




不点蓝字关注,我们哪来故事?
导读:大数据计算发展至今,已经形成了一个百花齐放的大数据生态,通用计算、定制开发,批量处理、实时计算,关系查询、图遍历以及机器学习等等,我们都可以找到各种对应的计算引擎来协助我们处理这些任务。本系列文章拟以大数据平台从低到高的层次为主线,梳理整个大数据计算生态组件及其功能。
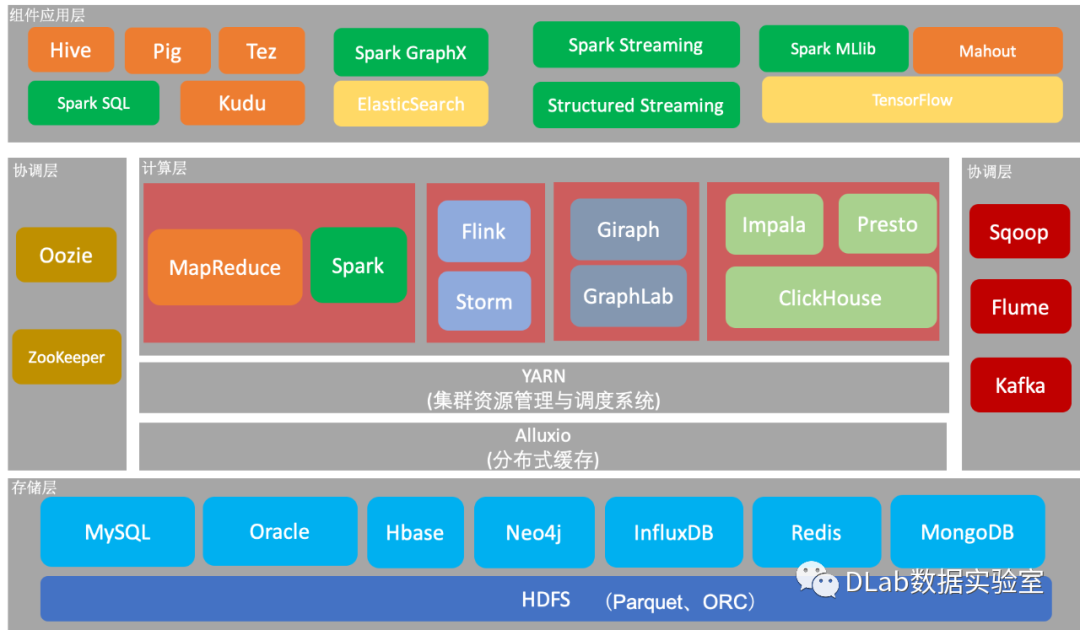
在[大数据计算生态之数据存储]中介绍了存储层中的各个存储组件的分类及功能。有了数据之后,各个应用就可以利用这些数据进行不同维度或角度的分析,从而形成不同的数据价值产品。支撑这一过程最重要的就是计算引擎。计算层是整个大数据计算生态的核心,计算引擎为各个数据任务提供算力支持。本文将详细介绍计算层的各个计算引擎。
