




1. concat
-- return the concatenation of str1、str2、..., strN-- SparkSQLselect concat('Spark', 'SQL');
2. concat_ws
在拼接的字符串中间添加某种分隔符:concat_ws(sep, [str | array(str)]+)。
参数1:分隔符,如 - ;参数2:要拼接的字符串(可多个)
-- return the concatenation of the strings separated by sep-- Spark-SQLselect concat_ws("-", "Spark", "SQL");
3. encode
设置编码格式:encode(str, charset)。
参数1:要进行编码的字符串 ;参数2:使用的编码格式,如UTF-8
-- encode the first argument using the second argument character setselect encode("HIVE", "UTF-8");
4. decode
转码:decode(bin, charset)。
参数1:进行转码的binary ;参数2:使用的转码格式,如UTF-8
-- decode the first argument using the second argument character setselect decode(encode("HIVE", "UTF-8"), "UTF-8");
5. format_string printf
-- returns a formatted string from printf-style format stringsselect format_string("Spark SQL %d %s", 100, "days");
6. initcap lower upper
initcap:将每个单词的首字母转为大写,其他字母小写。单词之间以空白分隔。
upper:全部转为大写。
-- Spark Sqlselect initcap("spaRk sql");-- SPARK SQLselect upper("sPark sql");-- spark sqlselect lower("Spark Sql");
7. length
-- 返回4select length("Hive");
8. lpad rpad
返回固定长度的字符串,如果长度不够,用某种字符进行补全。
lpad(str, len, pad):左补全
rpad(str, len, pad):右补全
注意:如果参数str的长度大于参数len,则返回的结果长度会被截取为长度为len的字符串
-- vehiselect lpad("hi", 4, "ve");-- hiveselect rpad("hi", 4, "ve");-- sparselect lpad("spark", 4, "ve");
9. trim ltrim rtrim
去除空格或者某种字符。
trim(str) trim(trimStr, str):首尾去除。
ltrim(str) ltrim(trimStr, str):左去除。
rtrim(str) rtrim(trimStr, str):右去除。
-- hiveselect trim(" hive ");-- arkSQLSSELECT ltrim("Sp", "SSparkSQLS") as tmp;
10. regexp_extract
-- 2000select regexp_extract("1000-2000", "(\\d+)-(\\d+)", 2);
11. regexp_replace
-- r-rselect regexp_replace("100-200", "(\\d+)", "r");
12. repeat
-- aaselect repeat("a", 2);
13. instr locate
-- returns the (1-based) index of the first occurrence of substr in str.-- 6select instr("SparkSQL", "SQL");-- 0select locate("A", "fruit");
14. space
select concat(space(2), "A");
15. split
-- ["one","two"]select split("one two", " ");
16. substr substring_index
-- k SQLselect substr("Spark SQL", 5);-- 从后面开始截取,返回SQLselect substr("Spark SQL", -3);-- kselect substr("Spark SQL", 5, 1);-- org.apache。注意:如果参数3为负值,则从右边取值select substring_index("org.apache.spark", ".", 2);
17. translate
-- The translate will happen when any character in the string matches the character in the `matchingString`-- A1B2C3select translate("AaBbCc", "abc", "123");
1. get_json_object
-- v2select get_json_object('{"k1": "v1", "k2": "v2"}', '$.k2');
2. from_json
select tmp.k from (select from_json('{"k": "fruit", "v": "apple"}','k STRING, v STRING', map("","")) as tmp);
-- 可以把所有字段转化为json字符串,然后表示成value字段select to_json(struct(*)) AS value;
1. current_date current_timestamp
select current_date;select current_timestamp;
2. 从日期时间中提取字段/格式化时间
1)year、month、day、dayofmonth、hour、minute、second
-- 20select day("2020-12-20");
-- 7select dayofweek("2020-12-12");
