




在Pinterest,后端核心服务负责Pinner和内部服务在引脚,电路板和用户上的各种操作。虽然Pinners的操作由于实时响应而被标识为在线流量,但内部处理却由于处理是异步的而被标识为离线,因此不需要实时响应。
这些情况的流量之间共享服务的读取和写入API。Pinner在单个对象上的大部分操作(例如,创建电路板,保存Pin或通过Web或移动设备编辑用户设置)都路由到API之一,以获取和更新数据存储区中的数据。同时,内部服务使用这些API代表用户对大量对象执行操作(例如,停用垃圾邮件帐户,删除垃圾邮件Pins)。
为了从API卸载内部脱机流量,以便有更好地性能来专门处理联机流量,写API应该支持批处理对象。提出并实现了在Kafka之上的批量写入平台。这还可以确保更有效地支持QPS之类的内部服务,而不会受到限制以保证高吞吐量。在本文中,我们将介绍内部脱机流量的特征,面临的挑战以及如何通过在后端核心服务中构建批量写入平台来改善它们。
数据存储和写入API
在Pinterest,MySQL是一种主要的数据存储,用于存储用户创建的内容。为了存储数以亿计的Pinner的数十亿Pins,电路板和其他数据,许多MySQL数据库实例形成一个MySQL集群,该集群被分为多个逻辑碎片,以更有效地管理和提供数据。所有数据都在这些分片上拆分。
为了有效地为一个用户读取和写入数据,数据存储在相同的分片中,因此API只需要从一个分片中获取数据,而无需对各种分片进行扇出查询。为了防止任何单个请求长时间占用MySQL数据库资源,请为每个单个查询配置超时。
最初,核心服务的所有写入API都是为Pinners的在线流量而构建的,并且运行良好,因为只接受单个对象,因为Pinner大部分时间都在单个对象上进行操作,而且操作轻巧。即使Pinners进行批量操作,例如将多个Pins移到一块板上,由于对象数量不是很大,并且编写的API可以一一处理,因此性能仍然不错。
挑战性
随着越来越多的内部服务将现有的写API用于各种批量操作(例如,在短时间内为垃圾邮件用户删除许多Pin或为大量现有的Pin回填新字段),情况发生了变化。由于写入API一次只能处理一个对象,因此在这些API中看到了峰值流量。
为了处理更多流量,可以应用服务的自动扩展,但由于MySQL群集限制了系统的容量,因此不一定能完全解决问题。使用MySQL群集的现有体系结构,很难对MySQL群集进行自动扩展。
为了保护服务和MySQL群集,将速率限制应用于写入API。
尽管节流可以在某种程度上有所帮助,但是它有几个缺点,这些缺点使后端核心服务变得更加可靠和可扩展。
- 到API的在线和离线流量都会相互影响。如果发生内部离线流量激增,则到同一API的在线流量会受到更高的延迟和降级的性能的影响,从而影响用户的体验。
