




最近碰到了这样一个场景:有应用需要基于我们封装好的Restful接口查询大量数据,并且需要在极低的响应时间内完成整个数据查询与传输流程。目前使用的Restful方式执行流程如下:
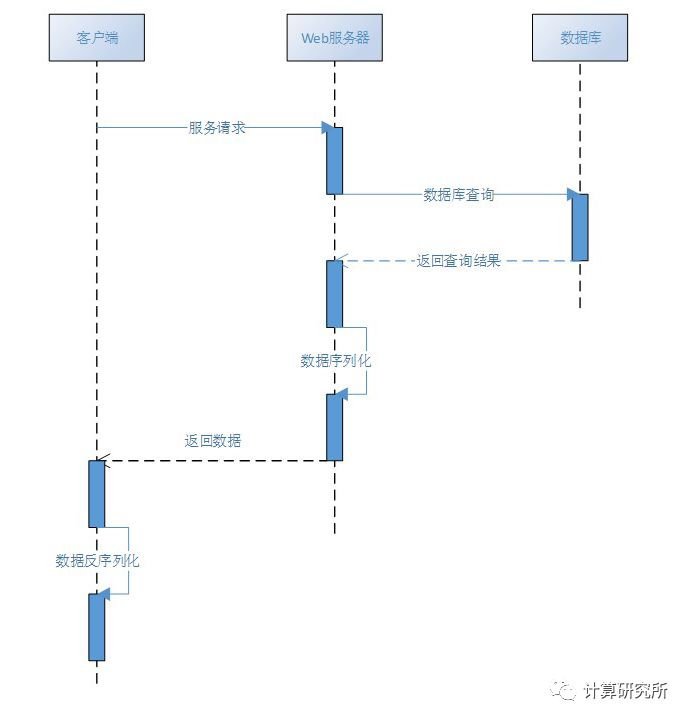
一个常见的REST数据请求调用过程
如上图,服务器收到客户端发出的REST资源请求后,查询后端数据库并将数据用JSON格式封装,并作为HTTP请求的响应(response)内容返回给客户端。在大部分场景下,REST请求的客户端一般是用户的浏览器,采用基于JS(JavaScript)的Ajax库发送REST查询请求,查询结果基于JSON格式返回给浏览器的最大好处是可无缝转换为JS对象供开发者直接调用,以提供更好的开发体验。
如果需要降低整个查询服务请求的时间消耗,分析请求流程的各个步骤后可以发现,有以下几个步骤可供优化:
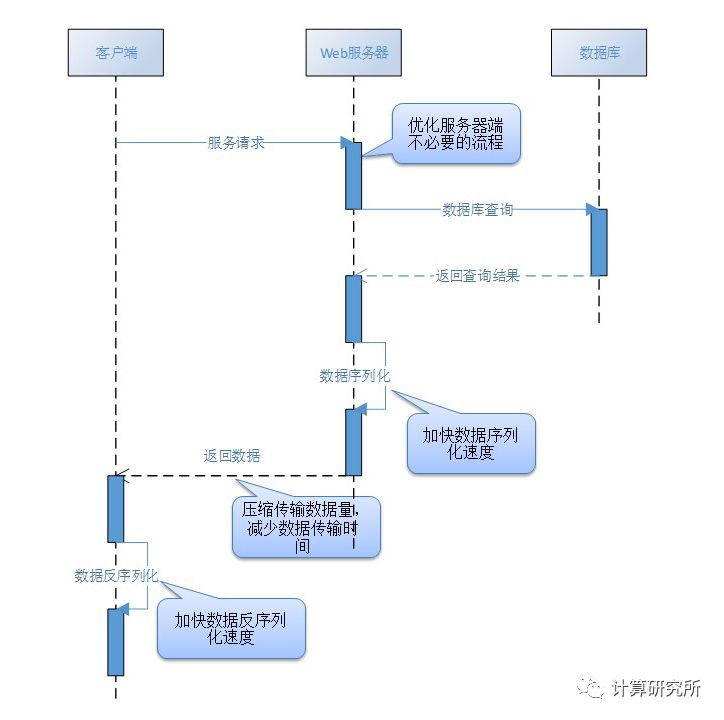
此次优化的目标是总体服务框架,故数据库查询性能优化不在此范围
在需要返回大量数据时,采用JSON格式封装也带来了一个不可避免的问题:封装处理时间长,未压缩的大量数据带来较大的网络传输时间。

一个JSON的例子,采用标签与括号层层封装数据
解决问题的思路有两个:
1、 摒弃Web API模式,开放数据库端口由应用直连,减少中间过程的时间消耗
2、 在优化整个服务框架流程的基础上,对REST请求的响应内容中采取更快的数据序列化算法,并对数据进行压缩以降低网络传输时间消耗
第一种思路将导致后端数据库直接暴露于外部网络,安全性得不到保证。第二种思路看起来是个更好的办法,那么接下来要考虑的就是优化以下两个步骤:数据序列化与数据压缩。
测试环境是台11年前的笔记本,Intel P8400 2.27GHz 双核CPU、6G内存
WEB服务采用Django框架搭建,详情参照:https://www.django.cn/
测试数据共26个字段,每行记录平均约210字节。
1、框架调用时间测试
在返回的消息体中直接返回空字符串,用于测试Django框架自身执行时间消耗
服务端处理代码:
def resp_msg(request):return HttpResponse('')
客户端采用python的requests库模拟浏览器请求,并计算查询时间
