




这是我在19年末,为单位同事做技术分享时整理的文档。今天在翻阅资料目录时看到了,特将此内容分享。虽然时间有点久了,但其中的概念逻辑并不过时,希望对初学大数据的同学,能有所帮助。以下是正文内容:
Hadoop HA环境搭建过程
文档整理:孟祥新(2019-12-17)

一. 本文概述:
Hadoop是基于JAVA语言开发的一个开源的分布式系统框架,用于在集群上存储数据和运行大数据处理的应用程序。Hadoop有以下几种安装模式:
(1) 本地模式安装(local mode,也称独立模式standalone):默认的安装模式,无需运行任何守护进程(daemon),所有程序都在单个JVM上执行。由于在本机模式下测试和调试MapReduce程序较为方便,因此,这种模式适宜用在开发阶段。这种模式使用的是本地文件系统,而不是分布式文件系统。
(2) 伪分布式模式安装(Single Node Cluster): 也称为单节点集群。是在一台主机上模拟多机环境,其中各个守护进程都运行在同一台主机上,Hadoop 的各个模块机以相互独立的Java进程的形式运行。在这种模式下,Hadoop使用的是分布式文件系统,各个作业也是由JobTraker服务来管理的独立进程。这种模式类似于完全分布式模式,此模式常用来开发测试Hadoop程序的执行是否正确。
(3) 完全分布式安装(Full Distributed Cluster):Hadoop 的相关功能模块,按规划运行在集群的不同主机上。
(4) 高可用集群模式安装(HA模式):用于解决的Hadoop单点故障,实现了NN和RM的高可用。生产环境一般都做HA部署。(ResourceManager的HA。是在Apache Hadoop 2.4.1版本中开始加入的)
(5) 高可用联邦集群模式(HA + Federation Cluster):是将两个或两以上的HA集群通过Federation进行连接。(可以将每一个HA集群看做是一个单独的网络,不同网络间通过Federation路由器进行沟通),这种模式实现了HA集群的横向扩展。解决了NN或RM负载过重的性能瓶颈。此模式适用于规模较大的企业应用。
本文档是为了更为贴近生产的真实环境,在结合官方技术文档和相关书籍的基础上,记录了在VMWare虚拟机环境搭建Hadoop Ha环境的安装部署过程。希望能以此文档抛砖引玉,促进大家在Hadoop大数据技术方面的学习和交流。
本文实践所需主机软硬件条件:8GB物理内存,Windows 7或Windows 10操作系统。
对于本文中可能存在的错误之处,或是在实践部署安装过程中遇到的问题,欢迎大家与我联系并批评指正。
在本文档最后,给出了相关的学习参考书目,供大家进一步的深入学习。
二. 软件准备
序号 | 软件包 | 大小(字节) | 下载地址 |
1 | VMware-workstation-full-15.5.1-15018445 | 191,375,184 | https://www.vmware.com/cn/products/workstation-pro/workstation-pro-evaluation.html |
2 | CentOS-6.9-x86_64-bin-DVD1.iso | 3,972,005,888 | |
3 | jdk-8u231-linux-x64.tar.gz | 194,151,339 | https://www.oracle.com/technetwork/java/javase/downloads/index.html |
4 | apache-zookeeper-3.5.6-bin.tar.gz | 9,230,052 | |
5 | hadoop-2.7.7.tar.gz | 218,720,521 |
三. 虚拟主机准备
1. 创建三台VMWare虚拟机
配置:1个CPU、内存1GB、硬盘20GB、NAT网络模式
主机名:hadoop1、hadoop2、hadoop3
2. 最小化安装CentOS-6.9操作系统
3. 设置IP与主机名的映射关系(hosts文件)
/etc/hosts
# 127.0.1.1
192.168.118.11 hadoop1
192.168.118.12 hadoop2
192.168.118.13 hadoop3
4. 关闭防火墙
chkconfig iptables off
service iptables stop
5. 关闭selinux
/etc/selinux/config
SELINUX=disabled
四. Hadoop的三大功能模块简介
1. HDFS模块
是Hadoop 大数据存储的基础架构,将大文件分块后进行分布式存储。每块默认大小为128MB
与其他文件系统不同的是,HDFS中小于一个块大小的文件不会占据整个块的空间。
注意:HDFS文件都是一次性写入的,并且严格要求在任何时候只能有一个写入者。
2. MapReduce模块
是Hadoop 大数据计算框架,分为两个阶段:Map 阶段和Reduce阶段,对数据进行分布式处理。
Map负责把作业分解成多个任务,提交给集群的多个运算节点处理。
Reduce负责把分解后多任务处理的结果汇总。
3. YARN 模块
