最近在学习 Scrapy,学习的过程总是枯燥的,所以总要有些实例操作,才有兴趣继续学习!这里我爬了三个小项目。
1、爬取 2345 影视网站上的电视剧和电影资源
1.1 安装环境什么的就一笔略过了。需要的依赖包列表如下,你可以保存为一个 123.txt,然后pip install -r 123.txt
来安装这些依赖包。
asn1crypto==0.24.0
attrs==18.1.0
Automat==0.7.0
cffi==1.11.5
constantly==15.1.0
cryptography==2.3.1
cssselect==1.0.3
hyperlink==18.0.0
idna==2.7
incremental==17.5.0
lxml==4.2.4
mysqlclient==1.3.13
parsel==1.5.0
pyasn1==0.4.4
pyasn1-modules==0.2.2
pycparser==2.18
PyDispatcher==2.0.5
PyHamcrest==1.9.0
pyOpenSSL==18.0.0
pywin32==223
queuelib==1.5.0
Scrapy==1.5.1
service-identity==17.0.0
six==1.11.0
Twisted==18.7.0
w3lib==1.19.0
zope.interface==4.5.0
如果有些包在 Windows 系统上可能安装不了,提示缺少 VC14 什么的,就单独下载 whl 格式的包安装。
1.2 新建一个 scrapy 项目
scrapy startproject tv2345
建议用开发工具,我用的是 PyCharm 的 IDE,然后新建了一个项目,用的是 python 的 venv 环境!
在目录 tv2345/tv2345/spiders/下,新建一个 tv2345_spider.py 的文件。内容如下:
import scrapy
import re
class Tv2345Spider(scrapy.Spider):
name = "tv2345"
#start_urls = ['http://so.kan.2345.com/search_ 最新/']
def start_requests(self):
yield scrapy.Request('http://so.kan.2345.com/search_ 神话/',
callback=self.parse_tv2345,
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'},
dont_filter=True,
)
def parse_tv2345(self, response):
for tv in response.css('div.item.clearfix'):
keyword = tv.css('span.sStyle::text').extract_first()
if keyword == '电视剧':
tmp_tv_name = tv.css('div.tit')
tv_name = tmp_tv_name.xpath('.//a/@title').extract_first()
