




“ pandas库是数据分析非常常用的库,我还是想把这个库的基础打牢。”

01
—
文件读取写入
大家对之前文件的打开关闭、读取写入是否还记得?咱们复习一下:

02
—
Excel读取:pandas.read_excel
那我们来看看pandas是如何操作的:(我估计我会喜新厌旧了,哈哈),大家准备下之前做练习用的一个excel表,然后用anaconda集成工具打开。
读取:pandas.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=False, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, comment=None, skipfooter=0, convert_float=None, mangle_dupe_cols=True, storage_options=None)
针对列,其用到的参数为:header,usecols,names,index_col
针对行,其所用到的参数为: skipfooter, skiprows, nrows
通用格式:dtype、converters(日期数据)、true_values和false_value
日期格式的转换: parse_dates 与 date_parser
空值处理:na_values,keep_defalt_na,na_filter
1、io:文件路径名
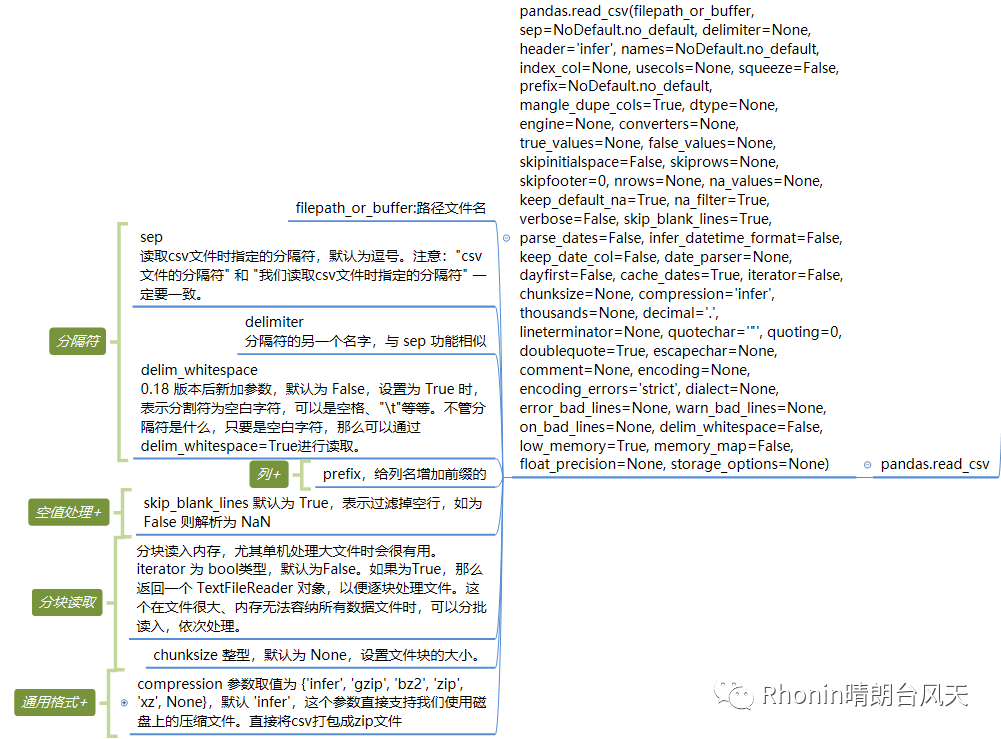
xlsx=pd.read_excel(r'C:\Users\Rhonin\Desktop\课程表.xlsx')xlsxOut[8]:cno cname cpno ccredit0 1 数据库 5.0 41 2 数学 NaN 22 3 信息系统 1.0 43 4 操作系统 6.0 34 5 数据结构 7.0 45 6 数据处理 NaN 26 7 PASCAL语言 6.0 4
2、sheet_name:str、int、list 或 None,默认为 0
字符是表示的是该表的名字,数字表示的是表的位置(从0开始),数字和字符是请求单个表格;列表形式的是请求多个表格.赋值为None是请求全部的表格
data=pd.read_excel(r'C:\Users\Rhonin\Desktop\课程表.xlsx',['Sheet1','Sheet2'])dataOut[28]:{'Sheet1': cno cname cpno ccredit0 1 数据库 5.0 41 2 数学 NaN 22 3 信息系统 1.0 43 4 操作系统 6.0 34 5 数据结构 7.0 45 6 数据处理 NaN 26 7 PASCAL语言 6.0 4,'Sheet2': cno cname cpno ccredit0 10 统计 5 5}data=pd.read_excel(r'C:\Users\Rhonin\Desktop\课程表.xlsx',sheet_name=None)dataOut[30]:{'Sheet1': cno cname cpno ccredit0 1 数据库 5.0 41 2 数学 NaN 22 3 信息系统 1.0 43 4 操作系统 6.0 34 5 数据结构 7.0 45 6 数据处理 NaN 26 7 PASCAL语言 6.0 4,'Sheet2': cno cname cpno ccredit0 10 统计 5 5}
3、header:指定作为列名的行,默认0,即取第一行的值为列名。数据为列名行以下的数据;若数据不含列名,则设定 header = None
