




在我们进行性能测试时,需要监控服务器性能的表现情况,以分析性能瓶颈,找出性能问题的原因。以下是使用jmeter的PerfMon插件对服务器性能进行监控的配置过程。
安装jmeter perfmon插件
1. 启动jmeter。
2. 点击“选项-Plugins Manager”。如果没有Plugins Manager,就需要到官网下载Plugins Manager的jar包进行安装:https://jmeter-plugins.org/wiki/PluginsManager/。
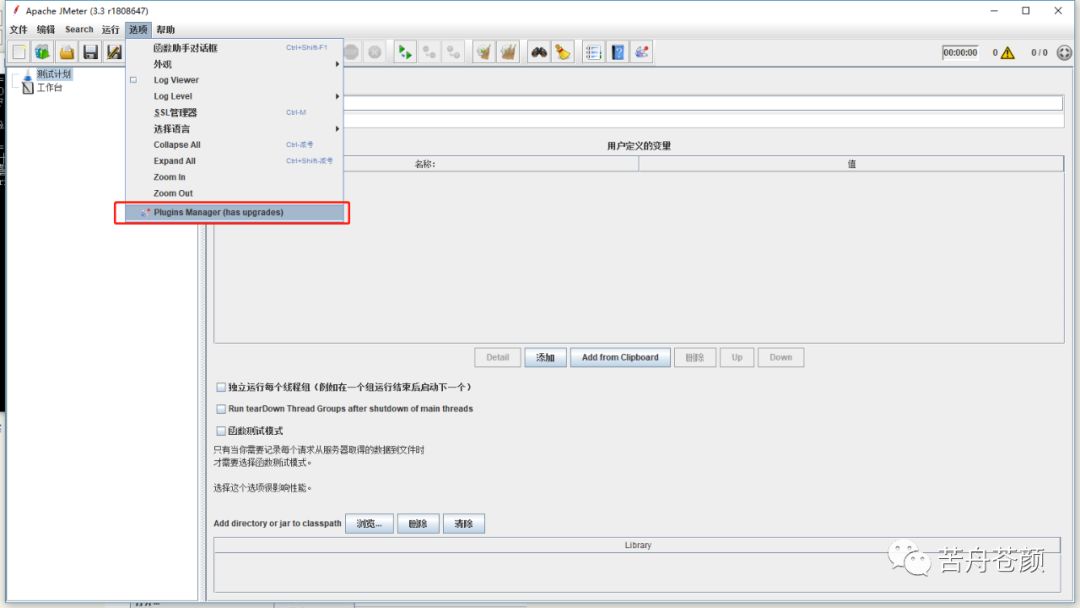
3. 搜索并安装perfmon插件,安装完成会自动重启jmeter。也可以从官网下载perfmon插件自己安装:https://jmeter-plugins.org/?search=jpgc-perfmon
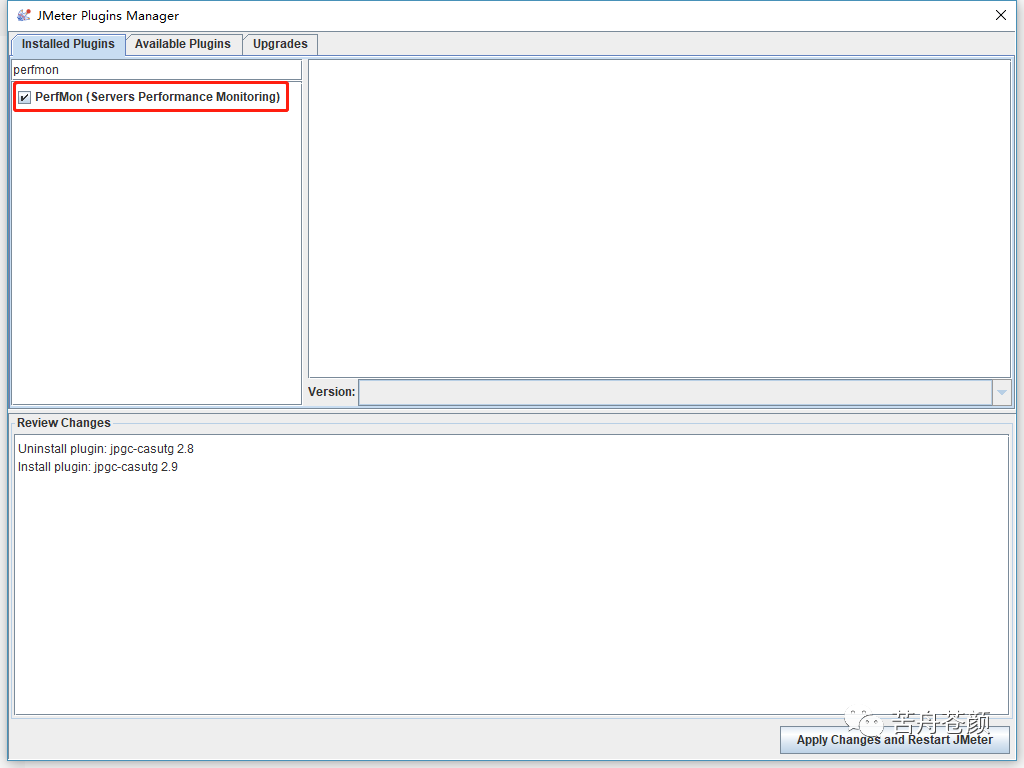
4. 重启完成后,添加监听器就会多出来perfmon的监听器了。
在服务器上安装serveragent代理工具
1. 下载serveragent:https://github.com/undera/perfmon-agent/blob/master/README.md#supported-metrics
2. 安装serveragent:将下载的serveragent压缩包上传到服务器并解压。
