排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
举报
首页
/
【技术分享】姜宇祥:MySQL时间序列存储引擎的探索与实践之旅
【技术分享】姜宇祥:MySQL时间序列存储引擎的探索与实践之旅
数据库技术大会
2016-06-24
721
本文整理自DTCC2016主题演讲内容,录音整理及文字编辑IT168@杨璐@胡晴。如需转载,请先联系本公众号获取授权!
演讲嘉宾
姜宇祥
携程MySQL团队
资深数据库工程师
拥有16年的代码开发经历,涵盖网络通讯、接口编写、数据存储、事务等数据库开发领域。10年数据库核心代码开发经验,相关开发涉及达梦、ORACLE、MySQL数据库。现致力于携程MySQL的底层研发,为业务定制、特殊问题定位和处理提供技术支持。
分享内容
我讲的是携程的一次实践。主要分为两大部分,第一部分是我们为什么要做这个时间序列存储;还有一部分是我们具体是怎么做的这个时间序列存储。
时间序列数据库简介:
先介绍一下概念,带时间标签的数据,就把它叫做时间序列的数据。存储这些数据的数据库,我们就叫做时间序列数据库。
典型的应用场景是早期在一些电厂,或者一些工业环境下要不停的记录数据,这种数据积累下来,就产生了时间序列的数据库。
在现在的IT行业,也就是服务器上面,要不停的记录CPU的状态,还有磁盘的各种状态,这都是时间序列的数据。然后把它进行管理,这就是时间序列数据库。
现状:
现在市场上已经有不少的时间序列的数据库,像Graphite、OpenTSDB、InfluxDB。
从理论上来讲,这些都可以满足大家的应用。但是从运维的角度来看,需要不断积累新的运维经验。
对于开发来讲,这三个数据库的接口都是不统一的。如果觉得这个不好了之后,就没有办法平滑的切换到其他的。相当于重新推翻,要重写一遍所有的代码,是一个新的经验的积累,每一个新的产品对我们来讲都是一次挑战。
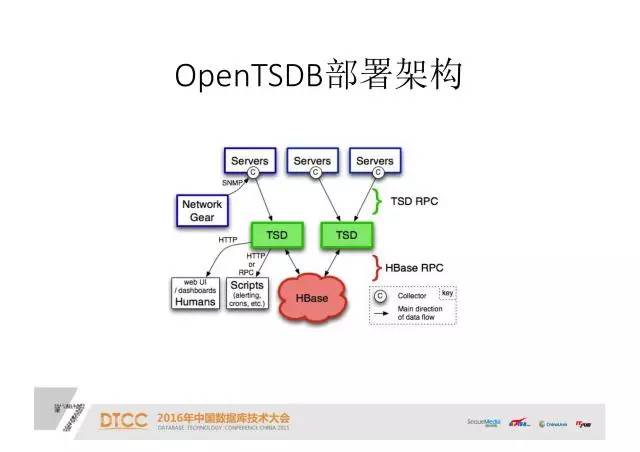
OpenTSDB部署架构:
举一个例子,这是OpenTSDB的一个后台程序,相当于一个服务器。它在不同的Servers上面要进行数据的收集,然后传到后台的程序,后台的程序又要接HBase,把数据插到HBase里面进行存储和查询。当客户端,比如WebUI、或其他脚本需要数据时,再访问TSDB。实际上最终转化是HBase数据的读取。
在这种情况下,我们依赖于TSDB的自定义的接口。对于上面的OpenTSDB和InfluxDB都是这样的。这就是我们碰到的问题,也就是新的开发经验和新的运维经验。
尝试:
我们当时就有一个想法,也挺有意思的。有一个同事说,反正我们也自己研究源码,我们就尝试写一个存储引擎。
