




Kafka安装
本文介绍如何使用Apache Kafka broker,包括如何搭建Apache Zookeeper, Kafka使用Zookeeper为代理存储元数据。还将涵盖Kafka部署的基本配置选项,以及选择运行broker硬件的一些建议。最后,介绍了如何安装多个Kafka代理作为单个集群的一部分,以及在生产环境中使用Kafka时应该注意的事项。
环境设置
在使用Apache Kafka之前,需要设置一些先决条件,以确保它正常运行。
选择操作系统
Apache Kafka是一个Java应用程序,可以在许多操作系统上运行。虽然Kafka能够运行在许多操作系统上,包括Windows, MacOS, Linux等,Linux是一般用例的推荐操作系统。本文的安装步骤将集中于在Linux环境中设置和使用Kafka。
安装Java
在安装Zookeeper或Kafka之前,需要一个Java环境设置和运行。Kafka和Zookeeper与所有基于OpenJDK的Java实现都能很好地工作,包括Oracle JDK。Kafka的最新版本同时支持Java 8和Java 11,本环境中安装JDK1.8:
[root@node03 ~]# java -versionjava version "1.8.0_221"Java(TM) SE Runtime Environment (build 1.8.0_221-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.221-b11, mixed mode)
安装Zookeeper
Apache Kafka使用Apache Zookeeper来存储Kafka集群的元数据,以及客户端的详细信息,如图1所示。Zookeeper是一种集中服务,提供配置信息维护、命名、分布式同步、组服务等功能。虽然可以使用Kafka发行版中包含的脚本运行Zookeeper服务器,但从发行版中安装完整版本的Zookeeper是很简单的。
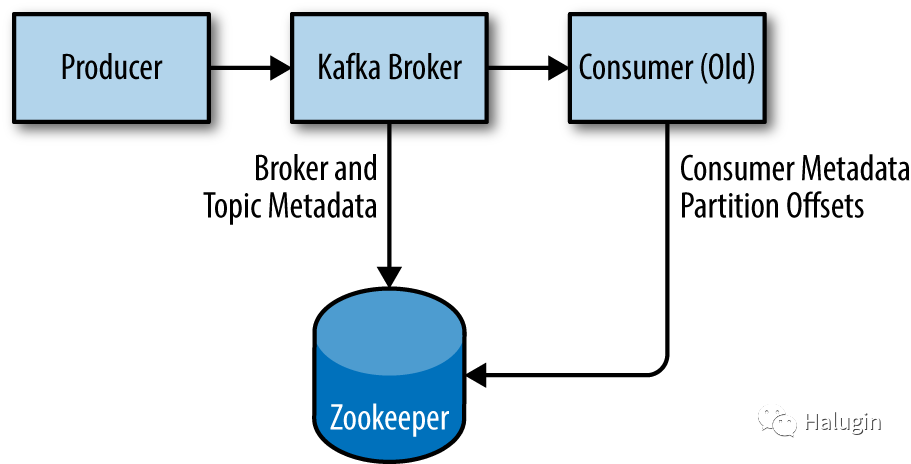
本文使用Zookeeper 3.5.9。
Standalone Server
Zookeeper自带了一个基本的配置示例文件,在/usr/local/zookeeper/config/zoo_sample.cfg
中大多数情况下都可以很好地工作。下面的例子安装Zookeeper的基本配置在/usr/local/zookeeper
中,数据存储在/var/lib/zookeeper
中:
[root@node01 opt]# tar -zxvf apache-zookeeper-3.5.9-bin.tar.gz [root@node01 opt]# mv apache-zookeeper-3.5.9-bin usr/local/zookeeper[root@node01 opt]# mkdir -p /var/lib/zookeeper[root@node01 opt]# cat /usr/local/zookeeper/conf/zoo.cfg tickTime=2000initLimit=10syncLimit=5dataDir=/var/lib/zookeeper clientPort=2181[root@node01 opt]# /usr/local/zookeeper/bin/zkServer.sh startZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED
现在可以通过连接到客户端端口并发送命令srvr
来验证Zookeeper是否在standalone模式下正确运行。这会从正在运行的服务器返回基本的Zookeeper信息:
[root@node01 opt]# telnet localhost 2181Trying ::1... Connected to localhost. Escape character is '^]'. srvr Zookeeper version: 3.5.9-83df9301aa5c2a5d284a9940177808c01bc35cef, built on 01/06/2021 19:49 GMT Latency min/avg/max: 0/0/0Received: 1Sent: 0Connections: 1Outstanding: 0Zxid: 0x0 Mode: standalone Node count: 5Connection closed by foreign host.
