




节点崩溃随时可能发生,这在任何现实情况下都是不可避免的。那时,巨大的独立数据库在数据世界中游荡,每一次如此巨大的跌落都会在全球范围内引发一系列问题。如今,数据世界已经发生了变化。正被一群可以适应不断变化的小型,敏捷,集群式数据库解决案例所取代。
这样数据库的一个示例是Galera Cluster,它(通常)以节点集群的形式部署。如果Galera节点之一发生故障,会有什么变化?这如何影响整个集群的可用性?在此博客文章中,我们将对此进行深入研究并解释Galera高可用性基础知识。
Galera群集和数据库高可用性
Galera Cluster通常部署在至少三个节点的群集中。这是由于Galera使用定额机制来确保所有节点的群集状态都是明确的,并且可以进行自动故障处理。为此,需要三个节点-节点崩溃后,必须有超过50%的节点处于活动状态才能使群集正常运行。
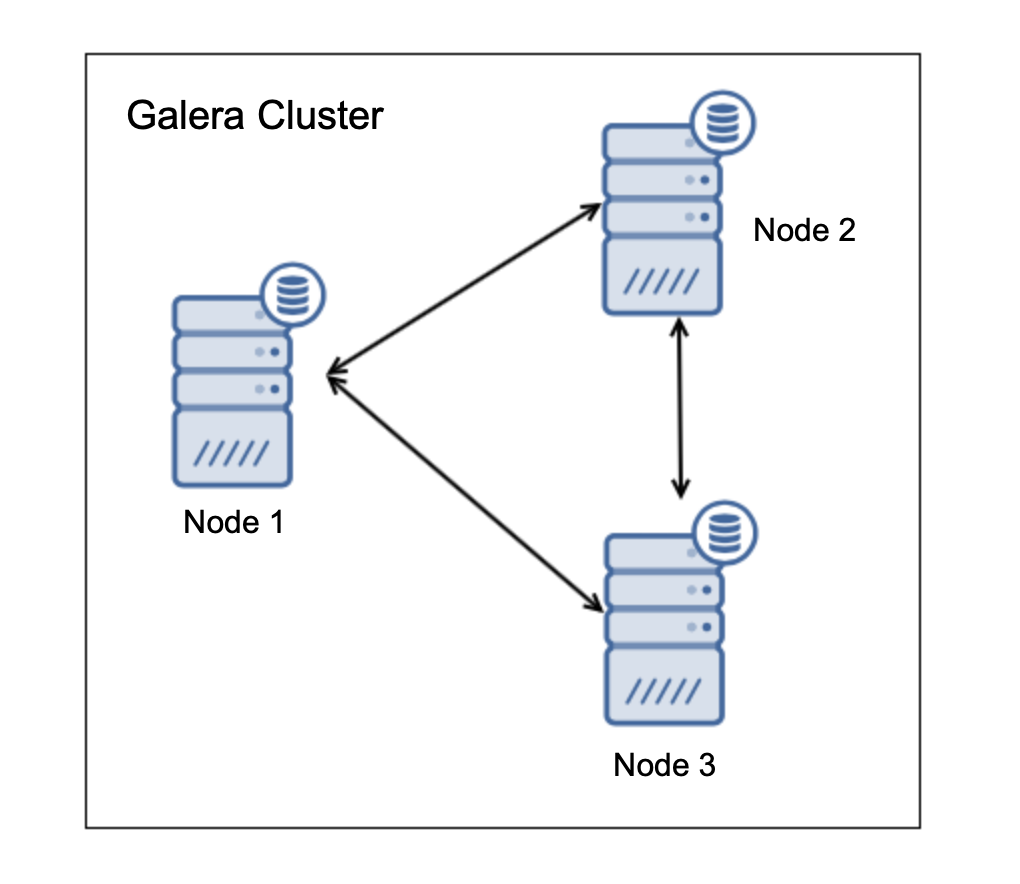
假设您在Galera Cluster中有三个节点,如上图所示。如果一个节点崩溃,情况将变为以下情况:
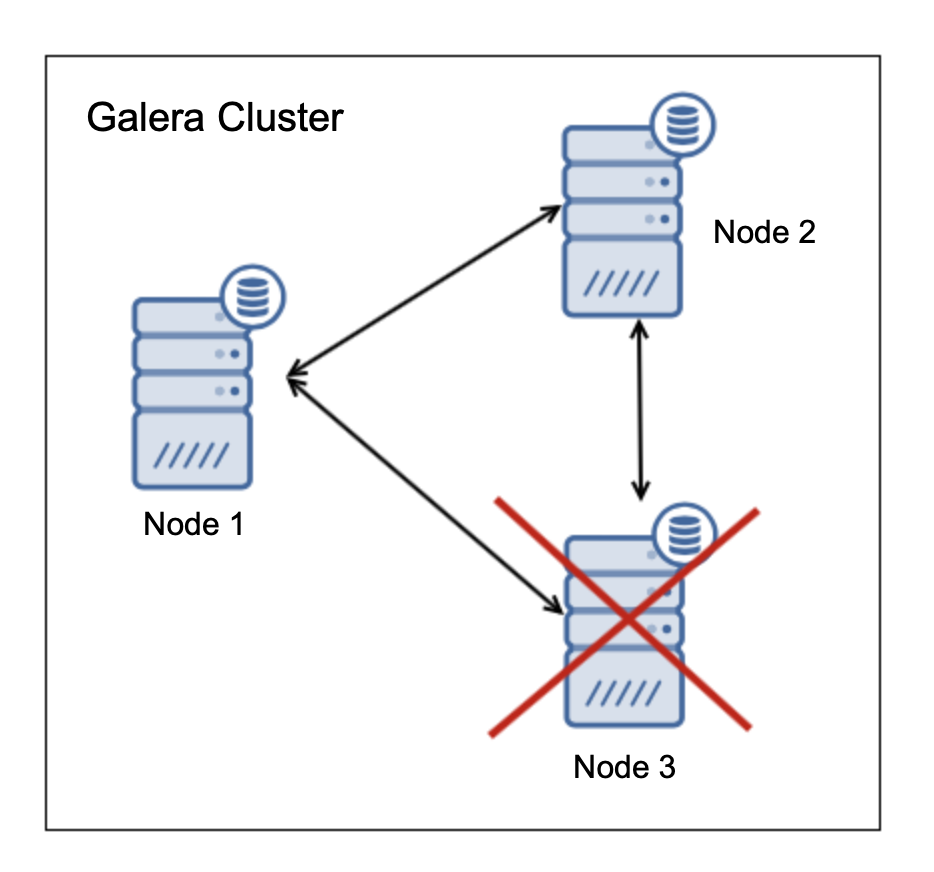
节点“ 3”关闭,但是有节点“ 1”和“ 2”,它们占集群中所有节点的66%。这意味着,这两个节点可以继续运行并形成集群。