data=pd.read_excel(r'C:\Users\Rhonin\Desktop\课程表.xlsx',header=3)dataOut[3]:3 信息系统 1 40 4 操作系统 6.0 31 5 数据结构 7.0 42 6 数据处理 NaN 23 7 PASCAL语言 6.0 4data=pd.read_excel(r'C:\Users\Rhonin\Desktop\课程表.xlsx',header=0)dataOut[5]:cno cname cpno ccredit0 1 数据库 5.0 41 2 数学 NaN 22 3 信息系统 1.0 43 4 操作系统 6.0 34 5 数据结构 7.0 45 6 数据处理 NaN 26 7 PASCAL语言 6.0 4data=pd.read_excel(r'C:\Users\Rhonin\Desktop\课程表.xlsx',header=[1,3])dataOut[7]:1 数据库 5 43 信息系统 1 40 4 操作系统 6.0 31 5 数据结构 7.0 42 6 数据处理 NaN 23 7 PASCAL语言 6.0 4
4、names:array-like, default None
names:指定列的名字,传入一个list数据,默认为None
data=pd.read_excel(r'C:\Users\Rhonin\Desktop\课程表.xlsx',names=['a','b','c','d'])dataOut[30]:a b c d0 1 数据库 5.0 41 2 数学 NaN 22 3 信息系统 1.0 43 4 操作系统 6.0 34 5 数据结构 7.0 45 6 数据处理 NaN 26 7 PASCAL语言 6.0 4
5、index_col:指定列为索引列,默认None列, index_col = 0——第一列为index值
index_col int,int 列表,默认None
data=pd.read_excel(r'C:\Users\Rhonin\Desktop\课程表.xlsx',index_col=2)dataOut[13]:cno cname ccreditcpno5.0 1 数据库 4NaN 2 数学 21.0 3 信息系统 46.0 4 操作系统 37.0 5 数据结构 4NaN 6 数据处理 26.0 7 PASCAL语言 4data=pd.read_excel(r'C:\Users\Rhonin\Desktop\课程表.xlsx',index_col=[2,3,1])dataOut[15]:cnocpno ccredit cname5 4 数据库 12 数学 21 4 信息系统 36 3 操作系统 47 4 数据结构 52 数据处理 66 4 PASCAL语言 7
6、usecols:int, str, list-like, or callable default None,指定解析的列
如果为None则解析所有列</br> 如果为int则表示要解析的最后一列</br> 如果为int列表则表示要解析的列号列表</br> 如果字符串则表示以逗号分隔的Excel列字母和列范围列表(例如“A:E”或“A,C,E:F”)。范围包括双方。
data=pd.read_excel(r'C:\Users\Rhonin\Desktop\课程表.xlsx',usecols=[1,2])dataOut[18]:cname cpno0 数据库 5.01 数学 NaN2 信息系统 1.03 操作系统 6.04 数据结构 7.05 数据处理 NaN6 PASCAL语言 6.0
7、skiprows:list-like, int, or callable, optional,省略指定行数的数据,从第一行开始