本文经授权转自公众号DLab数据实验室 作者 | 小舰 出品 | DLab数据实验室(ID:rucdlab)
导读:大数据计算发展至今,已经形成了一个百花齐放的大数据生态,通用计算、定制开发,批量处理、实时计算,关系查询、图遍历以及机器学习等等,我们都可以找到各种对应的计算引擎来协助我们处理这些任务。本系列文章拟以大数据平台从低到高的层次为主线,梳理整个大数据计算生态组件及其功能。
在[大数据计算生态之数据存储]中介绍了存储层中的各个存储组件的分类及功能。有了数据之后,各个应用就可以利用这些数据进行不同维度或角度的分析,从而形成不同的数据价值产品。支撑这一过程最重要的就是计算引擎。计算层是整个大数据计算生态的核心,计算引擎为各个数据任务提供算力支持。本文将详细介绍计算层的各个计算引擎。

01
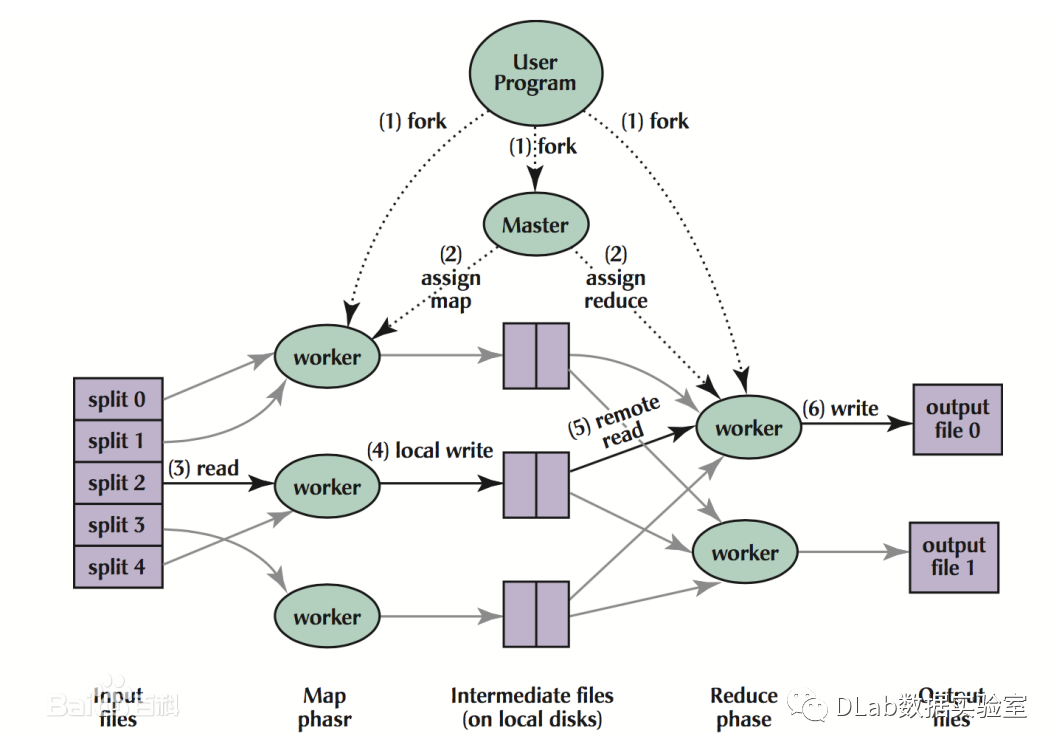
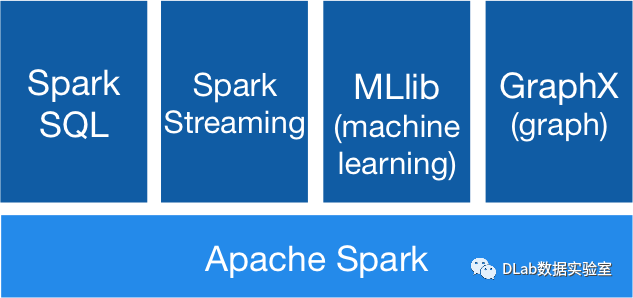
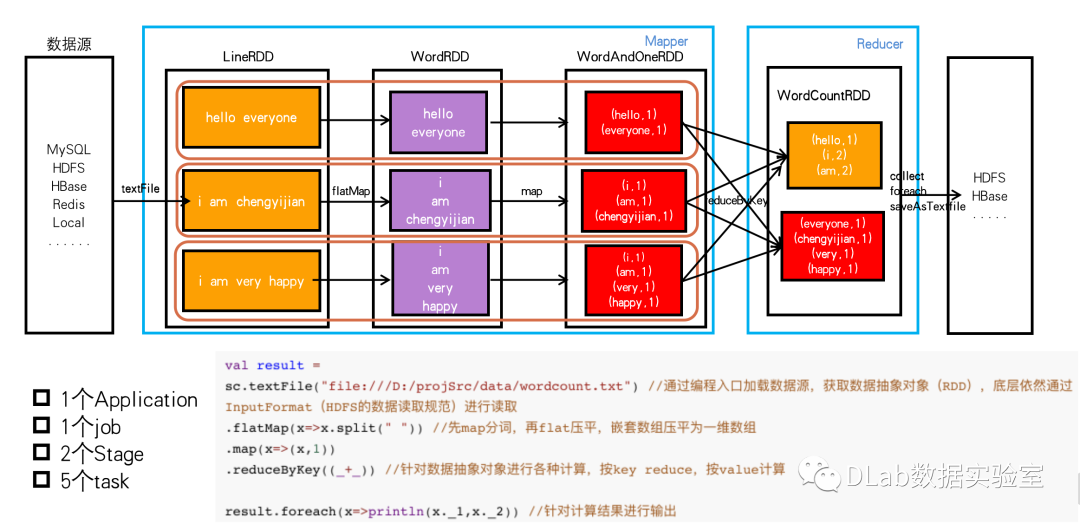
批处理计算
02
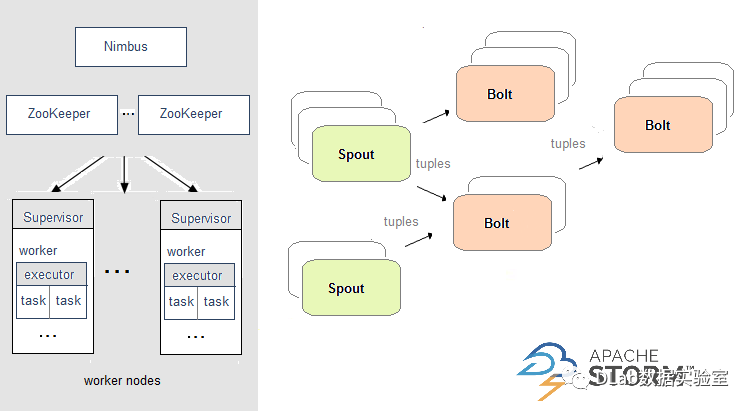
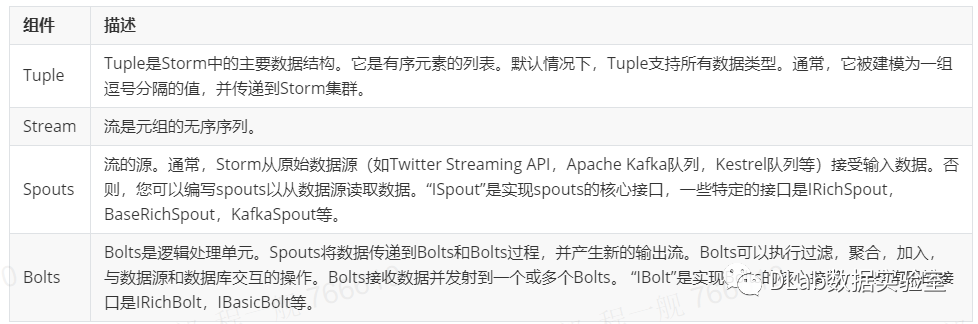
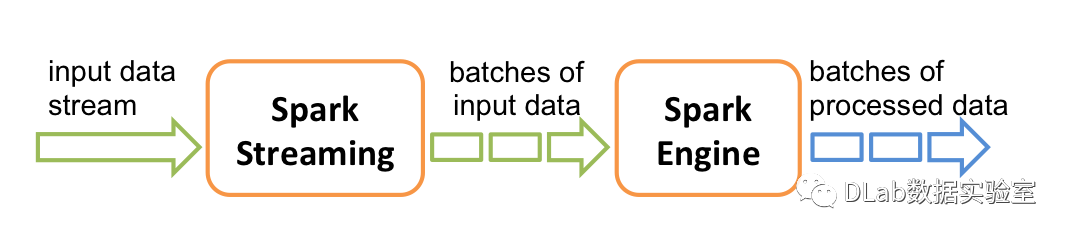
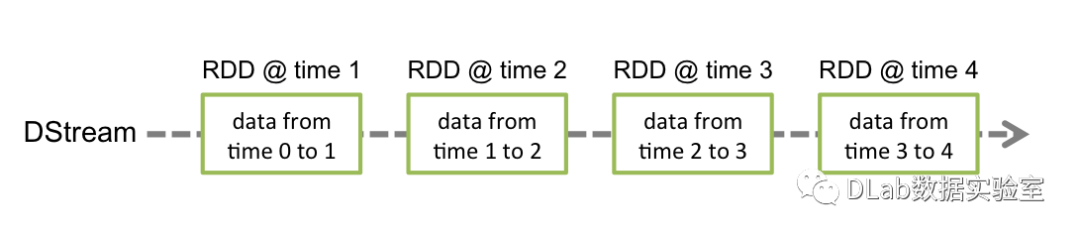