tv_img = tv.xpath('.//img/@data-src').extract_first()
temp_tvs = tv.css('div.wholeTxt>div:last-child')
tv_url = temp_tvs.xpath('.//a/@href').extract()
dels = 'javascript:void(0);'
while dels in tv_url:
tv_url.remove(dels)
tv_urls = tv_url
tv_nums = temp_tvs.xpath('.//a/@title').extract() # [3:0]截取字段
yield {
'tv_name': tv_name,
'tv_img': tv_img,
'tv_urls': tv_urls,
'tv_nums': tv_nums,
}
if keyword =='电影':
tmp_tv_name = tv.css('div.tit')
tv_name = tmp_tv_name.xpath('.//a/@title').extract_first()
tv_img = tv.xpath('.//img/@data-src').extract_first()
tmp_tv_urls = tv.css('div.playBtnCon.clearfix')
tv_url = tmp_tv_urls.xpath('.//a/@href')
tv_urls = tv_url.extract_first()
tv_nums = '播放'
yield {
'tv_name':tv_name,
'tv_img':tv_img,
'tv_urls':tv_urls,
'tv_nums':tv_nums,
}
next = response.css('div.v_page a.last_child')
next_url = next.xpath('.//@href').extract_first()
if next_url:
next_url = response.urljoin(next_url)
yield scrapy.Request(next_url, callback=self.parse_tv2345)
上面分别对电视剧类型和电影类型做了单独的爬取规则,因为还有综艺等其他类型就不爬取了。
1.3 修改 setting.py 文件
ITEM_PIPELINES = {
'tv2345.pipelines.tv2345Pipeline': 300,
}
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5'
ROBOTSTXT_OBEY = False #绕过 robots.txt
FEED_EXPORT_ENCODING = 'utf-8'
1.4 爬取文件落地,以上是爬取电视剧神话和电影神话的 Url,
scrapy crawl tv2345 -t json -o tv234.json
然后查看 tv2345.json 的内容如下图所示

也可以用 json 格式化工具查看,更加清晰,推荐 json 格式化工具效果如下图所示