data=pd.read_excel(r'C:\Users\Rhonin\Desktop\课程表.xlsx',skiprows=[2,4])dataOut[32]:cno cname cpno ccredit0 1 数据库 5.0 41 3 信息系统 1.0 42 5 数据结构 7.0 43 6 数据处理 NaN 24 7 PASCAL语言 6.0 4
8、 nrows int,默认None。解析0-所指定的行数
data=pd.read_excel(r'C:\Users\Rhonin\Desktop\课程表.xlsx',nrows=3)dataOut[36]:cno cname cpno ccredit0 1 数据库 5.0 41 2 数学 NaN 22 3 信息系统 1.0 4
9、skipfooter:int, default 0。省略从尾部数的行数据,没有第0行,从1开始
data=pd.read_excel(r'C:\Users\Rhonin\Desktop\课程表.xlsx',skipfooter=1)dataOut[34]:cno cname cpno ccredit0 1 数据库 5.0 41 2 数学 NaN 22 3 信息系统 1.0 43 4 操作系统 6.0 34 5 数据结构 7.0 45 6 数据处理 NaN 2
10、dtype: 转换某些列的数据类型,字典:{col _ name: type _ name,...}
data=pd.read_excel(r'C:\Users\Rhonin\Desktop\课程表.xlsx',dtype={'ccredit':float})dataOut[38]:cno cname cpno ccredit0 1 数据库 5.0 4.01 2 数学 NaN 2.02 3 信息系统 1.0 4.03 4 操作系统 6.0 3.04 5 数据结构 7.0 4.05 6 数据处理 NaN 2.06 7 PASCAL语言 6.0 4.0
11、converters某些特定列的各种转换(包括日期,数据类型等),converters意思就是将某个函数应用到某列上
converters={'date': lambda x: pd.to_datetime(x, format='%Y%m')})
百分比:convertPercent
data=pd.read_excel(r'C:\Users\Rhonin\Desktop\课程表.xlsx',converters={'ccredit':int})dataOut[24]:cno cname cpno ccredit0 1 数据库 5.0 41 2 数学 NaN 22 3 信息系统 1.0 43 4 操作系统 6.0 34 5 数据结构 7.0 45 6 数据处理 NaN 26 7 PASCAL语言 6.0 4
12、keep_default_na bool,默认为 True。
keep_default_na :解析数据时是否包含默认 NaN 值。根据是否传入na_values,行为如下:
如果keep_default_na为True,并且na_values指定,na_values 被附加到NaN值用于解析所述默认值。
如果keep_default_na为 True,并且未指定na_values,则仅使用默认 NaN 值进行解析。
如果keep_default_na为 False,并且指定了na_values,则仅使用na_values指定的 NaN 值进行解析。
如果keep_default_na为 False,并且未指定na_values,则不会将任何字符串解析为 NaN。
请注意,如果na_filter作为 False 传入,则keep_default_na和 na_values参数将被忽略。