YARN 是资源协同和任务调度框架,在此之上不仅可以运行 MapReduce,还可以运行Spark、Storm等其他计算框架。
五. 相关组件简介
1. Zookeeper
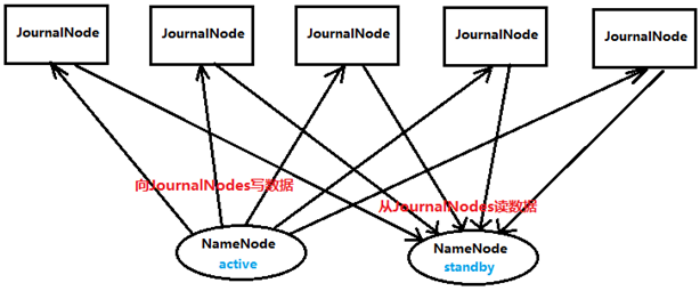
是分布式管理协作框架,用来保证Hadoop集群的高可用。Hadoop HA集群中两个NameNode,一个是Active,另一个是Standby状态,两个都定时向Zookeeper发送心跳。一旦Zookeeper检测不到Active的心跳,就将Standby状态的NameNode设置为Action状态。
2. NameNode
HDFS集群有两类节点,一个NameNode(管理者)和多个DataNode(工作者)。NameNode记录着每个文件中各个块所在的数据节点的信息,主要负责管理HDFS文件系统。NameNode主要维护两个文件:一个是fsimage,一个是editlog。
fsimage是NameNode的元数据镜像文件,是具体某一时刻,整个HDFS的快照。包含了整个HDFS文件系统的所有目录和文件的信息。
editlog是NameNode的操作日志文件。是对HDFS进行的更新操作的变更记录,HDFS客户端执行所有的写操作都会被记录到editlog中
NameNode维护了文件与数据块的映射表以及数据块与数据节点的映射表。就是一个文件,它切分成了几个数据块,以及这些数据块分别存储在哪些datanode上。
查看fsimage和editlog的方法:查看hdfs-site.xml,dfs.namenode.name.dir配置项的值:cd /opt/modules/hadoopha/hadoop-2.7.7/hdfs/name/current
3. DataNode
是HDFS的工作节点,负责存储数据块和提供数据块的读写服务。数据块以文件的形式保存在DataNode的磁盘上,包括两个文件:数据文件(数据本身)和元数据文件(包括:数据块的长度、数据块的MD5校验和、时间戳)
DataNode周期性(每3秒dfs.heartbeat.interval)向NameNode发送心跳,如果10分钟没有收到DataNode的心跳,则认为其已经lost,并copy其上的block到其它DataNode
DataNode周期性(每1小时dfs.namenode.checkpoint.period)向NameNode汇报其上所有数据块的信息。
4. Secondary NameNode
是定时从NameNode获得fsimage和editlog,并把二者重新合并再发给NameNode,避免在NameNode崩溃之后,导致的数据丢失。
为了避免editlog不断增大,secondary namenode会周期性合并fsimage和edits成新的fsimage,新的操作记录会写入新的editlog中
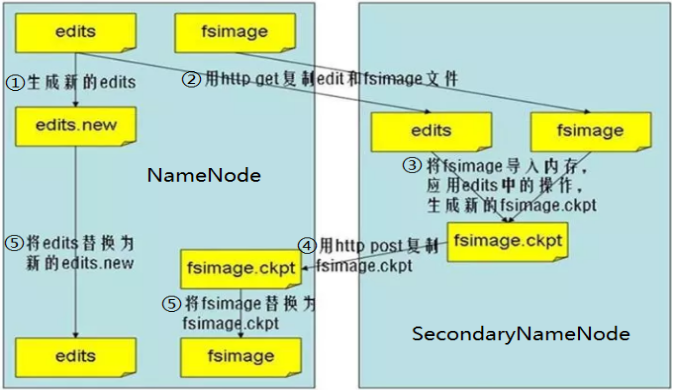
5. Journalnode
用于存放editlog,通过editlog,实现将active状态的NameNode的变化同步到standby状态的NameNode
6. NodeManager(TaskTraker)
NodeManager是Yarn集群中单个节点的代理,它负责管理Hadoop集群中单个计算节点,比如监视资源使用情况( CPU,内存,硬盘,网络)。NodeManage与应用程序的ApplicationMaster和集群管理器ResourceManager交互,管理Container的生命周期,监控每个Container的资源使用情况,追踪节点健康状况,向ResourceManager汇报各个Container的运行状态和节点健康状态,并领取相关的Container的命令执行。
7. ResourceManager(JobTracker)
是Yarn集群主控节点,负责协调和管理整个集群(所有NodeManager)的资源。ResourceManager主要有两个组件:Scheduler和ApplicationManager
Scheduler调度集群中的各种队列、应用等。另一个组件ApplicationManager主要负责接收job的提交请求,为应用分配第一个Container来运行ApplicationMaster,还有就是负责监控ApplicationMaster,在遇到失败时重启ApplicationMaster运行的Container。
ApplicationMaster 用于对单个作业的资源管理和任务监控。
8. Container
是一个容器,将内存、CPU、磁盘、网络等资源封装在一起,用于界定资源边界。
六. 主机及功能组件规划
主机名 | hadoop1 | hadoop2 | hadoop3 |
主机IP | 192.168.118.11 | 192.168.118.12 | 192.168.118.13 |
功能配置 | NTP Server | ||
Zookeeper | Zookeeper | Zookeeper | |
NameNode | NameNode | ||
DataNode | DataNode | DataNode | |
NodeManager | NodeManager | NodeManager | |