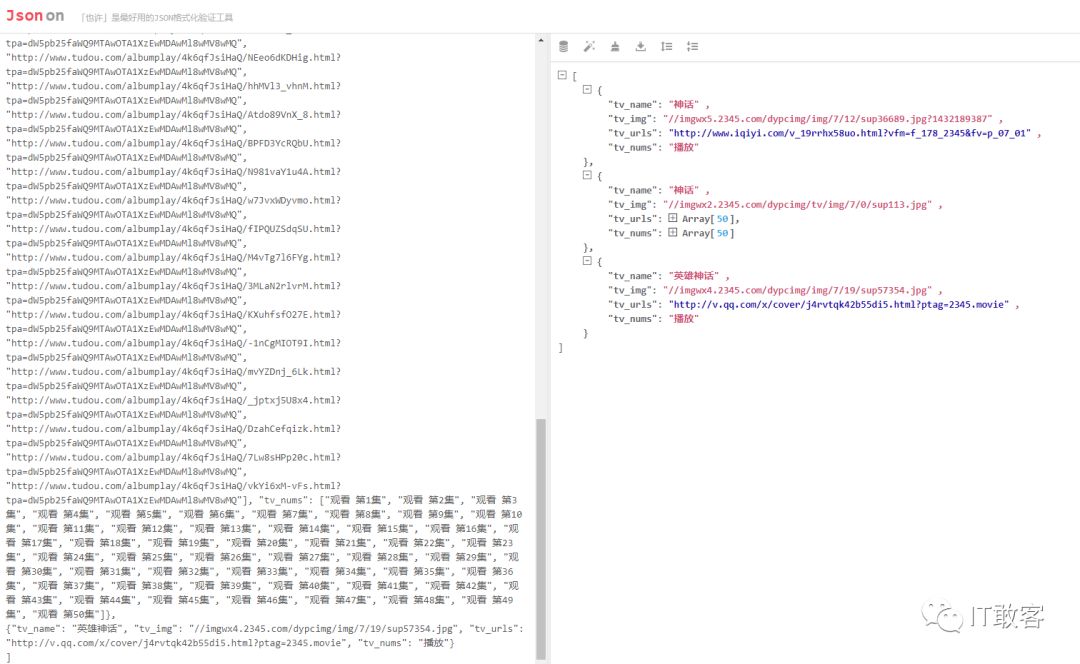
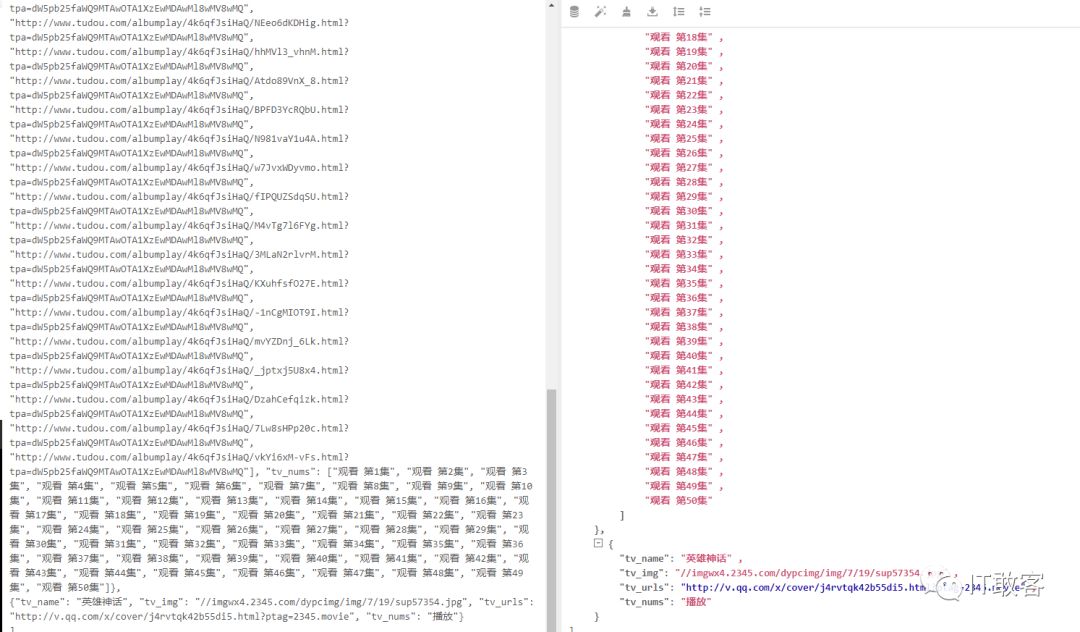
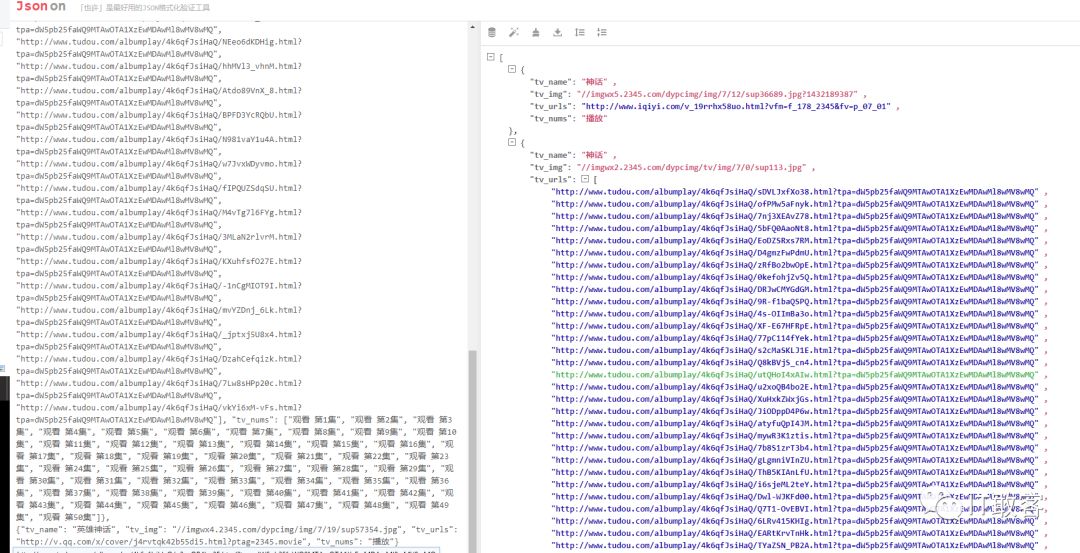
好了,以上还可以自定义导出 csv 等其他格式,如果需要导出 excel 格式,需要自定义写一下,默认不支持导出为 excel 格式。
2、爬取毒汤日历的语句,以及昨天和作者头像
2.1 新建一个 yiyan 的爬虫项目有
scrapy startproject yiyan
2.2 在 yiyan/yiyan/spiders/目录下新建 yiyan_spider.py 文件,内容如下:
# -*- coding:utf-8 -*-
import scrapy
import datetime
import json
class YiyanSpider(scrapy.Spider):
name = "yiyan"
start_urls = ['http://www.dutangapp.cn/u/toxic?date=2018-4-12']
def parse(self, response):
today = datetime.datetime.strptime('2018-08-17', '%Y-%m-%d')
fday = datetime.datetime.strptime('2018-04-12', '%Y-%m-%d')
contents = json.loads(response.body)
txts = contents['data']
for txt in txts:
id = int(txt['id'])
content = txt['data']
at1 = str(txt['at'])
at = int(at1[:-3])
attime = datetime.datetime.fromtimestamp(at)
ct1 = str(txt['createTime'])
ct = int(ct1[:-3])
crtime = datetime.datetime.fromtimestamp(ct)
if txt['writer']:
nickname = txt['writer']['nick']
tximg = txt['writer']['avatar']
else:
nickname = ''
tximg = ''
yield {
'id' : id,
'content': content,
'attime': attime,
'crtime': crtime,
'nickname': nickname,
'tximg': tximg,
}
while today > fday:
fday = fday + datetime.timedelta(days=1)
date1 = str(fday)
next_url = "http://www.dutangapp.cn/u/toxic?date=" + date1
yield scrapy.Request(next_url, callback=self.parse)
由于是爬取 json 格式的内容,所以用到了 json!
