






1 线性判别分析(LDA)
Linear Discriminant Analysis
用途:数据预处理中的降维,分类任务
历史:Ronald A. Fisher在1936年提出了线性判别方法
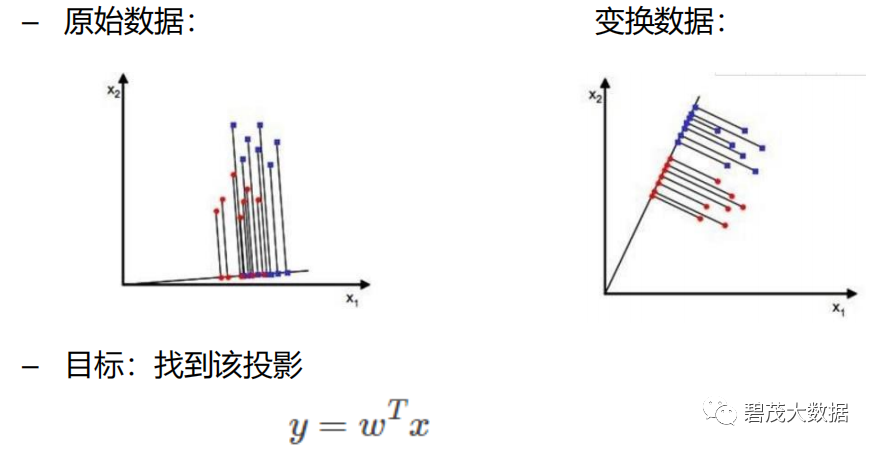
目标:LDA关心的是能够最大化类间区分度的坐标轴成分。将特征空间(数据集中的多维样本)投影到一个维度更小的 k 维子空间中, 同时保持区分类别的信息
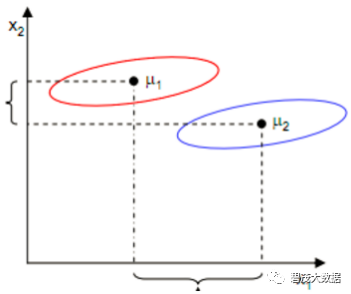
原理:投影到维度更低的空间中,使得投影后的点,会形成按类别区分,一簇一簇的情况,相同类别的点,将会在投影后的空间中更接近方法
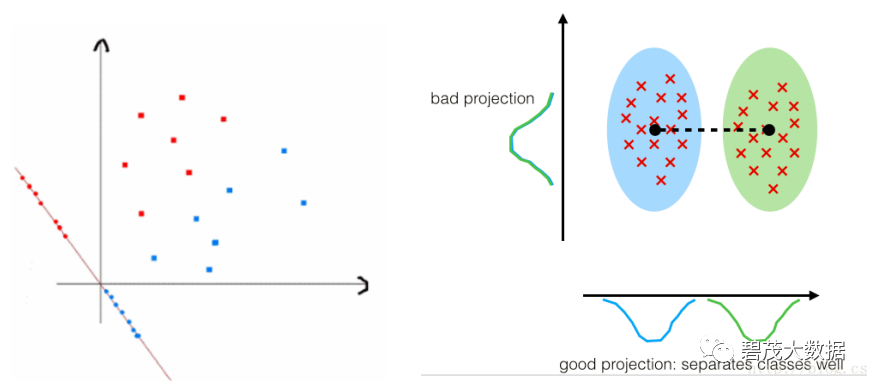
监督性:LDA是“有监督”的,它计算的是另一类特定的方向
投影:找到更合适分类的空间
与PCA不同,更关心分类而不是方差

数学原理
Linear Discriminant Analysis
LDA分类的一个目标是使得不同类别之间的距离越远越好, 同一类别之中的距离越近越好
每类样例的均值:
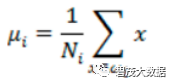
投影后的均值:
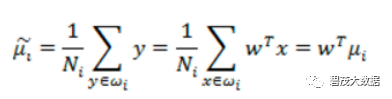
投影后的两类样本中心点尽量分离:
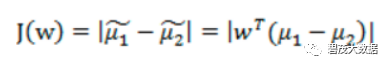
只最大化J(w)就可以了?
X1的方向可以最大化J(w),但是却分的不好
散列值:样本点的密集程度,值越大,越分散,反之,越集中
同类之间应该越密集些:
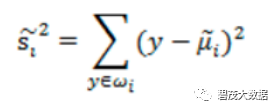
目标函数:
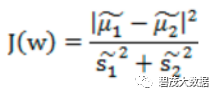
散列值公式展开:
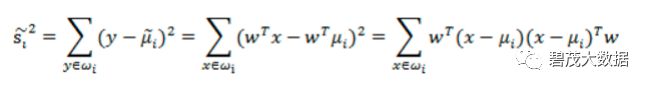
散列矩阵(scatter matrices):
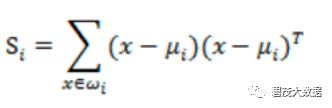
类内散布矩阵 Sw = S1+S2:
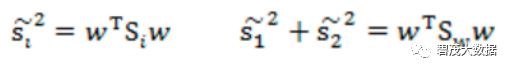
目标函数:
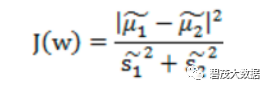
分子展开:
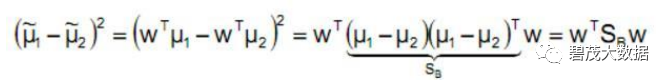
𝑆𝐵称作类间散布矩阵
最终目标函数:
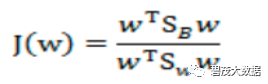
分母进行归一化:如果分子、分母是都可以取任意值的, 那就会使得有无穷解,我们将分母限制为长度为1
拉格朗日乘子法:
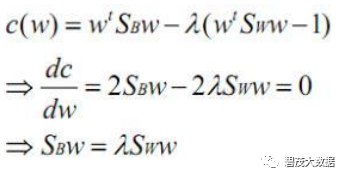
两边都乘以Sw的逆:

2 主成分分析(PCA)
Principal Component Analysis
用途:降维中最常用的一种手段
目标:提取最有价值的信息(基于方差)
问题:降维后的数据的意义?
向量的表示及基变换
内积:
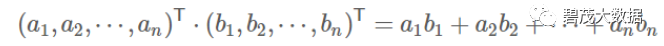
解释:

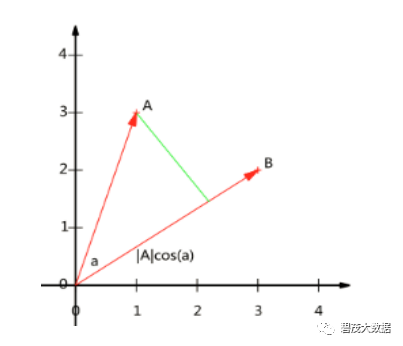
设向量B的模为1,则A与B的内积值等于A向B所在直线投影的矢量长度
向量可以表示为(3,2) 实际上表示线性组合:
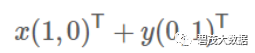
基:(1,0)和(0,1)叫做二维空间中的一组基
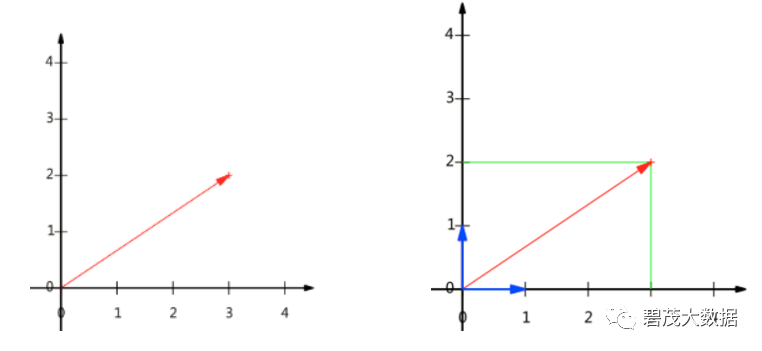
基变换
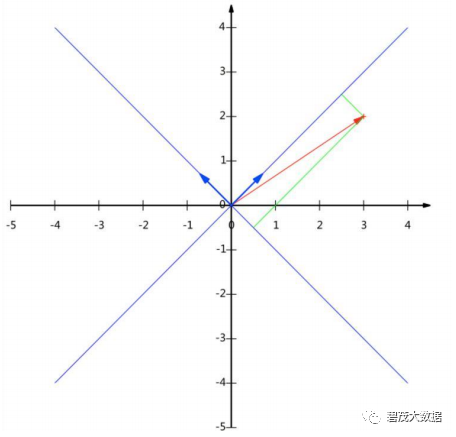
基是正交的(即内积为0,或直观说相互垂直)
要求:线性无关
变换:数据与一个基做内积运算,结果作为第一个新的坐标分量,然后与第二个基做内积运算,结果作为第二个新坐标的分量
数据(3,2)映射到基中坐标:
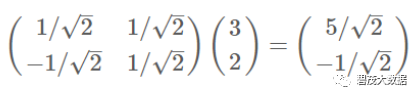
两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到 左边矩阵中每一行行向量为基所表示的空间中去
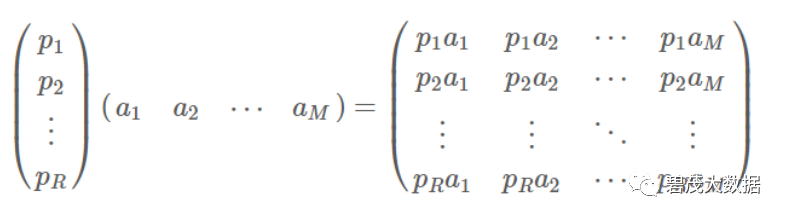
协方差矩阵
方向:如何选择这个方向(或者说基)才能尽量保留最多的原始信息呢? 一种直观的看法是:希望投影后的投影值尽可能分散
方差:
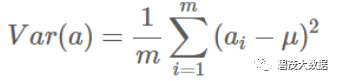
寻找一个一维基,使得所有数据变换为这个基上的坐标表示后,方差值最大
协方差(假设均值为0时):
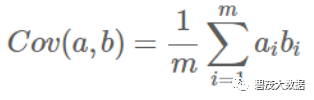
协方差
如果单纯只选择方差最大的方向,后续方向应该会和方差最大的方向接近重合。
解决方案:为了让两个字段尽可能表示更多的原始信息, 我们是不希望它们之间存在(线性)相关性的
协方差:可以用两个字段的协方差表示其相关性
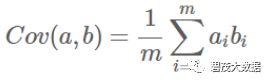
当协方差为0时,表示两个字段完全独立。为了让协方差为0,选择第二个基时 只能在与第一个基正交的方向上选择。因此最终选择的两个方向一定是正交的。
优化目标
将一组N维向量降为K维(K大于0,小于N),目标是选择K个单位正交基,使原始数据变换到这组基上后,各字段两两间协方差为0,字段的方差则尽可能
大协方差矩阵:
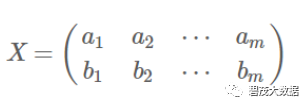
矩阵对角线上的两个元素分别是两个字段的方差,而其它元素是a和b的协方差。
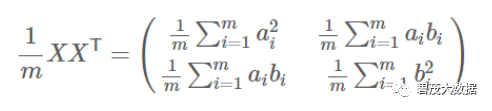
协方差矩阵对角化:即除对角线外的其它元素化为0,并且在对角线上将元素按大小从上到下排列
协方差矩阵对角化:
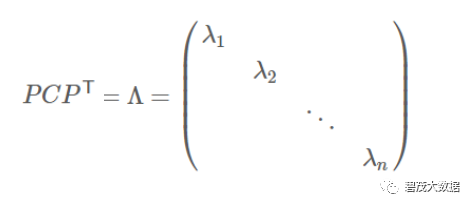
实对称矩阵:一个n行n列的实对称矩阵一定可以找到n个单位正交特征向量
实对称阵可进行对角化:
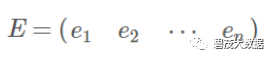
根据特征值的从大到小,将特征向量从上到下排列,则用前K行组成的矩阵乘以原始数据矩阵X,就得到了我们需要的降维后的数据矩阵Y
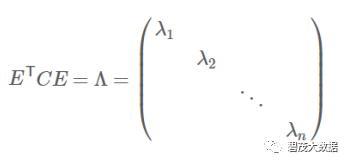