Journalnode | Journalnode | Journalnode | |
ResourceManager | ResourceManager |
七. 安装步骤
1. 安装JDK并设置环境变量
/etc/profile
export JAVA_HOME=/opt/jdk1.8.0_231
export CLASSPATH=.:$JAVA_HOME/jre/lib:$JAVA_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
测试JDK安装是否成功:java –version
2. 配置NTP时间服务器
(实验环境可略,如果需要详细过程请与我联系)
3. 创建hadoop用户并设置权限
useradd -m hadoop -s /bin/bash
vi /etc/sudoers
hadoop ALL=(ALL) ALL
4. 创建存放hadoop文件的目录
mkdir /opt/modules/hadoopha
chown -R hadoop:hadoop /opt/modules
5. 安装Zookeepe并启动Zookeeper服务
(1) 解压安装包:
tar -zxvf apache-zookeeper-3.5.6-bin.tar.gz
(2) 将目录改名:
mv apache-zookeeper-3.5.6-bin zookeeper-3.5.6
(3) 设置zookeeper的数据存放的目录:
mkdir -p /opt/modules/zookeeper-3.5.6/data/zData
(4) 设置配置文件:
cd /opt/modules/zookeeper-3.5.6/conf
cp zoo_sample.cfg zoo.cfg
设置zookeeper数据存放的目录:
dataDir=/opt/modules/zookeeper-3.5.6/data/zData
设置zookeeper集群信息:
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
server.3=hadoop3:2888:3888
(5) 将zookeeper安装目录分发到其他节点主机:
scp -r /opt/modules/zookeeper-3.5.6 hadoop2:/opt/modules
scp -r /opt/modules/zookeeper-3.5.6 hadoop3:/opt/modules
(6) 在各节点机上创建myid文件(文件内容为server点后面的数字):
echo 1 > /opt/modules/zookeeper-3.5.6/data/zData/myid
(7) 添加Zookeeper的环境变量到各主机:
/etc/profile
export ZOOKEEPER_HOME=/opt/modules/zookeeper-3.5.6
export PATH=$PATH:$ZOOKEEPER_HOME/bin
(8) 启动Zookeeper服务(按顺序分别在各节点机上执行):
/opt/modules/zookeeper-3.5.6/bin/zkServer.sh start
(9) 查看Zookeeper服务状态:
/opt/modules/zookeeper-3.5.6/bin/zkServer.sh status
6. 解压hadoop安装包
tar -zxvf hadoop-2.7.7.tar.gz
7. Hadoop的主要配置文件
配置文件名 | 作用 | 文件位置 |
core-site.xml | 设置hadoop集群全局参数 | ${HADOOP_HOME}/etc/hadoop/core-site.xml |
hdfs-site.xml | 设置HDFS参数 | ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml |
mapred-site.xml | 设置Mapreduce参数 | ${HADOOP_HOME}/etc/hadoop/mapred-site.xml |
yarn-site.xml | 设置集群资源系统参数 | ${HADOOP_HOME}/etc/hadoop/yarn-site.xml |
8. 配置 Hadoop 环境变量
(1) 操作系统环境变量设置
/etc/profile
export HADOOP_HOME=/opt/modules/hadoopha/hadoop-2.7.7
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
(2) Hadoop JDK 路径设置
${HADOOP_HOME}/etc/hadoop/hadoop-env.sh
${HADOOP_HOME}/etc/hadoop/mapred-env.sh
${HADOOP_HOME}/etc/hadoop/yarn-env.sh
export JAVA_HOME=/opt/jdk1.8.0_231
以上设置成功后,可以查看Hadoop的版本:hadoop version
