




Grafana是一个开源指标分析和可视化套件。 它最常用于可视化基础设施和应用程序分析的时间序列数据,但许多应用于其他领域。
Grafana通过提供插件形式的数据源(Data Sourse)和展示面板(Panel)可以完成许多有意思的图表或者流程展示。同时,管理员可以通过角色分配不同级别的权限,并且加以不同形式的内、外部的访问控制,可以组成有效的安全级别控制。
本文,单就不同数据源的展示和大家做下介绍。
仪表板
就可视化而言,仪表板(Dashboard)就是一切。
仪表板可以被认为是一组一个或多个面板的组织和排列成一个或多个行。
仪表板的时间段可以通过仪表板右上角的仪表板时间选择器进行控制。
仪表板可以利用模板来使它们更加动态和交互。
仪表板可以添加各式的外链,对展示的数据做其他维度的关联思考。
仪表板还有很多其他有意思的效果,这里就不一一举例。
仪表板涉及到的数据源:
以DataSource区分
zabbix监控数据、Elasticsearch数据源、InfluxDB数据源、部分通过API得到的第三方数据和Mysql数据源——Grafana4.6版本能够支持的数据源插件——尚在探讨适用范围。以数据阶段区分
原始数据(一手数据),对原始数据处理、过滤后的中间数据或者结果(二手数据)
关于仪表板的说明——
左上角

1) 侧面菜单切换:切换侧边菜单,令使用者专注于仪表板中显示的数据。信息中心下拉菜单:此下拉菜单显示当前正在查看的信息中心,并允许您轻松切换到新的信息中心。
2) 展板列表:下拉列表,展示所有权限允许查看的仪表板。
3) 星型仪表板:对当前仪表板执行星号(或取消星标)。加星标的信息中心在默认情况下会显示在您自己的主页信息中心上。
4) 共享仪表板:通过创建链接或创建其静态快照来共享当前仪表板。
5) 保存仪表板:当前仪表板将与当前仪表板名称一起保存。 6)设置:管理仪表板设置和功能,如模板和注释。
右上角

是关于选择时间的,很简单,这里不再赘言。
唱吧实践