Zookeeper ensemble
Zookeeper被设计成一个集群,称为一个整体,以确保高可用性。由于使用平衡算法,建议集成包含奇数个服务器(例如,3、5等),因为大多数集成成员(quorum)必须工作,以便Zookeeper响应请求。这意味着在三个节点的集成中,可以在缺少一个节点的情况下运行。对于五节点集成,可以在缺少两个节点的情况下运行。
要在一个集合中配置Zookeeper服务器,它们必须具有一个列出所有服务器的公共配置,并且每个服务器都需要在data目录中指定服务器ID号的myid文件。如果集合中服务器的主机名是zoo1.example.com、zoo2.example.com和zoo3.example.com,配置文件如下所示:
tickTime=2000dataDir=/var/lib/zookeeper clientPort=2181initLimit=20syncLimit=5server.1=zoo1.example.com:2888:3888server.2=zoo2.example.com:2888:3888server.3=zoo3.example.com:2888:3888
在这个配置中,initLimit
是允许follower与leader连接的时间。syncliit
值限制了跟随者与leader不同步的程度。这两个值都是一些tickTime
单位,这使得initLimit
为20 * 2000毫秒,即40秒。配置还列出了集成中的每个服务器,格式为:server.X=hostname:peerPort:leaderPort
:
X
服务器的ID号。这必须是一个整数,但它不需要是基于零或顺序的。
hostname
服务器的主机名或IP地址。
peerPort
集合中的服务器之间通过其通信的TCP端口。
leaderPort
进行leader选举的TCP端口。
客户端只需要能够通过clientPort连接到集群,但是集群的成员必须能够通过所有三个端口相互通信。
除了共享配置文件外,每个服务器必须在dataDir
目录中有一个名为myid
的文件。此文件必须包含服务器的ID号,该ID号必须与配置文件匹配。完成这些步骤后,服务器将启动并在一个集群中彼此通信。
安装kafka
配置好Java和Zookeeper后,就可以开始安装Apache Kafka了。本文中的示例使用的是2.7.0版本。
下面的例子安装Kafka在/usr/local/ Kafka
中,配置为使用之前启动的Zookeeper服务器,并存储消息日志段存储在/tmp/ Kafka -logs
中:
[root@node01 opt]# tar -zxf kafka_2.13-2.7.0.tgz [root@node01 opt]# mv kafka_2.13-2.7.0 /usr/local/kafka[root@node01 opt]# mkdir /tmp/kafka-logs[root@node01 opt]# /usr/local/kafka/bin/kafka-server-start.sh -daemon[root@node01 opt]# /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
一旦Kafka broker启动,可以通过对集群执行一些简单的操作来验证它是否工作,创建一个测试主题,生成一些消息,并消费相同的消息。
创建并验证主题:
[root@node01 opt]# /usr/local/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --replication-factor 1 --partitions 1 --topic testCreated topic test. [root@node01 opt]# /usr/local/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic testTopic: test PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824 Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
生成消息到测试主题(使用Ctrl-C
在任何时候停止生产者):
[root@node01 opt]# /usr/local/kafka/bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic testTest Message 1>Test Message 2> >
使用来自测试主题的消息:
[root@node01 opt]# /usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginningest Message 1Test Message 2^CProcessed a total of 4 messages
Broker配置
Kafka发行版提供的示例配置足以运行一个独立服务器作为概念验证,但对于大型安装来说不够。Kafka有许多配置选项,它们控制着设置和调优的所有方面。大多数选项可以保留默认设置,因为它们处理Kafka broker的调优方面,除非你有一个特定的用例需要调整这些设置,否则是不适用的。
General Broker
当在一台服务器上部署Kafka以外的任何环境时,有几个代理配置参数应该被审查。这些参数处理代理的基本配置,为了在与其他代理一起的集群中正常运行,必须对其中大多数参数进行更改。
broker.id
每个Kafka broker必须有一个整数标识符,它是通过broker.id