3. 关闭服务器的防火墙。
4. server agent的默认端口是4444,先查看服务器4444端口是否被占用。

5. 如果4444端口被占用,在启动server agent时重新指定端口:$ sh startAgent.sh --tcp-port 3450;如果4444端口没有被占用,直接启动server agent 就可以:$ sh startAgent.sh 。(如果是Windows服务器,直接运行startAgent.bat就可以)
6. 验证server agent 安装是否成功。在JMeter压力机使用telnet像ServerAgent发送“test”,如telnet 192.168.18.10 4444,连通后,输入test,正常情况下ServerAgent会输出类似INFO 2019-10-08 13:54:40.733 [kg.apc.p] (): Yep, we received the 'test' command的日志。注:有可能如果压力机是Windows系统,有可能没有安装telnet工具,需要去“程序和功能-启用或关闭Windows功能”中开启。



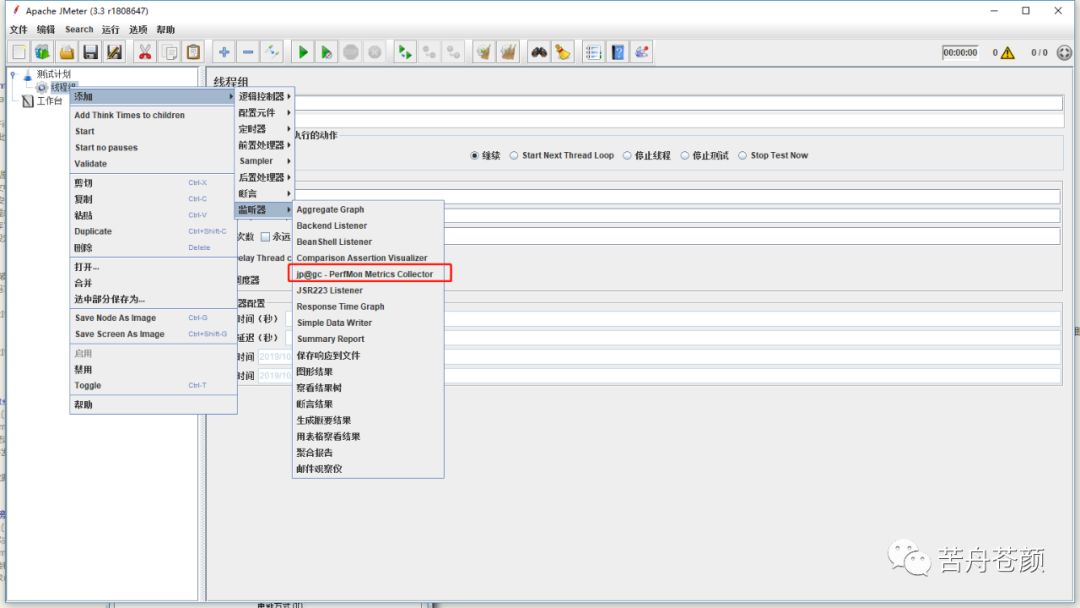
配置jmeter监控项
1.在jmeter中添加线程组、添加perfmon监听器
2.在perfmon监听器中点击“Add Row”添加监控项。每个监控项需要配置服务器ip、server agent 端口、监控项。
