




hive的三种部署模式
1、使用内置的derby数据库做元数据的存储
使用内置的derby数据库做元数据的存储,操作derby数据库做元数据的管理。使用derby存储方式时,运行hive会在当前目录生成一个derby文件和一个metastore_db目录。
这种存储方式的弊端是在同一个目录下同时只能有一个hive客户端能使用数据库,目录不同时元数据也无法共享,不适合生产环境只适合练习。
2、 本地模式
使用mysql做元数据的存储,操作mysql数据库做元数据的管理。
优点:可以多个hive client一起使用,并且可以共享元数据。但mysql的连接信息明文存储在客户端配置,不便于数据库连接信息保密和以后对元数据库进行更改,如果客户端太多也会对mysql造成较大的压力,因为每个客户端都自己发起连接。
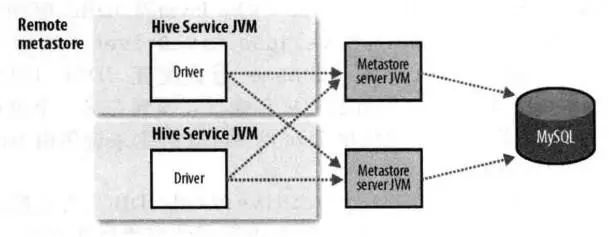
Driver和metastore在同一台机器上,能看到mysql的连接,不安全。只需启动metastore 服务就启动了hive。多个hive服务同时访问mysql,使得mysql服务端压力增加,可以通过mysql ha 减压。
3、远程模式
使用mysql做元数据的存储,使用metastore服务做元数据的管理。
优点:便于元数据库信息的保密。因为只需要在运行metastore的机器上配置元数据库连接信息,客户端只需要配置metastore连接信息即可。
缺点:会引发单点问题。例如metastore服务挂了,其它hive终端就获取不到元数据信息了。不过,一般来说企业环境推荐使用远程模式。
远程模式,Driver和metastore不在同一台机器上,看不到mysql的连接,安全可靠。需要启动每个机器的driver和metastore。多个hive服务同时访问metastore,使得metastore服务端压力增加,可以通过横向扩展metastore 减压。
总结:
本地模式和远程模式的区别:本地模式不需要单独起metastore服务,用的是跟hive在同一个进程里的metastore服务。
远程模式需要单独起metastore服务,然后每个客户端都在配置文件里配置连接到该metastore服务。远程模式的metastore服务和hive运行在不同的进程里。服务端指的是Metastore服务所在的机器,即安装metastore的机器。
metastore 服务端的配置,供参考。
<configuration>
<!-- mysql数据库配置-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbu:mysql://snl.hadoop:3306/hive_meta</value>
<description>mysql连接信息</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>mysql驱动</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>数据库用户名</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>1234abcd</value>
<description>数据库密码</description>
</property>
<!--HDFS文件路径配置,这里配置建表表和数据的存储路径 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>hive使用的HDFS目录</description>
</property>
<!-- metastore配置。在客户端使用时,mysql连接和metastore同时出现在配置文件中,客户端会选择使用metastore -->
<property>
<name>hive.metastore.schema.verification</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://snl.hadoop:9083</value>
</property>
</configuration>
安装部署完成hive以后,我们启动hive进行简单测试。启动hive的过程:配置完成之后,先启动matesotre服务,再启动hive client。
4、启动matesotre服务,命令:
nohup hive --service metastore > /dev/null 2>&1 &
注意:nohup是后台运行命令。
启动matesotre服务以后,启动hive客户端,直接hive或 ./bin/hive
5、对hive进行测试
建立一个新库,语法:
create database ;
show create database bigdata;
新建表
在bigdata数据库下创建表,首先进入数据库(use bigdata)如果没有进入数据库,那默认是default
//创建test表
create table tets(id int,name string);
//desc查看表的结构信息
desc tets;
//查看表的元数据信息
show create table user_info;
上传测试数据
#使用hadoop fs -put 命令 上传文件到 test 表的目录下
hadoop fs -put test.txt /hive/warehouse/bigdata.db/test
测试查询
select id,name from test;
6、hive的数据组织
hive数据库基本概念和关系型数据库类似,如:库,表,列,分区。按照数据组织粒度由大到小说明:
1)数据库 Databases 。Database起到命名空间的功能,避免表,视图等定义的混乱,同时也为权限的定义及分配提供良好的隔离。在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹。
2)表 Tables 每个表包含一个主题信息,有多个属性字段组成的二维数据集合,一个数据库可以包含多张表。在hdfs中表现为db目录下的一个文件夹。
3)分区 Partitions 每个表可以有一个或多个分区键值,是数据的存储单元,可以按分区key划分查询数据范围,有效提高查询效率。比如可以按月和按天设计表分区,查询是指定查某天则不需要扫描整月数据。在hdfs中表现为table目录下的子目录 。
4)桶 Buckets 表分区还可以按照某几列hash进行划分,是更细粒度的数据范围。桶表就是对应不同的文件。在HDFS中表现为table/分区/00000_0…0000N_0。
