





如果您认为B树索引是1980年代完善的技术,那您基本上是对的。但是仍有改进的空间,因此PostgreSQL v12(在v11的传统中)在该领域添加了一些新功能。
在本文中通过示例解释其中的一些改进。
B树索引测试用例
为了演示更改,将在PostgreSQL v11和v12上创建一个示例表:
CREATE TABLE rel (
aid bigint NOT NULL,
bid bigint NOT NULL
);
ALTER TABLE rel
ADD CONSTRAINT rel_pkey PRIMARY KEY (aid, bid);
CREATE INDEX rel_bid_idx ON rel (bid);
\d rel
Table "public.rel"
Column | Type | Collation | Nullable | Default
--------+--------+-----------+----------+---------
aid | bigint | | not null |
bid | bigint | | not null |
Indexes:
"rel_pkey" PRIMARY KEY, btree (aid, bid)
"rel_bid_idx" btree (bid)
这样的表通常用于实现其他表(实体)之间的多对多关系。
主键在表上创建唯一的复合 B树索引,该索引有两个作用:
- 它确保了在对的每个组合最多一个入口aid和bid
- 它可以加快bid与给定相关的所有的搜索aid
第二个索引加快了aid与给定相关的所有的搜索速度bid。
添加测试数据
现在,让我们按升序插入一些行,这对于人工生成的键很常见:
INSERT INTO rel (aid, bid)
SELECT i, i / 10000
FROM generate_series(1, 20000000) AS i;
/* set hint bits and calculate statistics */
VACUUM (ANALYZE) rel;
在这里每个bid都与10000 aids有关。
B树索引改进1:INSERT进入具有很多重复项的索引
当我们比较以下项的索引大小时,第一个区别显而易见bid:
在PostgreSQL v11中:
\di+ rel_bid_idx
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+-------------+-------+----------+-------+--------+-------------
public | rel_bid_idx | index | postgres | rel | 545 MB |
(1 row)
在PostgreSQL v12中:
\di+ rel_bid_idx
Schema | Name | Type | Owner | Table | Size | Description
--------+-------------+-------+----------+-------+--------+-------------
public | rel_bid_idx | index | postgres | rel | 408 MB |
(1 row)
v11中的索引大33%。
说明
每次bid在索引中发生10000次,因此将有许多叶子页,其中所有键都相同(每个叶子页可以包含数百个条目)。
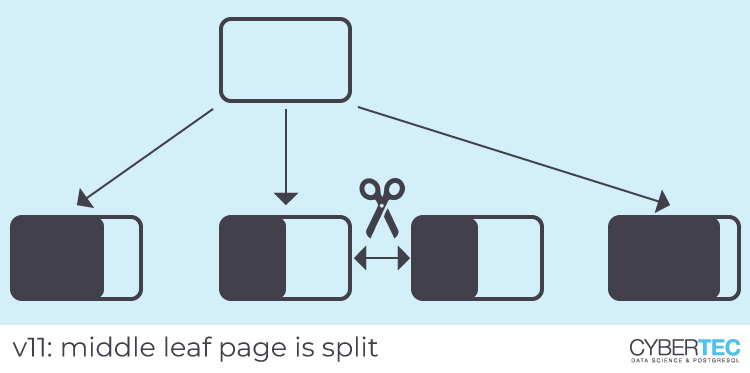
在v12之前,PostgreSQL将不以特殊顺序将此类条目存储在索引中。因此,如果必须拆分叶页面,则有时它是最右边的叶页面,但有时不是。最右边的叶子页总是向右端拆分,以优化单调增加的插入量。与此相反,其他叶页在中间被分割,浪费了空间。
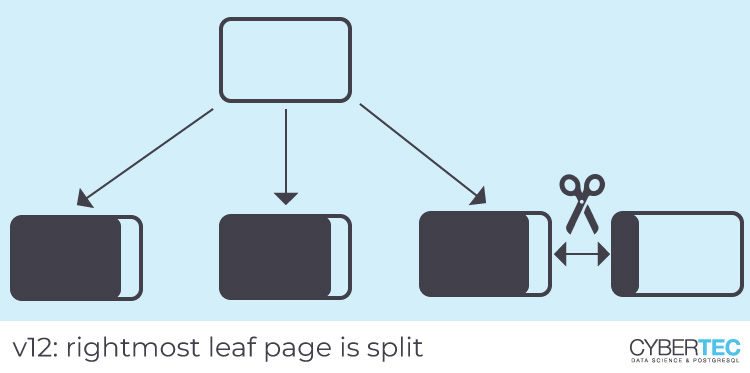
对于v12,表行的物理地址(“元组ID”或TID)是索引键的一部分,因此重复的索引条目按表顺序存储。这将导致对此类条目的索引扫描以物理顺序访问表,这可能会带来显着的性能优势,尤其是在旋转磁盘上。换句话说,重复索引条目的相关性将是完美的。此外,仅包含重复项的页面将在右端分割,从而产生密集的索引(这就是我们在上面观察到的)。
为多列索引添加了类似的优化,但是它不适用于我们的主键索引,因为重复项不在第一列中。主键索引在v11和v12中都密集打包,因为第一列是单调递增的,所以叶子页拆分总是发生在最右边的页上。如上所述,PostgreSQL已经对此进行了优化。
B树索引改进2:内部索引页的压缩存储
主键索引的改进并不明显,因为它们在v11和v12中的大小几乎相等。我们将不得不在这里进行更深入的研究。
