




Kubernetes网络之四:kubernetes网络简介
首先我们需要安装有kubernetes集群环境。kubernetes集群安装可以参考:https://github.com/eip-work/kuboard-press
。
前面我们讨论了Linux和容器网络的关键组件,现在开始kubernetes网络之旅。在本文中我们将讨论pod如何从内部和外部连接到集群。介绍kubernetes的内部组件是如何连接的。
kubernetes网络主要解决以下四个方面的问题:
- Highly-coupled container-to-container communications
- Pod-to-Pod communications
- Pod-to-Service communications
- External-to-Service communications
Docker网络模型默认使用一个虚拟网桥网络,它定义在每个主机上,是一个用于连接容器的私有网络。容器的IP地址被分配了一个私有IP地址,这意味着运行在不同机器上的容器不能相互通信。开发人员必须将主机端口映射到容器端口,然后用Docker代理跨节点的通信。在这种情况下,Docker管理员要负责避免容器之间的端口冲突。kubernetes有着不同的网络处理方式。
Kubernetes网络模型
Kubernetes网络模型本身支持多主机集群网络。默认情况下,pod可以相互通信,而不管它们部署在哪个主机上。kubernetes依靠Container Network Interface、CNI
来满足一下要求:
- 所有容器必须在没有NAT的情况下与每个容器通信;
- 节点可以在不使用NAT的情况下与容器通信;
- 容器的IP地址与将自己视为外部容器的IP地址相同。
kubernetes的最小工作单元是pod
。一个pod包含一个或多个容器,它们总是被部署在同一个节点上一起运行。这种连接性允许将服务的各个实例分离到不同的容器中。例如,开发人员可以选择在一个容器中运行服务,在另一个容器中运行日志转发器。在不同的容器中运行进程允许它们拥有独立的资源配额(例如,“日志转发器使用的内存不能超过512MB”)。它还允许通过减少构件容器所需的范围来分离容器构件和部署机制。
以下示例是一个最小的pod定义。省略了许多选项,kubernetes管理各种字段,比如pod的状态,并且是只读的。
apiVersion: v1 kind: Pod metadata: name: go-web namespace: default spec: containers: - name: go-web image: go-web:v0.0.1 ports: - containerPort: 8080 protocol: TCP
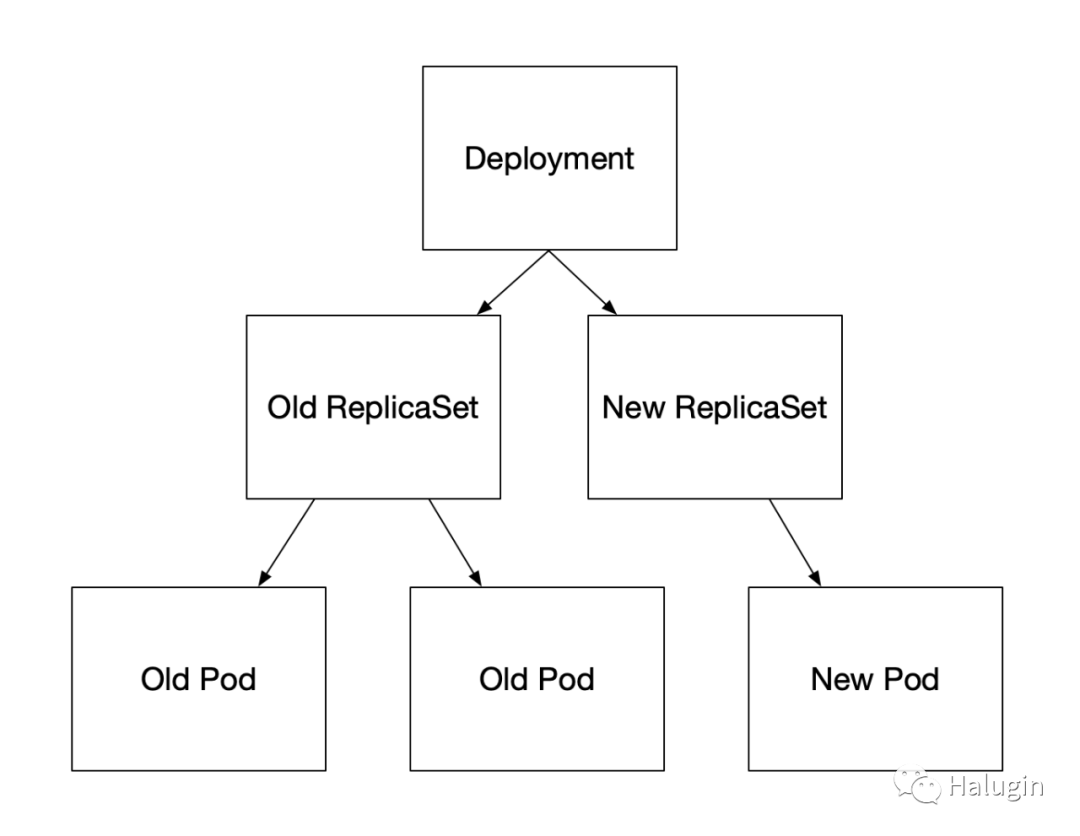
kubernetes用户通常不会直接创建pod。用户创建一个高级工作负载,例如Deployment,它根据一些预期的规范管理pod。在deployment中,如图1所示,用户为pod指定一个模板,以及他们希望存在多少pod副本。还有其他集中管理工作负载的方法:ReplicaSets、StatefulSets,我们将在后面介绍。有些在中间层上提供抽象,而有些则直接管理pod。还有以自定义资源定义(Custom Resource Definitions,CRD
)形式存在的第三方工作负载类型。Kubernetes中的工作负载是一个复杂的主题,我们只讨论最基本的内容和适用于网络堆栈的部分。
pod本身是临时的,这意味这它们会被删除,并被新版本所取代。对于熟悉半永久的、传统的物理或虚拟机的开发人员和操作人员来说,pod的短生命周期是一个主要的惊喜和挑战。在pod的生命周期中,本地磁盘状态、节点调度和IP地址都将被定期替换。
pod具有唯一的IP地址,该地址由pod中的所有容器共享。为每个pod提供IP地址的主要目的是消除对端口号的约束。在Linux中,只有一个程序可以侦听给定的地址、端口和协议。如果pod没有唯一的IP地址,那么一个节点上的两个pod可能争夺相同的端口(例如两个web服务器,都试图侦听端口80)。如果它们是相同的,则需要运行时配置来修复,例如使用--port
标志。或者,在第三方软件的情况下,需要一个脚本来更新配置文件。
在某些情况下,第三方软件根本无法在自定义端口上运行,这将需要更复杂的解决方案,如节点上的iptables
DNAT规则。Web服务器还有一个额外的问题,即期望在其软件中使用传统的端口号,例如HTTP为80,HTTPS为443。打破这些约定需要通过负载均衡器进行反向代理,或者让下游用户知道各种端口(这对于内部系统比外部系统容易得多)。一些系统,比如谷歌的Borg,就使用这个模型。Kubernetes选择IP per pod模型是为了让开发人员更容易采用,并使运行第三方工作负载更容易。不幸的是,为每个pod分配和路由IP地址会给Kubernetes集群增加相当大的复杂性。
使用自己的IP地址创建和删除pod可能会给不理解这种行为的初学者带来问题。假设我们在Kubernetes上运行一个小型服务,其部署形式是带有三个pod副本。当有人在部署中更新容器镜像时,Kubernetes执行滚动升级,删除旧的pod并使用新的容器镜像创建新的pod。这些新的pod可能会有新的IP地址,使旧的IP地址不可达。在配置或DNS记录中手动引用pod ip可能是一个常见的初学者错误,但它们无法解决。此错误是服务和端点试图解决的问题。
当显式创建pod时,可以指定IP地址。StatefulSets是一种用于数据库等工作负载的内置工作负载类型,它维护一个pod标识概念,并为一个新的pod提供与它所替代的pod相同的名称和IP地址。还有其他第三方CRD形式的示例,可以为特定的网络目的编写CRD。
每个Kubernetes节点运行一个名为Kubelet的组件,该组件管理节点上的pod。Kubelet中的网络功能来自于与节点上的CNI插件的API交互。CNI插件管理pod IP地址和单个容器网络配置。CNI定义了一个标准接口来管理容器的网络。将CNI作为接口的原因是要有一个可互操作的标准,其中有多个CNI插件实现。CNI插件负责分配pod的IP地址,并维护所有(适用的)pod之间的路由。Kubernetes没有附带默认的CNI插件,这意味着在Kubernetes的标准安装中,pod不能使用网络。
让我们开始讨论CNI和不同的网络设计如何启用pod网络。
节点和Pod网络设计
集群必须有一组由它控制的IP地址来分配一个IP地址给一个pod,例如10.1.0.0/16