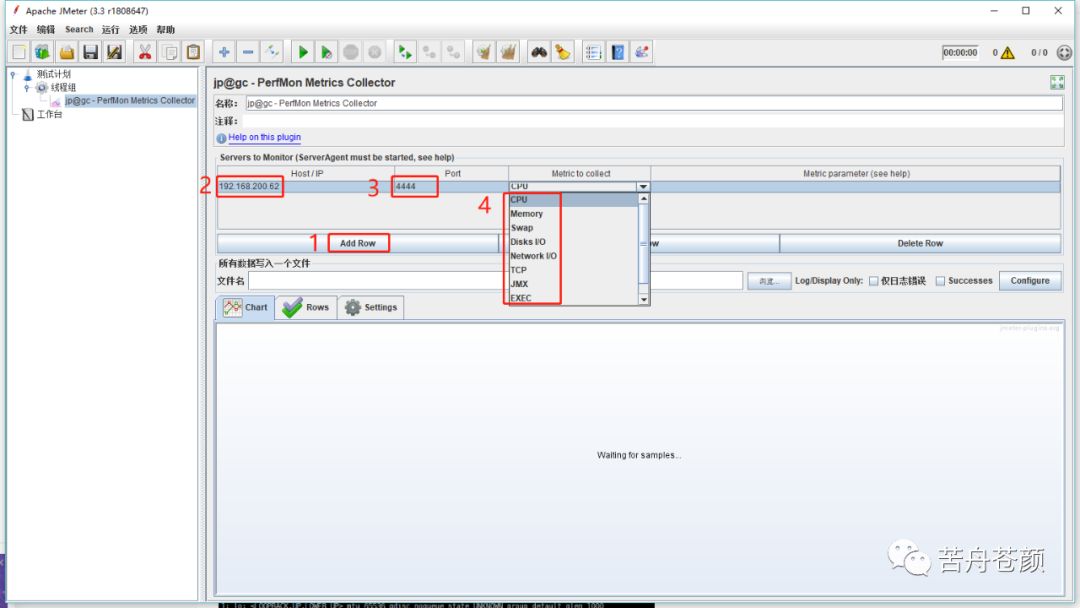
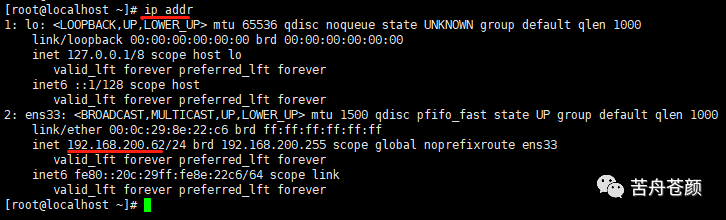
Host/IP:要监控的服务器地址,可以在服务器使用命令查看:$ ip addr
port:server agent 启动的端口,默认是4444,如果修改过就填写修改过的端口。
metric parameter:要监控的指标。有CPU、Disks I/O、Memory等
开始监控
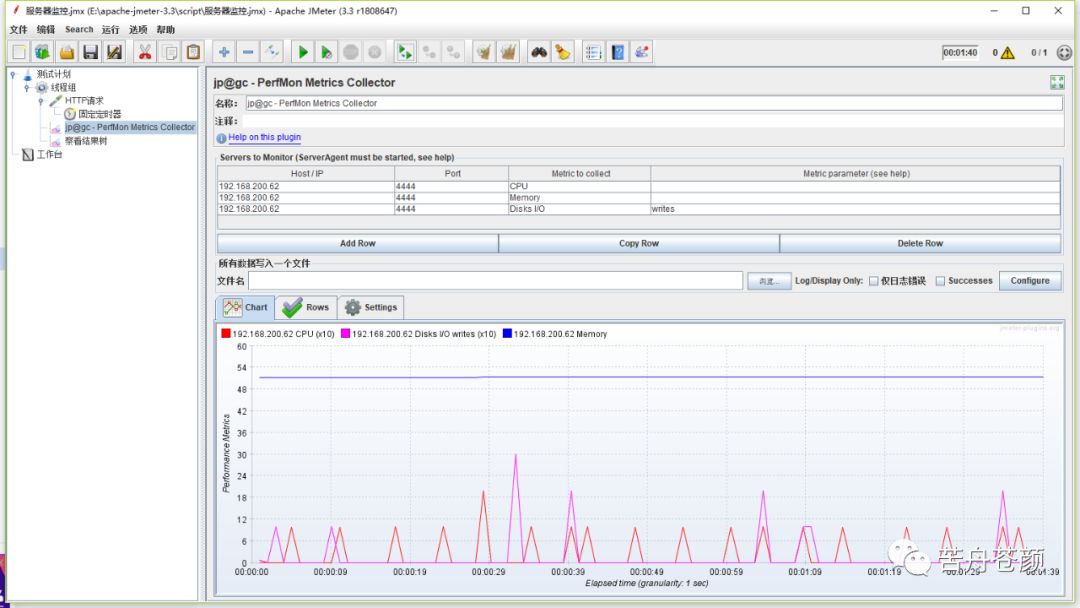
在线程组下面添加一个http取样器,再添加一个查看结果树、固定定时器,设置循环,然后运行。查看perfmon监听器,即可看到监控指标的图示。
结果分析
1. 监控指标
各项指标可以Metric parameter设置界面找到答案。我们知道对于服务器如CPU、内存等每一个监控指标类型,都有多种数据从不同维度来体现资源使用情况,比如对于CPU,在Linux系统用top命令,就可以看idle、user、system等数据。对于PerfMon插件,可以通过Metric parameter来设置某种资源具体要收集和展示的数据,只是它的入口并不是很醒目,如下图所示,需要双击输入框后,点击最后边的按钮打开,打开的界面如图4中级红色箭头所指,虽然每种指标的具体配置项不同,但结构相同,都分为Primary