





导读:我们常说我们生活在信息时代,实际上,我们更多的还是生活在数据时代。因为从过去到现在累积了大量的数据,对数据的挖掘和分析也仅是从最近几年大数据和人工智能技术的发展而兴起。我们对现有数据价值的利用还远低于数据本身拥有的价值。随着数据在党的十九届四中全会中与劳动、资本、土地、知识、技术、管理等一起被列为生产要素,数据价值的挖掘将会越来越深入。数据挖掘在《Data Mining》一书中的解释就是从大量数据中挖掘有趣模式和知识的过程。既然未来已来,我们就要顺应时代发展,掌握必备技能。
本系列将会介绍数据挖掘相关的知识。首先会先学习数据挖掘的重要算法和实战,在有了一个较为清晰的认识之后,再开始从理论上理清数据挖掘的理论体系,与大家共勉。
今天首先分享最经典的数据挖掘算法Apriori算法,它属于关联规则挖掘算法,我们常听到的“啤酒与尿布”的故事就是源于此类算法。
关联规则
Apriori 算法
1.原理介绍
Apriori算法主要用来挖掘频繁模式。频繁模式就是在数据中频繁出现的模式,可以分为频繁项集、频繁子序列和频繁子结构。频繁项集一般是指频繁地在数据集中一起出现的商品集合,例如大家去超市频繁一起购买的牛奶和面包,啤酒和尿布。频繁子序列相当于从时间维度上进行了特征提取,例如顾客可能会先买便携机,再买数码相机,然后买内存条、U盘和硬盘等,这样的一个模式就是频繁序列模式。子结构其实就设计更复杂的结构相识,可能是频繁项集和频繁子序列结合在一起。
通过挖掘频繁模式,也就是知道了哪些物品之间具有较强的关联性,这样超市在进行物品摆放的时候就可以将他们放在一起,诱导你捆绑消费。
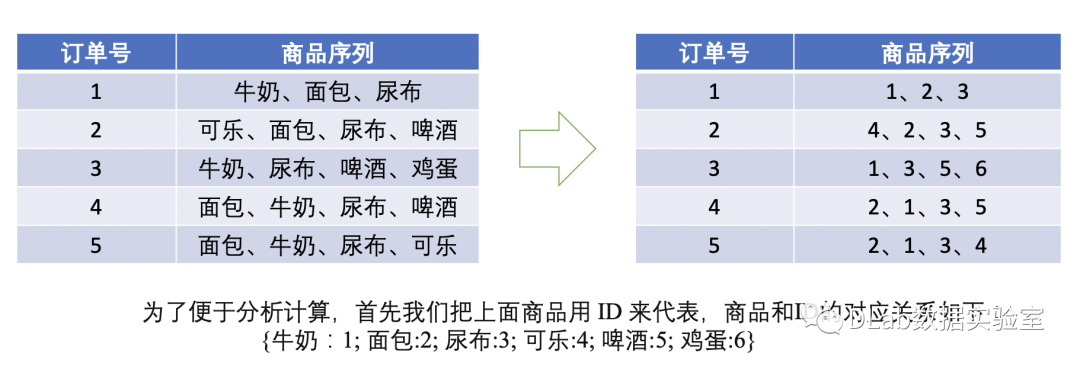
Apriori算法其实就是找出哪些商品组合是高频率。在进行频繁项集挖掘之前,首先需要明白三个概念:
支持度:支持度就是指某个项在所有订单中出现的次数比总订单数,例如“牛奶”在五次订单中出现了 4 次,那么这 5 笔订单中“牛奶”的支持度就是 4/5=0.8;同理“牛奶 + 面包”出现了 3 次,那么这 5 笔订单中“牛奶 + 面包”的支持度就是 3/5=0.6。
置信度:置信度类似于条件概率,它指的就是当你购买了商品 A,会有多大的概率购买商品 B;例如上面的例子中置信度(牛奶→啤酒)=2(购买牛奶的同时有两次买了啤酒)/4(购买牛奶的次数)=0.5,代表如果你购买了牛奶,会有50%的概率买啤酒;同理,置信度(啤酒→牛奶)=2/3=0.67,代表如果你购买了啤酒,会有67%概率会购买牛奶。
提升度:提升度类似于一个评价指标,就是评价关联规则的效果,比如我们把商品A和B放在一起,商品A的出现对商品B的出现概率有多大的提升。我们的目标都是为了提高提升度。
提升度 (A→B)= 置信度 (A→B)/ 支持度 (B)
现在我们来看一下如何计算频繁项集:
频繁1项集
首先,我们先计算单个商品的支持度,也就是得到频繁项K=1项的支持度:
支持度(ID=1) = 4(在5个订单中出现4次)/5(总共5个订单)= 0.8
支持度(ID=2) = 4(在5个订单中出现4次)/5(总共5个订单)= 0.8
...
支持度(ID=6) = 1(在5个订单中出现1次)/5(总共5个订单)= 0.2
频繁1项集:如果我们规定支持度超过50%的为频繁项集,那么在频繁项K=1时的频繁项集为ID集合{1,2,3,5}
频繁2项集
支持度ID{1,2} = 3(该组合在5次订单中出现了3次)/5 = 0.6
我们按照此方法依次算出ID{1,3}、ID{1,5}、ID{2,3}、ID{2,5}、ID{3,5}的支持度,然后找出支持度大于50%的频繁项集就是频繁2项集;
分别是{1,2} {2,3} {3,5}
继续沿用此方法,可以找出频繁3项集甚至是频繁4项集等等,所以总结一下Apriori 算法的递归流程:
1、K=1,计算 K 项集的支持度;
2、筛选掉小于最小支持度的项集;
3、如果项集为空,则对应 K-1 项集的结果为最终结果。
否则 K=K+1,重复 1-3 步。
2.使用场景
Apriori算法主要用于挖掘频繁模式,找出关联规则,提示商家哪些商品是经常被一起购买,将关联度高的商品放在一起促销或者捆绑消费,从而帮助电商平台捆绑推荐商品,提高成交量和营业额。
3.算法实现
最后,提供一份参考实现代码,来体验一下这个算法。
"""# Apriori算法实现"""def load_data_set():"""Load a sample data set (From Data Mining: Concepts and Techniques, 3th Edition)Returns:A data set: A list of transactions. Each transaction contains several items."""data_set = [['l1', 'l2', 'l5'], ['l2', 'l4'], ['l2', 'l3'],['l1', 'l2', 'l4'], ['l1', 'l3'], ['l2', 'l3'],['l1', 'l3'], ['l1', 'l2', 'l3', 'l5'], ['l1', 'l2', 'l3']]return data_setdef create_C1(data_set):"""Create frequent candidate 1-itemset C1 by scaning data set.Args:data_set: A list of transactions. Each transaction contains several items.Returns:C1: A set which contains all frequent candidate 1-itemsets"""C1 = set()for t in data_set:for item in t:item_set = frozenset([item])C1.add(item_set)return C1def is_apriori(Ck_item, Lksub1):"""Judge whether a frequent candidate k-itemset satisfy Apriori property.Args:Ck_item: a frequent candidate k-itemset in Ck which contains all frequentcandidate k-itemsets.Lksub1: Lk-1, a set which contains all frequent candidate (k-1)-itemsets.Returns:True: satisfying Apriori property.False: Not satisfying Apriori property."""for item in Ck_item:sub_Ck = Ck_item - frozenset([item])if sub_Ck not in Lksub1:return Falsereturn Truedef create_Ck(Lksub1, k):"""Create Ck, a set which contains all all frequent candidate k-itemsetsby Lk-1's own connection operation.Args:Lksub1: Lk-1, a set which contains