。节点和pod在这个IP地址空间中必须具有L3连接,连接性意味着具有IP地址的包可以路由到具有该IP地址的主机。重要的是要注意,交付数据包的能力比创建连接(L4概念)更为基础。在L4中,防火墙可以选择允许从主机A到B的连接,但拒绝从主机B发起的连接。L4必须允许从A到B的连接,在L3的连接,A到B和B到A的连接。没有L3连接,TCP握手是不可能的,因为SYN-ACK不能被交付。
一般来说,pod没有MAC地址。因此,L2连接pod是不可能的。CNI将为pods确定这一点。
Kubernetes中对L3与外部的连接没有要求。尽管大多数集群都有互联网连接,但出于安全原因,有些集群需要隔离。
我们将广泛讨论入口ingress(离开主机或集群的流量)和出口engress(进入主机或集群的流量)。我们在这里使用的“ingress”不应该与Kubernetes的ingress资源相混淆,它是一种将流量路由到Kubernetes服务的特定HTTP机制。
有三种不同的方法来构建集群网络:isolated network、flat network和island network
Isolated Networks
在一个孤立的集群网络中,节点在更广泛的网络上是可路由的(即,不属于集群的主机可以到达集群中的节点),但pod则不能。如图2所示。Pod不能到达集群之外的其他pod(或任何其他主机)。
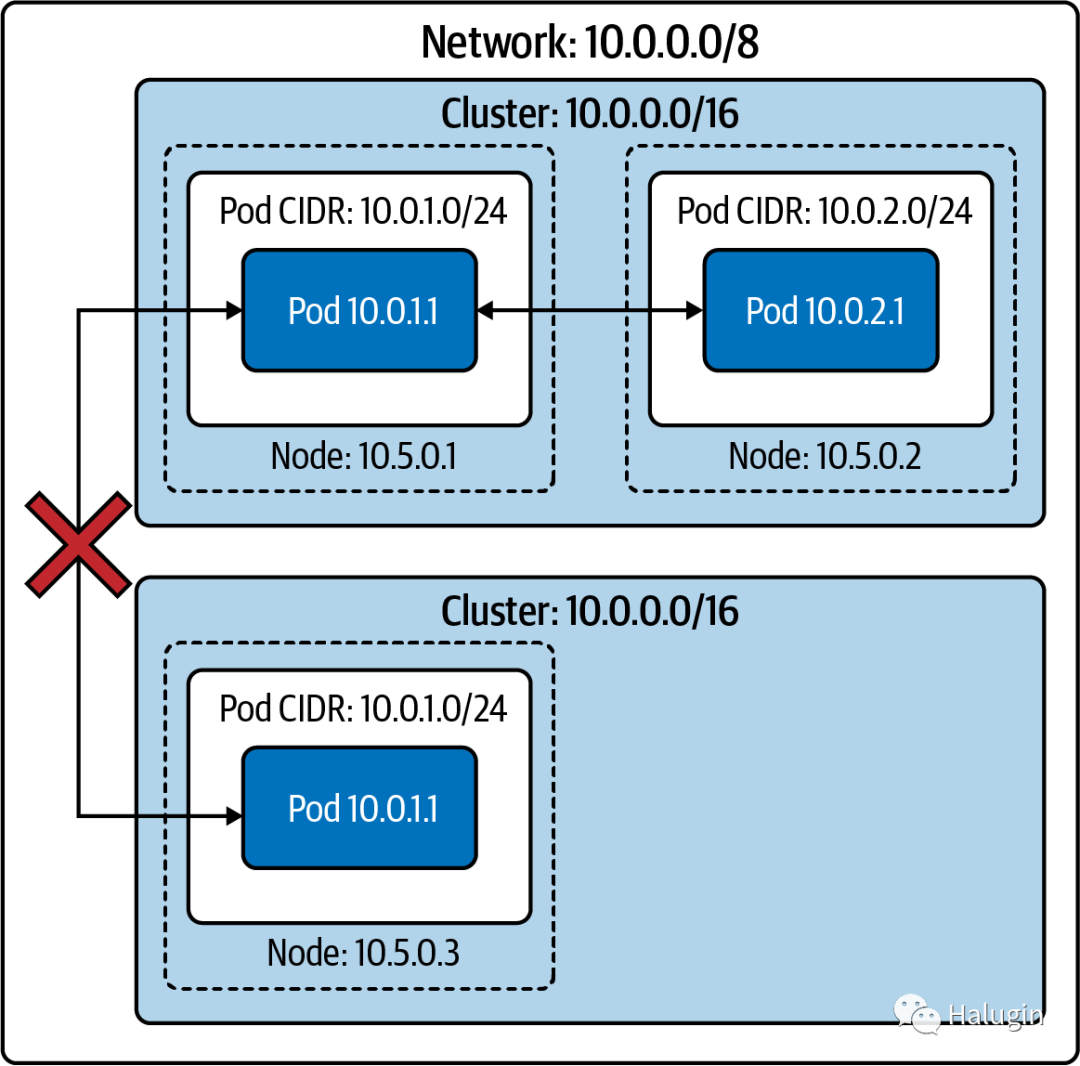
由于集群不能从更广泛的网络路由,多个集群甚至可以使用相同的IP地址空间。如果外部系统或用户应该能够访问Kubernetes API,那么Kubernetes API服务器需要能够从更广泛的网络路由。许多Kubernetes供应商都有类似的“安全集群”选项,集群和互联网之间不可能有直接通信。
如果集群的工作负载允许/需要这样的设置(例如用于批处理的集群),那么与本地集群的隔离可以极大地提高安全性。然而,这对所有集群都是不合理的。大多数集群将需要访问和/或由外部系统访问,例如必须支持依赖于更广泛的internet的服务的集群。负载均衡器和代理可以用来突破这个障碍,并允许互联网流量进入或离开孤立的集群。
Flat Networks
在flat network中,所有pod都有一个IP地址,可以从更广泛的网络路由。排除防火墙规则,网络上的任何主机都可以路由到集群内部或外部的任何pod。这种配置在网络简单性和性能方面有许多优点。Pod可以直接连接到网络中的任意主机。
在图3中,两个集群中没有两个节点的pod cidr重叠,因此不会给两个pod分配相同的IP地址。因为更广泛的网络可以将每个pod的IP地址路由到该pod的节点,所以网络上的任何主机都可以与任何pod连接。
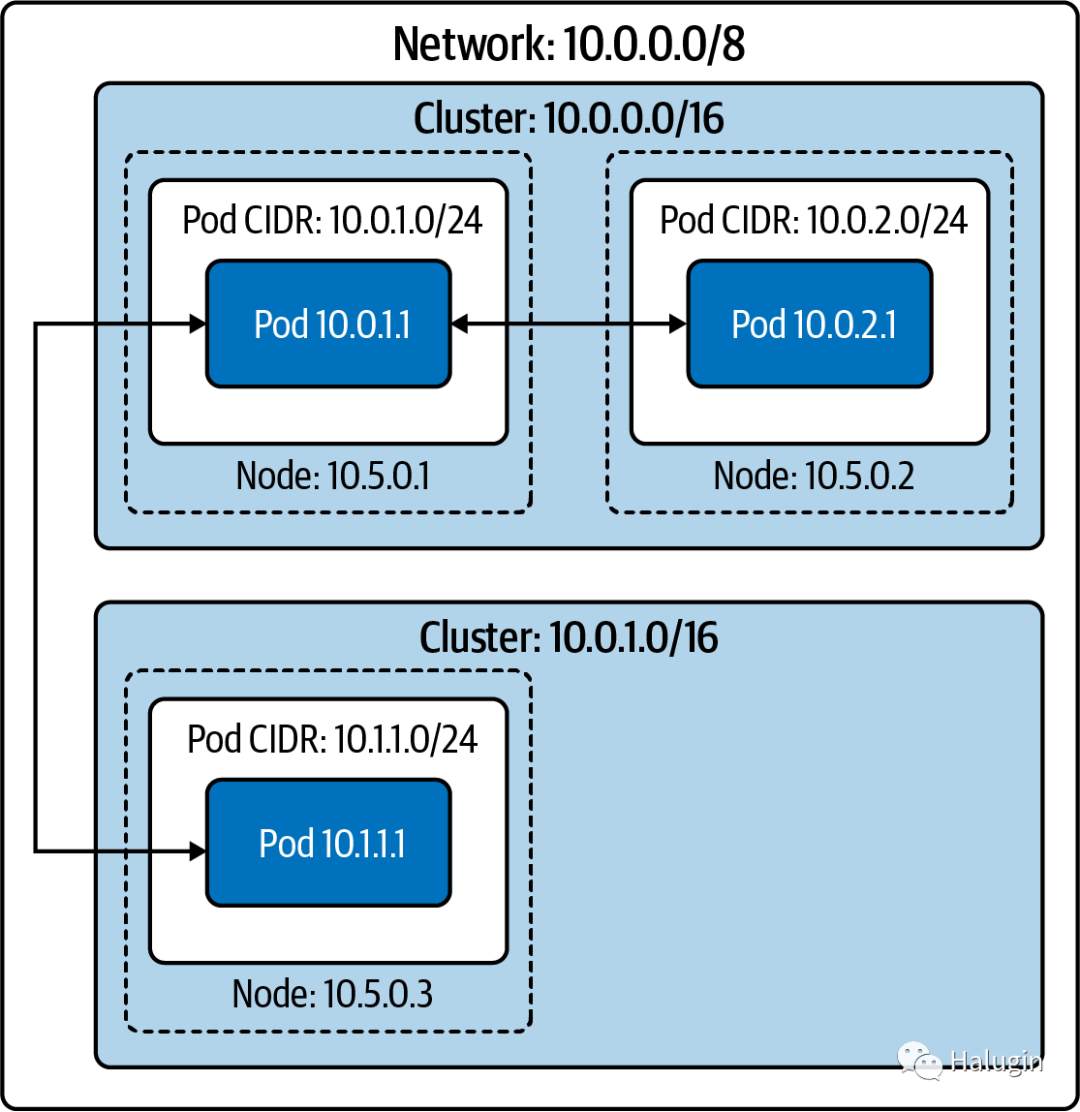
这种开放性允许任何拥有足够服务发现数据的主机决定哪个pod将接收这些数据包。集群外部的负载均衡器可以对pod进行负载平衡,比如另一个集群中的gRPC客户端。
外部pod流量(以及传入的pod流量,当连接的目的地是特定的pod IP地址时)具有低延迟和低开销。任何形式的代理或包重写都会产生延迟和处理成本,这虽然很小,但并非微不足道(特别是在涉及许多后端服务的应用程序体系结构中,每次延迟都会累加)。
不幸的是,这个模型需要为每个集群提供一个大的、连续的IP地址空间(即,一个范围内的每个IP地址都在你的控制之下的IP地址范围)。Kubernetes需要一个单独的CIDR用于pod IP地址(对于每个IP族)。该模型可以通过私有子网(如10.0.0.0/8或172.16.0.0/12)实现;然而,使用公共IP地址(尤其是IPv4地址)要困难得多,成本也高得多。管理员需要使用NAT将运行在私有IP地址空间的集群连接到互联网。
除了需要一个大的IP地址空间外,管理员还需要一个易于编程的网络。CNI插件必须分配pod的IP地址,并确保存在到给定pod节点的路由。
在云提供商环境中,在私有子网上的flat networks很容易实现。绝大多数云提供商网络将提供大型私有子网,并拥有用于IP地址分配和路由管理的API(甚至是已经存在的CNI插件)。
Island Networks
在island集群中,如图4所示,节点与更广泛的网络之间有L3连接,而pods没有。进出pod的通信必须通过某种形式的代理,通过节点。大多数情况下,这是通过iptables
源NAT在pod的包离开节点上实现的。这个设置,称为masquerading,使用SNAT重写数据包源从pod的IP地址到节点的IP地址。换句话说,包似乎来自节点,而不是pod。
共享一个IP地址,同时也使用NAT隐藏个人pod IP地址。跨集群边界的基于IP地址的防火墙和识别变得困难。在集群中,哪个IP地址是哪个pod(因此也是哪个应用程序)仍然很明显。其他集群或更广泛网络上的其他主机中的pod将不再具有这种映射。基于IP地址的防火墙和允许列表本身并不是足够的安全性,但却是一个有价值的、有时是必需的层。
让我们看看如何使用kube-controller-manager
配置这些网络设计。Control plane是指决定使用哪条路径发送包或帧的所有功能和进程。Data plane是指基于控制平面逻辑将报文/帧从一个接口转发到另一个接口的所有功能和进程。

kube-controller-manager配置
kube-controller-manager
在一个二进制和一个进程中运行大多数单独的Kubernetes控制器,大多数Kubernetes逻辑都在这个进程中。从较高的层次上讲,Kubernetes术语中的控制器是监视资源并采取行动同步或执行特定状态(期望的状态或将当前状态反映为状态)的软件。Kubernetes有许多控制器,它们通常“拥有”特定的对象类型或特定的操作。
kube-controller-manager
包括多个管理Kubernetes网络堆栈的控制器。值得注意的是,管理员在这里设置集群CIDR。
Kube-controller-manager
,由于运行大量的控制器,也有大量的标志。表1列出了一些重要的网络配置标志。
| Flag | Default | Description |
|---|---|---|
--allocate-node-cidrs | true | Sets whether CIDRs for pods should be allocated and set on the cloud provider. |
--CIDR-allocator-type string | RangeAllocator | Type of CIDR allocator to use. |
--cluster-CIDR | CIDR range from which to assign pod IP addresses. Requires --allocate-node-cidrsto be true. If kube-controller-managerhas IPv6DualStackenabled, --cluster-CIDRaccepts a comma-separated pair of IPv4 and IPv6 CIDRs. | |