一. 首页
由于是公司内部数据,抹掉了纵坐标具体数值,下同。
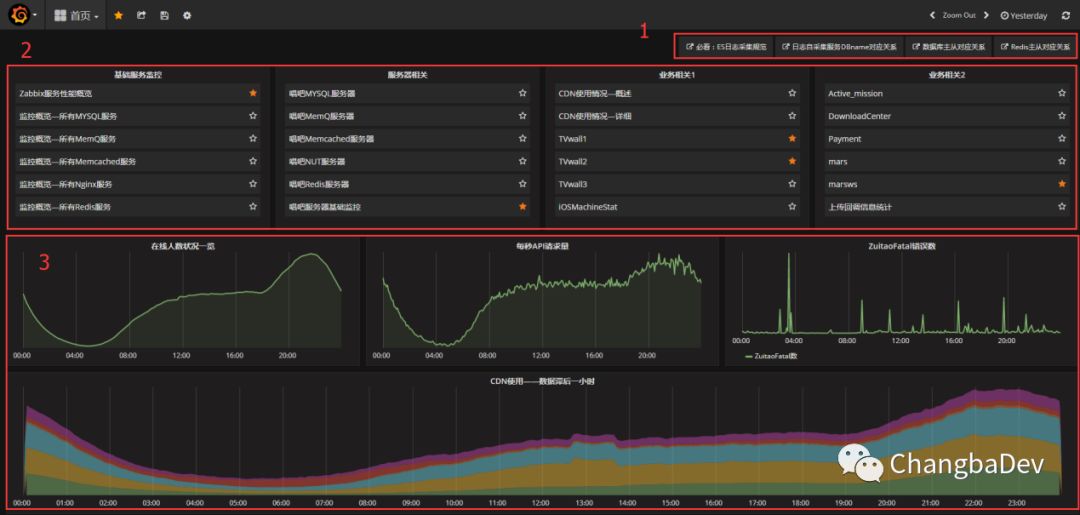
作为所有登录人员的默认登录页,分为3个区域:
外链区域——业务规范和数据关系参考
仪表板快链——各个维度常用的仪表板,为了便于截图,这里显示的是各个维度的前6名,实际上要更多,隐藏的也更多。
1) 基础服务监控:以服务分组作为维度,展示个类服务的数据概览,并提供具体实例和节点的状态外链,以便于做进一步分析。
2) 服务器相关:以服务实例或者服务器节点作为切分维度,并提供对应向上至服务组和向下所在主机和更细一步的所有监控项,以便对服务状态做向上和向下的深入分析和历史数据呈现
3) 业务相关1和业务相关2:具体的划分规则其实并未明确,目前的简单划分原则:长期业务展示和短期业务展示(活动类)、主产品业务和其他业务线业务
从很广域的方位,唱吧的几个线形图。
在线人数——后台统计;PV——来源于流式计算数据;错误统计:ES中的数据;CDN数据,通过第三方接口请求获得并存于zabbix监控中——后期考虑到存储及时序数据库中。 首页很是能够凸显grafana的特点——图文并茂,各个渠道的数据源集中展示。
二、Zabbix数据源展示举例——以MemcacheQ服务为例
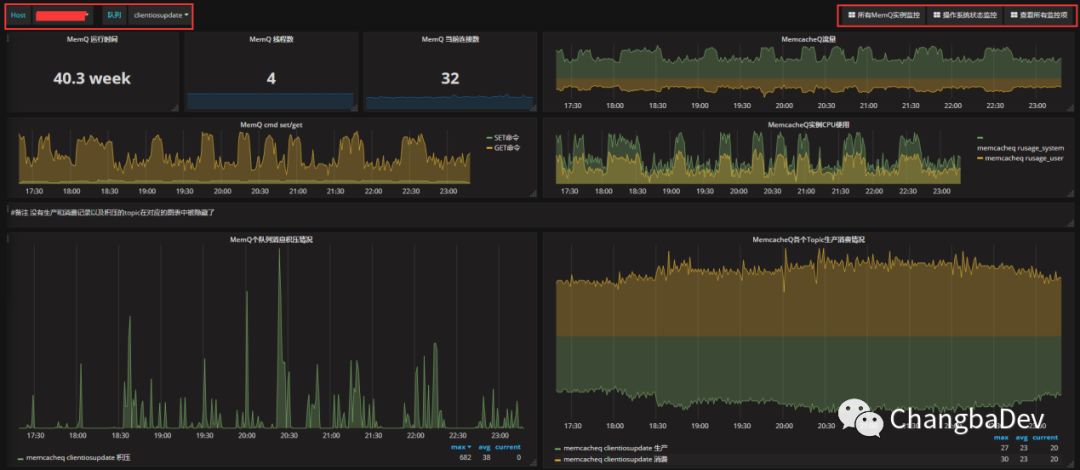
左上红框:
host:节点选择,单选。
队列:在该节点上发现的队列,可多选。
Zabbix的Templating的展示思维:group——Host——Application——items右上红框:
外链:所有实例状态、对应系统节点状态、采集但不存储于仪表板中的其他监控线。展示数据。 Panel使用如下:Graph(例如:积压情况和CPU使用)、Singlestat(例如:运行时间、当前连接数)和Text(备注)。
其中,graph中的流量和成产消费情况,为了便于识别,分别对进出流量、生产消费做了正负数的区分,从而使展示显得更加直观和可对比。