Metrics、Additional Metrics等等,Primary是官方认为常用的,通常也是实际工作中更关心,更具有参考意义的指标项,Additional则是在一些特殊场景可能需要了解的指标项。
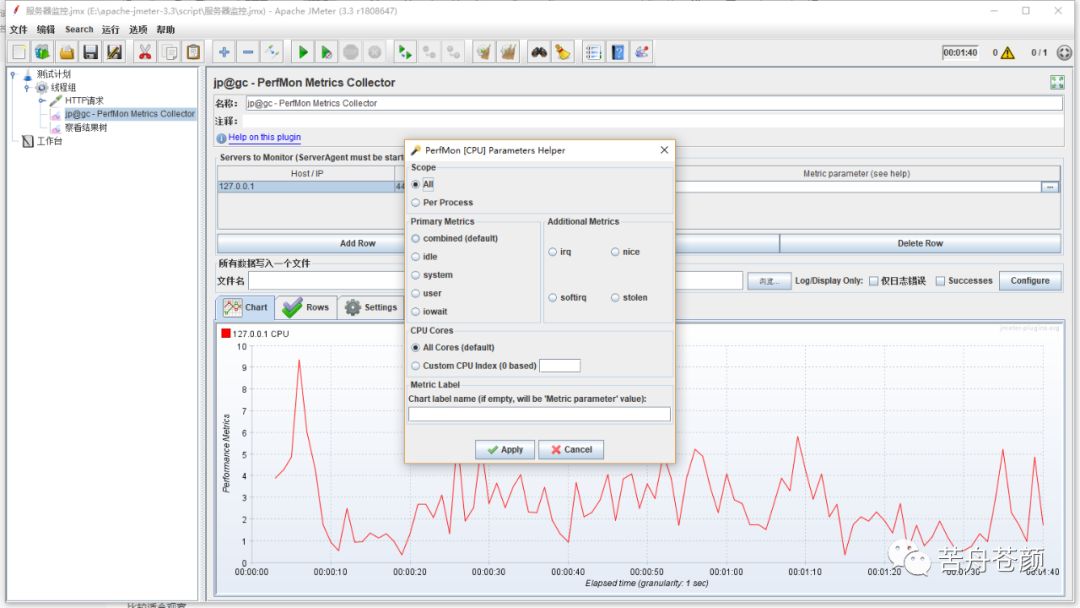
1.1 CPU
对于各指标项,数值都是代表百分比,比如默认配置(combined)下在曲线图中看到某个时间的数值是30,即代表此时总的cpu使用时间占比为30%。
有两点比较有用的地方值得说明:一是在Scope区域,可以通过Per Process选项来获取指定进程的CPU使用情况,二是在CPU Cores区域,我们可以选择监控指定的单个Core。
1.2 Memory
各指标项中,usedperc(默认)和freeperc两项的数值代表与总内存的百分比,其余指标项的数值都是指内存大小,选中对应项,可以看到Metric Unit区域单位配置将变为可用,通常Mb会比较适合观察。
同样,也可以选择监控指定进程的数据
1.3 Disk I/O
各指标项中,queue(默认)的数值代表等待I/O队列长度,reads、writes分别代表每秒处理的读/写次数,readbytes、writebytes顾名思义,代表每秒读/写的数据量,单位同样在Metric Unit区域配置,通常Mb会比较适合观察。
如果有挂载多个存储设备,可以在Filesystem Filter区域指定要监控的设备。