(3) 配置 core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://ns1</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/modules/hadoopha/hadoop-2.7.7/tmp</value> </property> <property> <name>io.file.buffer.size</name> <value>4096 </value> </property> <property> <name>ha.zookeeper.quorum</name> <value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value> </property> </configuration> |
(4) 配置 hdfs-site.xml
<configuration> <property> <name>dfs.nameservices</name> <value>ns1</value> </property> <property> <name>dfs.ha.namenodes.ns1</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.ns1.nn1</name> <value>hadoop1:8020</value> </property> <property> <name>dfs.namenode.rpc-address.ns1.nn2</name> <value>hadoop2:8020</value> </property> <property> <name>dfs.namenode.http-address.ns1.nn1</name> <value>hadoop1:50070</value> </property> <property> <name>dfs.namenode.http-address.ns1.nn2</name> <value>hadoop2:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/ns1</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/modules/hadoopha/hadoop-2.7.7/tmp/data/dfs/journal</value> </property> <property> <name>dfs.client.failover.proxy.provider.ns1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/opt/modules/hadoopha/hadoop-2.7.7/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/opt/modules/hadoopha/hadoop-2.7.7/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> </configuration> |
(5) 配置 yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>1024</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>1</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>4</value> </property> <property> <name>yarn.app.mapreduce.am.resource.mb</name> <value>200</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>106800</value> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarn-cluster</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm12,rm13</value> </property> <property> <name>yarn.resourcemanager.hostname.rm12</name> <value>hadoop2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm13</name> <value>hadoop3</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> </configuration> |
(6) 配置mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop1:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop1:19888</value> </property> </configuration> |