如果指定为 False,那么 pandas 在读取时就不会擅自将那些默认的值转成空值了,它们在 CSV 中长什么样,pandas 读取出来之后就还长什么样,即使单元格中啥也没有,那么得到的也是一个空字符串
data=pd.read_excel(r'C:\Users\Rhonin\Desktop\课程表.xlsx',keep_default_na=False)dataOut[42]:cno cname cpno ccredit0 1 数据库 5 41 2 数学 22 3 信息系统 1 43 4 操作系统 6 34 5 数据结构 7 45 6 数据处理 26 7 PASCAL语言 6 4
13、na_values参数处理na数据
如空值是-,通过na_values='--'转换成NaN
14、true_values和false_value,列表,默认None
指定哪些值应该被清洗为True,哪些值被清洗为False
注意这里的替换规则,只有当某一列的数据全部出现在true_values + false_values里面,才会被替换。
原因就是只有一个字段中所有的值都在true_values + false_values中,它们才会被替换
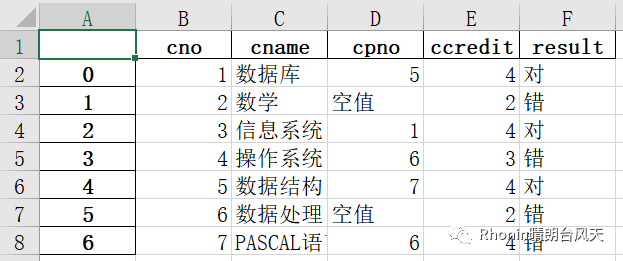
data=pd.read_excel(r'C:\Users\Rhonin\Desktop\课程表.xlsx',true_values=['对'],false_values=['错'])dataOut[62]:cno cname cpno ccredit result0 1 数据库 5.0 4 True1 2 数学 NaN 2 False2 3 信息系统 1.0 4 True3 4 操作系统 6.0 3 False4 5 数据结构 7.0 4 True5 6 数据处理 NaN 2 False6 7 PASCAL语言 6.0 4 Falsedata=pd.read_excel(r'C:\Users\Rhonin\Desktop\课程表.xlsx',true_values=['对','错'])dataOut[64]:cno cname cpno ccredit result0 1 数据库 5.0 4 True1 2 数学 NaN 2 True2 3 信息系统 1.0 4 True3 4 操作系统 6.0 3 True4 5 数据结构 7.0 4 True5 6 数据处理 NaN 2 True6 7 PASCAL语言 6.0 4 True
15、na_filter是否进行空值检测,默认为 True,如果指定为 False,那么 pandas 在读取 CSV 的时候不会进行任何空值的判断和检测,所有的值都会保留原样,提升文件运行速度
16、parse_dates:布尔值:值为True,解析index列
列表:列名或者列数--['col_name','col_name',..] or ['col_num1, col_num2,...] ,同时将多列字符串格式转换成日期格式
列表:列表的列表 ---[['col_name','col_name2']] or [['col_num','col_num2']],将列表中的多列,合并一个日期格式
字典:{'str': ['col_name','col_name2',..]} 为新合并的日期列指定一个新的列名'col_name'
parse_dates指定某些列为时间类型,这个参数一般搭配下面的date_parser使用。
date_parser是用来配合parse_dates参数的,因为有的列虽然是日期,但没办法直接转化,需要我们指定一个解析格式:
parse_dates=["date"], date_parser=lambda x: datetime.strptime(x, "%Y年%m月%d日")