存储引擎的好处是能依托MySQL的框架。MySQL已经把所有的对向前端框架的东西都做好了,我们只要实现后面的存储引擎,就可以利用它原来大部分的、不能说是绝大部分的东西使用出来。再利用已有的运维经验,就是我们的存储引擎CFL(Ctrip fast log),大家后面看到这个CFL的时候,这是我们携程。
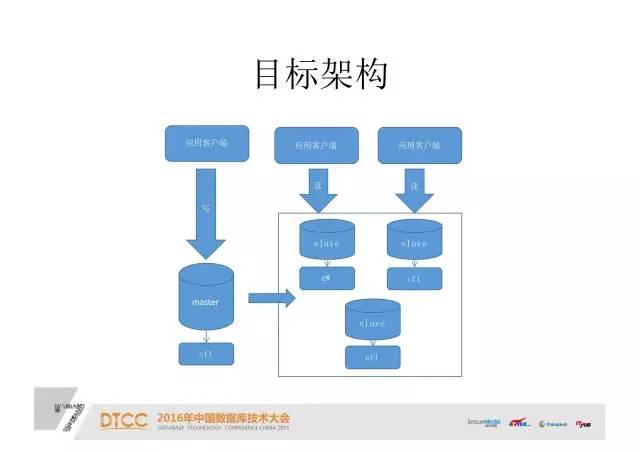
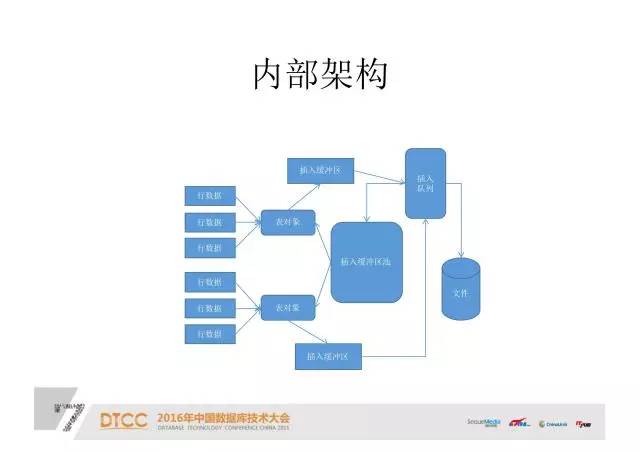
目标架构:
实现之后目标框架就是这个样子,应用程序还跟以往一样,直接导入master或slave数据库。把数据写到后端CFL的存储引擎,通过MySQL的复制功能复制到slave。在slave上读这个框架就基本上完成了。
在这个框架下,我们基本可以完全利用MySQL已有的集群,或者高可用性的东西,再下面我们只需要改一个CFL。
以上是我们为什么要做CFL存储引擎的原因,后面这个大问题,主要是讲我如何完成这个存储引擎的。
开发:
存储引擎的完成有两块很重要的措施:
1、整体介绍存储实现
2、框架适配:细节代码的讨论。
在整体开发上,主要会谈到如何设计存储,包括存储结构设计、整体框架设计。这是一个尝试性的工作,不可能非常完善,我还会列出缺点、使用限制等。
设计:
1、时序数据的特点:设计存储引擎要根据特点来进行针对性的设计才有价值。例如InnoDB的引擎最适合插入、删除,高效的插入和删除。但时序数据库的特点跟这种存储是不一样的,我们会针对这些特点进行设计。
2、设计目标:设计时要有一个设计的目标,要怎么样做才能根据这些特点达到我们期望的东西。
3、储存设计说明:我们会对比InnoDB和CFL存储,发现设计上有什么好处和不好的地方。
4、引擎架构:典型框架
时序数据的特点:
1、时序信息
2、顺序性:最重要的就是顺序性。不可能在两点拿到一个服务器的监控信息,写到数据库之后,突然接到了一点钟的东西。这种数据对于时序数据库来讲是没有什么意义的,对于监控也没有意义。
3、不易改变:发生的就是确定的事情,一旦发生就很少改变。
针对这三个特点,我们进行了最简单的设计。
设计目标:
快速插入和查询
1、索引和数据分离
2、顺序写入
事务
1、无事务:对于这个存储,我们不去满足ACID要求的特性。一旦这台机器挂了,那么这段时间的数据就被放弃掉了。
2、恢复:恢复时追求最快速的恢复。机器起来后读取到这个文件时,这个文件本质上就是完整的。
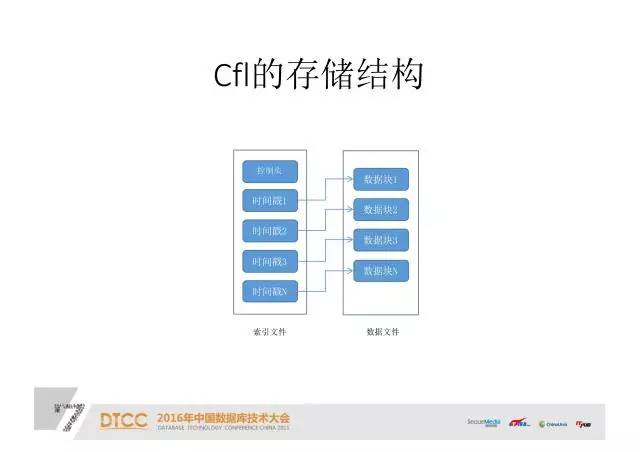