2.曲线图设置
2.1 使用策略
如果测试场景的测试执行时间较长,采集的监控数据量比较大,为了在GUI模式查看曲线图时更方便、快捷,建议将各个监控指标项单独使用一个PerfMon监听器,从而配置不同的指标项数据存储到不同的文件中,测试执行完毕后,载入数据和数据查看都会更快。
如果预计数据量不会太大,可以以服务器为单位来划分PerfMon监听器。这样可以方便的观察到整个测试过程中,某台服务器各项资源使用情况的变化趋势。
对于分布式服务、为了方便观察各个节点的负载分布、负载变化趋势,可以考虑将同类型的节点放置到同一个PerfMon监听器,以便对比观察。
2.2 数值
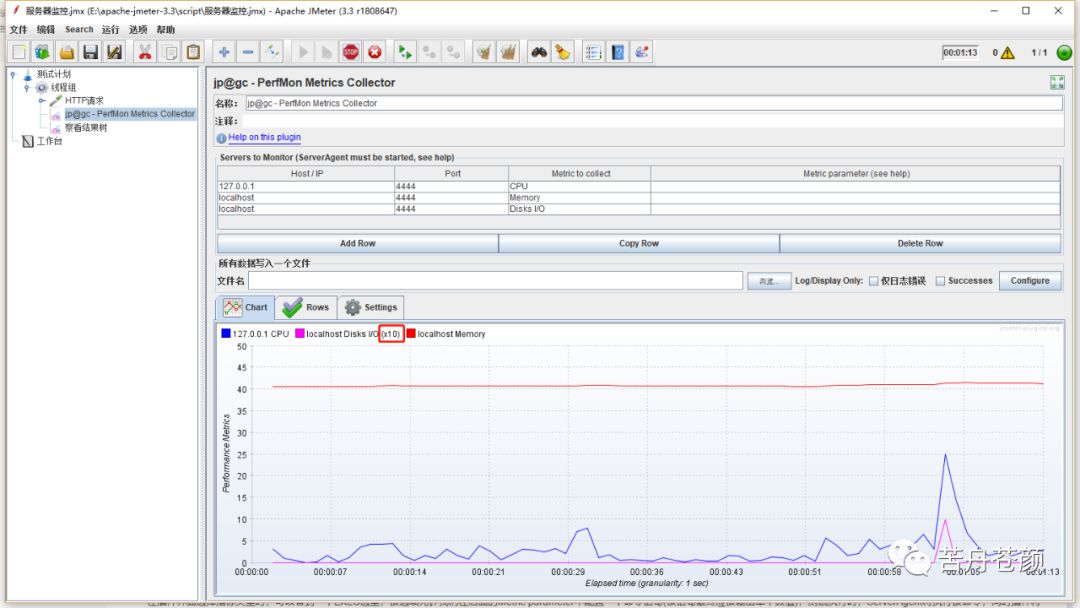
当一个PerfMon监听器中展示多种指标项的数据时,为了曲线图的可观察性,插件会自动进行优化,如图5所示,我们看到在磁盘读写监控项后面有个x10,代表曲线图中展示的数值是在采集到的真实数值上放大了10倍,目的是为了保证不同数据项在同一坐标系中展示时,各项都变化趋势都能够被观察到。
2.3 曲线图配置
插件界面的Rows标签页可以调整要在曲线图中展示的指标项。
Setting标签页中常用的配置项:
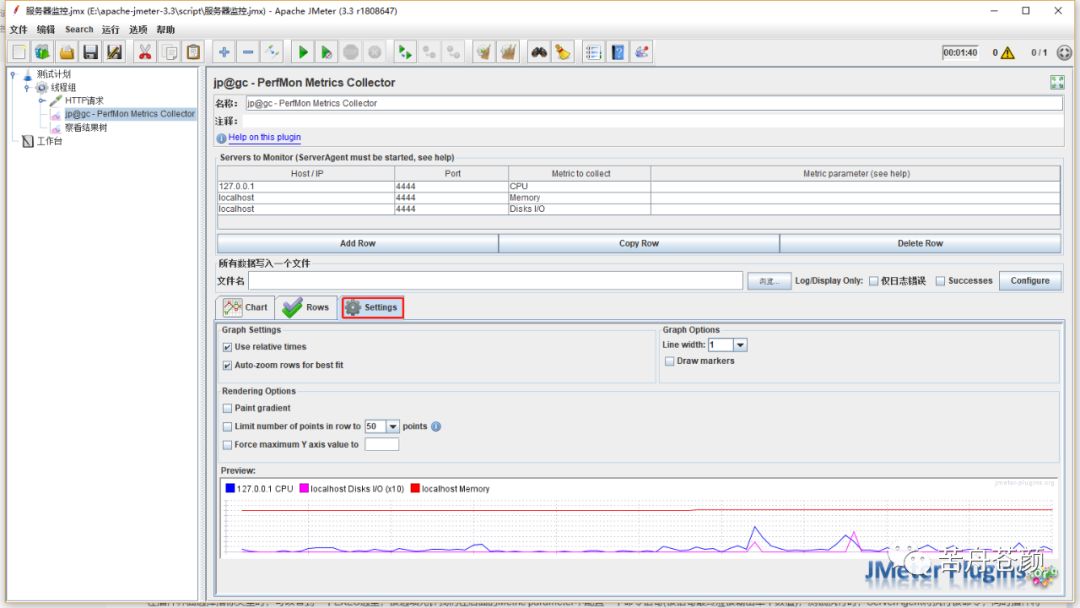
use relative times:用于配置曲线图x轴表示相对时间(测试开始时为0)还是实际系统时间。