--configure-cloud-routes | true | Sets whether CIDRs should be allocated by allocate-node-cidrsand configured on the cloud provider. |
--node-CIDR-mask-size | 24 for IPv4 clusters, 64 for IPv6 clusters | Mask size for the node CIDR in a cluster. Kubernetes will assign each node 2^(node-CIDR-mask-size)IP addresses. |
--node-CIDR-mask-size-ipv4 | 24 | Mask size for the node CIDR in a cluster. Use this flag in dual-stack clusters to allow both IPv4 and IPv6 settings. |
--node-CIDR-mask-size-ipv6 | 64 | Mask size for the node CIDR in a cluster. Use this flag in dual-stack clusters to allow both IPv4 and IPv6 settings. |
--service-cluster-ip-range | CIDR range for services in the cluster to allocate service ClusterIPs. Requires --allocate-node-cidrsto be true. If kube-controller-managerhas IPv6DualStackenabled, --service-cluster-ip-rangeaccepts a comma-separated pair of IPv4 and IPv6 CIDRs. |
现在我们已经讨论了Kubernetes控制平面中的高级网络架构和网络配置,让我们进一步研究Kubernetes工作节点如何处理网络。
Kubelet
Kubelet是一个运行在集群中的每个工作节点上的二进制文件。在较高的级别上,Kubelet负责管理调度到节点的任何pod,并为其上的节点和pod提供状态更新。然而,Kubelet主要充当节点上其他软件的协调器。Kubelet管理容器网络实现(通过CNI)和容器运行时(通过CRI)。
当控制器(或用户)在Kubernetes API中创建pod时,它最初仅作为pod API对象存在。Kubernetes调度程序监视这样的pod,并尝试选择一个有效的节点来调度pod。这种调度有几个限制。我们的pod的CPU/内存请求不能超过节点上剩余的未请求CPU/内存。许多选择选项是可用的,例如对标记节点或其他标记pod或节点上的污点的亲和性/反亲和性。假设调度器找到一个满足pod所有约束的节点,调度器将该节点的名称写入pod的nodeName
字段。假设Kubernetes将pod调度到node-1
:
apiVersion: v1 kind: Pod metadata: name: example spec: nodeName: "node-1" containers: - name: example image: example:1.0
node-1
上的kubelet监视所有预定的pods。等效的kubectl命令是kubectl get pods -w --field-selector spec.nodeName=node-1
。当kubelet观察到我们的pod存在但不在节点上时,就创建了它。我们将跳过CRI细节和容器本身的创建。一旦容器存在,Kubelet就向CNI发出ADD调用,这告诉CNI插件创建pod网络。
Pod Readiness and Probes
Pod准备就绪指pod是否准备好服务通信。Pod就绪情况决定Pod地址是否显示在来自外部源的endpoint
对象中。Kubernetes管理pod的其他资源,如deployment,将pod准备情况考虑到决策中,如在滚动更新期间推进。在滚动部署期间,一个新的pod已经准备好了,但是由于各种原因,还没有为新的pod准备好服务、网络策略或负载均衡器。这可能会导致业务中断。应该注意的是,如果pod规范包含任何类型的探测,Kubernetes默认对所有三种类型都成功。
用户可以在pod规范中指定pod就绪检查。Kubelet执行指定的检查并根据成功或失败更新pod状态。
探针影响Pods. status.Phase
属性。以下是pod各阶段的描述:
Pending
pod已被集群接受,但一个或多个容器尚未设置并准备运行。这包括pod等待调度所花费的时间,以及通过网络下载容器镜像所花费的时间。
Running
pod已被调度到一个节点,所有容器都已创建。至少有一个容器仍在运行或处于启动或重新启动的过程中。注意,有些容器可能处于失败状态,例如
CrashLoopBackoff
。Succeeded
Pod中的所有容器都已成功终止,不会重新启动。
Failed
Pod中的所有容器都已终止,且至少有一个容器因故障而终止。也就是说,容器要么以非零状态退出,要么被系统终止。
Unknown
由于某些原因,Pod的状态无法确定。这个阶段通常是由于与Kubelet通信时出错而发生的,此时pod应该运行在Kubelet上。
Kubelet对pod中的各个容器执行几种类型的运行状况检查:活性探测(livenessProbe
)、就绪探测(readinessProbe
)和启动探测(startupProbe
)。Kubelet(以及由此扩展而来的节点本身)必须能够连接到该节点上运行的所有容器,以便执行任何HTTP健康检查。
每个探针都有以下三种结果之一:
Success
容器通过了诊断。
Failure
容器诊断失败。
Unknown
诊断失败,因此不应采取任何操作。
探测可以是执行探测(尝试在容器中执行二进制文件)、TCP探测或HTTP探测。如果探测失败的次数超过failureThreshold
的次数,Kubernetes将认为检查失败。这种效果取决于探测的类型。
当容器就绪探测失败时,Kubelet不会终止它。相反,Kubelet将失败写入了pod的状态。