小结:



03
—
CSV读取:pandas.read_csv
读取:pandas.read_csv(filepath_or_buffer, sep=NoDefault.no_default, delimiter=None, header='infer', names=NoDefault.no_default, index_col=None, usecols=None, squeeze=False, prefix=NoDefault.no_default, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression='infer', thousands=None, decimal='.', lineterminator=None, quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, encoding_errors='strict', dialect=None, error_bad_lines=None, warn_bad_lines=None, on_bad_lines=None, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None, storage_options=None)
分隔符参数:sep,delimiter,delim_whitespace
分块读取:iterator,chunksize
空值处理+:skip_blank_lines
列+:prefix
通用格式+:compression
其它参数同excl读取参数
1、filepath_or_buffer:路径文件名
2、sep
读取csv文件时指定的分隔符,默认为逗号。注意:"csv文件的分隔符" 和 "我们读取csv文件时指定的分隔符" 一定要一致。
3、delimiter
分隔符的另一个名字,与 sep 功能相似
4、delim_whitespace
0.18 版本后新加参数,默认为 False,设置为 True 时,表示分割符为空白字符,可以是空格、"\t"等等。不管分隔符是什么,只要是空白字符,那么可以通过delim_whitespace=True进行读取。
5、prefix,给列名增加前缀的
6、skip_blank_lines 默认为 True,表示过滤掉空行,如为 False 则解析为 NaN
7、分块读入内存,尤其单机处理大文件时会很有用。
iterator 为 bool类型,默认为False。如果为True,那么返回一个 TextFileReader 对象,以便逐块处理文件。这个在文件很大、内存无法容纳所有数据文件时,可以分批读入,依次处理。
8、chunksize 整型,默认为 None,设置文件块的大小。
9、compression 参数取值为 {'infer', 'gzip', 'bz2', 'zip', 'xz', None},默认 'infer',这个参数直接支持我们使用磁盘上的压缩文件。直接将csv打包成zip文件
04
—
EXCEL写入:变量.to_excel
写入:变量.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None, storage_options=None)
1、excel_writer:文件路径
xlsx.to_excel(r'C:\Users\Rhonin\Desktop\课程表1.xlsx')
原课程表 导出后的课程表1
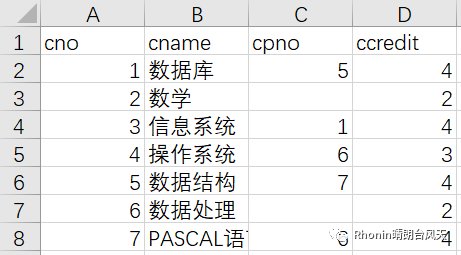
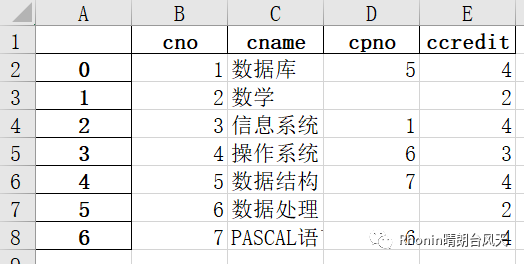
大家留意一下差别,导出的excel会增加索引。