import requests as reqimport sysimport datetimedef t():return datetime.datetime.now()def fetch_msg():t0=t()req.get('http://127.0.0.1:8000/trans/msg')t1=t()print("[empty msg]: (%s)" %(t1-t0))
单并发测试结果显示,无数据传输返回时框架与网络平均响应时间约为16.5ms
2、JSON数据序列化性能
服务端序列化数据为JSON:
def resp_json(request):t0 = t()rows = get_data_rows(get_rownum(request))t1 = t()resp = HttpResponse(json.dumps(rows), content_type="application/json")t2 = t()print("get data: (%s), construct response: (%s)" %(t1-t0, t2-t1))return resp
测试结果如下:
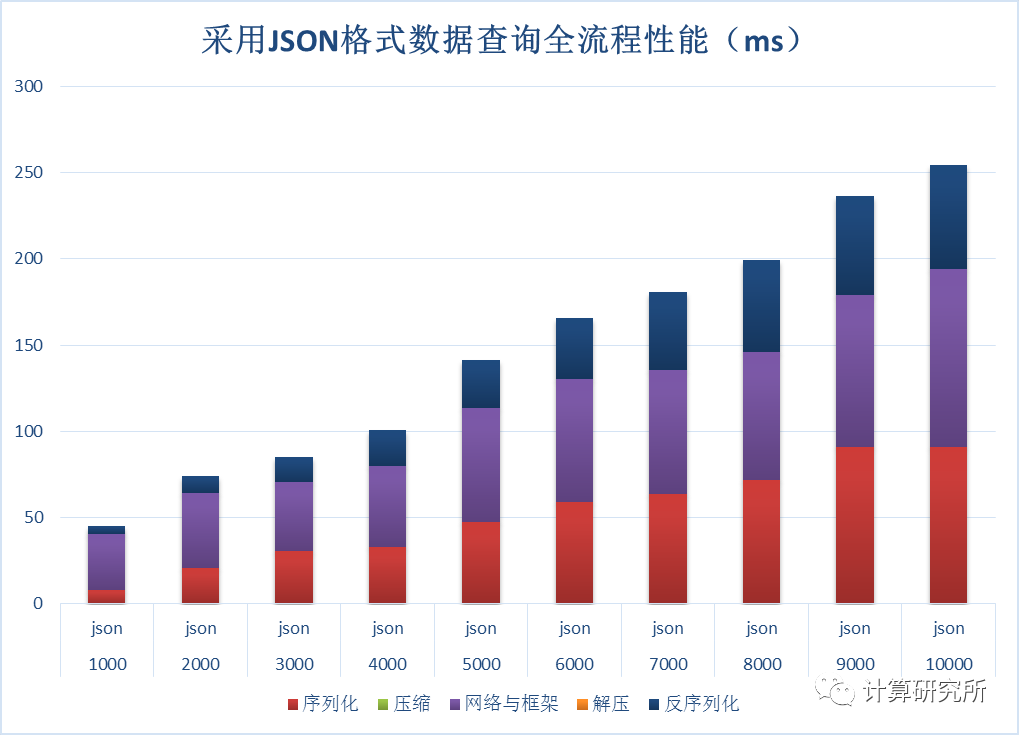
可以看出在数据量达到10000条记录(约2MB)时,整体查询时间接近250ms。数据序列化为JSON格式文本,网络传输,数据从JSON文本反序列化到内存三个步骤中,前两个步骤所占比重较大,也说明这里面应该还存在优化空间。
数据序列化
数据序列化的目的是为了将查询到的数据从内存对象转换为可用于存储或传输的字节序列,反序列化则是把字节序列恢复为对象的过程,比如JSON就是一种序列化算法,可以将各种语言的内存对象转换为可见的文本,同时也可以将JSON文本转换为各种语言的内存对象。
数据序列化与反序列化选择了msgpack和pickle两种算法,这两种算法有如下特点:
1、算法直接将对象序列化为二进制数据,速度更快、空间更省。
2、算法具有多种语言实现,可以实现异构语言平台之间的数据传输,仅GitHub上托管的代码,msgpack就有17种常见语言的实现[2],pickle也有十余种语言的支持。
数据压缩
常用压缩算法性能比较[1]
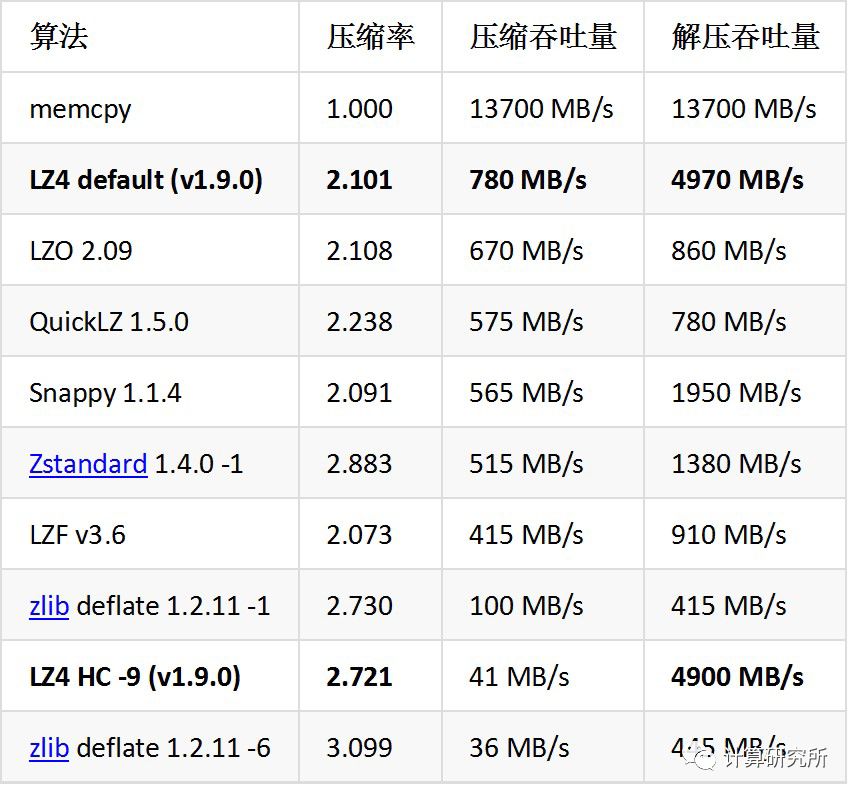
从上表中选择性能表现最好、业界应用也较多的LZ4和snappy算法,再加上最常用的zlib(gzip)算法作为对照,进行数据传输场景下的加压和解压吞吐量测试。
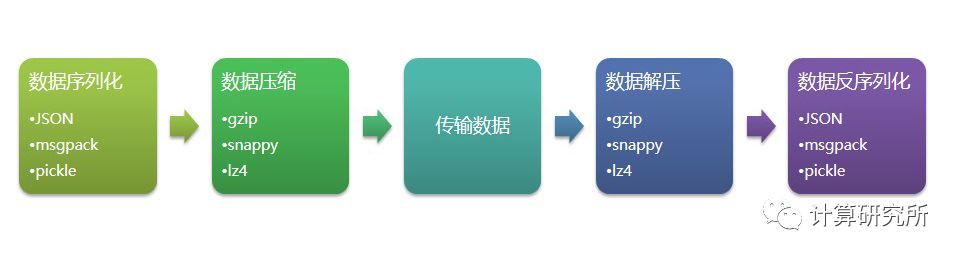