/*** Extracts the week number as an integer from a given date/timestamp/string.** A week is considered to start on a Monday and week 1 is the first week with more than 3 days,* as defined by ISO 8601** @return An integer, or null if the input was a string that could not be cast to a date* @group datetime_funcs* @since 1.5.0*/def weekofyear(e: Column): Column = withExpr { WeekOfYear(e.expr) }-- 50select weekofyear("2020-12-12");
4)trunc
-- 2020-01-01select trunc("2020-12-12", "YEAR");-- 2020-12-01select trunc("2020-12-12", "MM");
5)date_trunc
参数:YEAR、YYYY、YY、MON、MONTH、MM、DAY、DD、HOUR、MINUTE、SECOND、WEEK、QUARTER
-- 2012-12-12 09:00:00select date_trunc("HOUR" ,"2012-12-12T09:32:05.359");
6)date_format
-- 2020-12-12select date_format("2020-12-12 12:12:12", "yyyy-MM-dd");
3. 日期时间转换
1)unix_timestamp
返回当前时间的unix时间戳。
select unix_timestamp();-- 1609257600select unix_timestamp("2020-12-30", "yyyy-MM-dd");
2)from_unixtime
将unix epoch(1970-01-01 00:00:00 UTC)中的秒数转换为以给定格式表示当前系统时区中该时刻的时间戳的字符串。
select from_unixtime(1609257600, "yyyy-MM-dd HH:mm:ss");
3)to_unix_timestamp
-- 1609257600select to_unix_timestamp("2020-12-30", "yyyy-MM-dd");
4)to_date date
-- 2020-12-30select to_date("2020-12-30 12:30:00");select date("2020-12-30");
5)to_timestamp
select to_timestamp("2020-12-30 12:30:00");
6)quarter
-- 4select quarter("2020-12-30");
4. 日期、时间计算
1)months_between(end, start)
返回两个日期之间的月数。参数1为截止时间,参数2为开始时间
-- 3.94959677select months_between("1997-02-28 10:30:00", "1996-10-30");
2)add_months
-- 2020-12-28select add_months("2020-11-28", 1);
3)last_day(date)
-- 2020-12-31select last_day("2020-12-01");
4)next_day(start_date, day_of_week)
返回某时间后the first date基于specified day of the week。
参数1:开始时间。
参数2:Mon、Tue、Wed、Thu、Fri、Sat、Sun。
-- 2020-12-07select next_day("2020-12-01", "Mon");
5)date_add(start_date, num_days)
-- 2020-12-02select date_add("2020-12-01", 1);
6)datediff(endDate, startDate)
-- 3select datediff("2020-12-01", "2020-11-28");
7)关于UTC时间
-- to_utc_timestamp(timestamp, timezone) - Given a timestamp like '2017-07-14 02:40:00.0', interprets it as a time in the given time zone, and renders that time as a timestamp in UTC. For example, 'GMT+1' would yield '2017-07-14 01:40:00.0'.select to_utc_timestamp("2020-12-01", "Asia/Seoul") ;-- from_utc_timestamp(timestamp, timezone) - Given a timestamp like '2017-07-14 02:40:00.0', interprets it as a time in UTC, and renders that time as a timestamp in the given time zone. For example, 'GMT+1' would yield '2017-07-14 03:40:00.0'.select from_utc_timestamp("2020-12-01", "Asia/Seoul");
开窗函数格式通常满足:
OVER (
[PARTITION BY partition_expression,…]
[ORDER BY sort_expression, … [ASC|DESC]])
function_name: 函数名称,比如SUM()、AVG()
partition_expression:分区列
sort_expression:排序列
注意:以下举例涉及的表employee中字段含义:name(员工姓名)、dept_no(部门编号)、salary(工资)
如果按升序排列,则统计:小于等于当前值的行数/总行数(number of rows ≤ current row)/(total number of rows)。如果是降序排列,则统计:大于等于当前值的行数/总行数。用于累计统计。
1)统计小于等于当前工资的人数占总人数的比例 ,用于累计统计
SELECTname,dept_no,salary,cume_dist() OVER (ORDER BY salary) as cumeFROM employee;