2、sheet_name str,默认'Sheet1'
将包含 DataFrame 的工作表的名称。
3、na_rep str,默认 '',缺少数据表示。
data.to_excel(r'C:\Users\Rhonin\Desktop\课程表1.xlsx',na_rep='空值')
4、float_format str,可选
浮点数的格式字符串。例如 float_format="%.2f"将 0.1234 格式化为 0.12。
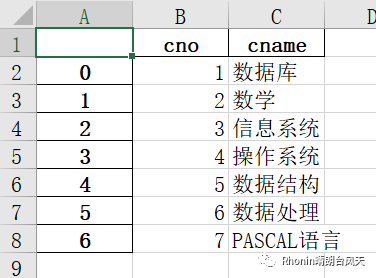
5、columns:序列或 str 列表,可选,要写入的列。
data.to_excel(r'C:\Users\Rhonin\Desktop\课程表1.xlsx',columns=['cno','cname'])
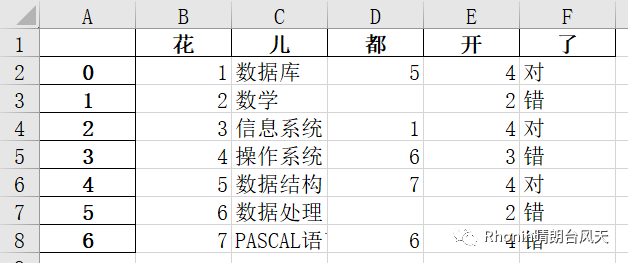
6、header bool 或 str 列表,默认为 True
写出列名。如果给出字符串列表,则假定它是列名的别名。
data.to_excel(r'C:\Users\Rhonin\Desktop\课程表1.xlsx',header=['花','儿','都','开','了'])
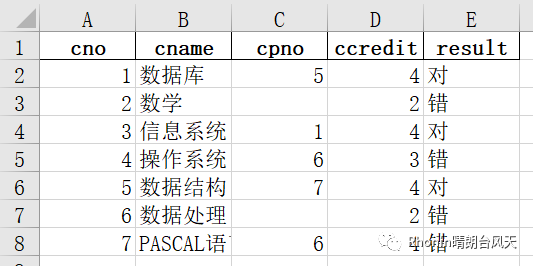
7、index:布尔值,默认为 True,写行名称(索引),去索引
data.to_excel(r'C:\Users\Rhonin\Desktop\课程表1.xlsx',index=False)
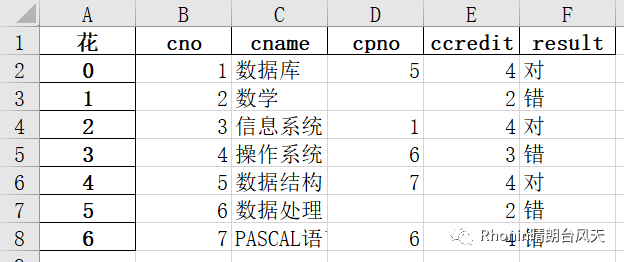
8、index_label str 或序列,可选
如果需要,索引列的列标签。如果未指定,并且 标头和索引为 True,则使用索引名称。如果 DataFrame 使用 MultiIndex,则应给出序列。
data.to_excel(r'C:\Users\Rhonin\Desktop\课程表1.xlsx',index_label=['花'])
9、startrow int,默认为 0。左上角单元格行转储数据帧。
startcol int,默认为 0。左上角单元格列转储数据帧。
表格定位
data.to_excel(r'C:\Users\Rhonin\Desktop\课程表1.xlsx',startrow=3)
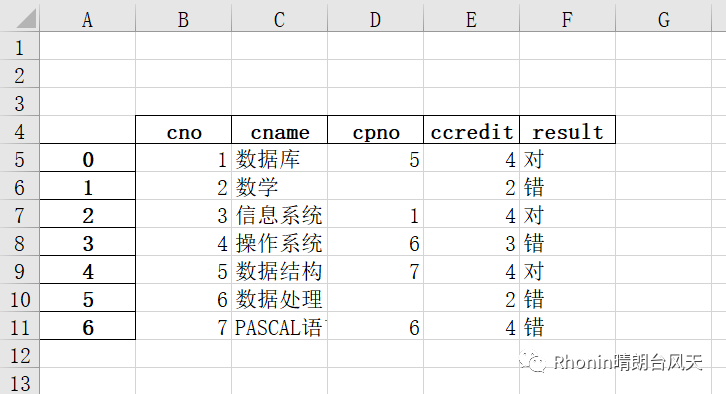
10、freeze_panes:int 元组(行,列),可选,冻结行列
data.to_excel(r'C:\Users\Rhonin\Desktop\课程表1.xlsx',freeze_panes=(1,2))
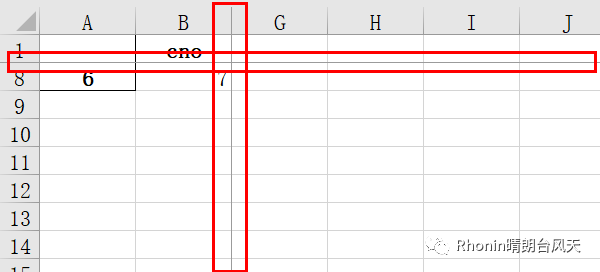

05
—
CSV写入:变量.to_csv
写入:变量.to_csv(path_or_buf=None, sep=',', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression='infer', quoting=None, quotechar='"', line_terminator=None, chunksize=None, date_format=None, doublequote=True, escapechar=None, decimal='.', errors='strict', storage_options=None)
1、sep str,默认','分隔符
06
—
SQL读写:pandas.read_sql/变量.to_sql

07
—
SPSS读取:pandas.read_spss