这就是我设计的数据库索引文件和数据文件。索引文件包括索引头、控制头、索引时间戳,和数据块、具体的数据块。
首先写数据文件,之后写时间戳,之后再写控制头。比如现在有三个数据的时间戳,当写到第四个的时候,把控制头改成第四个,这样一旦控制头写多了,前面的数据都写好了,不管在写的过程中任何地方崩溃,基本上都能保证整个数据的稳定性。
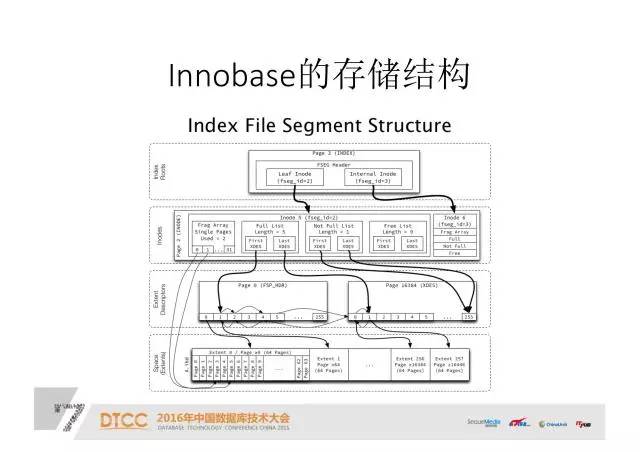
文件存储比较:
我们比较一下这两个存储结构。
用B+树去存储时间序列时,因为是顺序插入,每插满一个页就会分裂。分裂后前面的页一定不会再被使用,存在使用空间浪费的问题。
在B+树使用的时候,需要Redo log等事务性保证,而CFL不需要。
实现架构:
每一个表都有一个单独的表决项,它们的行进来时都是通过这个表决项插到缓冲区里。缓冲区又会进入一个插入的队列,从这个队列进入到文件系统里面。
在这个架构下面,如果缓冲区开得足够大,它的速度就取决于这个磁盘。
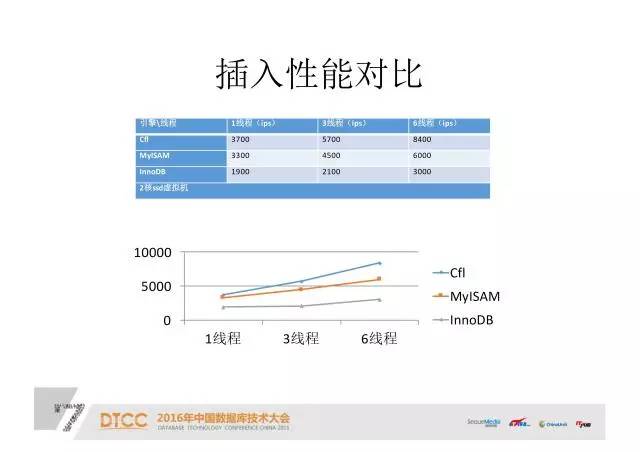
插入性能对比:
简单使用程序做出来后我们做一下对比,这是在二核的ssd虚拟机上做的比较,用的是单个存储引擎,分别是CLF、MyISAM和InnoDB。我们可以看到,从周期来讲,在一个线程、三个线程和六个线程,CLF的效率还是不错的。后面还有很多可以改进的效率,比如说前面的插入队列可能会更快一些。
缺点:
1、不支持更新:它写进数据时会一直保持在这里。
2、删除效率低:虽然也支持删除操作,但它的删除效率跟InnoDB是没有办法比的。以后会在这方面做规划。
3、不接受过期时间数据:因为前面缓冲区的限制,在一个缓冲区插入时,它会做一个排序,把排序的东西放在这里面,直接写入到文件。比如两点钟插入一个数据,过一会儿又来了一个一点钟的数据,已经没有办法再插入了。所以它暂时不接受过期使用的数据。
4、相当于表锁的插入并发:因为通过只有一个表对象,通过这个表对象插入行的时候,要对这个表对象进行一次锁定,相当于进行了一次表锁的操作。它做不到像InnoDB的更细腻的锁的实现。
使用限制:
因为必须要指定一个key_timestamp,只能针对这一个列去做索引的操作。这是我们碰到的使用限制,只能按照这个标准的方式来创建存储引擎的表。
未来:
1、多列索引:未来我们争取增加更多的列,比如像IInfluxDB一样,它有一个tag,相当于一个索引的列,能加入多列索引。
2、插入批量操作改进:在MySQL插入时可以采用批量的操作。
3、删除效率
4、多线程磁盘写入
接口适配的问题:
这块涉及到了MySQL真正内核的部分。
1、引擎框架结构:介绍MySQL存储引擎的框架。
