




MySQL是一个开源的关系型数据管理系统,用于存取数据、查询、更新和管理数据。
select distinct 字段名 from 表名 数据库自带的distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只用它来返回不重复记录的条数,而不是用它来返回不重复记录的所有值。其原因是 distinct只能返回它的目标字段,而无法返回其它字段。
连接方式:左连接、右连接、内连接
使用方法:
区别:
MySQL和Redis都可以存放数据,但MySQL里的数据是永久的,而Redis里的数据是缓存并有缓存机制,新的数据过来,老的数据会根据缓存机制失效。但是从Redis中读取数据比较快方便,而MySQL里的逻辑复杂,数据量大,读取数据耗时长。
优势:
唯一索引可以保证数据库表中每一行数据的唯一性 索引可以加快数据查询速度,减少查询时间
劣势:
创建索引和维护索引要耗费时间 索引需要占物理空间,除了数据表占用数据空间之外,每一个索引还要占用一定的物理空间 给表中的数据进行增、删、改的时候,索引也要动态的维护。
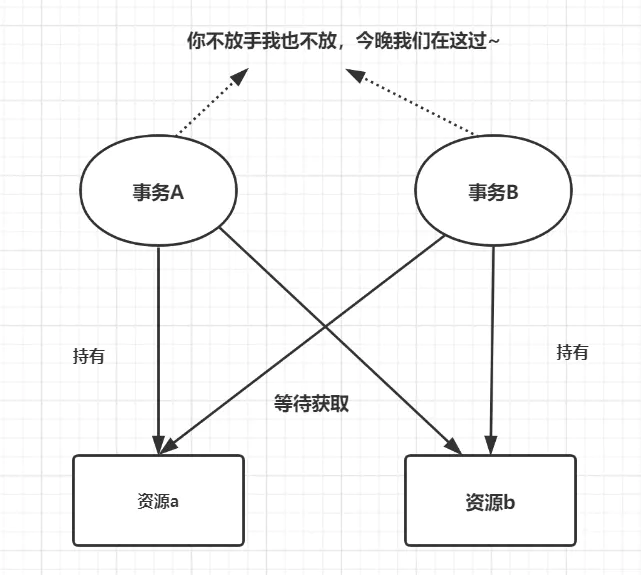
解决死锁思路,一般就是切断环路,尽量避免并发形成环路。 如果不同程序会并发存取多个表,尽量约定以相同的顺序访问表,可以大大降低死锁机会; 在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率; 对于非常容易产生死锁的业务部分,可以尝试使用升级锁定颗粒度,通过表级锁定来减少死锁产生的概率; 如果业务处理不好可以用分布式事务锁或者使用乐观锁; 死锁与索引密不可分,解决索引问题,需要合理优化索引。
视图是一个虚拟的表,是一个表中的数据经过某种筛选后的显示方式,视图由一个预定义的查询select语句组成。 为了提高复杂SQL语句的复用性和表操作的安全性,MySQL数据库管理系统提供了视图特性。
视图特点:
视图的列可以来自不同的表,是表的抽象和在逻辑意义上建立的新关系。 视图是由基本表(实表)产生的表(虚表)。 视图的建立和删除不影响基本表。 对视图内容的更新(添加,删除和修改)直接影响基本表。 当视图来自多个基本表时,不允许添加和删除数据。
视图用途:简化sql查询,提高开发效率,兼容老的表结构。
视图的常见使用场景:
重用SQL语句; 简化复杂的SQL操作。 使用表的组成部分而不是整个表; 保护数据 更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据。
查询简单化。视图能简化用户的操作 数据安全性。视图使用者能以多种角度看待同一数据,能够对机密数据提供安全保护 逻辑数据独立性。视图对重构数据库提供了一定程度的逻辑独立性
NOT NULL: 约束字段的内容一定不能为NULL。
UNIQUE: 约束字段唯一性,一个表允许有多个Unique约束。 PRIMARY KEY: 约束字段唯一,不可重复,一个表只允许存在一个。 FOREIGN KEY: 用于预防破坏表之间连接的动作,也能防止非法数据插入外键。 CHECK: 用于控制字段的值范围。
Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序; Union All:对两个结果集进行并集操作,包括重复行,不进行排序; UNION的效率高于UNION ALL
分析语句,是否加载了不必要的字段/数据。 分析SQL执行语句是否命中索引等。 如果SQL很复杂,优化SQL结构 如果表数据量太大,考虑分表情况
如果是单机的话,选择自增ID;如果是分布式系统,优先考虑UUID,但还是最好公司自己有一套分布式唯一ID生产方案。 自增ID:数据存储空间小,查询效率高。但是如果数据量过大,会超出自增长的值范围,多库合并,也有可能出现问题。 uuid:适合大量数据的插入和更新操作,但它是无序的,插入数据效率慢,占用空间大。
排查过程:
处理:
其他情况:
优点:
存储过程是一个预编译的代码块,执行效率比较高 存储过程在服务器端运行,减少客户端的压力 允许模块化程序设计,只需要创建一次过程,以后在程序中就可以调用该过程任意次,类似方法的复用 一个存储过程替代大量SQL语句 ,可以降低网络通信量,提高通信速率 可以一定程度上确保数据安全
缺点:
调试麻烦 可移植性不灵活 存在重新编译问题
加索引 避免返回不必要的数据 适当分批量进行 优化sql结构 分库分表 读写分离
表记录太少
经常插入、删除、修改的表
数据重复且分布平均的表字段,假如一个表有10万行记录,有一个字段A只有T和F两种值,且每个值的分布概率大约为50%,那么对这种表A字段建索引一般不会提高数据库的查询速度。
经常和主字段一块查询但主字段索引值比较多的表字段
存储更多数据。分区表的数据可以分布在不同的物理设备上,从而高效地利用多个硬件设备。和单个磁盘或者文件系统相比,可以存储更多数据。
优化查询。在where语句中包含分区条件时,可以只扫描一个或多个分区表来提高查询效率;涉及sum和count语句时,也可以在多个分区上并行处理,最后汇总结果。
分区表更容易维护。例如:想批量删除大量数据可以清除整个分区。
避免某些特殊的瓶颈,例如InnoDB的单个索引的互斥访问。
文章转载自JAVA高级架构,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