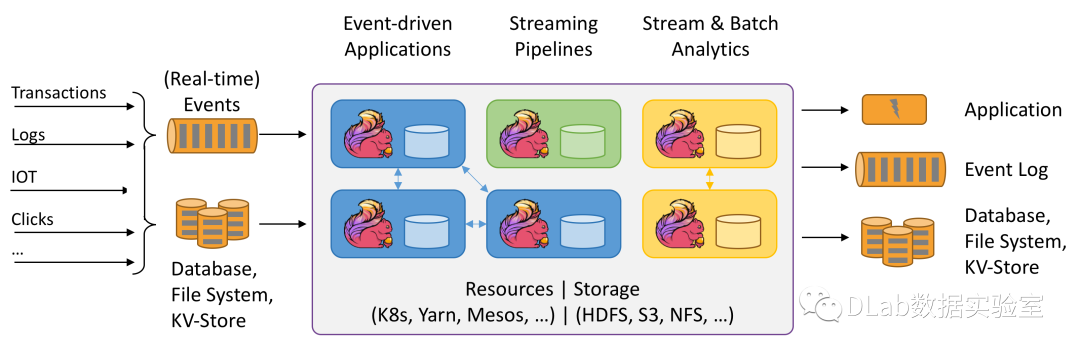
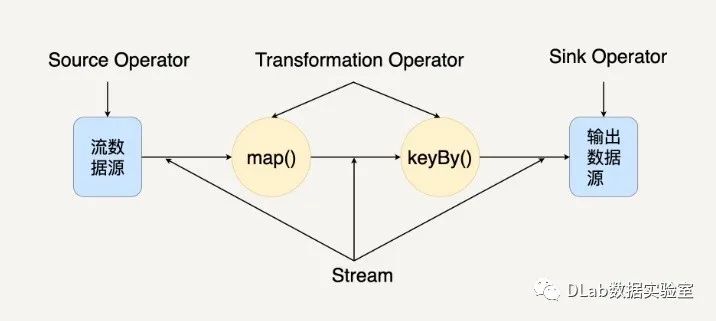
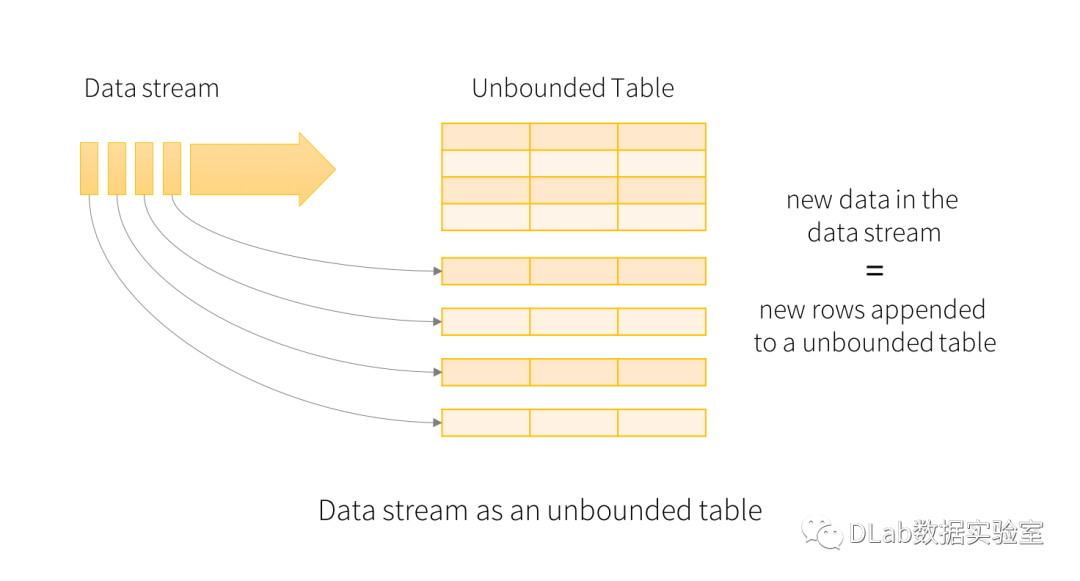
流处理计算
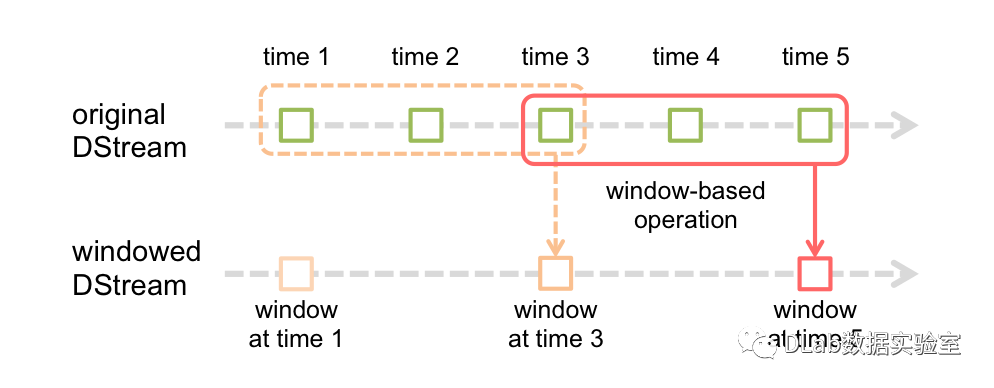
单次触发:顾名思义就是只触发一次执行,类似于Flink的批处理;
周期性触发:查询以微批处理模式执行,微批执行将以用户指定的时间间隔来进行;
默认触发:一个批次执行结束立即执行下个批次;
连续处理:是Structured Streaming从2.3开始提出的新的模式,对标的就是Flink的流处理模式,该模式支持传入一个参数,传入参数为checkpoint间隔,也就是连续处理引擎每隔多久记录查询的进度;
总结
批处理和流处理涵盖了大部分的应用场景,由于篇幅有限,本期就讲到这里,下期将会继续介绍大数据计算的另外两种场景:即席(Ad-Hoc)查询和图查询。

●Spark训练营(一)-- 开发环境搭建及wordCount实战
●Spark训练营(二)-- SparkStreaming流计算组件wordCount实战

文章都看完了 不点个
不点个 吗
吗
欢迎 点赞、在看、分享 三连哦~~
文章转载自DLab数据实验室,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
