




如果说Hive是离线数仓的代表,那么Greenplum就是MPP数据库的代表。在离线数仓的年代,以Hive为核心的数据仓库席卷数据仓库市场,几乎成为了离线数仓的代名词。但是Hive的查询能力非常弱,通常需要其它计算引擎辅助才能完成OLAP查询。
具体来说,Hive数据仓库的查询引擎主要有以下几种选择:
Ø Spark支持sql查询,需要启动Thrift Server,不稳定,查询速度一般几秒到几分钟。
Ø Impala是CDH公司推出的产品,一般用在CDH平台中,MPP架构,查询比Spark快,但是是C++开发的,非CDH平台安装比较困难;
Ø Presto和Hive一样也是Facebook开源的,但是语法居然不兼容Hive。查询速度也比较快,是基于MPP架构。
Ø Kylin是国人开源的MOLAP软件,基于Spark引擎对Hive数据做预计算保存在Hbase或者其他存储中,查询速度非常快并且稳定,一般在10s以下。但是模型构建复杂,使用和运维都不太方便。
Ø Clickhouse是目前最火的OLAP查询软件,特点是快,集成了各大数据库的精华引擎;独立于Hadoop平台以外,需要把Hive数据同步迁移过去;有限的SQL支持,几乎不支持join。
Ø Greenplum是MPP架构数据库的代表,支持行存储和列存储,支持非常完善的SQL语法,开发和使用与传统数据库几乎一致,查询速度通常在1s到10s之间。
详细的对比分析可以查看笔者之前的文章《大数据≠hadoop,数据中台选型你应该看到这些分布式数据库》。当时由于认知水平有限,未将Doris纳入比较。
根据我的经验,最大的常用业务查询表数据量在亿级以下,建议直接使用Greenplum数据库作为数据仓库或者数据中台,完全无需搭建Hive数据仓库。在数据量超过亿级的时候,Hive on Spark将实现更好的批处理,降低硬件成本,但是这个时候,Greenplum将成为数据应用层(ADS)的可选数据库之一(其他选项包括Kylin、Clickhouse、Doirs、Hana等)。
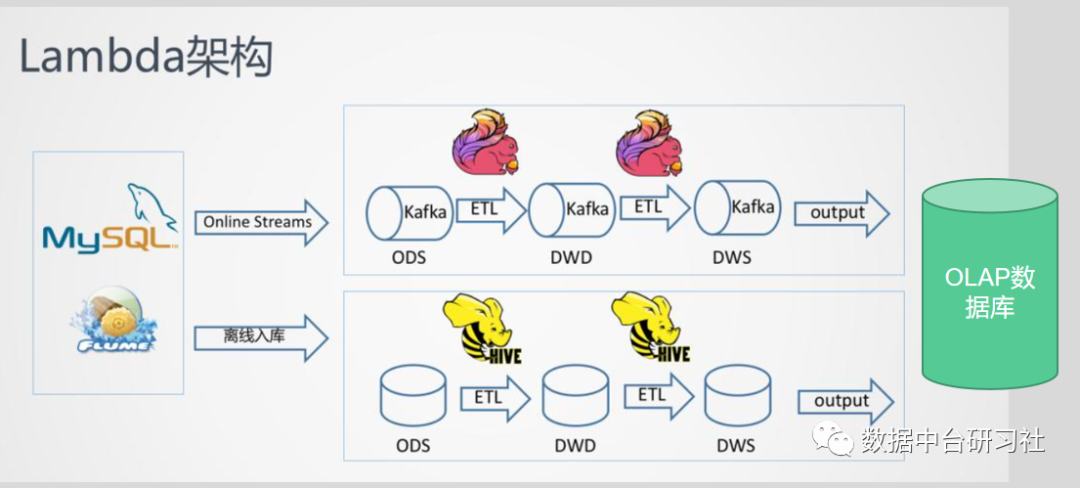
在Greenplum作为ADS存储的情况下,我们需要批量导入ADS层数据到Greenplum,这个时候GPLoad将发挥巨大的作用。
GPLoad是Greenplum数据库提供的用来进行并行数据装载的工具。GPLoad的实现原理是Greenplum数据库使用可读外部表和并行文件服务gpfdist装载数据的一个命令集合,允许通过使用配置文件的方式设置数据格式、文件位置等参数来创建外部表。GPLoad命令通过按照YAML格式定义的装载说明配置文件,然后执行insert、update、merger操作,将数据装载到目标数据库表中。
GPLoad的控制文件采用YAML1.1文档格式编写,因此它必须得是有效的YAML格式。YAML配置文件格式要求如下:
VERSION: 1.0.0.1DATABASE: opsUSER: gpadminHOST: mdw-1PORT: 5432GPLOAD:INPUT:- SOURCE:LOCAL_HOSTNAME:- etl1-1- etl1-2- etl1-3- etl1-4PORT: 8081FILE:- /var/load/data/*- COLUMNS:- name: text- amount: float4- category: text- descr: text- date: date- FORMAT: text- DELIMITER: '|'- ERROR_LIMIT: 25- LOG_ERRORS: TrueOUTPUT:- TABLE: payables.expenses- MODE: INSERTSQL:- BEFORE: "INSERT INTO audit VALUES('start', current_timestamp)"- AFTER: "INSERT INTO audit VALUES('end', current_timestamp)"
接下来,我们将通过一个模板脚本和shell程序实现HDFS数据的批量导入Greenplum。这个脚本是我2020年上半年实现的,至今仍然稳定运行在生产环境中。
首先,我们定义一个模板的yml文件gpload_cfg_template.yml,内容如下:
VERSION: 1.0.0.1DATABASE: xxUSER: xxHOST: 192.168.5.30PORT: 5432GPLOAD:INPUT:- SOURCE:LOCAL_HOSTNAME:- 192.168.5.10PORT: 12000PORT_RANGE: [12000,13000]FILE:- /data/hdsp/infra/ETL_HOME/shell/tempdata/{dbname}.{table}/*- FORMAT: text- HEADER: false- DELIMITER: '\001'- NULL_AS: '\N'OUTPUT:- TABLE: {dbname}.{table}- MODE: INSERTPRELOAD:- TRUNCATE: trueSQL:
其次,我们创建一个shell脚本hive2gp_gpload.sh,实现以下功能:
复制yaml模板,并根据shell脚本参数替换数据库表和表名;
从HDFS上线下载文件到本地,要求数据文件必须是TEXT格式;
运行gpload命令,加载数据到Greenplum数据库;
删除本地文件。
shell代码如下:
#!/bin/bash# 使用方式# eg: ./gpload2hive.sh dw dw_ret_sales_detail_text# 免密登录配置: ~.pgpassif [ ! -n "$2" ]; thenecho "Invalid arguments. Usage: sh hive2gp_gpload.sh dbname tablename"exit -1elsedbname=$1;tablename=$2;fisource ~/.bash_profile;shellpath=/data/hdsp/infra/ETL_HOME/shellyml_file=${shellpath}/gpload_yml/${dbname}.${tablename}.ymlif [ ! -f ${yml_file} ]; thencp $shellpath/gpload_yml/gpload_cfg_template.yml ${yml_file}sed -i "s/{table}/$tablename/g" $yml_file;sed -i "s/{dbname}/$dbname/g" $yml_file;fi#删除上一次抽取的文件rm -rf $shellpath/tempdata/${dbname}.${tablename}echo "[${dbname}.${tablename}]:start to get hdfs file!"#从hdfs上获取文件hdfs dfs -get hdfs://hdp01/data/apps/hive/warehouse/cabbeen_dw.db/$tablename $shellpath/tempdata/${dbname}.${tablename}echo "[${dbname}.${tablename}]:get hdfs file sucess! start to load!"#load数据到GP/data/greenplum6/greenplum-db/bin/gpload -f $yml_file -U zz-l $shellpath/gpload_log/${dbname}_${tablename}_$(date +"%Y-%m-%d-%H-%M-%S").logecho "[${dbname}.${tablename}]:load success!"#删除本次抽取的文件,节省空间rm -rf $shellpath/tempdata/${dbname}.${tablename}
调用脚本的方式如下:
sh hive2gp_gpload.sh dbname tablename
使用这种方式有以下前提:
1. hive表数据为text格式,分隔符为默认分隔符\u0001
2. gpload需安装,也可以直接复制Greenplum安装包并配置环境变量
3. 数据库用户需要有权限创建表
4. gp和hive schame和table映射关系相同,字段顺序也要保持一致。

《数据中台研习社》微信群,请添:laowang5244,备注【进群】
🧐分享、点赞、在看,给个三连击呗!👇