Auto-zoom rows for best fit:默认勾选,则会有上一节讲数值时提到的展示数据自动放大的功能,取消勾选则全部展示采集的实际数值。
Limit number of points in row to xx points:勾选后可以设定曲线图展示的采样点数量,我们的测试报告会有不同的角色查看,其中一些角色可能不具备也不需要对监控数据的细节理解能力,此时我们提供的监控曲线图应该是易读的,如果按照实际的所有采样点来渲染出曲线图,可能会有很多偏离趋势的噪点数据,这对于不了解的人来说可能会有很多疑惑,所以当我们有了分析结论,最后报告呈现的时候,可以考虑通过调整采样点,来让曲线图更好的展示资源使用趋势,消除其他不必要的信息。
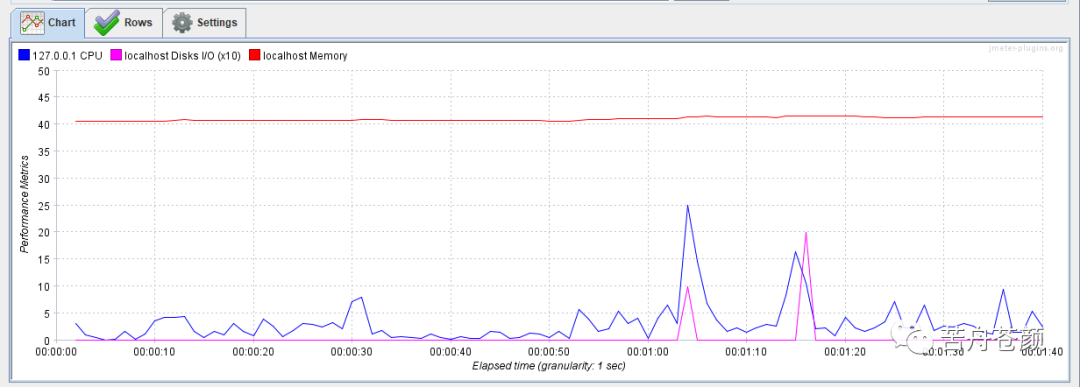
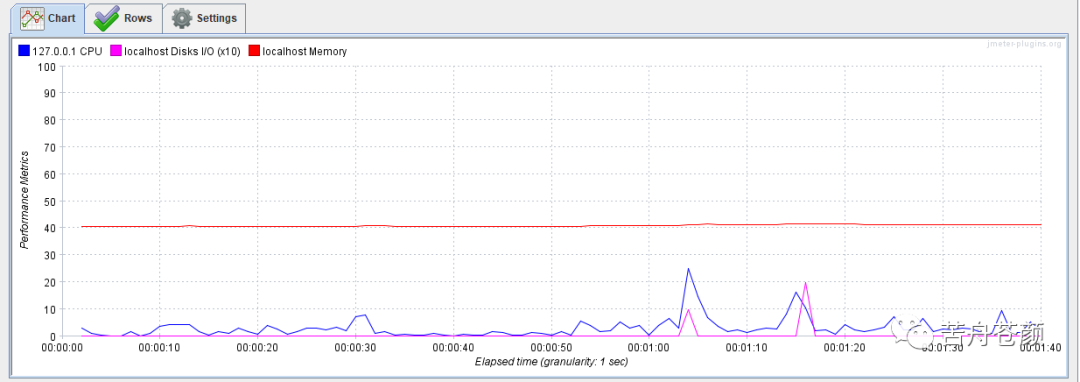
Force maximum Y axis value to xx:实际上我更多会选择不勾选,不勾选的情况下,插件在描绘曲线图的时候,会根据数值大小自动调整Y轴最大值,以达到更佳可读性,如图,分别是不勾选,和勾选后设置最大值为100时的曲线图效果,显然图7可以更容易的观察到变化的细节。不过与上一项类似,可能在对外出具报告时,为了更少的解释说明,可能需要某个指定的数值。
3.自定义指标
3.1 EXEC