如果活性探测失败,kubelet会终止容器。如果使用不当或配置不当,活性探针很容易导致意外故障。活动探测的预期用例是让Kubelet知道何时重新启动容器。然而,我们很快就会认识到,如果“出了什么问题,重新启动它”是一个危险的策略。例如,假设我们创建了一个activity探针来加载web应用的主页。进一步,假设在容器代码之外的系统发生了一些变化,导致主页返回404或500错误。出现这种情况的原因很多,例如后端数据库故障、必需的服务故障或暴露错误的特性标志更改。在这些场景中,活动探测将重新启动容器。在最好的情况下,这是没有帮助的;重新启动容器并不能解决系统中其他地方的问题,而且可能很快使问题恶化。Kubernetes有容器重新启动回退(CrashLoopBackoff
),这会增加重新启动失败容器的延迟。如果有足够多的pod或足够快的故障,应用程序可能会从主页上的错误变成硬着陆。根据应用程序的不同,pod也可能在重启时丢失缓存的数据;在假设的降级过程中,取回可能是费力的,或者不可能取回。因此,请谨慎使用活性探针。当pod使用它们时,它们只依赖于它们所测试的容器,没有其他依赖。许多工程师都有特定的健康检查端点,它们提供最低限度的标准验证,例如“PHP正在运行并服务于我的API”。
启动探针可以在激活探针生效之前提供一段宽限期。在启动探测成功之前,活性探测不会终止容器。一个示例用例是允许容器花很多分钟启动,但如果启动后容器变得不正常,则快速终止容器。
在示例1中,Golang web服务器有一个活动探针,它在端口8080
上执行HTTP GET
到路径/healthz
,而准备就绪探针在同一端口上使用/
。
apiVersion: v1 kind: Pod metadata: labels: test: liveness name: go-web spec: containers: - name: go-web image: go-web:v0.0.1 ports: - containerPort: 8080 livenessProbe: httpGet: path: /healthz port: 8080 initialDelaySeconds: 5 periodSeconds: 5 readinessProbe: httpGet: path: / port: 8080 initialDelaySeconds: 5 periodSeconds: 5
这种状态并不影响pod本身,但Kubernetes的其他机制会对此做出反应。一个关键的例子是ReplicaSets
(以及扩展为部署)。准备就绪探测失败会导致ReplicaSet控制器将pod计数为未准备就绪,当太多新pod不健康时,将导致部署停止。Endpoints
/EndpointsSlice
控制器也会对失败的准备就绪探测做出反应。如果pod的就绪探测失败,pod的IP地址将不在endpoint对象中,并且服务将不会将流量路由到它。
startupProbe
将通知Kubelet容器内的应用程序是否已启动。如果在pod规范中定义了startupProbe
,则禁用所有其他探测。一旦startupProbe
成功,Kubelet将开始运行其他探测。但是,如果启动探测失败,Kubelet将终止容器,容器将执行其重新启动策略。与其他方法一样,如果startupProbe
不存在,则默认状态为success。
探针可配置选项:
initialDelaySeconds
在启动活动或准备就绪探测之前,容器启动后的秒数。默认值0;最低0。
periodSeconds
执行探测的频率。默认10;最低1。
timeoutSeconds
探测超时的秒数。默认1;最低1。
successThreshold
探针失败后连续成功的最小值。默认1;对于活性和启动探针必须为1;最低1。
failureThreshold
当探测失败时,Kubernetes会尝试很多次,然后放弃。在activity探测的情况下放弃意味着容器将重新启动。准备就绪时,舱将被标记为未就绪。默认3;最低1。
Kubelet必须能够连接到Kubernetes API服务器。在图5中,我们可以看到集群中所有组件的所有连接:
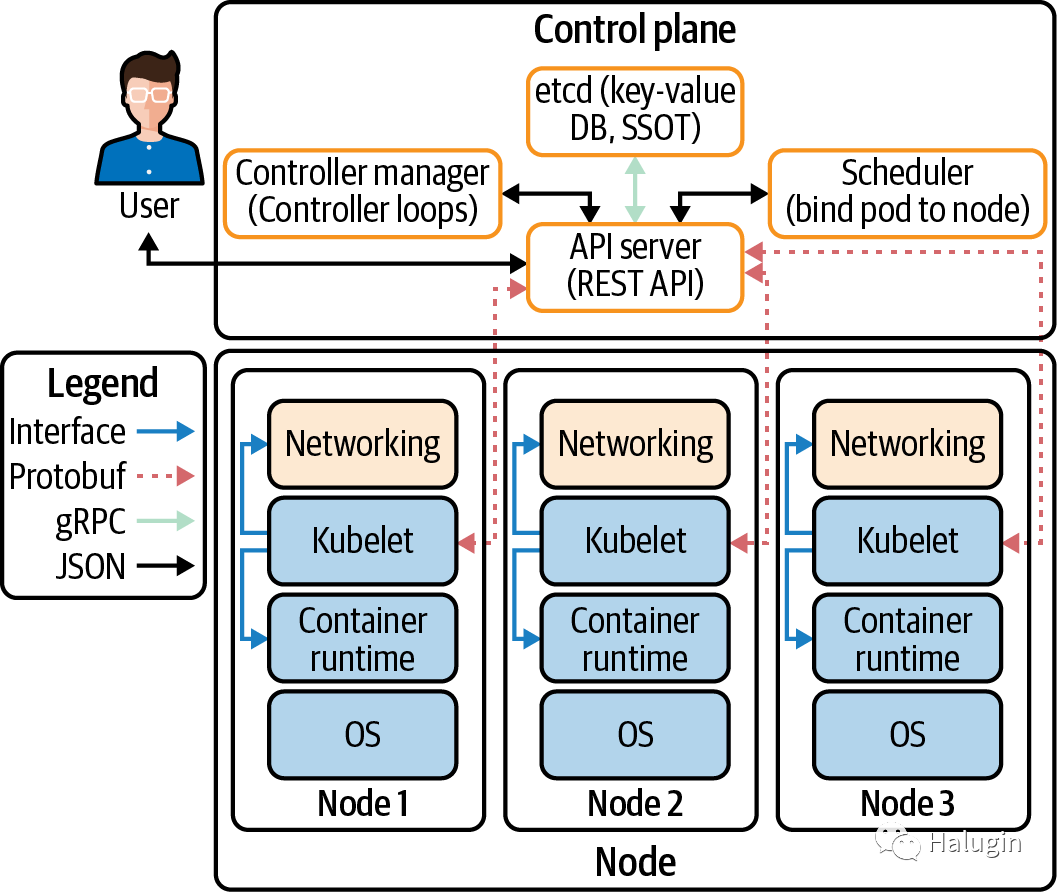
CNI
Kubelet的网络插件,使网络能够获得pods和services的ip。
gRPC
API服务器与
etcd
通信。kubelet
所有Kubernetes节点都有一个Kubelet,它确保分配给它的任何pod都在运行并配置为所需的状态。
CRI
在Kubelet中编译的gRPC API,允许Kubelet使用gRPC API与容器运行时进行通信。容器运行时提供程序必须使其适应CRI API,以允许Kubelet使用OCI标准(runC)与容器通信。CRI由协议缓冲区、gRPC API和库组成。
CNI规范
CNI规范本身非常简单。根据规范,CNI插件必须支持四种操作:
ADD
向网络添加一个容器。
DEL
从网络中删除容器。
CHECK
如果容器的网络有问题,返回一个错误。
VERSION
报告插件的版本信息。
在图6中,我们可以看到Kubernetes(或者运行时,CNI项目指的是容器协调器)是如何通过执行二进制文件来调用CNI插件操作的。Kubernetes向stdin
提供JSON格式的命令的任何配置,并通过stdout
接收JSON格式的命令输出。CNI插件通常有非常简单的二进制文件,作为Kubernetes调用的包装器,而二进制文件对持久后端进行HTTP或RPC API调用。基于频繁启动Windows进程时的性能问题,CNI维护者已经讨论过将其更改为HTTP或RPC模型。
Kubernetes一次只使用一个CNI插件,尽管CNI规范允许多重设置(例如,为一个容器分配多个IP地址)。Multus是一个CNI插件,它在Kubernetes中通过充当多个CNI插件的扇形来解决这个限制。
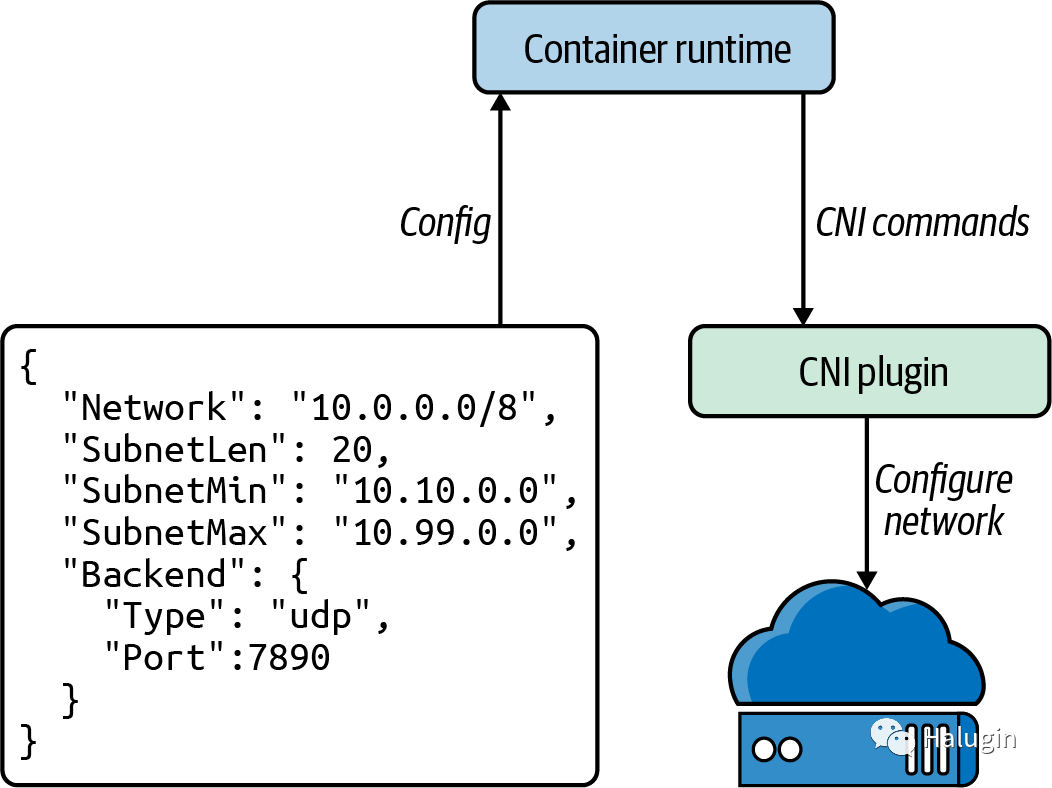
CNI插件
CNI插件有两个主要职责:为pod分配唯一的IP地址,并确保Kubernetes中存在到每个pod IP地址的路由。这意味着集群所在的总体网络决定了CNI插件的行为。例如,如果IP地址太少或无法为一个节点附加足够的IP地址,集群管理员将需要使用支持覆盖网络的CNI插件。使用的硬件堆栈或云提供商通常决定了哪些CNI选项是合适的。
要使用CNI,请将--network-plugin=cni
添加到Kubelet的启动参数中。默认情况下,Kubelet从/etc/cni/net.d
目录读取CNI配置。并期望在/opt/cni/bin/
找到CNI二进制文件。管理员可以使用--CNI -config-dir=<directory>
覆盖配置位置,使用--cni-bin-dir=<directory>
覆盖CNI二进制目录。