配置。默认情况下,这个整数被设置为0,但它可以是任何值。对于单个Kafka集群中的每个broker来说,这个整数必须是唯一的。这个数字是技术上任意的选择,它可以移动broker之间如果有必要维护任务,但是强烈建议将此值设置为某些内在的主机,这样在执行维护不繁重的代理身份号码映射到主机。例如,如果你的主机名包含一个唯一的数字(如host1.example.com
、host2.example.com
等),那么1
和2
将是broker.id
最好的选择值。
listeners
旧版本的Kafka使用了一个简单的port
配置。这仍然可以作为简单配置的备份,但已弃用配置。示例配置文件在TCP端口9092上启动Kafka。新的listeners
配置是一个逗号分隔的uri列表,我们用侦听器名称监听这些uri。如果监听器名称不是一个通用的安全协议,那么还必须配置另一个listener.security.protocol.map
。监听器定义为:
zookeeper.connect
用于存储代理元数据的Zookeeper的位置是使用zookeeper.connect
配置参数。本例配置使用运行在本地主机端口2181上的Zookeeper,该端口指定为localhost:2181
。该参数的格式为以分号分隔的hostname:port/path
字符串列表,其中包括:
hostname
,Zookeeper服务器的主机名或IP地址。port
,服务器的客户端端口号。/path
,一个可选的Zookeeper路径,用来作为Kafka集群的chroot环境。如果省略,则使用根路径。
如果指定了chroot路径(指定作为给定应用程序的根目录的路径),并且该路径不存在,则broker将在启动时创建该路径。
log.dirs
Kafka将所有消息保存到磁盘,这些日志段存储在日志中指定的log.dir
配置。对于多个目录,配置log.dirs
。如果未设置此值,则默认返回log.dir
。log.dirs
是本地系统上以逗号分隔的路径列表。如果指定了多个路径,代理将以“最少使用”的方式在它们上存储分区,其中一个分区的日志段存储在同一路径中。注意,代理将新分区放置在当前存储分区数量最少的路径中,而不是使用的磁盘空间最少的路径中,因此不能保证数据跨多个目录的均匀分布。
num.recovery.threads.per.data.dir
Kafka使用一个可配置的线程池来处理日志段。目前,使用这个线程池:
- 正常启动时,打开每个分区的日志段
- 在失败后启动时,检查并截断每个分区的日志段
- 关闭时,彻底关闭日志段
默认情况下,每个日志目录只使用一个线程。由于这些线程只在启动和关闭期间使用,所以为了并行化操作,设置更大数量的线程是合理的。具体来说,当从不干净的关闭中恢复时,这可能意味着重新启动一个具有大量分区的代理需要几个小时,在设置此参数时,请记住所配置的数字是由log.dirs
指定的每个日志目录。这意味着如果num.recovery.threads.per.data.dir
设置为8,并且在log.dirs
中指定了3个路径,总共有24个线程。
auto.create.topics.enable
Kafka的默认配置指定了代理应该在以下情况下自动创建主题:
- 当生产者开始向主题写入消息时
- 当使用者开始从主题读取消息时
- 当任何客户端请求主题的元数据时
在许多情况下,这可能是不受欢迎的行为,特别是当没有办法通过Kafka协议验证主题的存在而不导致它被创建。如果你显式地管理主题创建,无论是手动还是通过配置系统,都可以将auto.create.topics.enable
配置设置为false
。
auto.leader.rebalance.enable
为了确保Kafka集群不会因为在一个broker上有所有的topic leader而变得不平衡,这个配置可以被指定来确保尽可能多的leader是平衡的。它允许一个后台线程定期检查分区的分布(这个间隔可以通过leader. balance.check.interval.seconds
进行配置)。如果leader的不平衡超过了另一个配置leader. balance.per.broker.percentage
,那么将启动分区首选leader的重新平衡。
delete.topic.enable
根据环境和数据保留方案,你可能希望锁定集群,以防止任意删除主题。可以通过将此标志设置为false
来设置禁用主题删除。
Topic配置
Kafka服务器配置为创建的主题指定了许多默认配置。其中一些参数,包括分区计数和消息保留,可以使用管理工具对每个主题进行设置。服务器配置中的默认值应该设置为适合集群中的大多数主题的基线值。
num.partitions
num.partitions
参数决定使用多少个分区创建一个新主题,主要是在启用主题创建时(这是默认设置)。该参数默认为一个分区。一个主题的分区数量只能增加,而不能减少。这意味着如果一个主题需要比num.partitions
更少的分区,那么需要小心手动创建主题。
分区是Kafka集群中一个主题被扩展的方式,这使得在添加brokers时使用分区计数来平衡整个集群的消息负载变得很重要。许多用户将使一个主题的分区计数等于或等于集群中代理的数量的倍数。这允许分区均匀地分布到brokers,brokers将均匀地分布消息负载。例如,一个Kafka集群中有10个分区,有10台主机,leader在所有10台主机中平衡,这个主题将拥有最优的吞吐量。然而,这并不是必需的,因为还可以通过其他方式平衡消息负载,比如拥有多个主题。
在选择分区数量时,有几个因素需要考虑:
- 希望这个主题的吞吐量是多少?例如,希望每秒写入100kb还是1gb ?