节点“ 3”(如果它是活动的,但无法连接到群集中的其他节点)将占群集中节点的33%,因此它将停止运行。
我们希望现在已经很清楚:最少三个节点。如果有两个节点,则每个节点将是群集中节点的50%,因此两个节点都不占多数-这样的群集不提供HA。如果我们要再增加一个节点怎么办?
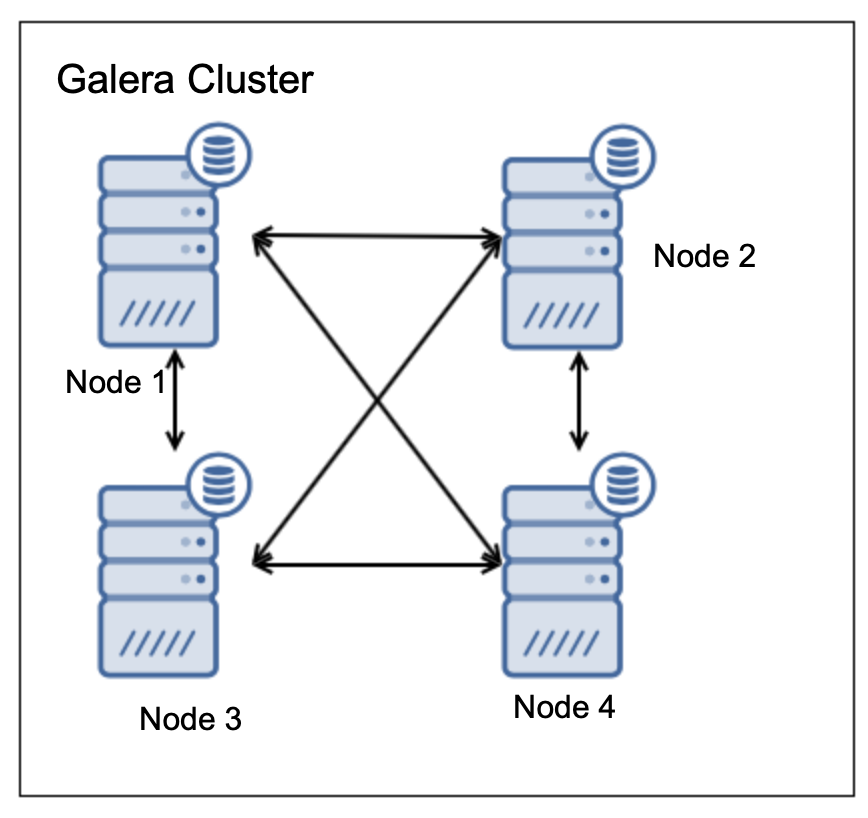
这种设置还允许一个节点发生故障:
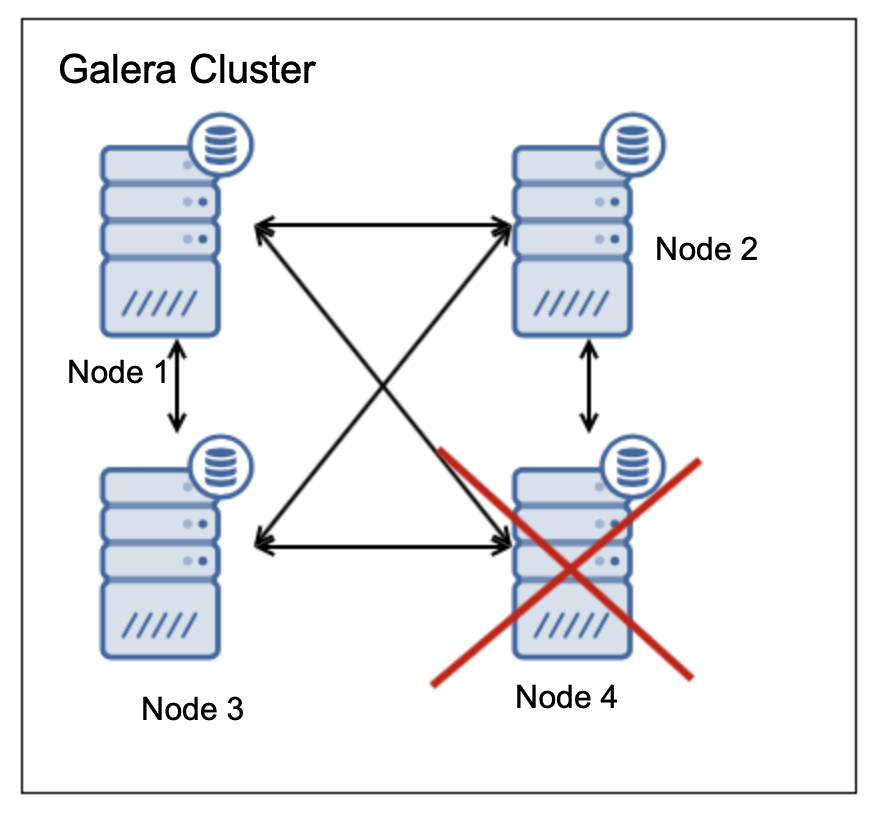
在这种情况下,我们有三个(75%)的节点处于运行状态,这是大多数。如果两个节点发生故障会怎样?