- 随着越来越多的内部流量发送到API,需要严格限制速率限制,以便API可以提供更多流量而不影响现有流量。
- 速率限制不会阻止热碎片。当内部服务为特定用户写入数据时(例如,为合作伙伴摄取大量Feed针),所有请求都针对同一分片。由于在短时间内请求数量激增,预计会出现热碎片。当MySQL中的更新操作非常昂贵时,情况变得更糟。
由于内部服务需要在短时间内处理大量对象并且不需要实时响应,因此可以将针对同一分片的请求组合在一起,并通过对MySQL的一个共享查询来异步处理以提高效率并节省了MySQL连接资源的带宽。所有合并的批处理请求应以受控的速率进行处理,以免产生碎片。
批量写入架构
批量写入平台的体系结构旨在为具有高吞吐量和零热碎片的内部服务支持高QPS。另外,只需调用新的API,即可轻松迁移到平台。
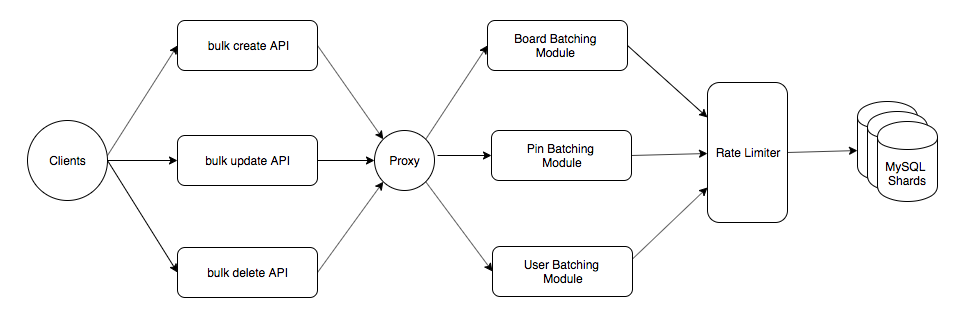
批量写入API和代理
为了支持对一批对象的写入(更新,删除和创建)操作,为内部服务提供了一组批量写入API,这些API可以接受对象列表而不是单个对象。与常规写入API相比,这有助于大幅降低API的QPS。
代理是一项finagle服务,它将传入的请求映射到不同的批处理模块,这些模块根据对象的类型将对同一分片的请求组合在一起。
配料模块
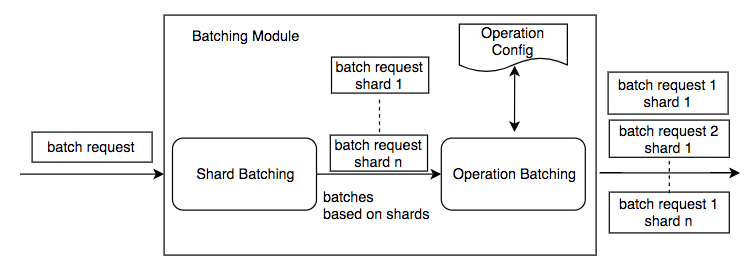
批处理模块用于根据操作类型和对象类型将批处理请求分成小批,以便可以在MySQL中有效地处理一批对象,并且为每个查询配置了超时。
这样做是出于两个主要考虑因素:
- 首先,应配置对每个分片的写入速率,以避免热分片,因为分片可能包含不同数量的记录并执行各种操作。来自代理的一个批处理请求包含不同分片上的对象。为了准确控制分片的QPS,基于目标分片将批处理请求分成多个批次。“碎片批处理”模块按受影响的MySQL碎片拆分请求
- 其次,每个写操作都有自己的批处理大小。对不同对象类型的操作具有不同的性能,因为它们更新了不同数量的各种表。例如,创建一个新的Pin可能会更改四个到五个不同的表,而更新现有的Pin可能只会更改两个表。同样,对表的更新查询可能会花费各种时间。因此,针对一种对象类型的批次更新可能会遇到不同批次大小的各种延迟。为了使批次更新高效,针对各种写入操作,对批次大小进行了不同的配置。“操作批处理”进一步按操作类型划分这些请求。
卡夫卡限速器