- 当使用单个分区时,期望达到的最大吞吐量是多少?分区总是完全由单个消费者使用(即使不使用消费者组,消费者也必须读取分区中的所有消息)。如果知道较慢的用户向数据库写入数据,而该数据库在每个线程向其写入数据时的处理速度从不超过每秒50 MB,那么就知道从分区使用数据时的吞吐量被限制为每秒50 MB。
- 可以通过相同的练习来估计单个分区的每个生产者的最大吞吐量,但由于生产者通常比消费者快得多,因此跳过这一步通常是安全的。
- 如果正在根据键向分区发送消息,那么稍后添加分区可能非常困难,因此根据预期的未来使用情况而不是当前使用情况来计算吞吐量。
- 考虑将在每个代理上放置的分区数量以及每个代理的可用磁盘空间和网络带宽。
避免过高估计,因为每个分区都会使用代理上的内存和其他资源,并且会增加元数据更新和领导转移的时间。 - 如果正在使用云服务,虚拟机或磁盘是否有IOPS限制?根据云服务和VM配置,允许的IOPS数量可能会有硬上限,这将导致达到配额。过多的分区可能会带来副作用,即由于涉及的并行性而增加IOPS。
default.replication.factor
如果启用了自动主题创建,则此配置将设置新主题的复制因子。
强烈建议将复制因子设置为至少比min.insync.replicas
设置高1。如果有足够大的集群和足够多的硬件,要获得更多的抗故障设置,最好将复制因子设置为比min.insync.replicas
(简称RF++)高2。RF++将使维护更容易,并防止停机。这个建议背后的原因是允许副本集中同时发生一个计划内的停机和一个计划外停机。对于一个典型的集群,这意味着每个分区至少有3个副本。举个例子,如果在Kafka或底层操作系统的滚动部署或升级期间,出现了网络交换机中断、磁盘故障或其他计划外的问题,你可以确信仍然会有一个额外的副本可用。
log.retention.ms
Kafka将保留多长时间消息的最常见配置是时间。默认值是在配置文件中使用log.retention.hours
参数指定的,设置为168小时,即一周。但是,允许使用其他两个参数:log.retention.minutes
和log.retention.ms
。这三个参数都控制着相同的目标(消息被删除的时间),但是推荐使用log.retention.ms
,因为如果指定了多个单位,则较小的单位将优先。这将确保为log.retention.ms
设置的值始终是使用的值。如果指定了多个,则较小的单元大小将优先。
log.retention.bytes
过期消息的另一种方法是基于保留消息的总字节数。这个值是使用log.retention.bytes
参数设置的,并应用于每个分区。这意味着如果有一个包含8个分区的主题,并且log.retention.bytes
被设置为1 GB,则该主题保留的数据量最多为8gb。注意,所有保留都是针对单个分区执行的,而不是主题。这意味着如果一个主题的分区数量被扩展,如果使用log.retention.bytes
,保留率也会增加。将该值设置为-1
将允许无限保留。
log.segment.bytes
前面提到的日志保留设置操作日志段,而不是单独的消息。当消息被生成到Kafka broker时,它们被附加到当前分区的日志段中。一旦日志段达到log.segment.bytes
参数指定的大小(默认为1gb),日志段将关闭,并打开一个新的日志段。一旦日志段被关闭,就可以考虑它是否过期。较小的日志段意味着必须更频繁地关闭和分配文件,这降低了磁盘写的总体效率。