all frequent candidate (k-1)-itemsets.k: the item number of a frequent itemset.Return:Ck: a set which contains all all frequent candidate k-itemsets."""Ck = set()len_Lksub1 = len(Lksub1)list_Lksub1 = list(Lksub1)for i in range(len_Lksub1):for j in range(1, len_Lksub1):l1 = list(list_Lksub1[i])l2 = list(list_Lksub1[j])l1.sort()l2.sort()if l1[0:k-2] == l2[0:k-2]:Ck_item = list_Lksub1[i] | list_Lksub1[j]# pruningif is_apriori(Ck_item, Lksub1):Ck.add(Ck_item)return Ckdef generate_Lk_by_Ck(data_set, Ck, min_support, support_data):"""Generate Lk by executing a delete policy from Ck.Args:data_set: A list of transactions. Each transaction contains several items.Ck: A set which contains all all frequent candidate k-itemsets.min_support: The minimum support.support_data: A dictionary. The key is frequent itemset and the value is support.Returns:Lk: A set which contains all all frequent k-itemsets."""Lk = set()item_count = {}for t in data_set:for item in Ck:if item.issubset(t):if item not in item_count:item_count[item] = 1else:item_count[item] += 1t_num = float(len(data_set))for item in item_count:if (item_count[item] t_num) >= min_support:Lk.add(item)support_data[item] = item_count[item] t_numreturn Lkdef generate_L(data_set, k, min_support):"""Generate all frequent itemsets.Args:data_set: A list of transactions. Each transaction contains several items.k: Maximum number of items for all frequent itemsets.min_support: The minimum support.Returns:L: The list of Lk.support_data: A dictionary. The key is frequent itemset and the value is support."""support_data = {}C1 = create_C1(data_set)L1 = generate_Lk_by_Ck(data_set, C1, min_support, support_data)Lksub1 = L1.copy()L = []L.append(Lksub1)for i in range(2, k+1):Ci = create_Ck(Lksub1, i)Li = generate_Lk_by_Ck(data_set, Ci, min_support, support_data)Lksub1 = Li.copy()L.append(Lksub1)return L, support_datadef generate_big_rules(L, support_data, min_conf):"""Generate big rules from frequent itemsets.Args:L: The list of Lk.support_data: A dictionary. The key is frequent itemset and the value is support.min_conf: Minimal confidence.Returns:big_rule_list: A list which contains all big rules. Each big rule is representedas a 3-tuple."""big_rule_list = []sub_set_list = []for i in range(0, len(L)):for freq_set in L[i]:for sub_set in sub_set_list:if sub_set.issubset(freq_set):conf = support_data[freq_set] support_data[freq_set - sub_set]big_rule = (freq_set - sub_set, sub_set, conf)if conf >= min_conf and big_rule not in big_rule_list:# print freq_set-sub_set, " => ", sub_set, "conf: ", confbig_rule_list.append(big_rule)sub_set_list.append(freq_set)return big_rule_listif __name__ == "__main__":"""Test"""data_set = load_data_set()L, support_data = generate_L(data_set, k=3, min_support=0.2)big_rules_list = generate_big_rules(L, support_data, min_conf=0.7)for Lk in L:print "="*50print "frequent " + str(len(list(Lk)[0])) + "-itemsets\t\tsupport"print "="*50for freq_set in Lk:print freq_set, support_data[freq_set]print "Big Rules"for item in big_rules_list:print item[0], "=>", item[1], "conf: ", item[2]
Apriori算法实现起来在时空复杂度上都不是最优的,下一期将会介绍Apriori算法的改进版本,敬请期待吧~

●Spark原理与实战--SparkStreaming流处理(二)

文章都看完了 不点个
不点个 吗
吗
欢迎 点赞、在看、分享 三连哦~~