还比如redis的实例展示,大量的使用singlestat对从库的最新状态做了展示

三、ES数据展示——以CDN使用情况-详细为例:
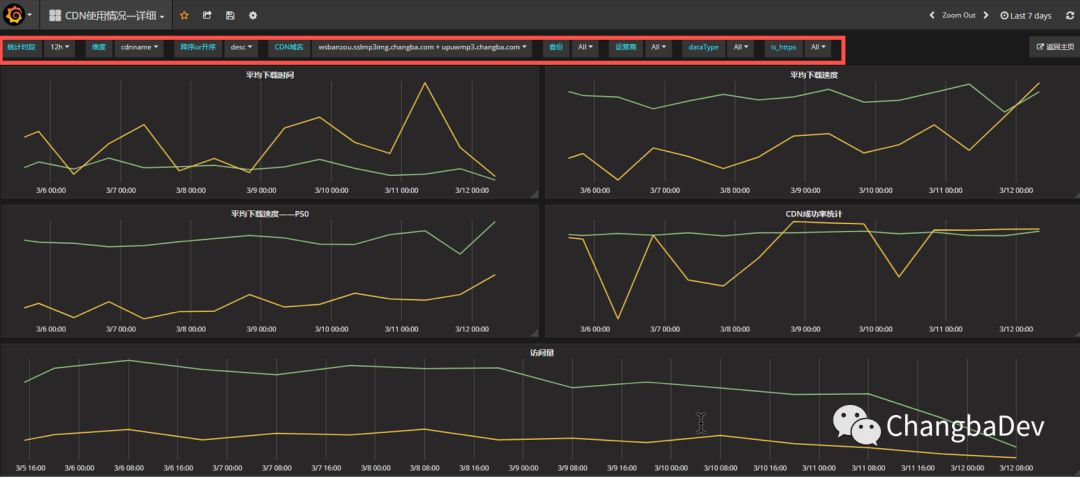
为了便于需求方查询,大量的采用的“模板”的概念,以便于从各个维度去查询数据。
统计时段:1m,10m,1h,12h,1d,时间颗粒度的划分。
维度:cdnname(域名),isp(服务商),geoip.region_name(用户地区)。即ES查询中terms划分的field name,类似于mysql中的group by keyname。
降序or升序:terms数据排序规则。
CDN域名、省份、运营商中数据对应维度的cdnname,isp,geoip.region_name 。当维度中选择后,terms数据就以对应选项中的数据划分buckets。
dataType:简单理解为上传或者下载。这个数据也有对应的field。
Is_https:这是名字起得懒了,应为访问类型——http或者https。
右上角孤零零的“返回主页”,为了提升用户体验——别乱找了。
同样的逻辑,也应用在了nginx访问原始日志上:
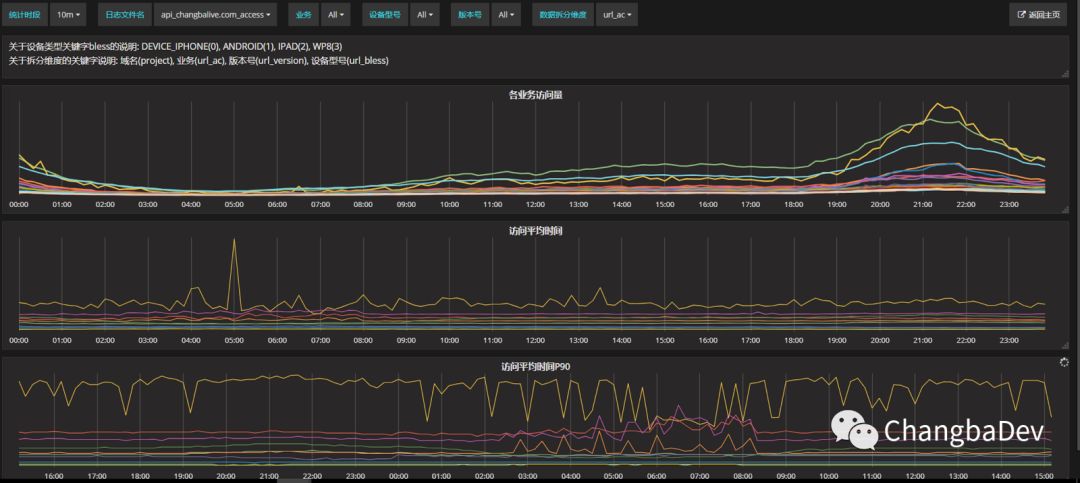
对应的templating的设计截图——
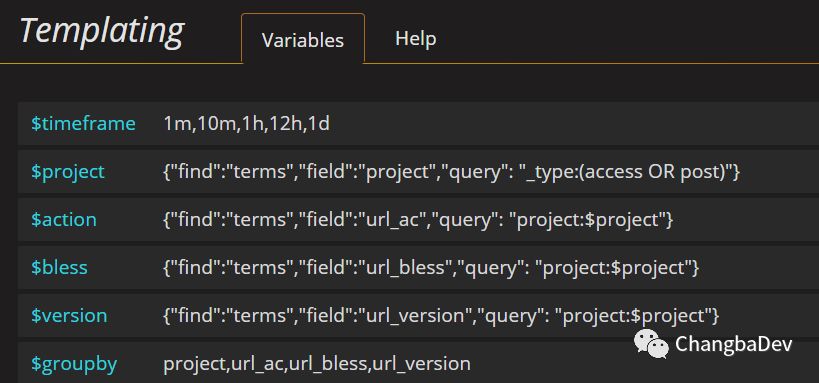
对应原始日志的统计数据:
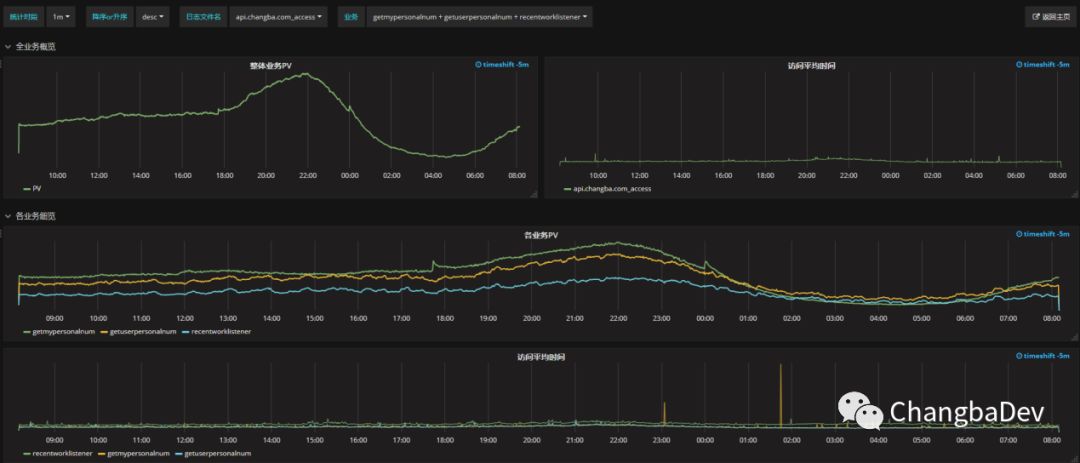
两者的区别就是统计的维度没有那么多了,只剩下了域名和业务的维度选择。