如果主题产生率较低,调整日志段的大小可能很重要。例如,如果一个主题每天只接收100兆字节的消息,并且log.segment.bytes
被设置为默认值,那么它将需要10天来填充一个段。由于消息在日志段关闭之前是不会过期的,如果log.retention.ms
设置为604800000(1周),那么实际上会有多达17天的消息保留,直到关闭的日志段过期。这是因为,一旦日志段以当前10天的消息关闭,根据时间策略,该日志段必须保留7天,才能过期(因为只有当该段中的最后一条消息过期时,该段才能被删除)。
log.segment.ms
另一种控制何时关闭日志段的方法是使用log.segment.ms
参数,该参数指定关闭日志段的时间。与log.retention.bytes
和log.retention.ms
参数一样,log.segment.bytes
和log.segment.ms
不是互斥的属性。Kafka会在达到大小限制或时间限制时关闭一个日志段,以先到的为准。缺省情况下,没有log.segment.ms
配置,这只导致按大小关闭日志段。
min.insync.replicas
当为数据持久性配置集群时,将min.insync.replicas
设置为2可以确保至少有两个副本被捕获并与生产者“同步”。这是与设置生产者配置ack“all”请求一起使用的。这将确保至少有两个副本(leader和另一个副本)acks
写操作,以确保写操作成功。当leader写入失败,leader被转移到没有成功写入的副本时,这可以防止数据丢失。如果没有这些持久的设置,生产者就会认为他们成功地生成了消息,而消息就会掉到地上而丢失。然而,由于涉及额外的开销,为更高的持久性配置的副作用是效率较低,因此,对于偶尔丢失消息的高吞吐量集群,不一定建议使用这种配置。
message.max.bytes
Kafka broker限制消息的最大大小,由message.max.bytes
参数配置,默认为1000000,或1 MB。生产者试图发送消息比这将会收到一个错误从代理,和消息将不被接受。与代理上指定的所有字节大小一样,该配置处理的是压缩消息大小,这意味着生产者可以发送比未压缩的消息大得多的消息,只要它们压缩到配置的message.max.bytes
大小之下。
增加允许的消息大小会带来明显的性能影响。较大的消息意味着处理网络连接和请求的代理线程将在每个请求上工作更长的时间。较大的消息还会增加磁盘写的大小,这将影响I/O吞吐量。其他存储解决方案,如blob存储和/或分层存储可能是解决大磁盘写问题的另一种方法。
硬件选择(Hardware Selection)
Kafka本身对特定的硬件配置没有严格的要求,并且在大多数系统上运行都没有问题。然而,一旦性能成为一个问题,有几个因素可能导致整体性能瓶颈:磁盘吞吐量和容量、内存、网络和CPU。当Kafka扩展到非常大的时候,由于需要更新的元数据的数量,单个broker可以处理的分区数量也会受到限制。一旦确定了哪种类型的性能对环境最关键,就能够选择适合你的预算的优化硬件配置。
磁盘吞吐量
用于存储日志段的broker磁盘的吞吐量将最直接地影响生产者客户端的性能。Kafka消息在生成时必须提交到本地存储,大多数客户端会等待,直到至少一个broker确认消息已经提交,才会考虑发送成功。这意味着更快的磁盘写入将等于更低的生成延迟。