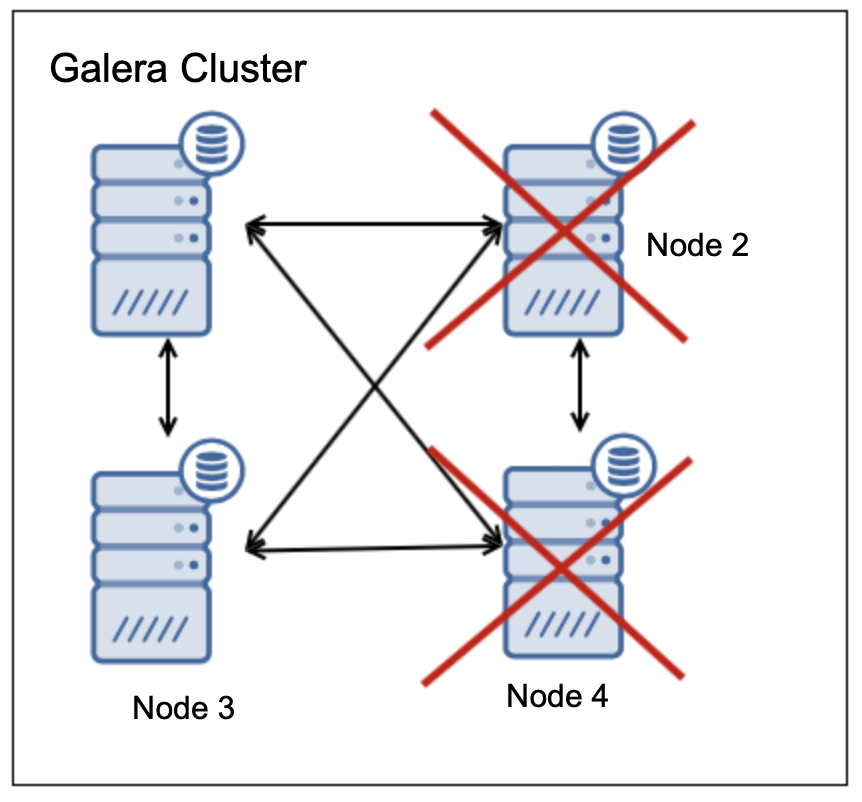
两个节点处于启动状态,两个节点处于关闭状态。只有50%的节点可用,没有多数节点,因此群集必须停止其操作。支持两个节点失败的最小群集大小为五个节点:
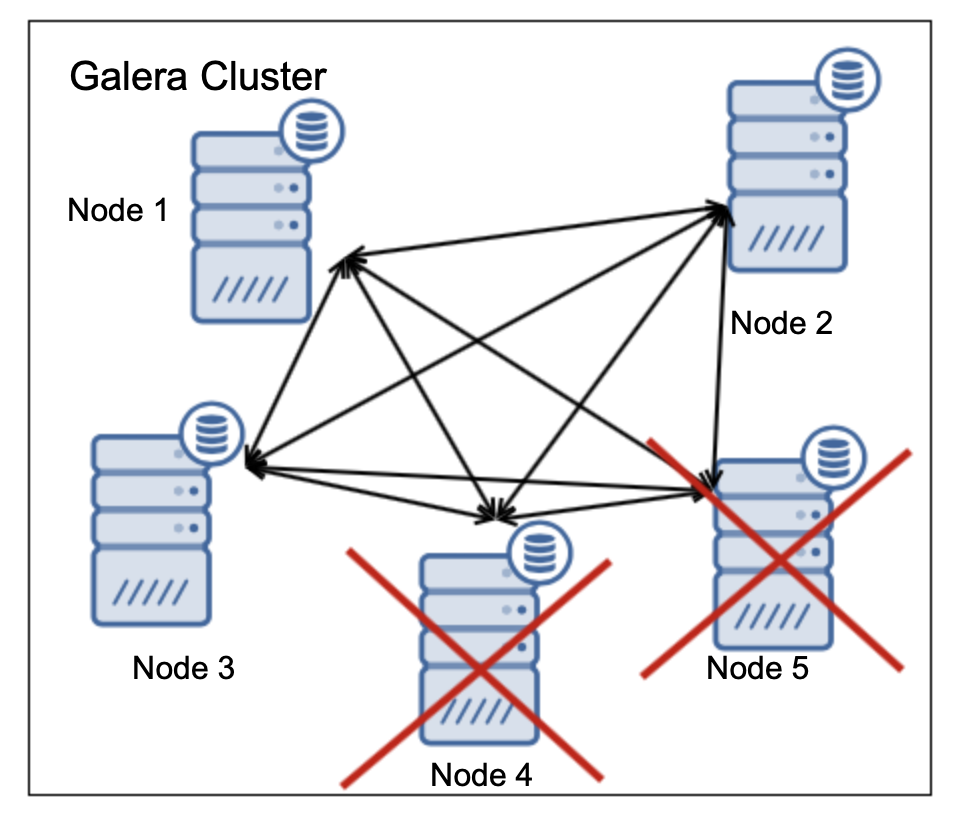
在上述两个节点处于关闭状态的情况下,剩下三个节点,这使其60%可用,因此达到了大多数节点并且群集可以运行。
综上所述,三个节点是允许一个节点发生故障的最小群集大小。群集应该有奇数个节点-这不是必须的,但是正如我们所看到的,将群集大小从三个增加到四个不会对高可用性产生任何影响-仍然只能同时允许一个故障。为了使群集更具弹性并同时支持两个节点故障,群集大小必须从三个增加到五个。如果要进一步提高群集处理故障的能力,则必须添加另外两个节点。
数据库节点故障对群集负载的影响
在上一节中,我们讨论了Galera Cluster中高可用性的基本数学原理。一个节点可以在三个节点的群集中关闭,而两个节点可以在五个节点的群集中关闭。这是Galera的基本要求。
您还必须牢记其他方面。我们现在将快速浏览它们。对于初学者来说,集群上的负载。
假设所有节点均创建为相等。相同的配置,相同的硬件,它们可以处理相同的负载。仅在一个节点上负载不会对三个节点群集(更不用说五个节点群集或更大)在成本上没有太大意义。