区别于流式处理,访问数据的统计是一种伪实时处理——为了避免数据积压的干扰,实际上统计的五分钟以前的数据。通过Elasticsearch的API接口针对不同域名的不同业务(ac)以每分钟为一个时段统计出对应的PV、UV、平均访问时间和percentile90的访问时间。这样,就把亿级的日访问数据压缩到了十万一级。好处就是可以快速浏览更长的时间轴——因为统计过后的数据查询量大概为原始数据的万分之一到万分之十之间,数据越多优势越大,对应的,也降低了活跃的永久数据的存储成本。对应的,为了便于灵活的查询,ES中业务记录一定周期的原始数据,以方便定制一些灵活的查询规则,同时也为了探索更好的统计维度。
最近遇到的大坑
背景:
log_collect项目的出现是为了针对不同的定制化日志的自动化采集,通过LogCollect方法定义的不同dbname存储到不同的index里面,日志内容为json格式。
最开始的想法的是通过dbname存储到不同的kafka的topic里面,以便于自动化采集,同时各个不同的topic可以作为不同程度的复用——被多个consumer使用。
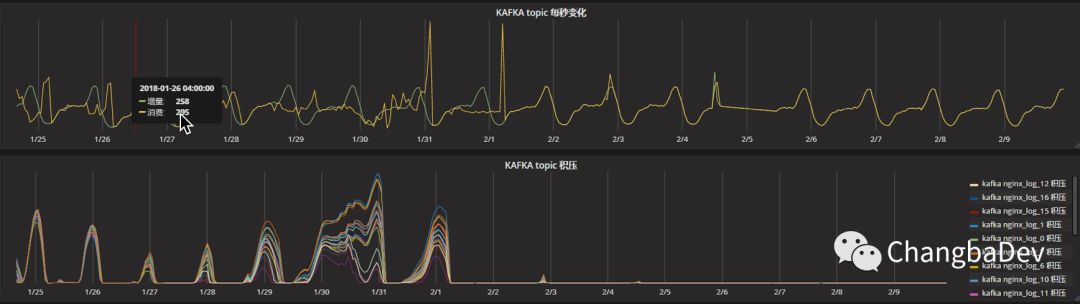
但是,随着dbname越来越多,不同的dbname之前的数据量差距越来越大,top3数量多的和top3数量少的会差几万倍,这样造成了kafka的topic资源的很大浪费,而且数据提交的效率也越来越低,不仅造成了大量的数据积压——不能及时的消费数据,而且还造成的大量的重复消费数据。下图是已经合并所有DBname的topic后log_collect每个 partition的积压量。
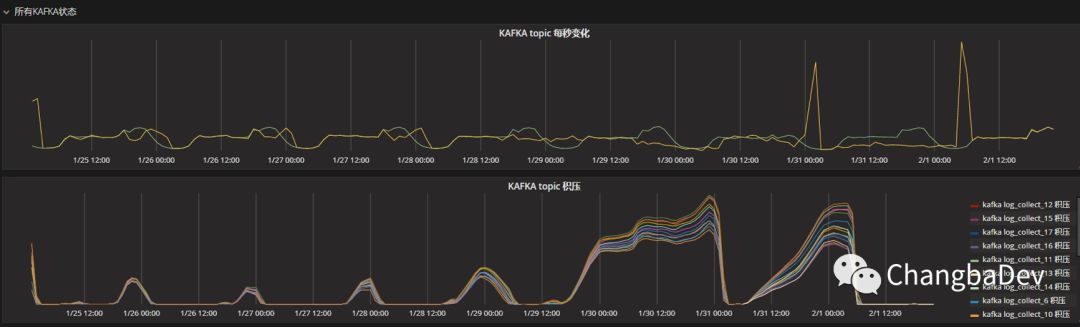
造成这一现象的原因是过多的小包请求直接打满了ES是集群的thread_pool的bulk的线程池,造成了数据阻塞,进而早打了每次bulk提交的相应时间,然后会有频繁的提交失败和拒绝。出问题期间 ,ES的对应接口情况:
| node_name | name | active | queue | rejected |
|---|---|---|---|---|
| changbaES-node-1 | bulk | 0 | 0 | 96237 |