当涉及到磁盘吞吐量时,一个显而易见的决定是使用传统旋转硬盘驱动器(HDD)还是固态硬盘(SSD)。ssd具有极低的寻道和访问时间,并将提供最佳性能。另一方面,hdd更经济,提供更多的单位容量。还可以通过在broker中使用更多的hdd来提高性能,无论是通过拥有多个数据目录,还是通过在独立磁盘冗余阵列(RAID)配置中设置驱动器。其他因素,如特定的驱动器技术(例如,串行连接存储或串行ATA),以及驱动器控制器的质量,将影响吞吐量。对于存储需求非常高的集群,硬盘驱动器通常更有用,但访问频率不高,而如果有大量客户端连接,ssd则是更好的选择。
磁盘容量
容量是存储讨论的另一方面,所需的磁盘容量取决于在任何时候需要保留多少消息。如果代理预计每天接收1tb的流量,并有7天的保留时间,那么代理将需要至少7tb的可用存储空间用于日志段。除了希望为流量波动或随时间增长而保持的任何缓冲区之外,还应该考虑到其他文件的至少10%的开销。
存储容量是决定Kafka集群大小和扩展的因素之一。通过为每个主题拥有多个分区,集群的总流量可以在整个集群之间实现平衡,如果单个代理上的密度不足以满足要求,则允许额外的broker来增加可用容量。需要多少磁盘容量的决定还取决于为集群选择的复制策略。
内存
Kafka消费者的正常操作模式是从分区的末端读取数据。消费者正在读取的消息被最佳地存储在系统的页面缓存中,这使得读取速度比broker从磁盘重新读取消息更快。因此,为系统提供更多用于页面缓存的内存将提高客户端的性能。
Kafka本身并不需要为Java虚拟机(JVM)配置很多堆内存。即使是每秒处理150000条消息和200mb/s的数据速率的代理也可以在5gb堆中运行。剩余的系统内存将被页面缓存使用,并允许系统缓存使用中的日志段,这将使Kafka受益。这就是不推荐Kafka和其他重要应用放在一个系统上的主要原因,因为它们必须共享页面缓存的使用。这将降低Kafka的消费者性能。
Networking
可用网络吞吐量将指定Kafka可以处理的最大流量。这可以与磁盘存储一起成为集群规模调整的一个控制因素。由于Kafka对多个消费者的支持而造成的入站和出站网络使用的内在不平衡,使得情况变得更加复杂。生产者可以为一个给定的主题每秒编写1 MB的内容,但是可以有任意数量的消费者,这会对出站网络使用产生乘数效应。其他操作,如集群复制和镜像也将增加需求。如果网络接口饱和,集群复制落后的情况并不少见,这可能使集群处于脆弱状态。为了防止网络成为主要的控制因素,建议至少使用10Gb网卡(网络接口卡)运行。带有1Gb网卡的旧机器很容易饱和,不推荐使用。
CPU
处理能力并不像磁盘和内存那么重要,直到你开始将Kafka扩展到非常大,但它会在一定程度上影响代理的整体性能。理想情况下,客户机应该压缩消息以优化网络和磁盘使用。Kafka broker必须解压缩所有的消息批,但是,为了验证每个消息的cheksum
分配偏移量。然后需要重新压缩消息批处理,以便将其存储在磁盘上。这就是Kafka对处理能力的大部分需求的来源。然而,这不应该是选择硬件的主要因素,除非集群变得非常大,单个集群中有数百个节点和数百万个分区。此时,选择性能更好的CPU可以帮助减少集群大小。
Kafka集群
单个Kafka broker对于本地开发工作或概念验证系统都很有效,但是将多个brokers配置为一个集群有显著的好处,如图2所示。最大的好处是能够跨多个服务器扩展负载。其次是使用复制来防止由于单个系统故障造成的数据丢失。复制还允许在Kafka或底层系统上执行维护工作,同时仍然维护客户端的可用性。以下主要介绍配置Kafka基本集群的步骤。
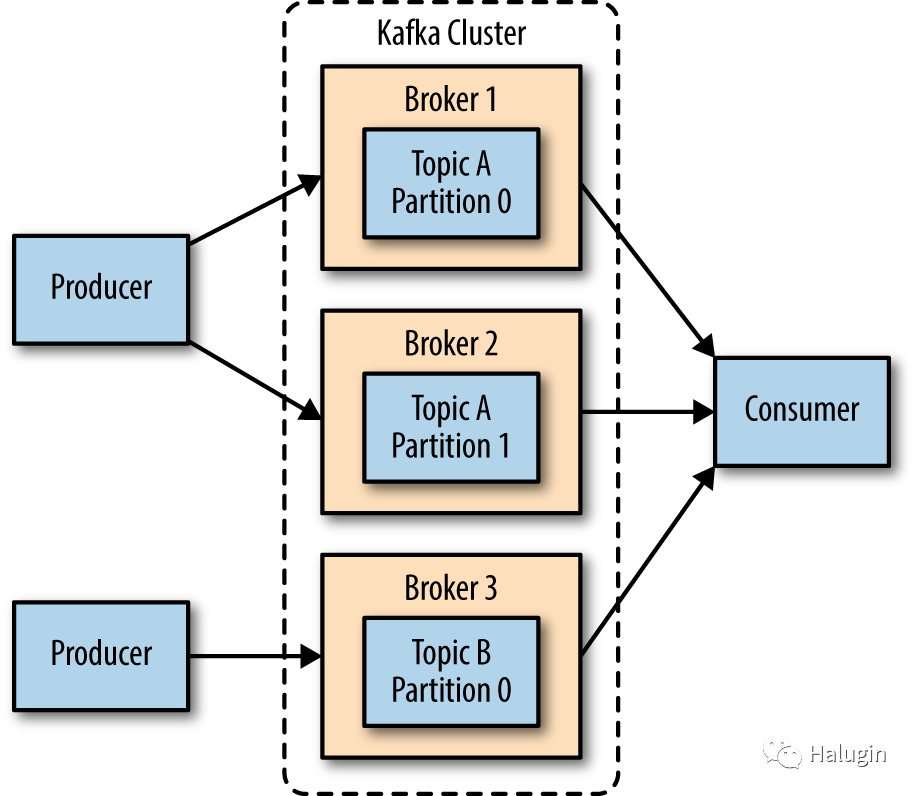
需要多少Brokers?