2、接口类介绍:接口是MySQL如何实现框架最核心的部分。
3、接口类中的关键接口
实现了框架内的一些功能接口,我们就完成了MySQL存储引擎的开发。
Handler简介:
MySQL的存储引擎里,最核心的东西就叫做Handler。每一个引擎都有自己的Handler,通过Handler可以访问我们自己引擎之间的数据。
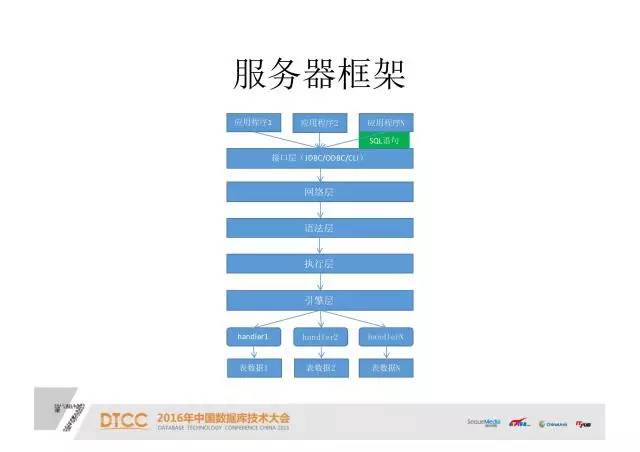
服务器框架:
这是一个MySQL框架。应用程序发一个SQL语句,通过接口传输,或者是接JDBC,通过网络层,达到语法层,进行语法解析。语法解析之后再通过执行层,生成一个执行计划,把这个计划执行,这个计划最终通过引擎层,引擎层里面的每一个Handler去访问我们的表数据。
这是整个MySQL如何访问数据,或者说如何访问每一个存储引擎数据的架构。
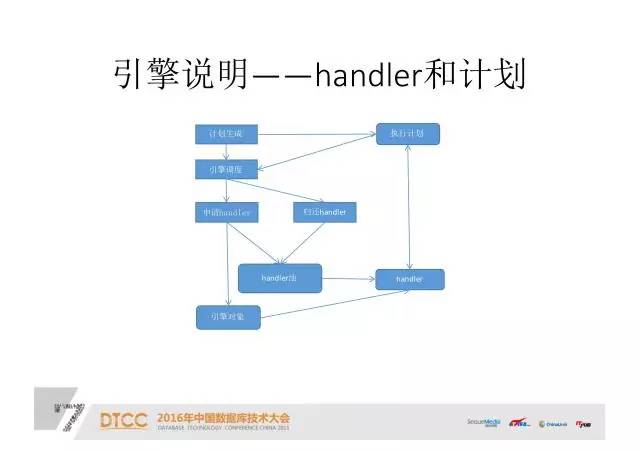
引擎说明——Handler执行计划:
这个图说明的是执行计划,是对引擎层下结构的细化说明。这是一个很复杂的过程,在执行前、执行后都是要涉及到,只是暂时通过这一张图描述一下。
对于Handler都有一个池子,执行计划生成时,会通过引擎的调度程序在Handler池里拿到一个Handler。比如有一张表,它对应一个Handler。在执行计划生成,通过调度引擎访问这张表时,要在Handler池拿到一个对应这张表的Handler。确定这些Handler具体访问到哪个表之后,这个计划才能算是生成结束了。
计划生成结束之后,执行计划时就通过这个Handler直接访问存储引擎对象,比如插入行、更新行,或删除行等。一些DDL也都是在这里面进行操作的。计划执行完成后,通过引擎调度把Handler还给引擎池。
这就是在实际执行的过程中,Handler和存储引擎对象是如何交互的。
Handler和表和会话:
总结Handler和表和会话的关系会帮助大家理解前面的引擎架构。
首先Handler表对象和表是多对一的关系,什么叫多对一的关系呢?就是定义一张表之后,可以在内存中可以生成多个Handler对象,然后去访问这张表。也就是说在会话并发的时候,我们每一个会话都会有一个Handler对同一张表进行访问。
并发情况下,多个事务并发,每一个会话都会通过一个Handler访问一个表对象;非并发情况下,会重用这个Handler的表对象,这是前面Handler池的作用。
案例:
举一个案例,这个版本是5.6,应该是改过的版本了。有一个8K分区的数据表,当时最大并发连接数是10个左右,结果这台机器就频繁发生内存的消耗。漏洞出来之后发现,在这种运行情况下,我们预计使用内存量大概是400G,内存实际上只有128G。我们进行压缩,压缩到2k之后就可以正常运营了。
