
"min_score": 10
}
},
"explain": true
}
备注:function_score query 的用法非常多,适用场景也比较广,比如说:1)通过文档中的字段值影响相关度,比如可以让博客的点赞数越多,相关度越高;2)随机分数【可应用于千人千面】;3)根据距离参考值的衰减函数计算相关度,比如说地理位置查询,距离参考点越远的,相关性越低;4)更复杂的场景也可以用自定义脚本完全控制评分计算,实现所需逻辑。
关于对 function_score query 的详细讲解,TeHero后续会和大家分享的。
GET blogs_index/_search
{
"query": {
"dis_max": {
"tie_breaker": 0.5,
"boost": 1.2,
"queries": [
{
"term": {
"content": "es"
}
},
{
"match": {
"content": "相关度"
}
}
]
}
},
"explain": true
}
注意:queries 下的查询子句间的布尔关系是OR。
positive:用于获取返回结果 negative:对上述结果的相关性打分进行调整 negative_boost:调整参数:升权(>1), 降权(>0 and <1)
GET blogs_index/_search
{
"query": {
"boosting": {
"positive": {
"bool": {
"should": [
{
"term": {
"title": "es"
}
},
{
"term": {
"title": "相关性"
}
}
]
}
},
"negative": {
"term": {
"content": "编程"
}
},
"negative_boost": 0.2
}
},
"explain": true
}
1)根据 positive 下的查询语句检索,得到结果集; 2)在上述的结果集中,对于那些同时还匹配 negative 查询的文档,将通过文档的原始 _score 与 negative_boost 相乘的方式重新计算相关性得分。
negative_boost 的值>1,是正向评分,增加匹配 negative 查询的文档的权重。
GET blogs_index/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"content": {
"query": "es的相关度",
"minimum_should_match": "30%"
}
}
},
{
"match": {
"title": {
"query": "es"
}
}
}
]
}
},
"rescore": {
"window_size": 3,
"query": {
"rescore_query": {
"match_phrase": {
"content": {
"query": "es的相关度",
"slop": 50
}
}
}
}
}
}
PUT my_index
{
"settings": {
"similarity": {
"my_bm25": {
"type": "BM25",
"b": 0.8,
"k1": 1.5
}
}
},
"mappings": {
"doc": {
"properties": {
"title": {
"type": "text",
"similarity": "my_bm25"
}
}
}
}
}
注意:一般情况不建议更改这两个参数值。
PUT blogs_index1
{
"settings": {
"index": {
"number_of_shards": 10,
"number_of_replicas": 0
}
},
"mappings": {
"_doc": {
"dynamic": false,
"properties": {
"id": {
"type": "integer"
},
"author": {
"type": "keyword"
},
"title": {
"type": "text",
"analyzer": "ik_smart"
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"tag": {
"type": "keyword"
},
"influence": {
"type": "integer_range"
},
"createAt": {
"type": "date",
"format": "yyyy-MM-dd HH:mm"
}
}
}
}
}
POST _bulk
{"index":{"_index":"blogs_index1","_type":"_doc","_id":"1"}}
{"id":1,"author":"方才兄","title":"es的相关度","content":"这是关于es的相关度的文章","tag":[1,2,3],"influence":{"gte":10,"lte":12},"createAt":"2020-05-24 10:56"}
{"index":{"_index":"blogs_index1","_type":"_doc","_id":"2"}}
{"id":2,"author":"方才兄","title":"相关度","content":"这是关于相关度的文章","tag":[2,3,4],"influence":{"gte":12,"lte":15},"createAt":"2020-05-23 10:56"}
{"index":{"_index":"blogs_index1","_type":"_doc","_id":"3"}}
{"id":3,"author":"方才兄","title":"es","content":"这是关于关于es和编程的必看文章","tag":[2,3,4],"influence":{"gte":12,"lte":15},"createAt":"2020-05-22 10:56"}
{"index":{"_index":"blogs_index1","_type":"_doc","_id":"4"}}
{"id":4,"author":"方才","title":"关注我,系统学习es","content":"这是关于es的文章,介绍了一点相关度的知识","tag":[1,2,3],"influence":{"gte":10,"lte":15},"createAt":"2020-05-24 10:56"}
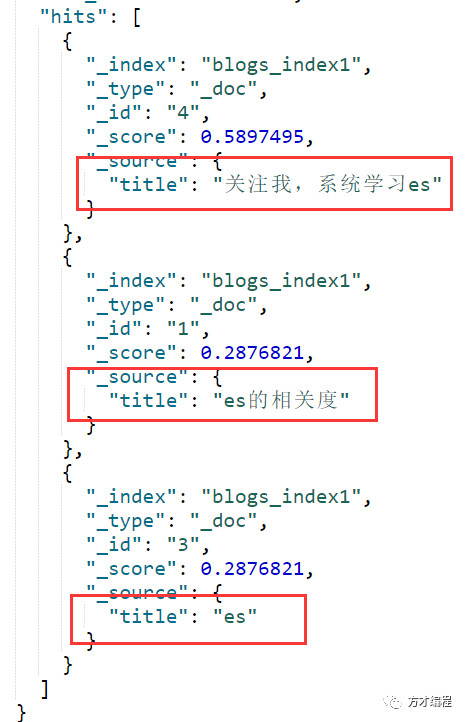
GET blogs_index1/_search
{
"_source": "title",
"query": {
"match": {
"title": {
"query": "es"
}
}
}
}
PUT tehero_index
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
GET /blogs_index1/_search?search_type=dfs_query_then_fetch
{
"query": {
"match": {
"title": {
"query": "es"
}
}
}
}
下期预告:ES的实战【关注公众号:方才编程,系统学习ES】
待续
 ●ES系列01:如何系统学习ES
●ES系列01:如何系统学习ES
ps:本文知识脑图,后台回复【es13】,即可获取!