| changbaES-node-2 | bulk | 0 | 0 | 3998 |
| changbaES-node-41 | bulk | 0 | 0 | 3141 |
| changbaES-node-43 | bulk | 0 | 0 | 1012 |
| changbaES-node-3 | bulk | 0 | 0 | 36796 |
| changbaES-node-45 | bulk | 16 | 714 | 4416 |
事后分析:
大量写入积压的原因:
设计bulk的目的是把很多条数据数据一次性提交给ES,从而节约建立请求的开销,进而提升效率。但是高频的请求所有dbname的数据在分流道各个index,其实是人为的把大包打散成小包传给ES——更准确的说是拆散成了或大或小的包,从而极大的增加了bulk接口的负载,以致间歇性奔溃。ES中大量重复数据的原因:
Kafka的consumer消费有两种常规状态,消费成功和不消费。消费成功了,offset(消费量)指针变化;不消费,offset不变,logsize变化,对应log(偏移量)增大。但是,还有一种少见的中间变化——消费了,但是没成功。造成的影响就是offset不变,同时被sonsumer反复请求,然后consumer消费后把数据提交给ES时有的数据提交成功了,有了则没有。这样就造成了ES中有很多重复的数据。从而扰乱了统计数据的准确性。
1) 解决上述两个问题的直接方法是:在kafka端,增大消费超时时间,调整offset变化策略,增大消费间隔;在提交数据的logstash端,增加提交的超时时间;在ES增加bulk线程池的参数,不修改bulk的并发参数是因为意义不大。然而,这种调整策略复杂、效果很差,本身的调整也不科学。
2) 我最后的做法是在kafka和 ES中间在增加一个更大更灵活的缓冲池——存到磁盘里。
