在大规模数据量的数据分析及建模任务中,针对全量数据进行挖掘分析时会十分耗时和占用集群资源,一般情况下只需要抽取一小部分数据进行分析就可以了。下面讲讲Hive的三种数据抽样方法:随机抽样、数据块抽样,分桶抽样。建立一张样表:uid,0-500,cost,1-1000随机数。
一、随机抽样
1、distribute by rand() sort by rand()
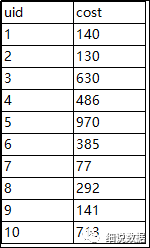
使用rand()函数进行随机抽样,limit关键字限制抽样返回的数据,其中rand函数前的distribute和sort关键字可以保证数据在mapper和reducer阶段是随机分布的。这里我取的是限制cost大于100,随机取10个数select * from demo
where cost>100
distribute by rand() sort by rand()
limit 10
结果:
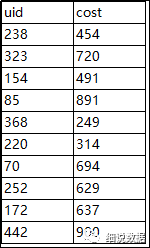
2、order by rand()
select * from demo
where cost>100
order by rand()limit 10
3、cluster by rand()
select * from demo
cluster by rand() limit 10
这里插一个知识点:HIVE中,order by、sort by、 distribute by和 cluster by区别:order by主要是做全局排序。只要hive的sql中指定了order by,那么所有的数据都会到同一个reducer进行处理,不管有多少map,也不管文件有多少的block,只会启动一个reducer 。但是对于大量数据这将会消耗很长的时间去执行。sort by是局部排序,每个reduce端都会进行排序,也就是局部有序,可以指定多个reduce。distribute by的功能是控制map结果的分发,它会将具有相同字段的map输出分发到一个reduce节点上做处理。某种情况下,我们需要控制某个特定行到某个reducer中,这种操作一般是为后续可能发生的聚集操作做准备。通常和sort by一起用,distribute by必须要写在sort by之前,理解成:按照XX字段分区,再按照XX字段排序。cluster by:当distribute by和sorts by字段相同时,可以使用cluster by方式代替。cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能像distribute by一样去指定排序的规则为ASC或者DESC。
二、数据块抽样
1、根据hive表数据的大小按比例抽取数据,例如:取10%。
select * from demo
tablesample(10 percent)
2、指定抽样数据的大小,单位为M,例如取10M大小数据。
select * from demo
tablesample(10M)
3、指定抽样数据的行数,其中n代表每个map任务均取n行数据,例如取10行数据。
select * from demo
tablesample(10 rows)
结果:
三、分桶抽样
hive中分桶其实就是根据某一个字段Hash取模,放入指定数据的桶中,比如将表按照ID分成100个桶,其算法是hash(id)%100,hash(id)%100 = 0的数据被放到第一个桶中,hash(id)%100 = 1的记录被放到第二个桶中。例如随机分成10个桶,抽样第一个桶的数据。select * from demo
tablesample(bucket 1 out of 10 on rand())
按比例和分桶的抽样的数量都没有严格限制数量或者行数来得更准确。
随机抽样实现按比例抽样:
select * from
(select *, rand() as ratio from demo)tmp
where ratio>=0
and ratio<=0.05
如果不想随机抽样,想更精准的抽样,可以用row_number()排序,或者ntile()分组后再抽样。





