





序言:集成学习(Ensemble Learning)可以称得上一种比较火爆的机器学习方法了,但它本身并不能算一种机器学习算法,只能说是一种优化的方法或者策略。它通过构建多个弱分类器来合成一个强分类器,进而达到比单个模型更好的回归和分类表现,也就是我们说的“博采众长”。可用于分类问题、回归问题、特征选取、异常点检测集成等。
内容目录
集成学习(1)概念(2)原因(3)应用(4)常用算法Bagging和Boosting(1)Bagging(2)Boosting结合方法(1)均值法(2)投票法
集成学习
(1)概念
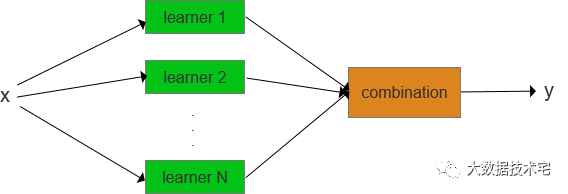
大多数集成学习方法使用同一种基学习算法产生同质的基学习器(基相同种类的学习器),生成同质集成(homogeneous ensemble);与之对应的,是使用多种学习算法训练不同种类的学习器,构建异质集成(heterogeneous ensemble)。在异质集成中,由于没有单一的基学习算法,相较于基学习器,人们更倾向于称这些学习器为个体学习器(individual learner)或组件学习器(component learner)。
一般来讲,构建集成的步骤有两个:首先是产生基学习器,然后是将它们结合起来。为获得一个较好的集成,通常认为每个基学习器应该尽可能准确,同时,尽可能不同。这里值得一提的是,构建一个集成的计算代价未必会显著高于构建单一的学习器。因为,在日常学习或工作中,构建单一学习器,在模型选择和调参方面通常会尝试不同方案,迭代产生多个版本的模型,这与集成学习中构建多个基学习器的代价是相当的,至于集成后期的结合,由于结合策略往往比较简单,所以并不会产生过高的计算代价。
(2)原因
模型选择
在概念部分,我们有提到集成学习是由多个弱分类器构成的,如果这些分类器存在差异(大到不同算法,小到不同配置参数),就会导致最终生成不同的分类决策边界(划分类别时的线、平面等),即在生成的决策边界时犯不同的错。如果此时我们采用集成的策略,那么就会综合多种分类器的结果来给定最终的决策边界,达到减少整体错误的目的。
分治
数据集规模过大或过小
数据源种类多
(3)应用
KDD cup作为最著名的数据挖掘竞赛,自1997年以来每年举办,吸引了全球大量数据挖掘队伍的积极参与。竞赛包含种类丰富的实际任务,诸如:网络入侵检测、肺栓塞检测、客户关系管理、教育数据挖掘和音乐推荐等。在诸多机器学习技术中,集成学习方法获得了高度的关注和广泛使用。
集成学习方法还被应用于解决计算机辅助医疗诊断中的多种任务,尤其用于提升诊断的可靠性方面。周志华等人也曾设计一种双层集成架构用于肺癌细胞检测。此外,集成学习还被应用到多个其他领域,如:信用卡欺诈检测、破产预测、蛋白质结构分类、种群分布预测、天气预报、航空发动机缺陷检测、音乐风格和艺术家识别。
(4)常用算法
集成学习按照集成的思想,可以分为Bagging、Boosting、Stacking、Blending,共4种框架(见下图),由于Bagging和Boosting讨论的最多,所以咱们这篇文章也将把接下来的篇幅重点分给这两种算法。
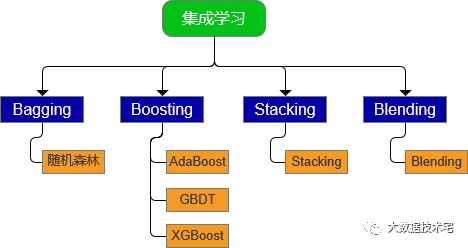
Bagging和Boosting
(1)Bagging
从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本。共进行k轮抽取,得到k个训练集(k个训练集之间是相互独立的)。 每次使用一个训练集得到一个模型,k个训练集共得到k个模型(不同模型在训练时互不影响,不存在依赖其他模型结果的情况)。 将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果,(所有模型的重要性相同)。

(2)Boosting
Boosting算法的基本思想是,每次在抽取数据时,都会更新其权重,提高上一次分错的数据集的权重,最后得到T个基分类器。
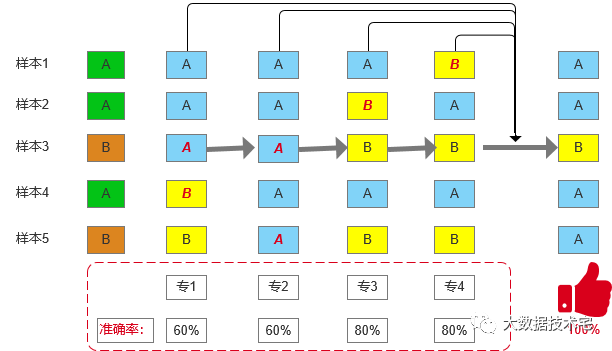
为便于各位小伙伴对Bagging和Boosting算法更好的记忆,这里同样以类似上述专家的例子讲述Boosting的过程(见上图)。为便于绘图(绘图花费笔者不少时间哦,觉得还不错的小伙伴麻烦点个“在看”,谢谢),这里把专家个数由6位调整为4位。好了,现在开始带你了解Boosting的流程。第一步,专家1对五个样本进行类别判断,从图片可知,专家1的正确率为60%;第二步,专家2开始基于专家1的预测结果进行判断,他会试图纠正专家1所犯的错误(虽然还是会犯少量的错误)。由于专家1是在对样本3和样本4的类别进行判断时出错的,所以专家2在进行数据抽取时会先提高样本3和样本4的权重,然后再进行预测。通过图片可知,专家2在样本4的判断上正确;第三步,专家3依据上一个专家(专家2)的结果,会采用专家2的做法,继续提高被专家2分错的样本3和样本5的权重;第四步,专家4会尝试纠正专家3在样本2上所犯的错;最后,通过对4位专家的预测结果采用设定的集合策略给出最终的判断结果。
结合方法
集成学习方法通过结合一组基学习器来提升泛化能力,而非从中选取一个最好的。这里的结合的意思就是采用某种数学方法来融合不同基学习期的结果,实现最终预测结果的输出。常见的结合方法有均值法和投票法
(1)均值法
均值法分为简单平均法和加权平均法。简单平均法直接对个体学习器的输出取均值来获取结合后的输出结果;加权平均法通过对每一学习器的输出结果赋予不同的重要性权重来获取结合输出结果。
(2)投票法
对于多值输出的问题,投票法是最常用也是最基本的结合方法。主要有绝大多数投票法、相对多数投票法、加权投票法、软投票法。
绝大多数投票法:最常用的投票方法。其中,每个分类器都会给一个类别标记进行投票,最终的输出类别标记为获取票数过半的标记;如果所有类别标记获取票数均不过半,则拒绝预测。
相对多数投票法:与绝大多数投票法不同,相对多数投票法仅需获胜方票数最多即可,而平局时则任选一个。显然,该方法不会出现拒绝预测的现象。 加权投票法:如果个体分类器性能不均等,投票时给性能强的分类器更高权重是合理的,加权投票法就是在相对多数投票法的集成输出时对于不同分类器赋予不同权值。 软投票法:对于生成二值二类标记的个体分类器,可以使用上述三种投票法,但对于生成类概率输出的个体分类器,通常会采用软投票法。