具体的做法,就是已知的几个dbname的数据,从kafka中消费出来后直接提交到ES中;另外一部分数据则直接落在对应consumer所在的系统磁盘上。然后在对持久化到磁盘上的数据通过logstash的input-file和ouput-elasticsearch提交到ES中,同时在input-file中增加检查文件内容是否变化的参数stat_interval => 4(4秒,默认是1秒,可以根据情况在调整)。同时对本地化到磁盘上的数据做定时清。
使用如下方法后,效果如下:
| node_name | name | active | queue | rejected |
|---|---|---|---|---|
| changbaES-node-1 | bulk | 0 | 0 | 96237 |
| changbaES-node-2 | bulk | 0 | 0 | 3998 |
| changbaES-node-41 | bulk | 0 | 0 | 3141 |
| changbaES-node-43 | bulk | 0 | 0 | 1012 |
| changbaES-node-3 | bulk | 0 | 0 | 36796 |
| changbaES-node-45 | bulk | 2 | 0 | 4416 |
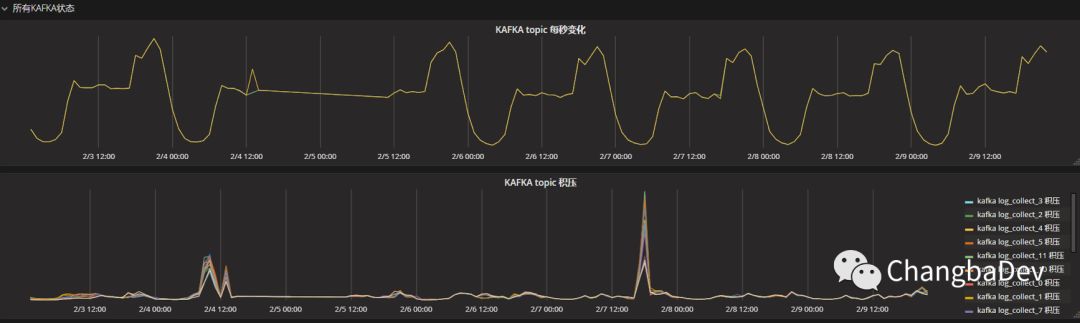
collect做到了实施消费,基本没有了积压,并且不再产生重复消费。同时ES的bulk的压力降低,其他项目的消费也得以正常进行。
如nginxlog,这个topic,也恢复正常了
作图大原则
抓取数据的目的是令业务更加健壮,展示的目的是令数据更加直观。多聆听,多交流,切实抓住用户的需求和痛点,才便于更有效的展示数据。
展望
随着持续推进和认可,内部用户越来越多了,更多的需求,更多量和类型的数据,更多的用户角色,对数据展示平台的易用性、稳定性和安全性带来了越来越多的要求,以及用户快速简单的自建仪表板也快成为了新需求。今后有机会和大家再多多分享这方面的做法。