组合json/pickle/msgpack三种序列化算法与lz4/snappy/gzip三种算法,测试数据从1000条到10000条记录分10档递增。
测试代码如下:
import datetimeimport snappyimport pickleimport pickletoolsimport msgpackimport lz4.frameimport jsonimport gzipfrom data_factory import get_data_rowsdef t():return datetime.datetime.now()def pack_json(rows):return bytes(json.dumps(rows), encoding = 'utf8')def unpack_json(data):return json.loads(data)pack_func_set = {'json': [pack_json, unpack_json],'pickle': [pickle.dumps, pickle.loads],'msgpack': [msgpack.packb, msgpack.unpackb]}def gzip_1(rows):return gzip.compress(rows, compresslevel = 1)def gzip_5(rows):return gzip.compress(rows, compresslevel = 5)compress_func_set = {'snappy': [snappy.compress, snappy.decompress],'gzip_1': [gzip_1, gzip.decompress],'gzip_5': [gzip_5, gzip.decompress],'lz4': [lz4.frame.compress, lz4.frame.decompress]}def time_delta(dt):return dt.seconds * 1000 + dt.microseconds 1000for repeat in range(0, 1):for cnt in range(1, 11):rowcnt = cnt * 1000rows = get_data_rows(rowcnt)for pack_func in pack_func_set.keys():for