






1 fasttext
fasttext 是一个用于高效学习单词表示和句子分类的库
fasttext原理
Fasttext的3个特点:神经网络模型架构,分层SoftMax和N-gram子词特征
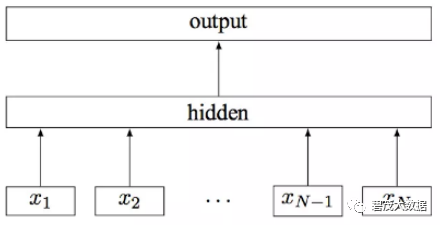
fastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率
序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签
1.1 子词嵌入(fastText)
英语单词通常有其内部结构和形成方式。
例如,可以从“dog”“dogs”和“dogcatcher”的字面上推测它们的关系。这些词都有同一个词根“dog”,但使用不同的后缀来改变词的含义。
而且,这个关联可以推广至其他词汇。
例如,“dog”和“dogs”的关系如同“cat”和“cats”的关系,“boy”和“boyfriend”的关系如同“girl”和“girlfriend”的关系。
在word2vec中,并没有直接利用构词学中的信息。
无论是在跳字模型还是连续词袋模型中,都将形态不同的单词用不同的向量来表示。
例如,“dog”和“dogs”分别用两个不同的向量表示,而模型中并未直接表达这两个向量之间的关系。
鉴于此,fastText提出了子词嵌入(subword embedding)的方法,从而试图将构词信息引入word2vec中的跳字模型 。
在fastText中,每个中心词被表示成子词的集合。
下面用单词“where”作为例子来了解子词是如何产生的。
首先,在单词的首尾分别添加特殊字符“<”和“>”以区分作为前后缀的子词。
然后,将单词当成一个由字符构成的序列来提取 n 元语法。
例如,当 n=3 时,得到所有长度为3的子词:“<wh”“whe”“her”“ere”“re>”以及特殊子词“<where>”。
1.2 Fasttext模型
fastText 模型架构和 Word2Vec 中的 CBOW 模型很类似
fastText 在预测标签时使用了非线性激活函数,但在中间层不使用非线性激活函数
Fasttext核心:将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类
1.3 Fasttext分层softmax
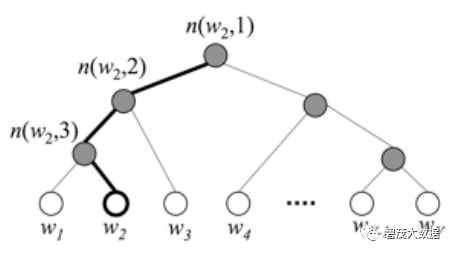
分层 Softmax 技巧建立在哈弗曼编码的基础上,对标签进行编码,能够极大地缩小模型预测目标的数量
fasttext 也利用了类别(class)不均衡这个事实(一些类别出现次数比其他的更多),通过使用Huffman 算法建立用于表征类别的树形结构
频繁出现类别的树形结构的深度要比不频繁出现类别的树形结构的深度要小,这也使得进一步的计算效率更高
2 GloVe
基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具
可以把一个单词表达成一个由实数组成的向量
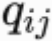
这些向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)等
实现步骤
矩阵中的每一个元素Xij代表单词i和上下文单词j在特定大小的上下文窗口(context window)内共同出现的次数
根据语料库(corpus)构建一个共现矩阵(Co-ocurrence Matrix)X
构建词向量(Word Vector)和共现矩阵(Co-ocurrence Matrix)之间的近似关系
2.1 GloVe模型
GloVe模型采用了平方损失,并基于该损失对跳字模型做了3点改动 :
权重函数h(x)是值域在 [0,1] 的单调递增函数。
中心词偏差项
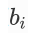
和背景词偏差项 。
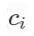
使用非概率分布的变量
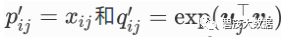
并对它们取对数。因此,平方损失项是
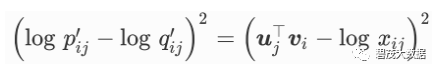
为每个词 wi 增加两个为标量的模型参数:
将每个损失项的权重替换成函数
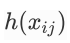
如此一来,GloVe模型的目标是最小化损失函数:

h(x)取值为
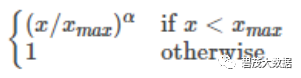
需要强调的是,如果词wi出现在词wj的背景窗口里,那么词wj也会出现在词wi的背景窗口里。
也就是说

不同于word2vec中拟合的是非对称的条件概率
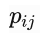
GloVe模型拟合的是对称的
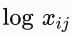
因此,任意词的中心词向量和背景词向量在GloVe模型中是等价的。
但由于初始化值的不同,同一个词最终学习到的两组词向量可能不同。
当学习得到所有词向量以后,GloVe模型使用中心词向量与背景词向量之和作为该词的最终词向量。
关注公众号:
领取精彩视频课程
海量免费语音课程