(7) 配置 slaves 文件
${HADOOP_HOME}/etc/hadoop/slaves
hadoop1 hadoop2 hadoop3 |
9. 设置Hadoop集群各主机间的SSH互信访问
(1) 在一台主机上生成密钥
ssh-keygen -t rsa
(2) 将公钥分发到其他主机
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
(3) 同样方法在另外两台主机上设置免密访问
(4) 测试主机间的免密互信访问
比如在hdoop1主机上执行 ssh hdoop2和ssh hdoop3
10. 分发Hadoop文件到其他节点
scp -r /opt/modules/hadoopha/hadoop-2.7.7 hadoop2:/opt/modules/hadoopha
scp -r /opt/modules/hadoopha/hadoop-2.7.7 hadoop3:/opt/modules/hadoopha
11. 启动Hadoop前的准备工作
(1) 创建一个zNode
在Zookeeper上创建一个存储NameNode节点命名空间的节点
${HADOOP_HOME}/bin/hdfs zkfc –formatZK
(2) 启动每个JournalNode节点
${HADOOP_HOME}/sbin/hadoop-daemon.sh start journalnode
(3) 格式化主NameNode节点
${HADOOP_HOME}/bin/hdfs namenode -format ns1
(4) 启动主NameNode节点
${HADOOP_HOME}/sbin/hadoop-daemon.sh start namenode
(5) 格式化备NameNode节点的目录
${HADOOP_HOME}/bin/hdfs namenode –bootstrapStandby
(6) 启动备namenode进程
${HADOOP_HOME}/sbin/hadoop-daemon.sh start namenode
(7) 启用Zookeeper的主备NameNode节点的故障切换功能
(在两个namenode节点上执行)
${HADOOP_HOME}/sbin/hadoop-daemon.sh start zkfc
12. 启动Hadoop集群
(1) 启动Zookeeper(在各相关节点机)
${ZOOKEEPER_HOME}/bin/zkServer.sh start
(2) 启动HDFS
${HADOOP_HOME}/sbin/start-all.sh
(3) 启动Yarn
${HADOOP_HOME}/sbin/start-yarn.sh
(4) 查看hadoop各组件的启动情况
Jps
(5) 查看两个NameNode的状态
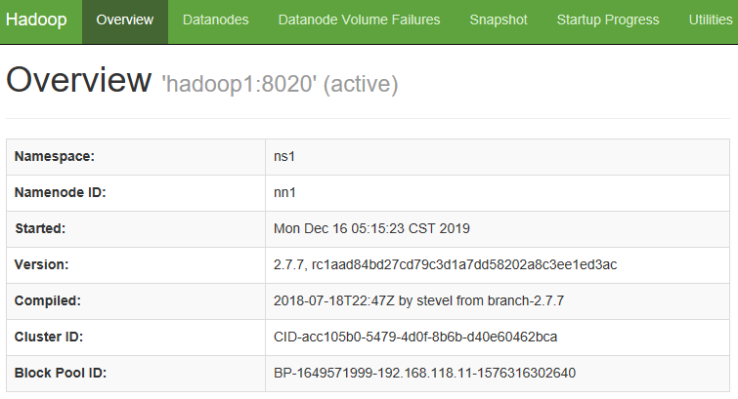
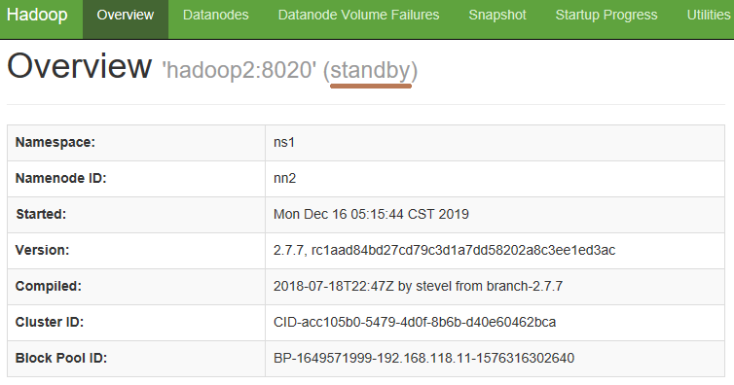
(6) 查看YARN 的 Web 页面
先确定哪个RM处于active状态: yarn rmadmin -getServiceState rm12

13. 停止Hadoop 集群
(1) 停止Yarn
${HADOOP_HOME}/sbin/stop-yarn.sh
(2) 停止HDFS
${HADOOP_HOME}/sbin/stop-all.sh
(3) 停止Zookeeper集群
${ZOOKEEPER_HOME}/bin/stop-zk.sh
八. Hadoop HA集群的Failover功能测试
1. NameNode Failover功能测试
将Active状态的NN进程kill掉,模拟NN在生产环境中的异常down掉。
在Zookeeper的作用下,会自动将处于standby状态的NN转换为active
启动NN的命令:${HADOOP_HOME}/sbin/hadoop-daemon.sh start namenode
2. ResourceManager Failover功能测试
将Active状态的RM进程kill掉,模拟RM在生产环境中的异常down掉。
在Zookeeper的作用下,会自动将处于standby状态的RM转换为active
启动RM的命令:${HADOOP_HOME}/sbin/yarn-daemon.sh start resourcemanager
九. Hadoop功能实测
1. 创建测试用的 Input 文件
vi wc.input
hadoop mapreduce hive hbase spark storm sqppp hadoop hive spark hadoop |
2. 在HDFS上创建测试用输入目录
${HADOOP_HOME}/bin/hdfs dfs -mkdir -p /wordcountdemo/input
3. 上传本地文件到 HDFS的输入目录
${HADOOP_HOME}/bin/hdfs dfs -put /home/hadoop/wc.input /wordcountdemo/input
4. 执行运算