Kafka集群的大小是由几个因素决定的。通常情况下,集群的大小取决于以下关键因素:
- 磁盘容量
- 每个broker的复制容量
- CPU容量
- 网络容量
要考虑的第一个因素是需要多少磁盘容量才能保留消息,以及单个broker上有多少可用存储空间。如果集群需要保留10tb的数据,而单个broker可以存储2tb的数据,那么最小的集群大小是5个broker。此外,增加复制因子至少会增加100%的存储需求,这取决于所选择的复制因子设置。在本例中,副本指的是单个分区复制的不同broker的数量。这意味着这个配置了2个副本的集群现在需要包含至少10个broker。
另一个需要考虑的因素是集群处理请求的能力。这可以通过上面提到的其他3个瓶颈体现出来。
如果你有一个10个broker Kafka集群,但是在你的集群中有超过100万个副本(即500,000个复制因子为2的分区),在一个均衡的场景中,每个broker大约有100,000个副本。这可能导致在生产、消费和控制器队列中出现瓶颈。早期,官方建议每个broker不超过4,000个分区副本,每个集群不超过200,000个分区副本。然而,集群效率的提高使得Kafka可以扩展得更大。目前,在配置良好的环境中,建议每个broker不超过14,000个分区副本,每个集群不超过100万个副本。
正如前面提到的,CPU通常不是大多数用例的主要瓶颈,但如果broker上有过多的客户端连接和请求,它可能是一个瓶颈。根据有多少唯一的客户端和消费者组来关注总体CPU使用情况,并进行扩展以满足这些需求,这有助于确保大型集群中更好的总体性能。网络容量,重要的是要记住什么是网络接口的能力,和他们能处理客户端流量如果有多个用户的数据或者交通的保存期不一致的数据(例如,在高峰时期的流量)。如果单个代理上的网络接口在峰值时使用了80%的容量,并且该数据有两个消费者,那么消费者将无法跟上峰值流量,除非有两个broker。如果在集群中使用复制,则必须考虑数据的额外使用者。为了处理由于磁盘吞吐量或系统可用内存较少而引起的性能问题,还可以向外扩展到集群中更多的broker。
Broker配置
在broker配置中,允许多个Kafka broker加入一个集群只有两个要求。首先,所有代理必须对zookeeper具有相同的配置zookeeper.connect
参数。指定Zookeeper集成和集群存储元数据的路径。第二个要求是集群中的所有brokers必须对代理具有唯一的值broker.id
参数。如果两个代理试图用同一个broker.id
加入同一个集群时,第二个代理将记录一个错误并无法启动。在运行集群时,还使用了其他配置参数—-特别是控制复制的参数。
操作系统调优
虽然大多数Linux发行版都有开箱即用的内核调优参数配置,这对于大多数应用程序来说都工作得相当好,但Kafka broker可以做一些改变来提高性能。这些问题主要围绕虚拟内存和网络子系统,以及用于存储日志段的磁盘挂载点的具体问题。这些参数通常在/etc/sysctl.conf
文件中配置。
virtual Memory
通常,Linux虚拟内存系统会根据系统的工作负载自动调整。我们可以对交换空间的处理方式以及脏内存页面进行一些调整,以适应Kafka的工作负载。
对于大多数应用程序(特别是那些需要考虑吞吐量的应用程序),最好避免(几乎)不惜一切代价进行交换。在Kafka中,将内存页面交换到磁盘所产生的成本将对性能的各个方面产生显著影响。另外,Kafka占用了大量的系统页面缓存,当虚拟机系统换磁盘时,页面缓存没有足够的内存分配。
避免交换的一种方法是根本不配置任何交换空间。交换并不是必需的,但如果系统发生灾难性的事情,它确实提供了一个安全网。使用交换可以防止操作系统因内存不足而突然终止进程。因此,建议设置vm.swappiness
参数为一个非常低的值,例如1。该参数是VM子系统使用交换空间而不是从页面缓存中删除页面的可能性的百分比。最好减少页缓存可用的内存量,而不是利用任何数量的交换内存。
调整内核处理必须刷新到磁盘的脏页的方式还有一个好处。Kafka依赖于磁盘I/O性能来为生产者提供良好的响应时间。这也是为什么日志段通常放在快速磁盘上的原因,无论是具有快速响应时间的单个磁盘(例如SSD),还是具有重要NVRAM用于缓存的磁盘子系统(例如RAID)。其结果是,在刷新后台进程开始将脏页写入磁盘之前,允许的脏页数量可以减少。这是通过设置vm.dirty_background_ratio
来实现的,值低于默认值10。该值是系统内存总量的百分比,在许多情况下,将该值设置为5是合适的。但是,不应该将此设置设置为零,因为这会导致内核不断刷新页面,从而消除内核针对底层设备性能的临时峰值缓冲磁盘写的能力。
在内核强制同步操作将脏页刷新到磁盘之前允许的脏页总数也可以通过更改vm.dirty_ratio