SELECTname,dept_no,salary,cume_dist() OVER (PARTITION BY dept_no ORDER BY salary) as cume_valFROM employee;
2. lead(value_expr[,offset[,default]])
用于统计窗口内往下第n行值。第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)。
SELECTname,dept_no,salary,lead(salary, 1) OVER (PARTITION BY dept_no ORDER BY salary) as lead_valFROM employee;
3. lag(value_expr[,offset[,default]])
与lead相反,用于统计窗口内往上第n行值。第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)。
举例:按照部门统计每个部门员工的工资以及小于等于该员工工资的上一个员工的工资
SELECTname,dept_no,salary,lag(salary, 1) OVER (PARTITION BY dept_no ORDER BY salary) as lag_valFROM employee;
4. first_value
取分组内排序后,截止到当前行,第一个值。
举例:按照部门统计每个部门员工工资以及该部门最低的员工工资
SELECTname,dept_no,salary,first_value(salary) OVER (PARTITION BY dept_no ORDER BY salary) as first_valFROM employee;
5. last_value
取分组内排序后,截止到当前行,最后一个值。
举例:按部门分组,统计每个部门员工工资以及该部门最高的员工工资
SELECTname,dept_no,salary,last_value(salary) OVER (PARTITION BY dept_no ORDER BY salary RANGEBETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as last_valFROM employee;
注意:
last_value默认的窗口是RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,表示当前行永远是最后一个值,需改成RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING。
此外:
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW:为默认值,即当指定了ORDER BY从句,而省略了window从句 ,表示从开始到当前行(当前行永远是最后一个值)。
RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING:表示从当前行到最后一行。
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING:表示所有行。
6. rank
对组中的数据进行排名,如果名次相同,则排名也相同,但是下一个名次的排名序号会出现不连续。比如查找具体条件的topN行。RANK() 排序为 (1,2,2,4)。
dense_rank函数的功能与rank函数类似,dense_rank函数在生成序号时是连续的,而rank函数生成的序号有可能不连续。当出现名次相同时,则排名序号也相同。而下一个排名的序号与上一个排名序号是连续的。
DENSE_RANK() 排序为 (1,2,2,3)。
8. SUM/AVG/MIN/MAX
数据:
id time pv1 2015-04-10 11 2015-04-11 31 2015-04-12 61 2015-04-13 31 2015-04-14 22 2015-05-15 82 2015-05-16 6
结果:
SELECT id,time,pv,SUM(pv) OVER(PARTITION BY id ORDER BY time) AS pv1, -- 默认为从起点到当前行SUM(pv) OVER(PARTITION BY id ORDER BY time ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS pv2, --从起点到当前行,结果同pv1SUM(pv) OVER(PARTITION BY id) AS pv3, --分组内所有行SUM(pv) OVER(PARTITION BY id ORDER BY time ROWS BETWEEN 3 PRECEDING AND CURRENT ROW) AS pv4, --当前行+往前3行SUM(pv) OVER(PARTITION BY id ORDER BY time ROWS BETWEEN 3 PRECEDING AND 1 FOLLOWING) AS pv5, --当前行+往前3行+往后1行SUM(pv) OVER(PARTITION BY id ORDER BY time ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS pv6 ---当前行+往后所有行FROM data;
NTILE(n),用于将分组数据按照顺序切分成n片,返回当前切片值。
NTILE不支持ROWS BETWEEN,比如 NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW)。
从1开始,按照顺序,生成分组内记录的序列。
ROW_NUMBER() 的应用场景非常多,比如获取分组内排序第一的记录。
以上函数都是可以直接在SQL中应用的。
那么如果是在Spark SQL的DataFrame/DataSet的算子中调用,可以参考DataFrame/DataSet的算子以及org.apache.spark.sql.functions._下的函数:
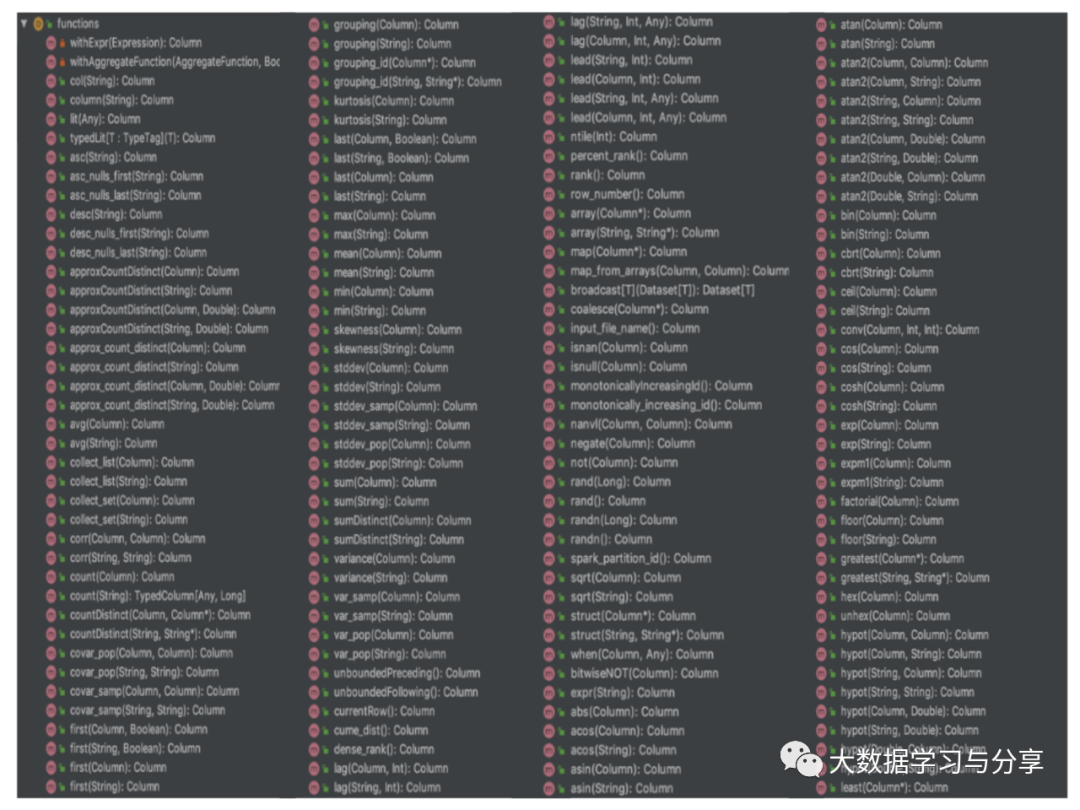

推荐文章:
Hive常用性能优化方法实践全面总结
SparkSQL真的不支持存储NullType类型数据到Parquet吗?
经典的SparkSQL/Hive-SQL/MySQL面试-练习题
Spark在处理数据的时候,会将数据都加载到内存再做处理吗?
如何获取流式应用程序中checkpoint的最新offset
关注大数据学习与分享,获取更多技术干货