说明:毒汤一言的 api 接口为http://www.dutangapp.cn/u/toxic?date=2018-8-17,后面加日期,会返回一串 json 格式的内容。如下所示
{"total":3,"data":[{"id":1451,"data":"如果全世界都不要你了,你要记得还有我,我也不要你。","at":1534435200000,"by":4891,"from":null,"to":null,"type":null,"taste":1,"view":2299,"like":23,"say":4,"forward":9,"createTime":1528022185000,"audit":1,"status":1,"writer":{"id":4891,"nick":"凯哥哥 V5","avatar":"http://thirdwx.qlogo.cn/mmopen/vi_32/vCXR1tKSkwLqDW7rMziclFibMcUUDApBEib2R3qYbY4oLMTplkEP5T4FEeUEPrxlb4a9GTXatfGicCW4XbXT1brPdA/132","msgCount":null},"actions":[],"format":1,"viewStr":"上千人"},{"id":1027,"data":"不要再说自己是一条单身狗,其实,你可能比不上狗…","at":1534435200000,"by":5501,"from":null,"to":null,"type":null,"taste":1,"view":2350,"like":22,"say":2,"forward":3,"createTime":1526695986000,"audit":1,"status":1,"writer":{"id":5501,"nick":".","avatar":"http://thirdwx.qlogo.cn/mmopen/vi_32/WUndm7hBa1EtibmjNYO4TgN96ZlNrHwSiayAjPrBmomUp7OntwtjPeYvVBppsMqjd65iaVL7FyrxrtvN6BcmeAb4g/132","msgCount":null},"actions":[],"format":1,"viewStr":"上千人"},{"id":877,"data":"有些人出现在你的生活里,是想告诉你,你真好骗啊!","at":1534435200000,"by":4116,"from":null,"to":null,"type":null,"taste":1,"view":2236,"like":16,"say":2,"forward":8,"createTime":1526269165000,"audit":1,"status":1,"writer":{"id":4116,"nick":"Weirdo.","avatar":"http://thirdwx.qlogo.cn/mmopen/vi_32/ZrPfqw4AbHfY47VqKlUnZ7wxWQqbdp3J9x2wNzkNYpYX0BG5S3R6JMt2Eiawpdx9iaYzkXE27JNgsp5vhgSicrqUg/132","msgCount":null},"actions":[],"format":1,"viewStr":"上千人"}]}
2.3 增加导入到 Mysql 数据库,修改 settings.py
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'yiyan.pipelines.YiyanPipeline': 300,
'yiyan.pipelines.YiyanEveryPipeline': 301,
'yiyan.pipelines.MySQLPipeline': 401,
}
DEFAULT_REQUEST_HEADERS = {
"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36",
}
FEED_EXPORT_ENCODING = 'utf-8'
MYSQL_DB_NAME = 'spydb'
MYSQL_HOST = 'localhost'
MYSQL_USER = 'spydb'
MYSQL_PASSWORD = 'spydb'
MYSQL_PORT = 3306
定义了数据和 User-Agent 等信息
2.4 修改 pipelines.py 文件,增加以下内容
import MySQLdb
class MySQLPipeline:
def open_spider(self, spider):
db = spider.settings.get('MYSQL_DB_NAME')
host = spider.settings.get('MYSQL_HOST')
port = spider.settings.get('MYSQL_PORT')
user = spider.settings.get('MYSQL_USER')
passwd = spider.settings.get('MYSQL_PASSWORD')
self.db_conn = MySQLdb.connect(host=host,db=db,user=user,passwd=passwd,port=port,charset='utf8')
self.db_cur = self.db_conn.cursor()
def close_spider(self,spider):
self.db_conn.commit()
self.db_conn.close()
def process_item(self,item,spider):
self.insert_db(item)
return item
def insert_db(self,item):
values = (
item['id'],
item['content'],
item['attime'],
item['crtime'],
item['nickname'],
item['tximg'],
)
sql = 'insert into yiyan values (%s,%s,%s,%s,%s,%s)'
self.db_cur.execute(sql,values)
这里是爬取了从 2018-04-12 到 2018-08-17 也就是今天的全部数据。自己去数据库建一张表!
