




1、HDFS有什么作用
1)高容错:提供较高的容错率,因为数据有备份,通过机架感知策略,namenode会尽量将数据的复本放到不同的机架上,所以小规模的宕机不影响数据的存储。
对于网络的就近原则,先近再远,如果有多个机架,会在多个机架建立副本。
2、机架感知策略的实现机制
<property>
<name>topology.script.file.name</name>
<value>/path/to/script</value>
</property>

3、HDFS的系统结构
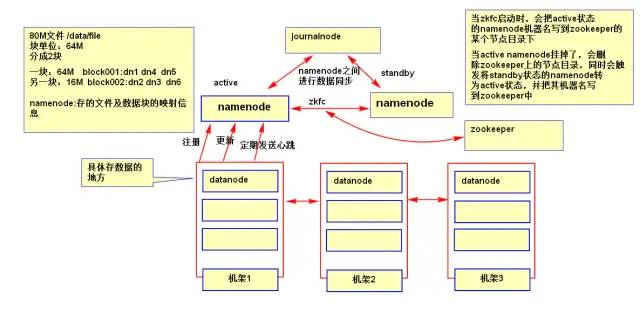
namenode和datanode之间的关系:
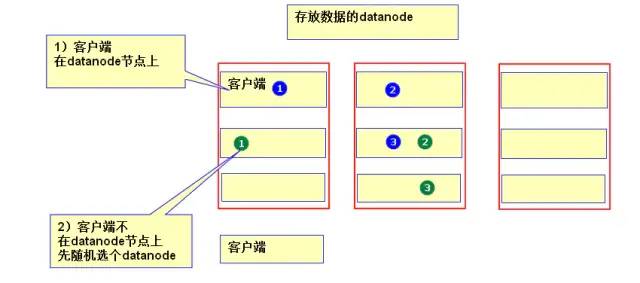
4、数据块——block
5、 namenode
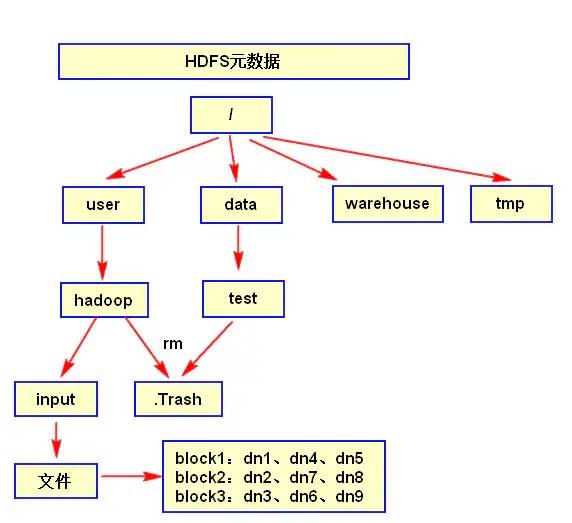
可以通过HDFS的操作日志记录文件(editlog)来恢复,如果元数据fsimage完整就直接恢复,不完整再用editlog进行补余。
6、datanode
7、HDFS数据的写入过程
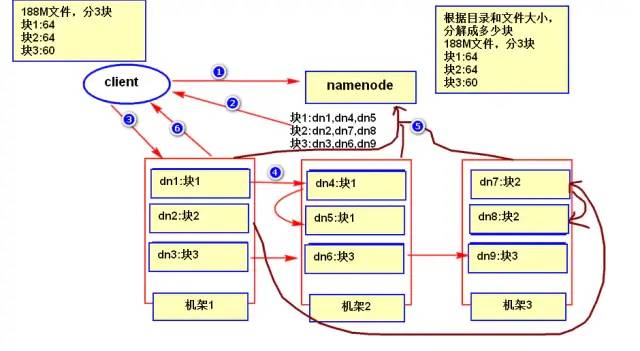
2)namenode根据你的情况(client端所在位置、文件大小)分配给你分配写入数据的位置也就是写到那几个机器上;
3)向datanode写入数据;
4)datanode复制数据;
5)复制完成之后,各数据节点向namenode上报block信息;
6)datanode通知客户端已完成。
8、HDFS数据的读取过程
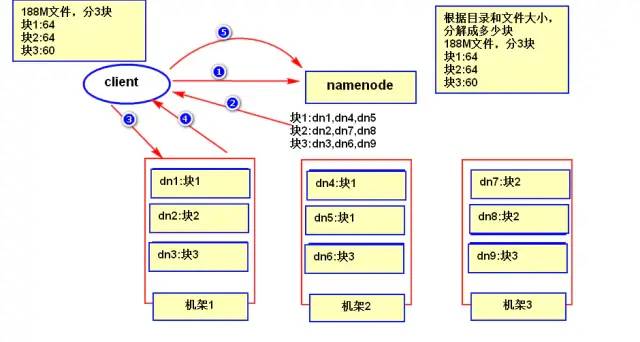
2)告诉namenode要读那个文件;
3)namenode返回block信息列表(包括要读取的数据在那个机器上);
4)到指定的机器上读取具体的数据;
5)datanode根据block信息找到数据的存储位置并返回数据给客户端;
6)客户端读完数据之后告诉namenode我已经读取完成。
文章转载自Spark大数据,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