在插件界面选择指标类型时,可以看到一个EXEC选型,该选项允许我们在后面的Metric parameter中配置一个命令语句(该语句最终应该输出单个数值),测试执行时,ServerAgent将执行该命令,同时插件将接收ServerAgent捕获的输出数值。
语法规则:EXEC所配置的语句需要按照一定的规则来填写,先是给出命令的执行程序的位置,然后将具体的命令以及命令的参数作为,命令和命令参数都需要用冒号”:”来隔开。比如/bin/sh:-c:free |grep Mem |awk '{pring $7}'
/bin/sh,代表命令的执行程序
-c,即/bin/sh的-c选型,有-c选型的情况下,将从后面的字符串按一定规则解析为命令和命令参数
可以看到有用冒号分隔了执行程序/选型参数/命令语句
对于windows,也类似,如C\:\Windows\System32\cmd.exe:/c:echo %RANDOM%
3.2 TAIL
如同Linux的tail命令,读取文件的最后一行,用在这里,需要文件每一行只包含一个单独的数值。借助tail,我们可以通过自定义脚本监控任意指标,只需要脚本的输出满足要求即可。
显而易见,TAIL后面的参数就是配置要读取的文件的地址,测试执行时,ServerAgent将根据配置读取所在服务器的指定文件。
参考文章:
https://blog.csdn.net/tx_programming/article/details/79990311
