




ClusterControl使用多种恢复算法进行编程,以自动响应影响数据库系统的不同类型的常见故障。它了解不同类型的数据库拓扑和与数据库相关的流程管理,以帮助您确定恢复群集的最佳方法。在某种程度上, ClusterControl可以提高数据库的可用性。
一些拓扑管理器仅涵盖群集恢复,例如MHA,Orchestrator和mysqlfailover,但是您必须自己处理节点恢复。ClusterControl支持群集和节点级别的恢复。
配置选项
ClusterControl支持两个恢复组件,分别是:
- 群集-尝试将群集恢复到操作状态
- 节点-尝试将节点恢复到操作状态
为了确保服务可用性尽可能高,这两个组件是最重要的事情。如果 ClusterControl顶部已经有拓扑管理器,则可以禁用自动恢复功能,然后让其他拓扑管理器为您处理。ClusterControl具有所有的可能性。
可以通过简单的切换ON / OFF启用和禁用自动恢复功能,该功能适用于群集或节点恢复。绿色图标表示已启用,红色图标表示已禁用。以下屏幕快照显示了在数据库集群列表中可以找到它的位置:
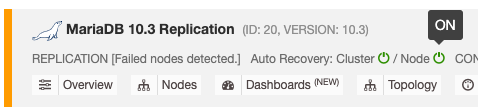
有3个ClusterControl参数可用于控制恢复行为。所有参数默认为true(使用布尔整数0或1设置):
- enable_autorecovery-启用群集和节点恢复。此参数是enable_cluster_recovery和enable_node_recovery的超集。如果设置为0,则子集参数将关闭。
- enable_cluster_recover y-如果启用,ClusterControl将执行群集恢复。
- enable_node_recovery-如果启用,ClusterControl将执行节点恢复。
群集恢复涵盖了恢复整个群集拓扑的尝试。例如,一个主从复制必须在任何给定时间至少有一个主服务器处于活动状态,而与可用从服务器的数量无关。ClusterControl尝试对复制群集至少一次纠正拓扑,但对NDB Cluster和Galera Cluster 等多主复制进行无限纠正。
节点恢复涵盖了节点恢复问题,例如,是否在不使用ClusterControl的情况下停止节点,例如通过SSH控制台的系统停止命令或被OOM进程杀死。
节点恢复
在间歇性故障的情况下, ClusterControl可以通过监视进程和与数据库节点的连接来恢复数据库节点。在此过程中,它的工作方式与systemd类似,除非您有意通过ClusterControl UI将其停止,否则它将确保 MySQL服务已启动并正在运行。
如果节点重新联机,ClusterControl将建立与数据库节点的连接,并执行必要的操作。以下是ClusterControl将如何恢复节点:
- 它将等待systemd / chkconfig / init启动受监视的服务/进程30秒
- 如果受监视的服务/进程仍然关闭,则ClusterControl将尝试自动启动数据库服务。
- 如果ClusterControl无法恢复受监视的服务/进程,则会发出警报。
请注意,如果数据库关闭是由用户启动的,则ClusterControl将不会尝试恢复特定的节点。它希望用户通过ClusterControl UI来启动它,方法是转到Node- > Node Actions-> Start Node或显式使用OS命令。
恢复包括与数据库有关的所有服务,例如ProxySQL,HAProxy,MaxScale,Keepalived,Prometheus导出器和garbd。特别注意Prometheus导出器,其中ClusterControl使用名为“ daemon”的程序来守护导出器进程。ClusterControl将尝试连接到导出程序的侦听端口以进行运行状况检查和验证。因此,建议从ClusterControl和Prometheus服务器打开导出器端口,以确保在恢复过程中没有错误警报。
集群恢复
ClusterControl了解数据库拓扑并遵循执行恢复的最佳实践。对于具有内置容错功能的数据库群集(例如 Galera Cluster, NDB Cluster和 MongoDB Replicaset),数据库服务器将通过仲裁计算,心跳和角色切换(如果有)自动执行故障转移过程。ClusterControl监视过程并对可视化进行必要的调整,例如在“拓扑”视图下反映更改,并针对新角色(例如副本集中的新主节点)调整监视和管理组件。
对于不具有自动恢复功能的内置容错功能的数据库技术(例如MySQL / MariaDB复制和PostgreSQL / TimescaleDB流复制),ClusterControl将遵循数据库供应商提供的最佳实践来执行恢复过程。如果恢复失败,则需要用户干预,并且您当然会收到有关此情况的警报通知。
在混合/混合拓扑中,例如连接到Galera群集或NDB群集的异步从属服务器,如果启用了群集恢复,则节点将由ClusterControl恢复。
群集恢复不适用于独立的MySQL服务器。但是,建议在ClusterControl UI中为此群集类型打开节点和群集恢复。
MySQL / MariaDB复制
ClusterControl支持以下MySQL / MariaDB复制设置的恢复:
- 使用MySQL GTID的主从
- MariaDB GTID的主从
- 没有GTID的主从(MySQL和MariaDB都包括)
- MySQL GTID的大师-大师
- MariaDB GTID的大师-大师
- 连接到Galera群集的异步从站
执行群集恢复时,ClusterControl将遵循以下参数:
- enable_cluster_autorecovery
- auto_manage_readonly
- repl_password
- repl_user
- plication_auto_rebuild_slave
- 复制_检查_binlog_过滤_bf_故障转移
- plication_check_external_bf_failover
- plication_failed_reslave_failover_script
- plication_failover_blacklist
- 复制失败事件
- plication_failover_wait_to_apply_timeout
- Replication_Failover_Whitelist