为什么会有这个原因?因为在多并发情况下,每一个筛选都要对一个Handler进行操作。而在5.6的版本下,每个分区表都会创建一个Handler,就会造成这么大的内存使用。
接口类:
这个是最细节的部分,如果我们要实现存储引擎,就一定要用到Handler.H和Handler.C这两个文件。
Handler.H文件前面直接指向table源代码,table直接指向MySQL里table元数据的内存结构。
ha_open,close,index的部分是跟查询相关。
下面这些是在Handler运行过程中,进行互斥保护和share的内容。
DDL接口:
Handler提供DDL和DML的功能接口。DDL的代码中,create对应建表语句的操作,drop_table对应的是drop语句的操作,truncate对应truncate语句的操作。
DML接口:
DML里,write_row就是写数据的操作,我只列出我们实践过的函数的接口,delete_row是删除行操作。
表扫描的操作,scan就是初始化全表扫描;结束全表扫描;然后从第一行开始一个一个的读取。实现这个我们就可以实现全表扫描的功能。
索引扫描接口:
光有全表扫描效率肯定是不够的,要想快速查询就一定要实现索引扫描的接口。
这四个接口就是索引扫描的接口。 index_read是进行范围查询,传入范围查询比较的值,进行大于等于或小于等于的操作。index_next是在前面read执行之后,就是定位完之后,一条一条读索引数据的操作。
只要实现这几个接口,这个存储引擎基本上就实现了。
查询实现说明:
1、游标:在实现查询时,一定要提到游标的操作。每一个Handler要记录自己查到的数据的位置。通过前面的next,就可以不断的定位到下一条。
2、索引扫描元信息
整个实践就结束了,感谢我的公司携程,感谢DTCC大会,谢谢!
关于DTCC
中国数据库技术大会(DTCC)是目前国内数据库与大数据领域最大规模的技术盛宴,于每年春季召开,迄今已成功举办了七届。大会云集了国内外顶尖专家,共同探讨MySQL、NoSQL、Oracle、缓存技术、云端数据库、智能数据平台、大数据安全、数据治理、大数据和开源、大数据创业、大数据深度学习等领域的前瞻性热点话题与技术,吸引IT人士参会5000余名,为数据库人群、大数据从业人员、广大互联网人士及行业相关人士提供了极具价值的交流平台。
关注
大会官方公众号
,获取更多详情
!
↓↓↓
mysql
文章转载自
数据库技术大会
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