3 LDA和PCA实验
In:
import numpy as np
In:
X = np.random.rand(10000,96)
y = np.random.randint(20,size=10000)
In:
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(X,y,test_size=0.25)
3.1 LDA
In:
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
In:
lda = LinearDiscriminantAnalysis(n_components=16)
# min(n_classes - 1, n_features)
In:
X_lda = lda.fit_transform(X,y)
In:
X_lda.shape
out:
(10000, 16)
3.2 PCA
In:
from sklearn.decomposition import PCA
In:
pca = PCA(n_components=48)
In:
X_pca = pca.fit_transform(X)
In:
X_pca.shape
out:
(10000, 48)
大数据视频推荐:
腾讯课堂:https://bmkj.ke.qq.com/?tuin=903c7756#category=-1&tab=1
CSDN学https://edu.csdn.net/lecturer/2494/course
大数据语音推荐:
企业级大数据技术应用:https://www.ximalaya.com/keji/47878945/
大数据机器学习案例之推荐系统:https://www.ximalaya.com/keji/47132510/
自然语言处理:https://www.ximalaya.com/jiaoyupeixun/46905034/
大数据基础:https://www.ximalaya.com/jiaoyupeixun/46905403/
人工智能:深度学习入门到精通:https://www.ximalaya.com/jiaoyupeixun/46153326/



碧茂课堂精彩课程推荐:
海量免费课程语音:
喜马拉雅:https://www.ximalaya.com/zhubo/137449483/
蜻蜓FM:https://www.qingting.fm/podcasters/a78de5aa1c0c420bac9fe9687a87fcc0/

1.Cloudera数据分析课;
2.Spark和Hadoop开发员培训;
3.大数据机器学习之推荐系统;
4.Python数据分析与机器学习实战;

详情请关注我们公众号:碧茂大数据-课程产品-碧茂课堂
现在注册互动得海量学币,大量精品课程免费送!