首先,在v11和v12中的仅索引扫描中观察微小差异(重复执行该语句,直到块位于高速缓存中为止):
在PostgreSQL v11中:
EXPLAIN (ANALYZE, BUFFERS, COSTS off, SUMMARY off, TIMING off)
SELECT aid, bid FROM rel
WHERE aid = 420024 AND bid = 42;
QUERY PLAN
---------------------------------------------------------------
Index Only Scan using rel_pkey on rel (actual rows=1 loops=1)
Index Cond: ((aid = 420024) AND (bid = 42))
Heap Fetches: 0
Buffers: shared hit=5
(4 rows)
在PostgreSQL v12中:
EXPLAIN (ANALYZE, BUFFERS, COSTS off, SUMMARY off, TIMING off)
SELECT aid, bid FROM rel
WHERE aid = 420024 AND bid = 42;
QUERY PLAN
---------------------------------------------------------------
Index Only Scan using rel_pkey on rel (actual rows=1 loops=1)
Index Cond: ((aid = 420024) AND (bid = 42))
Heap Fetches: 0
Buffers: shared hit=4
(4 rows)
在v12中,将读取少一(索引)的块,这意味着该索引少一级。由于索引的大小几乎相同,因此必须意味着内部页面可以容纳更多的索引条目。在v12中,索引具有更大的扇出度。
说明
如上所述,PostgreSQL v12引入了TID作为索引键的一部分,这将浪费内部索引页中过多的空间。因此,同一提交从内部页面引入了“冗余”索引属性的截断。TID是多余的,INCLUDE子句中的非关键属性也是这样(这些内容在v11中也已从内部索引页中删除)。但是PostgreSQL v12也可以截断表行标识不需要的那些索引属性。
在我们的主键索引中,bid是一个冗余列,并且从内部索引页中被截断,这为每个索引条目节省了8个字节的空间。让我们看一下带有pageinspect扩展名的内部索引页:
在PostgreSQL v11中:
SELECT * FROM bt_page_items('rel_pkey', 2550);
itemoffset | ctid | itemlen | nulls | vars | data
------------+------------+---------+-------+------+-------------------------------------------------
1 | (2667,88) | 24 | f | f | cd 8f 0a 00 00 00 00 00 45 00 00 00 00 00 00 00
2 | (2462,0) | 8 | f | f |
3 | (2463,15) | 24 | f | f | d6 c0 09 00 00 00 00 00 3f 00 00 00 00 00 00 00
4 | (2464,91) | 24 | f | f | db c1 09 00 00 00 00 00 3f 00 00 00 00 00 00 00
5 | (2465,167) | 24 | f | f | e0 c2 09 00 00 00 00 00 3f 00 00 00 00 00 00 00
6 | (2466,58) | 24 | f | f | e5 c3 09 00 00 00 00 00 3f 00 00 00 00 00 00 00
7 | (2467,134) | 24 | f | f | ea c4 09 00 00 00 00 00 40 00 00 00 00 00 00 00
8 | (2468,25) | 24 | f | f | ef c5 09 00 00 00 00 00 40 00 00 00 00 00 00 00
9 | (2469,101) | 24 | f | f | f4 c6 09 00 00 00 00 00 40 00 00 00 00 00 00 00
10 | (2470,177) | 24 | f | f | f9 c7 09 00 00 00 00 00 40 00 00 00 00 00 00 00
...