您可以放心地期望,如果您投资三个或五个galera节点,则想利用所有这些节点。这非常容易-负载平衡器可以为您在所有Galera节点之间分配负载。您可以将写入发送到一个节点,并在集群中的所有节点之间平衡读取。这带来了您必须牢记的其他威胁。如果将一个节点从群集中取出,负载将如何?让我们看一下以下五节点群集的情况。
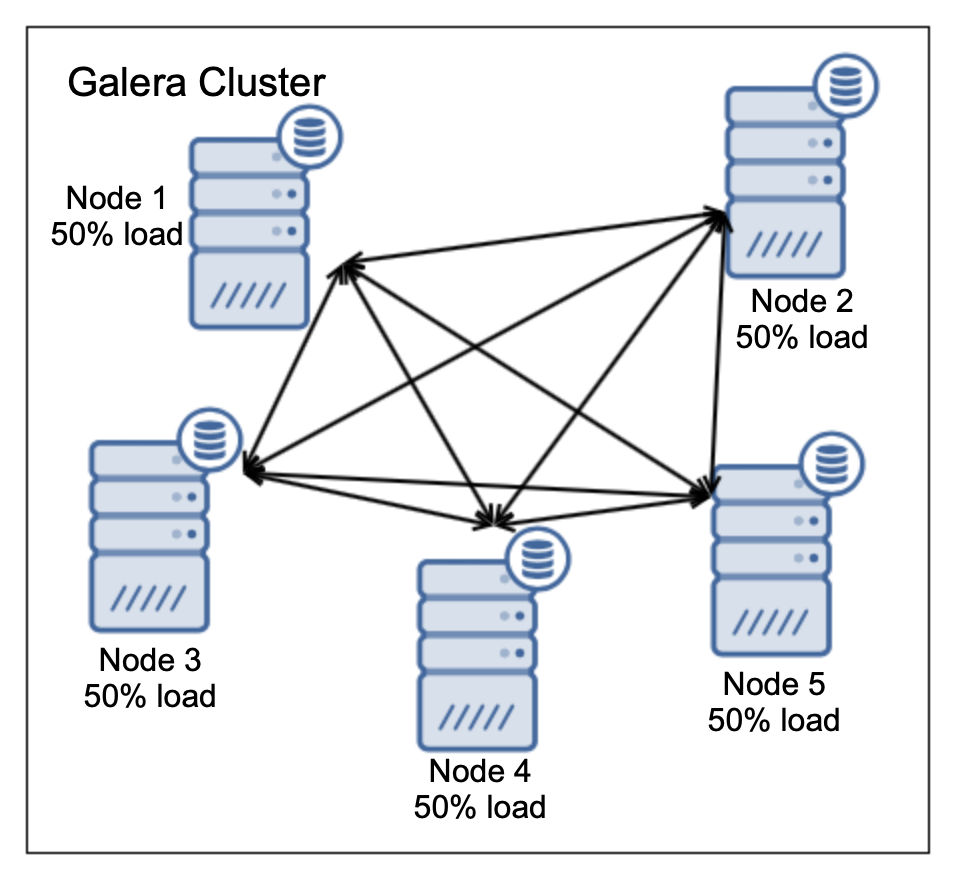
我们有五个节点,每个节点处理50%的负载。没关系,节点已被相当负载,但它们仍具有一定的能力来容纳工作负载中的意外峰值。正如我们所讨论的,这种集群最多可以处理两个节点故障。好的,让我们看看它是什么样的:
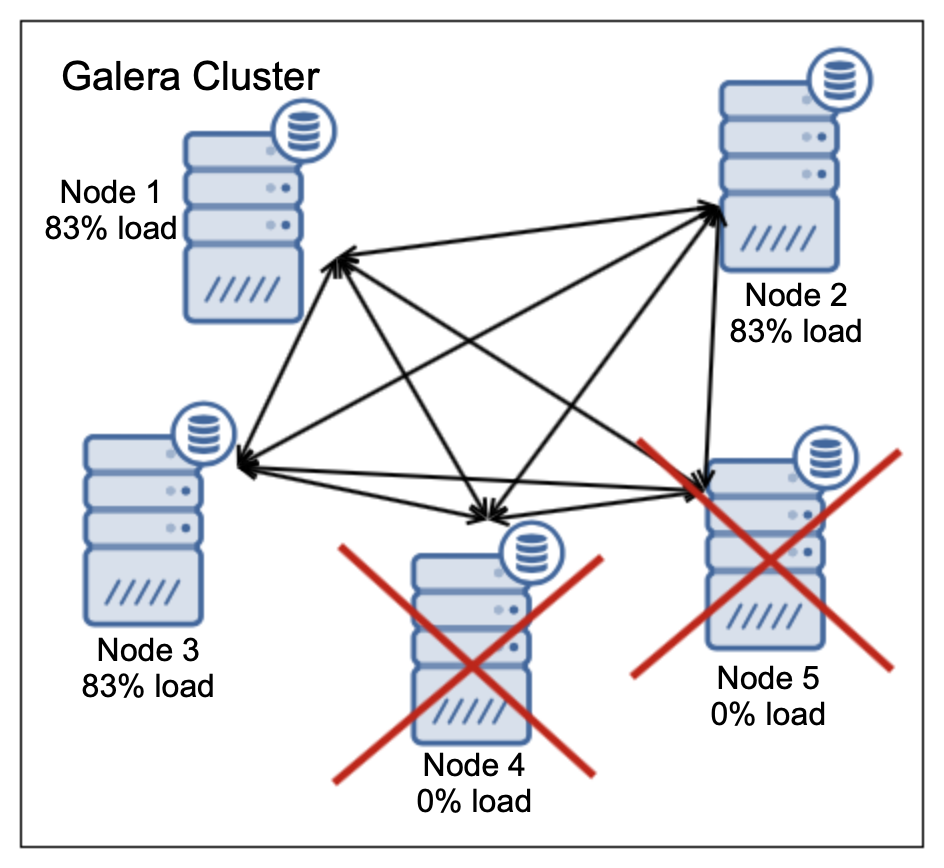
两个节点都关闭了,没关系。Galera可以处理。必须在其余三个节点之间重新分配100%的负载。这样一来,总共有250%的负载分布在三个节点上。结果,它们每个将以其容量的83%运行。这可能是可以接受的,但平均负载为83%,这意味着响应时间将增加,查询将花费更长的时间,并且工作负载的任何峰值很可能会引起严重的问题。
我们的五个节点集群(所有节点的利用率为50%)是否真的能够处理两个节点的故障?好吧,不是,不是。在崩溃之前,它绝对不会像集群那样出色。它可以生存,但是其可用性可能会因工作负载的临时峰值而受到严重影响。