2.5 爬取数据,并导入数据库
scrapy crawl yiyan
2.6 查看数据库的内容
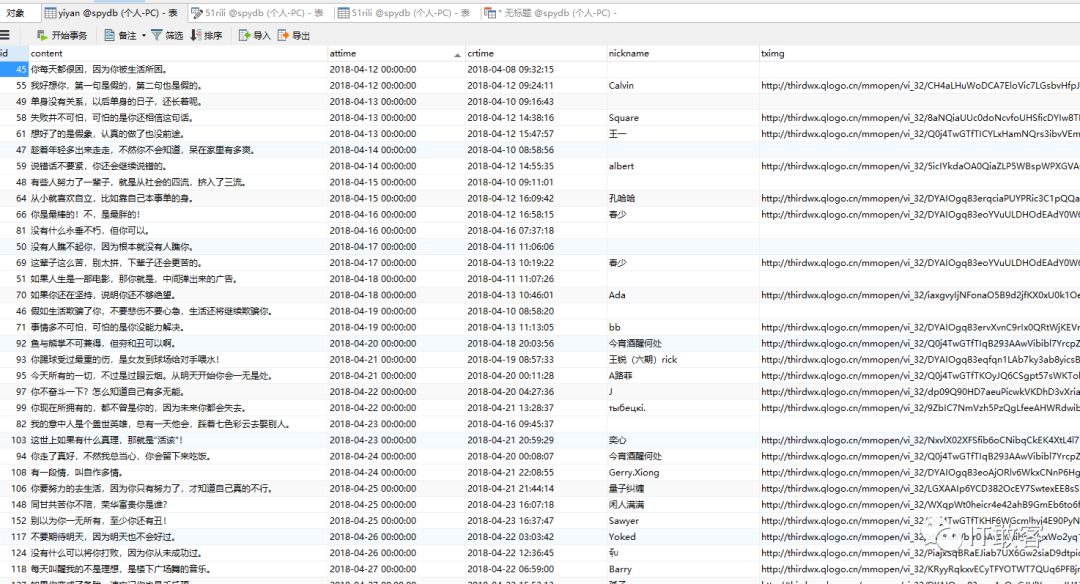
2.7 以后每天定时抓取一个当天的数据。
在 yiyan/yiyan/spiders/目录下,新建一个 yiyan_everyday_spider.py 文件,内容如下
# -*- coding:utf-8 -*-
import scrapy
import datetime
import json
class YiyanEverySpider(scrapy.Spider):
name = "yiyan_every"
tdy = datetime.datetime.now().strftime('%Y-%m-%d')
tday = str(tdy)
url = "http://www.dutangapp.cn/u/toxic?date=" + tday
start_urls = [url]
def parse(self, response):
contents = json.loads(response.body)
txts = contents['data']
for txt in txts:
id = int(txt['id'])
content = txt['data']
at1 = str(txt['at'])
at = int(at1[:-3])
attime = datetime.datetime.fromtimestamp(at)
ct1 = str(txt['createTime'])
ct = int(ct1[:-3])
crtime = datetime.datetime.fromtimestamp(ct)
if txt['writer']:
nickname = txt['writer']['nick']
tximg = txt['writer']['avatar']
else:
nickname = ''
tximg = ''
yield {
'id' : id,
'content': content,
'attime': attime,
'crtime': crtime,
'nickname': nickname,
'tximg': tximg,
}
再次运行 scrapy crawl yiyan,会插入当天的数据!
3 爬取 51 万年历上面的数据
原理同上,就不再阐述了。主要是知道 51 万年历的 api 接口地址为http://www.51wnl.com/api/getdailysentenceweb.ashx?dt=2017-04-28,好了看一下最后的爬取结果。

举一反三:
1、有了以上的数据,可以自己做一些 api 的接口出来,主要是防止其他网站不能访问的时候。
2、如果将 scrapy 和 django 结合起来用,效果会更好,只传参数,数据不落地,但是目前还不知道怎么用。