CNI网络模型有两大类:flat networks和overlay networks。在flat networks中,CNI驱动程序使用来自集群网络的IP地址,这通常需要许多IP地址对集群可用。在overlay networks中,CNI驱动程序在Kubernetes中创建一个次级网络,该网络使用集群的网络(称为底层网络)来发送数据包。overlay networks在集群中创建一个虚拟网络。在overlay networks中,CNI插件封装数据包。overlay networks增加了相当大的复杂性,并且不允许集群网络上的主机直接连接到pod。然而,overlay networks允许集群网络更小,因为只有节点必须分配该网络上的IP地址。
CNI插件通常还需要一种在节点之间通信状态的方法。插件采用非常不同的方法,比如将数据存储在Kubernetes API中,并存储在专用的数据库中。
CNI插件还负责调用IPAM插件进行IP寻址。
IPAM接口
CNI规范有第二个接口,IP Address Management (IPAM)接口,以减少CNI插件中IP分配代码的重复。IPAM插件需要确定并输出接口的IP地址、网关和路由,示例2所示。IPAM接口类似于CNI:带有对stdin
的JSON输入和来自stdout
的JSON输出的二进制文件。
{ "cniVersion": "0.4.0", "ips": [ { "version": "<4-or-6>", "address": "<ip-and-prefix-in-CIDR>", "gateway": "<ip-address-of-the-gateway>" (optional) }, ... ], "routes": [ (optional) { "dst": "<ip-and-prefix-in-cidr>", "gw": "<ip-of-next-hop>" (optional) }, ... ] "dns": { (optional) "nameservers": <list-of-nameservers> (optional) "domain": <name-of-local-domain> (optional) "search": <list-of-search-domains> (optional) "options": <list-of-options> (optional) } }
常用的CNI插件
Cilium是一个开源软件,用于透明地保护应用程序容器之间的网络连接。Cilium是一种支持L7/http的CNI,可以使用与网络寻址分离的基于身份的安全模型在L3-L7上执行网络策略。
Flannel专注于网络,是为Kubernetes设计的一种简单的配置三层网络结构的方法。如果集群需要网络策略等功能,管理员必须部署其他cni,如Calico。Flannel使用Kubernetes集群现有的etcd存储其状态信息,以避免提供专用的数据存储。
Calico表示,它“将灵活的网络能力与随处运行的安全强制措施相结合,提供了具有本地Linux内核性能和真正的云本地可伸缩性的解决方案。”Calico不使用overlay networks。相反,Calico配置了一个三层网络,使用BGP路由协议在主机之间路由报文。Calico还可以与Istio(服务网格)集成,在服务网格和网络基础设施层解释和执行集群内工作负载的策略。
表2给出了可供选择的主要CNI插件的简要概述。
| Name | NetworkPolicy support | Data storage | Network setup |
|---|---|---|---|
| Cilium | Yes | etcd or consul | Ipvlan(beta), veth, L7 aware |
| Flannel | No | etcd | Layer 3 IPv4 overlay network |
| Calico | Yes | etcd or Kubernetes API | Layer 3 network using BGP |
| Weave Net | Yes | No external cluster store | Mesh overlay network |
让我们在示例3中使用Golang web服务器部署Cilium进行测试。我们需要一个kubernetes群集来部署cilium。在本地部署集群进行测试的最简单的方法之一是KIND,它允许我们使用YAML配置文件创建一个集群,然后使用Helm将Cilium部署到该集群中。
kind: Cluster # Specifies that we are configuring a KIND cluster apiVersion: kind.x-k8s.io/v1alpha4 # The version of KIND’s config nodes: # The list of nodes in the cluster - role: control-plane # One control plane node - role: worker # Worker node 1 - role: worker # Worker node 2 - role: worker # Worker node 3 networking: # KIND configuration options for networking disableDefaultCNI: true # Disables the default networking option so that we can deploy Cilium
使用KIND集群配置YAML,我们可以使用下面的命令使用KIND创建该集群。
$ kind create cluster --config=kind-config.yaml Creating cluster "kind" ... ✓ Ensuring node image (kindest/node:v1.18.2) Preparing nodes ✓ Writing configuration Starting control-plane Installing StorageClass Joining worker nodes Set kubectl context to "kind-kind"You can now use your cluster with: kubectl cluster-info --context kind-kind Have a question, bug, or feature request? Let us know! https://kind.sigs.k8s.io/ Always verify that the cluster is up and running with kubectl.