您还必须记住一件事-必须重建故障节点。Galera具有内部机制,允许它配置崩溃后加入群集的节点。当其余节点之一在gcache中具有所需数据时,它可以是IST(增量状态传输)。否则,将必须进行完整的数据传输-所有数据将从一个节点(施主)传输到加入节点。该过程称为SST-状态快照传输。IST和SST都需要一些资源。必须从供体上的磁盘读取数据,然后通过网络进行传输。IST重量更轻,SST重得多,因为必须从供体上的磁盘读取所有数据。无论使用哪种方法,都会消耗一些额外的CPU周期。供体上17%的免费资源是否足以运行数据传输?这将取决于硬件。也许。也许不吧。无济于事的是,默认情况下,大多数代理都会从节点池中删除供体节点以向其发送流量。这很合理-处于“ Donor / Desync”状态的节点可能会落后于群集的其余部分。
当使用Galera(实际上是一个同步群集)时,我们不希望节点滞后。对于应用程序来说,这可能是一个严重的问题。另一方面,在我们的案例中,从节点池中删除施主以平衡工作负载可确保群集超负荷(250%的负载将仅分布在两个节点上,节点容量的125%是,超出了它的处理能力)。这将使群集绝对不可用。
结论
如您所见,群集中的高可用性不仅仅是仲裁计算的问题。您必须考虑其他因素,例如工作量,时间变化,处理状态转移。希望这篇文章可以帮助您理解,即使仅基于两个变量(节点数和节点容量)进行讨论,高可用性还是一个棘手的话题。了解这一点将帮助您使用Galera Cluster 设计更好,更可靠的HA环境。