${HADOOP_HOME}/bin/yarn jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /wordcountdemo/input /wordcountdemo/output
5. 查看输出结果
查看输出结果目录:
${HADOOP_HOME}/bin/hdfs dfs -ls /wordcountdemo/output
查看输出文件内容
${HADOOP_HOME}/bin/hdfs dfs -cat /wordcountdemo/output/part-r-00000
hadoop 3
hbase 1
hive 2
mapreduce 1
spark 2
sqppp 1
storm 1
可以看到上面的结果已经按照键值进行了排序。
十. Hadoop 的 优缺点分析
Hadoop是一个开源软件框架,用于大数据的存储和运算处理。具有以下优点:
1. 优点:
(1) 高效:移动计算而非数据,适用于批处理。以并行的方式工作提高数据处理速度。且计算能力与运行节点数量成正比。
(2) 可靠:Hadoop的框架设计,考虑到了计算和存储节点失败的情况,确保能够针对失败的节点重新分布处理。
(3) 容错:自动保存数据的多个副本,副本丢失后自动恢复。并且能够自动将失败的任务重新分配。
(4) 灵活可扩展:存储的数据多样化,且存储和计算节点可以横向伸缩扩展。
(5) 低成本:开源的软件框架,并且可以构建在廉价机器上,适合大规模数据存储与计算。
2. 缺点:
(1) 不适用于低延迟数据访问
(2) 不能高效存储大量小文件
(3) 不支持多用户写入并任意修改文件
(4) 在数据安全性方面,存在先天不足
(5) MapReduce编程有一定难度主,并且不适合所有问题(对于迭代和交互式分析任务,效率不高)
十一. Hadoop端口号
组件 | 端口 | 描述 | 参数 | 配置文件 |
Zookeeper | 2181 | 客户端连接zookeeper的端口 | ha.zookeeper.quorum yarn.resourcemanager.zk-address | core-site.xml yarn-site.xml |
2888 | zookeeper集群内通讯使用,Leader监听此端口 | server.1=hadoop1:2888:3888 server.2=hadoop2:2888:3888 server.3=hadoop3:2888:3888 | zoo.cfg | |
3888 | zookeeper端口 用于选举leader | |||
Hadoop | 50010 | datanode服务端口,用于数据传输 | dfs.datanode.address | |
50020 | datanode的IPC服务器地址和端口 | dfs.datanode.ipc.address | ||
50075 | datanode的http服务的端口 | dfs.datanode.http.address | ||
8019 | ZKFC端口,ZooKeeper FailoverController,用于NN HA | dfs.ha.zkfc.port | ||
8020 | fs.defaultFS 接收Client连接的RPC端口,用于获取文件系统metadata信息 | |||
8030 | scheduler组件的IPC端口 | yarn.resourcemanager.scheduler.address | ||
8031 | yarn.resourcemanager.resource-tracker.address | |||
8032 | RM的applications manager(ASM)端口 | yarn.resourcemanager.address | ||
8033 | yarn.resourcemanager.admin.address | |||
8040 | localizer IPC | yarn.nodemanager.localizer.address | ||
8041 | NM中container manager的端口 | yarn.nodemanager.address | ||
8042 | http服务端口 | yarn.nodemanager.webapp.address | ||
8080 | ||||
8088 | Yarn 的WEB UI 接口 | yarn.resourcemanager.webapp.address | ||
8480 | JournalNode 的HTTP服务 | dfs.journalnode.http-address | ||
8485 | JournalNode 的RPC端口 | dfs.journalnode.rpc-address | ||
10020 | mapreduce.jobhistory服务端口 | mapreduce.jobhistory.address | ||
19888 | mapreduce.jobhistory WEB UI端口 | mapreduce.jobhistory.webapp.address |
十二. 问题记录
1. 没能启动NameNode