的值,将其增加到默认值20以上(也是系统总内存的百分比)。此设置的可能值范围很广,但在60到80之间是一个合理的数字。这种设置确实会带来少量风险,包括未刷新磁盘活动的数量,以及强制同步刷新时可能出现的长时间I/O暂停。如果vm.dirty_ratio
的设置更高,强烈建议在Kafka集群中使用复制,以防止系统故障。
当为这些参数选择值时,明智的做法是在Kafka集群在负载下运行时检查脏页面的数量,无论是在生产环境中还是模拟环境中。当前脏页的数量可以通过检查/proc/vmstat文件来确定:
[root@node01 opt]# cat /proc/vmstat | egrep "dirty|writeback"nr_dirty 9nr_writeback 0nr_writeback_temp 0nr_dirty_threshold 232455nr_dirty_background_threshold 77485
Kafka为日志段和打开的连接使用文件描述符。如果一个broker有很多分区,那么该broker至少需要(number_of_partitions)\(partition_size/segment_size)*来跟踪所有的日志段,以及代理建立的连接数。
Disk
除了选择磁盘设备硬件以及使用RAID(如果使用RAID)的配置之外,为该磁盘选择文件系统对性能的影响仅次于磁盘设备硬件。有许多不同的文件系统可用,但本地文件系统最常见的选择是EXT4或区段文件系统(XFS)。XFS已经成为许多Linux发行版的默认文件系统,在大多数工作负载下,只需要最小的调优,XFS的性能就优于EXT4。EXT4可以执行得很好,但它需要使用被认为不太安全的调优参数。这包括将提交间隔设置为比默认值(5)更长的时间,以强制降低刷新频率。EXT4还引入了块的延迟分配,这在系统故障的情况下带来了更大的数据丢失和文件系统损坏的可能性。XFS文件系统也使用延迟分配算法,但它通常比EXT4使用的算法更安全。XFS对于Kafka的工作负载也有更好的性能,不需要优化文件系统执行的自动优化。当批处理磁盘写操作时,它也更高效,所有这些操作结合起来可以提供更好的总体I/O吞吐量。
无论选择哪个文件系统作为保存日志段的挂载,建议为挂载点设置noatime
挂载选项。文件元数据包含三个时间戳:创建时间(ctime
)、最后修改时间(mtime
)和最后访问时间(atime)
。默认情况下,每次读取文件时都会更新atime
。这将生成大量的磁盘写操作。一般认为atime
属性用处不大,除非应用程序需要知道文件在最后一次修改后是否被访问过(在这种情况下可以使用相对选项)。Kafka根本没有使用atime
,所以禁用它是安全的。在挂载上设置noatime
将防止这些时间戳更新发生,但不会影响对ctime
和mtime
属性的正确处理。当有较大的磁盘写操作时,使用largeio
选项也可以帮助提高Kafka的效率。
Networking
对于任何产生大量网络流量的应用程序来说,调整Linux网络堆栈的默认调优都是很常见的,因为默认情况下内核不会针对大型、高速的数据传输进行调优。事实上,Kafka的建议改变和大多数web服务器和其他网络应用的建议是一样的。第一个调整是更改为每个套接字的发送和接收缓冲区分配的默认和最大内存量。这将显著提高大型传输的性能。每个套接字的发送和接收缓冲区默认大小的相关参数是net.core。wmem_default
和net.core.rmem_default
,这些参数的合理设置是131072,即128 KiB。发送和接收缓冲区的最大大小的参数是net.core.wmem_max
和net.core.rmem_max
,合理设置为2097152,即2个MiB。记住,最大大小并不意味着每个套接字都会分配这么多缓冲区空间;它只允许在需要的情况下达到这么多。
除了套接字设置之外,TCP套接字的发送和接收缓冲区大小必须使用net.ipv4.tcp_wmem
和net.ipv4.tcp_rmemc
参数设置。它们使用三个用空格分隔的整数设置,分别指定最小、默认和最大大小。最大大小不能大于使用net.core.wmem_max
和net.core.rmem_maxnet.core
为所有套接字指定的值。这些参数的示例如“4096 65536 2048000”,最小值为4kib,默认值为64kib,最大缓冲区为2 MiB。基于你的Kafka broker的实际工作负载,你可能想要增加最大的大小,以允许更大的网络连接缓冲。
总结
在本文中,学习了如何启动和运行Apache Kafka。还讨论了为brokers选择合适的硬件,以及在生产环境中进行设置时的具体关注事项。
感兴趣的关注如下公众号!