现在集群已经在本地运行,我们可以开始使用Kubernetes的部署工具Helm安装Cilium。根据其文档,Helm是安装Cilium的首选方式。
$ helm repo add cilium https://helm.cilium.io/# Pre-pulling and loading container images is optional.$ docker pull cilium/cilium:v1.9.1kind load docker-image cilium/cilium:v1.9.1
现在Cilium的先决条件已经完成,我们可以用Helm把它安装到我们的集群中。Cilium有很多配置选项,Helm使用--set NAME_VAR=VAR
配置选项:
$ helm install cilium cilium/cilium --version 1.10.1 \ --namespace kube-system NAME: Cilium LAST DEPLOYED: Fri Jan 1 15:39:59 2021NAMESPACE: kube-system STATUS: deployed REVISION: 1TEST SUITE: None NOTES: You have successfully installed Cilium with Hubble. Your release version is 1.10.1. For any further help, visit https://docs.cilium.io/en/v1.10/gettinghelp/
Cilium在集群中安装了几个组件:代理、客户端、操作员和cilium-cni
插件:
Agent
cilium -agent
运行在集群中的每个节点上。代理通过Kubernetes api接受配置,这些api描述了网络、服务负载平衡、网络策略以及可见性和监控需求。Client(CLI)
Cilium CLI客户端(Cilium)是随Cilium代理一起安装的命令行工具。它与同一节点上的REST API交互。CLI允许开发人员检查本地代理的状态和状态。它还提供了访问eBPF映射以直接验证其状态的工具。
Operator
Operator负责管理集群中的职责,这些职责应该由每个集群而不是每个节点来处理。
CNI Plugin
CNI插件(
cilium-cni
)与节点的Cilium API交互,以触发配置以提供网络、负载均衡和网络策略。
可以使用kubectl -n kube-system get pods --watch
命令观察集群中部署的所有组件:
$ kubectl -n kube-system get pods --watch NAME READY STATUS cilium-65kvp 0/1 Init:0/2cilium-node-init-485lj 0/1 ContainerCreating cilium-node-init-79g68 1/1 Running cilium-node-init-gfdl8 1/1 Running cilium-node-init-jz8qc 1/1 Running cilium-operator-5b64c54cd-cgr2b 0/1 ContainerCreating cilium-operator-5b64c54cd-tblbz 0/1 ContainerCreating cilium-pg6v8 0/1 Init:0/2cilium-rsnqk 0/1 Init:0/2cilium-vfhrs 0/1 Init:0/2coredns-66bff467f8-dqzql 0/1 Pending coredns-66bff467f8-r5nl6 0/1 Pending etcd-kind-control-plane 1/1 Running kube-apiserver-kind-control-plane 1/1 Running kube-controller-manager-kind-control-plane 1/1 Running kube-proxy-k5zc2 1/1 Running kube-proxy-qzhvq 1/1 Running kube-proxy-v54p4 1/1 Running kube-proxy-xb9tr 1/1 Running kube-scheduler-kind-control-plane 1/1 Running cilium-operator-5b64c54cd-tblbz 1/1 Running
现在已经部署了cilium,我们可以运行cilium连接检查,以确保它正常运行:
$ kubectl apply -n cilium-test \-f \ https://raw.githubusercontent.com/strongjz/advanced_networking_code_examples/ master/chapter-4/connectivity-check.yaml deployment.apps/echo-a created deployment.apps/echo-b created deployment.apps/echo-b-host created deployment.apps/pod-to-a created deployment.apps/pod-to-external-1111 created deployment.apps/pod-to-a-denied-cnp created deployment.apps/pod-to-a-allowed-cnp created deployment.apps/pod-to-external-fqdn-allow-google-cnp created deployment.apps/pod-to-b-multi-node-clusterip created deployment.apps/pod-to-b-multi-node-headless created deployment.apps/host-to-b-multi-node-clusterip created deployment.apps/host-to-b-multi-node-headless created deployment.apps/pod-to-b-multi-node-nodeport created deployment.apps/pod-to-b-intra-node-nodeport created service/echo-a created service/echo-b created service/echo-b-headless created service/echo-b-host-headless created ciliumnetworkpolicy.cilium.io/pod-to-a-denied-cnp created ciliumnetworkpolicy.cilium.io/pod-to-a-allowed-cnp created ciliumnetworkpolicy.cilium.io/pod-to-external-fqdn-allow-google-cnp created
连接性测试将部署一系列Kubernetes部署,这些部署将使用各种连接性路径。连接路径具有或不具有服务负载均衡,并且存在于各种网络策略组合中。
$ kubectl get pods -n cilium-test -w NAME READY STATUSecho-a-57cbbd9b8b-szn94 1/1 Runningecho-b-6db5fc8ff8-wkcr6 1/1 Runningecho-b-host-76d89978c-dsjm8 1/1 Running host-to-b-multi-node-clusterip-fd6868749-7zkcr 1/1 Running host-to-b-multi-node-headless-54fbc4659f-z4rtd 1/1 Running pod-to-a-648fd74787-x27hc 1/1 Running pod-to-a-allowed-cnp-7776c879f-6rq7z 1/1 Running pod-to-a-denied-cnp-b5ff897c7-qp5kp 1/1 Running pod-to-b-intra-node-nodeport-6546644d59-qkmck 1/1 Running pod-to-b-multi-node-clusterip-7d54c74c5f-4j7pm 1/1 Running pod-to-b-multi-node-headless-76db68d547-fhlz7 1/1 Running pod-to-b-multi-node-nodeport-7496df84d7-5z872 1/1 Running pod-to-external-1111-6d4f9d9645-kfl4x 1/1 Running pod-to-external-fqdn-allow-google-cnp-5bc496897c-bnlqs 1/1 Running
现在Cilium为集群管理我们的网络,我们将在后面的NetworkPolicy
概述中使用它。并不是所有的CNI插件都支持NetworkPolicy
,所以这是决定使用哪个插件时的一个重要细节。
kube-proxy
kube-proxy
是Kubernetes中另一个每个节点的守护进程,与Kubelet类似。Kube-proxy
在集群内提供基本的负载平衡功能。它实现服务并依赖于endpoint /EndpointSlices
。
- 服务为一组pod定义了负载平衡器。
- Endpoint/Endpointslices列出一组就绪的pod ip。它们是从服务中自动创建的,使用与服务相同的pod选择器。
大多数类型的服务都有一个服务的IP地址,称为集群IP地址,该地址在集群外部不可路由。kube-proxy
负责将服务的集群IP地址的请求路由到健康的pod。到目前为止,kube-proxy
是Kubernetes服务最常见的实现,但kube-proxy
还有其他替代方式,比如替换模式Cilium。
kube-proxy
有四种模式,可以改变其运行时模式和确切的特性集:userspace
、iptables
、ipvs
和kernelspace
。可以使用--proxy-mode
指定模式。值得注意的是,所有模式在某种程度上都依赖于iptables
。
userspace Mode
第一个也是最古老的模式是userspace
模式。在userspace
模式下,kube-proxy