comp_func in compress_func_set:t0 = t()data = pack_func_set[pack_func][0](rows)t1 = t()comp_data = compress_func_set[comp_func][0](data)t2 = t()uncomp_data = compress_func_set[comp_func][1](comp_data)t3 = t()pack_func_set[pack_func][1](uncomp_data)t4 = t()print("%s+%s,%d,%s,%s,%s,%s,%d" %(pack_func, comp_func, rowcnt,time_delta(t1-t0), time_delta(t2-t1), time_delta(t3-t2), time_delta(t4-t3), len(comp_data)))
测试结果数据如下:
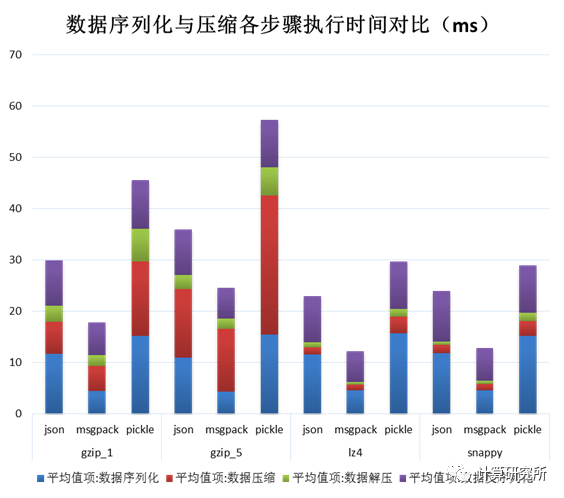
三种序列化算法与三种压缩算法千条记录平均压缩时间(其中gzip分别采用1级(最快)与5级(均衡)压缩率)
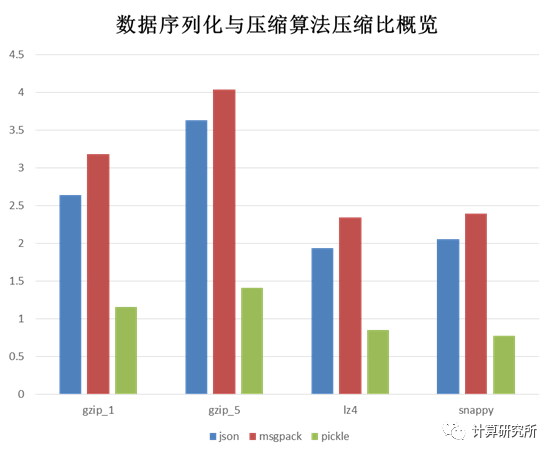
压缩比=原始记录字节数/序列化+压缩算法输出数据字节数,可以看出lz4和snappy在压缩比上没有太大差异
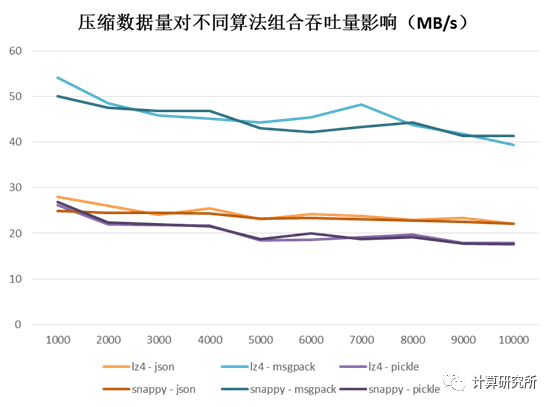
测试不同数据量对序列化与压缩算法吞吐量的影响,总体上吞吐量随着数据量加大略有下降,但并不明显
综合以上测试结果,可以认为lz4与snappy在我们的测试场景下各方面性能比较接近,msgpack算法相对pickle与json具有较大的优势。
接下来采用msgpack与lz4/snappy两种算法的组合进行WebAPI数据请求的全流程测试,并对比原有的JSON序列化算法
服务端代码如下:
def resp_snappy_msgpack(request):t0 = t()rows = get_data_rows(get_rownum(request))t1 = t()rows_bytes = msgpack.packb(rows, use_bin_type=True)t2 = t()rows_zip = snappy.compress(rows_bytes)t3 = t()resp = HttpResponse(rows_zip, content_type='application/octet-stream')t4 = t()print("snappy+msgpack,%d,%d,%d,%d,%d" % (get_rownum(request), time_delta(t1-t0), time_delta(t2-t1), time_delta(t3-t2), time_delta(t4-t3)))return respdef resp_lz4_msgpack(request):t0 = t()rows = get_data_rows(get_rownum(request))t1 = t()rows_bytes = msgpack.packb(rows, use_bin_type=True)t2 = t()rows_zip = lz4.frame.compress(rows_bytes)t3 = t()resp = HttpResponse(rows_zip, content_type='application/octet-stream')t4 = t()print("[resp_lz4_msgpack] get data: (%s), msgpack: (%s), snappy[(%d) -> (%d)|(%f)]: (%s), resp: (%s)" %(t1-t0, t2-t1, len(rows_bytes), len(rows_zip), len(rows_bytes) / len(rows_zip), t3-t2, t4-t3))return resp
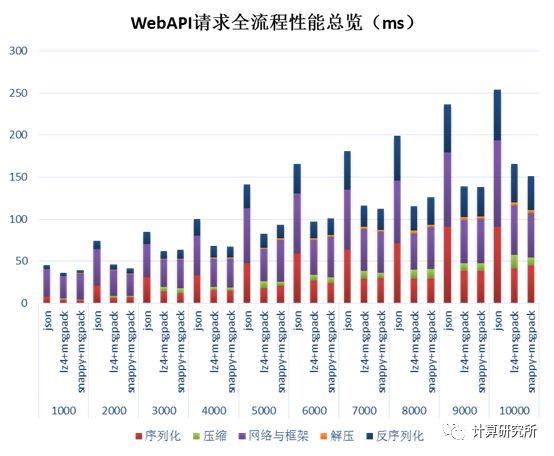
查询数据量从1000到10000条记录时,各流程执行时间情况
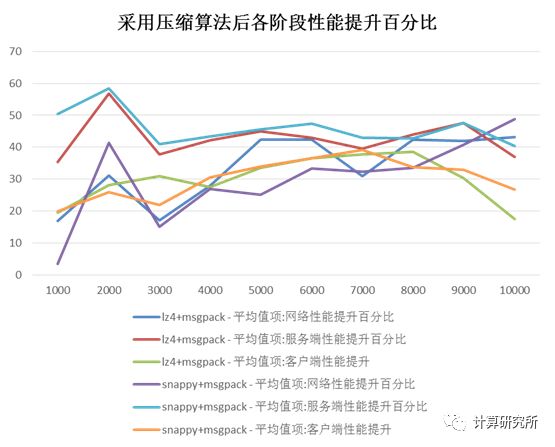
总结
1、基于整个服务请求的全流程测试结果,可以看到在这个需求场景下,采用lz4/snappy压缩与msgpack序列化算法平均可以获得30-40%的性能提升。
2、在经验上,对于数据库中的记录而言,以行为方向组织的数据压缩率要低于以列为方向组织的数据,但是如何将JDBC返回的以行方向组织的数据进行高效的行列转置是影响整体处理速度的关键,如果能够实现这一点,或许可以获得进一步的性能提升。
[1] https://github.com/lz4/lz4
[2] https://github.com/msgpack