来自批处理模块的批处理请求中的所有对象都位于同一分片上。如果有太多请求到达一个特定的分片,则预计会出现热分片。热分片会影响所有其他查询到同一分片,并降低系统性能。为避免此问题,对一个分片的所有请求都应以受控的速率发送,这样该分片将不会被淹没并且可以有效地处理请求。为了实现此目标,每个分片都需要一个速率限制器,并且它控制该分片的所有请求。
为了同时支持来自内部客户端的高QPS,应将来自它们的所有请求临时存储在平台中,并以可控的速度进行处理。这是卡夫卡非常适合这些目的的地方。
- Kafka可以处理非常高的qps写入和读取。
- Kafka是一个可靠的分布式消息存储系统,用于缓冲批处理请求,以便以受控的速率处理请求。
- Kafka可以利用负载的重新平衡并自动管理使用者。
- 每个分区专门分配给一个使用者(在同一使用者组中),并且使用者可以以良好的速率限制来处理请求。
- 所有分区中的请求都由不同的使用者处理器同时处理,因此吞吐量非常高。
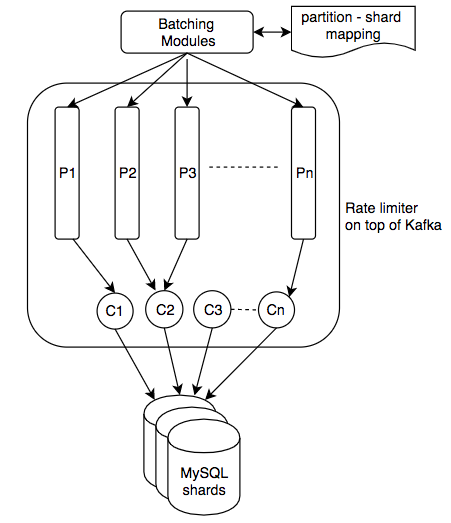
P:分区C:消费者处理器
Kafka配置
首先,MySQL群集中的每个分片在Kafka中都有一个匹配的分区,因此对该分片的所有请求都将发布到相应的分区,并由一个具有精确QPS的专用使用者处理器处理。其次,大量的消费类处理器正在运行,因此最多可将一个或两个分区分配给一个消费类处理器以实现最大的吞吐量。
消费者处理器
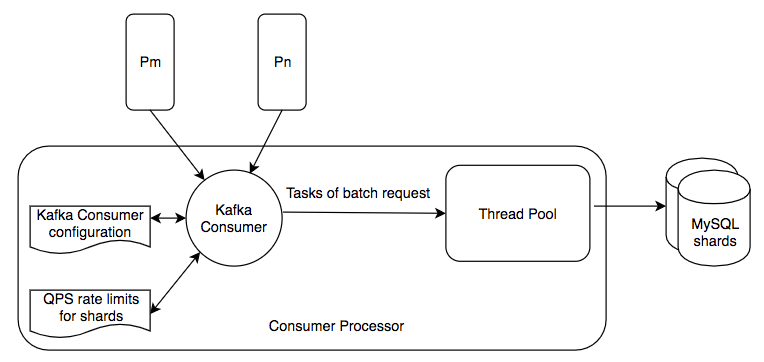
消费者处理器通过两个步骤对分片上的QPS进行速率限制:
- 首先,配置使用者可以一次从其分区中拉出多少个请求。
- 其次,消费者咨询分片的配置以获取一个分片可以处理的批处理请求的准确数量,然后使用Guava Ratelimiter进行速率控制。例如,对于某些分片,它可能处理低流量,因为热用户存储在该分片中。
消费者处理器可以通过采取适当的措施来处理不同的故障。为了处理线程池中的拥塞,如果线程池已满并且忙于现有任务,则消费者处理器将使用配置的退避时间重试该任务。为了处理MySQL分片中的故障,它将检查MySQL群集的响应以捕获错误和异常,并对不同的故障采取适当的措施。例如,当它看到两个连续的超时失败时,它将向系统管理员发送警报,并在配置的等待时间后停止拉取和处理请求。通过这些机制,请求处理的成功率很高。
结果
内部团队的几个用例已经发布到具有良好性能的批量编写平台。例如,合作伙伴的Feed摄取正在使用该平台。在该过程所花费的时间和成功率上均观察到许多改进。摄取约430万个Pin的结果如下所示。

另外,在饲料摄取过程中再也看不到热碎片,这之前已经引起了很多类似的问题。
随着越来越多的内部流量从现有的写API分离到新的批量写API,用于在线流量的API的性能得到了改善,例如减少了停机时间,降低了延迟。这有助于使系统更加可靠和高效。