运行一个web服务器,并通过iptables
将所有业务IP地址路由到web服务器。web服务器终止连接,并将请求代理到服务端点中的pod。userspace
模式已不常用,应该避免使用它,除非有明确的理由使用它。
iptables Mode
iptables
模式完全使用iptables
。它是默认模式,也是最常用的模式。
iptables
模式执行连接扇出,而不是真正的负载均衡。换句话说,iptables
模式将把一个连接路由到一个后端pod,并且使用该连接发出的所有请求将转到同一个pod,直到连接终止。这很简单,并且在理想的场景中具有可预测的行为(例如,同一连接中的连续请求将能够从后端pod中的任何本地缓存中受益)。当处理长期存在的连接时,例如HTTP/2连接(值得注意的是,HTTP/2是gRPC的传输),它也可能是不可预测的。假设有两个pod, X和Y,提供服务,在正常滚动更新期间将X替换为Z。旧的pod Y仍然拥有所有现有连接,加上在pod X关闭时需要重新建立的一半连接,导致pod Y提供更多的流量。有很多类似的场景会导致流量不平衡。
以下是集群中kube-dns
服务的iptables
转发规则。在我们的示例中,kube-dns
服务的集群IP地址是10.96.0.10
。
$ sudo iptables -t nat -L KUBE-SERVICES Chain KUBE-SERVICES (2 references) target prot opt source destination /* kube-system/kube-dns:dns cluster IP */ udp dpt:domain KUBE-MARK-MASQ udp -- !10.217.0.0/16 10.96.0.10/* kube-system/kube-dns:dns cluster IP */ udp dpt:domain KUBE-SVC-TCOU7JCQXEZGVUNU udp -- anywhere 10.96.0.10/* kube-system/kube-dns:dns-tcp cluster IP */ tcp dpt:domain KUBE-MARK-MASQ tcp -- !10.217.0.0/16 10.96.0.10/* kube-system/kube-dns:dns-tcp cluster IP */ tcp dpt:domain KUBE-SVC-ERIFXISQEP7F7OF4 tcp -- anywhere 10.96.0.10 ADDRTYPE match dst-type LOCAL /* kubernetes service nodeports; NOTE: this must be the last rule in this chain */ KUBE-NODEPORTS all -- anywhere anywhere
kube-dns
有一对UDP和TCP规则。我们将重点放在UDP协议上。
第一条UDP规则将任何不是来自pod IP地址(10.217.0.0/16
是默认的pod网络CIDR)的服务连接标记为伪装。
下一条UDP规则的目标是KUBE-SVC-TCOU7JCQXEZGVUNU
链。
$ sudo iptables -t nat -L KUBE-SVC-TCOU7JCQXEZGVUNU Chain KUBE-SVC-TCOU7JCQXEZGVUNU (1 references) target prot opt source destination /* kube-system/kube-dns:dns */ KUBE-SEP-OCPCMVGPKTDWRD3C all -- anywhere anywhere statistic mode random probability 0.50000000000/* kube-system/kube-dns:dns */ KUBE-SEP-VFGOVXCRCJYSGAY3 all -- anywhere anywhere
在这里,我们看到一个有50%执行机会的链,和一个将执行其他情况的链。如果我们检查第一个链,我们会看到它路由到10.0.1.141
,这是我们两个CoreDNS pod的ip之一:
$ sudo iptables -t nat -L KUBE-SEP-OCPCMVGPKTDWRD3C Chain KUBE-SEP-OCPCMVGPKTDWRD3C (1 references) target prot opt source destination /* kube-system/kube-dns:dns */ KUBE-MARK-MASQ all -- 10.0.1.141 anywhere /* kube-system/kube-dns:dns */ udp to:10.0.1.141:53DNAT udp -- anywhere anywhere
ipvs Mode
ipvs
模式使用ipvs
,而不是iptables
来实现连接负载均衡。ipvs
模式支持六种负载均衡模式,使用--ipvs -scheduler
指定:
rr
:Round-robinlc
:east connectiondh
:Destination hashingsh
:Source hashingsed
:Shortest expected delaynq
:Never queue
缺省情况下,负载均衡模式为Round-robin (rr)
。它与iptables
模式的行为最接近(因为无论pod状态如何,连接都是相当均匀的),尽管iptables
模式实际上并不执行轮询路由。
kernelspace Mode
kernelspace
是最新的,只有windows的模式。它为Windows上的Kubernetes提供了一种userspace
模式的替代方案,因为iptables
和ipvs
是特定于Linux的。
NetworkPolicy
Kubernetes的默认行为是允许集群网络中任意两个pod之间的通信。这种行为是为了易于采用和配置的灵活性而精心设计的,但在实践中极不可取。允许任何系统建立(或接收)任意连接都会带来风险。攻击者可以探测系统,并可能利用捕获的凭据或发现削弱或丢失的身份验证。允许任意连接还可以更容易地通过受损的工作负载从系统中提取数据。总之,我们强烈反对在没有NetworkPolicy
的情况下运行真正的集群。由于所有pod都可以与所有其他pod通信,因此我们强烈建议应用程序所有者使用NetworkPolicy
对象以及其他应用层安全措施,如身份验证令牌或相互传输层安全(mTLS),用于任何网络通信。
NetworkPolicy
是Kubernetes中的一种资源类型,它包含基于允许的防火墙规则。用户可以添加NetworkPolicy
对象来限制与pod之间的连接。NetworkPolicy
资源充当CNI插件的配置,后者本身负责确保pod之间的连通性。Kubernetes API声明NetworkPolicy
支持对于CNI驱动是可选的,这意味着有些CNI驱动不支持网络策略,如表3所示。如果开发人员在使用不支持NetworkPolicy
对象的CNI驱动程序时创建了NetworkPolicy
,则不会影响pod的网络安全性。一些CNI驱动程序,如企业产品或公司内部的CNI驱动程序,可能会引入等价的NetworkPolicy
。一些CNI驱动程序对NetworkPolicy
规范的“解释”也可能略有不同。
| CNI plugin | NetworkPolicy supported |
|---|---|
| Calico | Yes, and supports additional plugin-specific policies |
| Cilium | Yes, and supports additional plugin-specific policies |
| Flannel | No |
| Kubenet | No |
示例4详细说明了NetworkPolicy
对象,该对象包含pod选择器、进入规则和出口规则。策略将应用于与匹配选择器标签的NetworkPolicy
相同名称空间中的所有pod。选择器标签的使用与其他Kubernetes api是一致的:规范通过它们的标签而不是它们的名称或父对象来标识pod。
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: demo namespace: default spec: podSelector: matchLabels: app: demo policyTypes: - Ingress - Egress ingress: []NetworkPolicyIngressRule # Not expanded egress: []NetworkPolicyEgressRule # Not expanded
在深入研究API之前,让我们先看一个创建NetworkPolicy
的简单示例,以减少某些pod的访问范围。让我们假设有两个不同的组件:demo
和demo- db
。由于我们在图7中没有现有的NetworkPolicy
,所有的pods可以与所有其他pods通信(包括假设不相关的pods,未显示)。
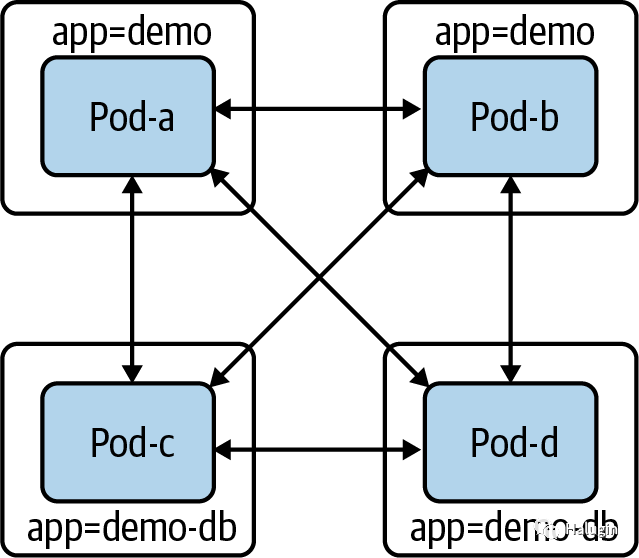
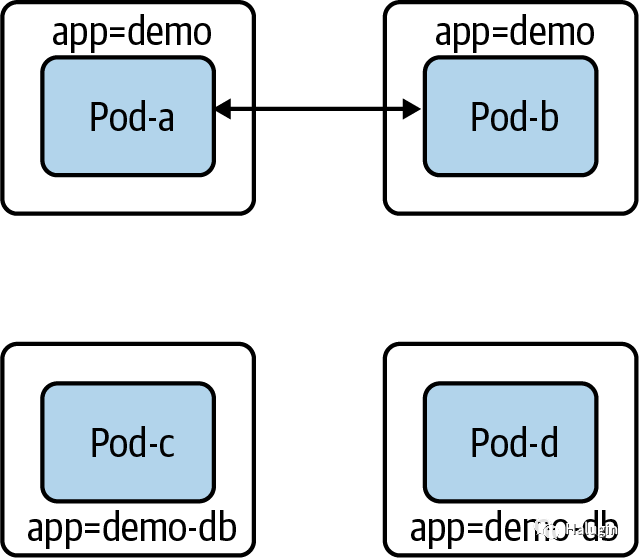
让我们限制demo-DB
的访问级别。如果我们创建了以下选择demo-DB
pod的NetworkPolicy
, demo-DB
pod将无法发送或接收任何流量:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: demo-db namespace: default spec: podSelector: matchLabels: app: demo-db policyTypes: - Ingress - Egress
在图8中,我们现在可以看到带有标签app=demo
的pods不再能够创建或接收连接。
对于大多数工作负载(包括我们的示例数据库)来说,没有网络访问是不可取的。我们的demo-db
应该(仅)能够接收来自demo
pod的连接。为此,我们必须在NetworkPolicy
中添加一个入口规则:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: demo-db namespace: default spec: podSelector: matchLabels: app: demo-db policyTypes: - Ingress - Egress ingress: - from: - podSelector: matchLabels: app: demo