205 | (2666,12) | 24 | f | f | c8 8e 0a 00 00 00 00 00 45 00 00 00 00 00 00 00
(205 rows)
在data条目中,我们看到来自aid和的字节bid。该实验是在Little-endian机器上进行的,因此第6行中的数字为0x09C3E5和0x3F或(作为十进制数)639973和63。每个索引条目的宽度为24个字节,其中8个字节为元组标头。
在PostgreSQL v12中:
SELECT * FROM bt_page_items('rel_pkey', 2700);
itemoffset | ctid | itemlen | nulls | vars | data
------------+----------+---------+-------+------+-------------------------
1 | (2862,1) | 16 | f | f | ab 59 0b 00 00 00 00 00
2 | (2576,0) | 8 | f | f |
3 | (2577,1) | 16 | f | f | 1f 38 0a 00 00 00 00 00
4 | (2578,1) | 16 | f | f | 24 39 0a 00 00 00 00 00
5 | (2579,1) | 16 | f | f | 29 3a 0a 00 00 00 00 00
6 | (2580,1) | 16 | f | f | 2e 3b 0a 00 00 00 00 00
7 | (2581,1) | 16 | f | f | 33 3c 0a 00 00 00 00 00
8 | (2582,1) | 16 | f | f | 38 3d 0a 00 00 00 00 00
9 | (2583,1) | 16 | f | f | 3d 3e 0a 00 00 00 00 00
10 | (2584,1) | 16 | f | f | 42 3f 0a 00 00 00 00 00
...
286 | (2861,1) | 16 | f | f | a6 58 0b 00 00 00 00 00
(286 rows)
在data只包含aid,因为bid已被截断了。这样可以将索引条目的大小减小到16,以便在索引页面上可以容纳更多的条目。
升级注意事项
由于v12中的索引存储已更改,因此引入了新的B树索引版本4。
由于使用进行升级pg_upgrade不会更改数据文件,因此升级后索引仍将处于版本3中。PostgreSQL v12可以使用这些索引,但是以上优化将不可用。您需要REINDEX一个索引才能将其升级到版本4(REINDEX CONCURRENTLY在PostgreSQL v12中,此操作变得更容易了)。
v12中引入的其他B树索引功能
PostgreSQL v12中添加了其他一些改进。我不会详细讨论它们,但这是列表:
- 减少B树索引插入的锁定开销,以提高性能。
- 引入REINDEX CONCURRENTLY以使其更易于重建索引而无需停机。
- 提高对具有许多属性的索引的仅索引扫描的性能。
- 添加视图pg_stat_progress_create_index以报告CREATE INDEX和的进度REINDEX。
结论
B树索引在PostgreSQL v12中再次变得更加智能,特别是对于具有许多重复条目的索引。为了充分受益,您必须使用转储/还原进行升级,或者必须在REINDEX之后进行索引pg_upgrade。