- plication_onfail_failover_script
- plication_post_failover_script
- plication_post_switchover_script
- plication_post_unsuccessful_failover_script
- plication_pre_failover_script
- plication_pre_switchover_script
- 复制_skip_apply_missing_txs
- 复制错误
在监视和管理主从复制时,ClusterControl将遵循以下规则:
- 所有节点将以read_only = ON和super_read_only = ON(无论其角色如何)启动。
- 在任何给定时间只允许一个主机(read_only = OFF)运行。
- 依靠MySQL变量report_host映射拓扑。
- 如果一次有两个或多个节点的read_only = OFF,ClusterControl将在两个主节点上自动将read_only = ON设置为防止意外写入。通过禁用只读,需要用户干预才能选择实际的母版。转到节点->节点操作->禁用只读。
万一活动主服务器出现故障,ClusterControl将尝试按以下顺序执行主服务器故障转移:
- 主机无法访问3秒后,ClusterControl将发出警报。
- 检查从机可用性,ClusterControl必须至少有一个从机可以访问。
- 选择奴隶作为主人候选人。
- 如果启用了GTID,ClusterControl将计算错误事务的概率。
- 如果未检测到错误事务,则所选事务将被提升为新的主事务。
- 创建并授予复制用户以供从属使用。
- 将指向旧主机的所有从机更改为新升级的主机。
- 启动slave并启用只读。
- 刷新在所有节点上的日志。
- 如果从属升级失败,则ClusterControl将中止恢复作业。需要用户干预或cmon服务重新启动才能再次触发恢复作业。
- 当旧的母版再次可用时,它将以只读方式启动,并且不会成为复制的一部分。需要用户干预。
同时,将发出以下警报:

PostgreSQL / TimescaleDB流复制
ClusterControl支持恢复以下PostgreSQL复制设置:
- PostgreSQL流复制
- TimescaleDB流复制
执行群集恢复时,ClusterControl将遵循以下参数:
- enable_cluster_autorecovery
- repl_password
- repl_user
- plication_auto_rebuild_slave
- Replication_Failover_Whitelist
- plication_failover_blacklist
有关每个参数的更多详细信息,请参阅文档页面。
ClusterControl将遵循以下规则来管理和监视PostgreSQL流复制设置:
- wal_level设置为“副本”(或“ hot_standby”,具体取决于PostgreSQL版本)。
- 主服务器上的变量archive_mode设置为ON。
- 在从属节点上设置recovery.conf文件,这会将节点变成启用了只读功能的热备用数据库。
如果活动主服务器出现故障,ClusterControl将尝试按以下顺序执行群集恢复:
- 主机不可达10秒后,ClusterControl将发出警报。
- 在10秒的适度等待超时后,ClusterControl将启动主故障转移作业。
- 在所有可用节点上采样replayLocation和receiveLocation以确定最高级的节点。
- 将最高级的节点升级为新的主节点。
- 停止奴隶。
- 使用pg_rewind验证同步状态。
- 用新的主机重启从机。
- 如果从属升级失败,则ClusterControl将中止恢复作业。需要用户干预或cmon服务重新启动才能再次触发恢复作业。
- 当旧的主服务器再次可用时,它将被迫关闭,并且不会成为复制的一部分。需要用户干预。进一步查看。
当旧的主机重新联机时,如果PostgreSQL服务正在运行,则ClusterControl将强制关闭PostgreSQL服务。这是为了保护服务器免受意外写入,因为它将在没有恢复文件(recovery.conf)的情况下启动,这意味着它是可写的。您应该期望以下行将出现在postgresql- {day} .log中:
2019-11-27 05:06:10.091 UTC [2392] LOG: database system is ready to accept connections
2019-11-27 05:06:27.696 UTC [2392] LOG: received fast shutdown request
2019-11-27 05:06:27.700 UTC [2392] LOG: aborting any active transactions
2019-11-27 05:06:27.703 UTC [2766] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.704 UTC [2758] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.709 UTC [2392] LOG: background worker "logical replication launcher" (PID 2419) exited with exit code 1
2019-11-27 05:06:27.709 UTC [2414] LOG: shutting down
2019-11-27 05:06:27.735 UTC [2392] LOG: database system is shut down
在PostgreSQL的启动服务器后,回来在网上围绕5时06分10秒,但ClusterControl后,大约5时06分27秒17秒执行快速关机。如果您不希望这样做,则可以暂时禁用此群集的节点恢复。
结论
ClusterControl自动恢复了解数据库集群的拓扑结构,并且能够将宕机或降级的集群恢复到可正常运行的集群,这将极大地改善数据库服务的正常运行时间。立即尝试ClusterContro l,在SLA和数据库可用性方面达到九位数。不认识你 看看这个酷的 9位数计算器。