问题现象:在启动Hadoop集群时,偶尔出现NameNode没能启动的现象,经过查看$HADOOP_HOME/logs下的hadoop-hadoop-namenode-hadoop1.log,相关内容摘录如下:
2019-12-26 13:13:17,633 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: hadoop1/192.168.118.11:8485. Already tried 9 time(s); retry policy is RetryUpToMaximumCountWithFixedSlee p(maxRetries=10, sleepTime=1000 MILLISECONDS) 2019-12-26 13:13:17,635 FATAL org.apache.hadoop.hdfs.server.namenode.FSEditLog: Error: recoverUnfinalizedSegments failed for required journal (JournalAndStream(mgr=QJM to [192.168.118.11:8485 , 192.168.118.12:8485, 192.168.118.13:8485], stream=null)) org.apache.hadoop.hdfs.qjournal.client.QuorumException: Got too many exceptions to achieve quorum size 2/3. 3 exceptions thrown: 192.168.118.12:8485: Call From hadoop1/192.168.118.11 to hadoop2:8485 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache. org/hadoop/ConnectionRefused 192.168.118.13:8485: Call From hadoop1/192.168.118.11 to hadoop3:8485 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache. org/hadoop/ConnectionRefused 192.168.118.11:8485: Call From hadoop1/192.168.118.11 to hadoop1:8485 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache. org/hadoop/ConnectionRefused ...... 2019-12-26 13:13:17,638 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1 2019-12-26 13:13:17,664 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop1/192.168.118.11 ************************************************************/ |
问题原因分析:
通过以上日志信息,可以看出,NameNode做为JournalNode的客户端发起请求,但失败了。然后NameNode又向其他节点依次发起请求都失败了,直至到了最大重试次数。
解决方法:
修改core-site.xml中的ipc参数。
<property> <name>ipc.client.connect.max.retries</name> <value>100</value> <description>Indicates the number of retries a client will make to establish a server connection. </description> </property> <property> <name>ipc.client.connect.retry.interval</name> <value>10000</value> <description>Indicates the number of milliseconds a client will wait for before retrying to establish a server connection. </description> </property> |
三台主机都要按以上修改core-sie,xml,然后重启Hadoop集群。
附录:参考书目
书名 | 作者 | 出版社 |
《Hadoop基础教程》 | [英] Garry Turkington | 人民邮电出版社 |
《Hadoop实战》 | [美] Chuck Lam | 人民邮电出版社 |
《Hadoop权威指南》(第4版) | Tom White | 清华大学出版社 |
《大数据技术原理与应用》(第2版) | 林子雨 | 人民邮电出版社 |
《从零开始学Hadoop大数据分析》 | 温春水、毕洁馨 | 机械工业出版社 |