现在,demo-db
pod只能接收来自demo
pod的连接。此外,demo-db
pod无法进行连接(如图9所示)。

NetworkPolicy示例:cilium
我们的Golang网络服务器现在连接到Postgres数据库,没有TLS。此外,如果没有NetworkPolicy
对象,网络上的任何pod都可以嗅探Golang web服务器和数据库之间的流量,这是一个潜在的安全风险。下面将部署Golang web应用程序及其数据库,然后部署NetworkPolicy
对象,该对象只允许从web服务器连接到数据库。使用与Cilium安装KIND集群,让我们使用以下YAML
和kubectl
命令部署Postgres数据库:
$ kubectl apply -f database.yaml service/postgres created configmap/postgres-config created statefulset.apps/postgres created
下面我们将web服务器作为Kubernetes部署到KIND集群中:
$ kubectl apply -f web.yaml deployment.apps/app created
为了在集群网络中运行连通性测试,我们将部署并使用dnsutils
pod,它拥有ping
和curl
等基本网络工具:
$ kubectl apply -f dnsutils.yaml pod/dnsutils created
由于我们没有部署带入口ingress的服务,我们可以使用kubectl port-forward
来测试到我们的web服务器的连通性:
kubectl port-forward app-5878d69796-j889q 8080:8080
现在从本地终端,我们可以到达我们的API:
$ curl localhost:8080/ Hello $ curl localhost:8080/healthz Healthy $ curl localhost:8080/data Database Connected
让我们测试从其他pod到集群内web服务器的连通性。为了做到这一点,我们需要获得web服务器pod的IP地址:
$ kubectl get pods -l app=app -o wide NAME READY STATUS RESTARTS AGE IP NODE app-5878d69796-j889q 1/1 Running 0 87m 10.244.1.188 kind-worker3
现在我们可以测试L4和L7从dnsutils
pod到网络服务器的连通性
$ kubectl exec dnsutils -- nc -z -vv 10.244.1.188 808010.244.1.188 (10.244.1.188:8080) open sent 0, rcvd 0
从我们的dnsutils
,我们可以测试第7层HTTP API访问:
$ kubectl exec dnsutils -- wget -qO- 10.244.1.188:8080/ Hello $ kubectl exec dnsutils -- wget -qO- 10.244.1.188:8080/data Database Connected $ kubectl exec dnsutils -- wget -qO- 10.244.1.188:8080/healthz Healthy
我们还可以在数据库pod上进行测试。首先,我们必须检索数据库pod的IP地址10.244.2.189
。我们可以使用kubectl
与标签和选项的组合来获得这些信息:
$ kubectl get pods -l app=postgres -o wide NAME READY STATUS RESTARTS AGE IP NODE postgres-0 1/1 Running 0 98m 10.244.2.189 kind-worker
同样,让我们使用dnsutils
pod来测试通过默认端口5432到Postgres数据库的连通性:
$ kubectl exec dnsutils -- nc -z -vv 10.244.2.189 543210.244.2.189 (10.244.2.189:5432) open sent 0, rcvd 0
该端口对所有人开放,因为没有适当的网络策略。现在让我们用cilium网络策略来限制它。下面的命令部署网络策略,以便我们可以测试安全的网络连通性。让我们首先将对数据库pod的访问限制为仅对web服务器。应用网络策略,只允许从web服务器pod到数据库的流量:
$ kubectl apply -f layer_3_net_pol.yaml ciliumnetworkpolicy.cilium.io/l3-rule-app-to-db created
Cilium部署Cilium对象创建的资源可以像kubectl
的pod一样被回收。使用kubectl describe ciliumnetworkpolicy.cilium.io l3-rule-app-to-db
,我们可以看到关于通过YAML部署的规则的所有信息:
$ kubectl describe ciliumnetworkpolicies.cilium.io l3-rule-app-to-db Name: l3-rule-app-to-db Namespace: default Labels: <none> Annotations: API Version: cilium.io/v2 Kind: CiliumNetworkPolicy Metadata: Creation Timestamp: 2021-01-10T01:06:13Z Generation: 1Managed Fields: API Version: cilium.io/v2 Fields Type: FieldsV1 fieldsV1: f:metadata: f:annotations: .: f:kubectl.kubernetes.io/last-applied-configuration: f:spec: .: f:endpointSelector: .: f:matchLabels: .: f:app: f:ingress: Manager: kubectl Operation: Update Time: 2021-01-10T01:06:13Z Resource Version: 47377Self Link: /apis/cilium.io/v2/namespaces/default/ciliumnetworkpolicies/l3-rule-app-to-db UID: 71ee6571-9551-449d-8f3e-c177becda35a Spec: Endpoint Selector: Match Labels: App: postgres Ingress: From Endpoints: Match Labels: App: app Events: <none>
由于网络策略的应用,dnsutils
pod不能再到达数据库pod;我们可以在试图从dnsutils
pod到达DB端口的超时时间中看到:
$ kubectl exec dnsutils -- nc -z -vv -w 5 10.244.2.189 5432nc: 10.244.2.189 (10.244.2.189:5432): Operation timed out sent 0, rcvd 0command terminated with exit code 1
当web服务器pod仍然连接到数据库pod时,/data
路由将web服务器连接到数据库,并且NetworkPolicy
允许这样做:
$ kubectl exec dnsutils -- wget -qO- 10.244.1.188:8080/data Database Connected $ curl localhost:8080/data Database Connected
现在让我们应用L7的策略。cilium是第7层感知的,因此我们可以阻止或允许HTTP URI路径上的特定请求。在我们的示例策略中,我们允许在/
和/data
上启用HTTP GETs,但不允许在/healthz
上启用它们;让我们进行测试:
$ kubectl apply -f layer_7_netpol.yml ciliumnetworkpolicy.cilium.io/l7-rule created
我们可以看到策略的应用就像API中的其他Kubernetes对象一样:
$ kubectl get ciliumnetworkpolicies.cilium.io NAME AGE l7-rule 6m54s $ kubectl describe ciliumnetworkpolicies.cilium.io l7-rule Name: l7-rule Namespace: default Labels: <none> Annotations: API Version: cilium.io/v2 Kind: CiliumNetworkPolicy Metadata: Creation Timestamp: 2021-01-10T00:49:34Z Generation: 1 Managed Fields: API Version: cilium.io/v2 Fields Type: FieldsV1 fieldsV1: f:metadata: f:annotations: .: f:kubectl.kubernetes.io/last-applied-configuration: f:spec: .: f:egress: f:endpointSelector: .: f:matchLabels: .: f:app: Manager: kubectl Operation: Update Time: 2021-01-10T00:49:34Z Resource Version: 43869 Self Link:/apis/cilium.io/v2/namespaces/default/ciliumnetworkpolicies/l7-rule UID: 0162c16e-dd55-4020-83b9-464bb625b164 Spec: Egress: To Ports: Ports: Port: 8080 Protocol: TCP Rules: Http: Method: GET Path: / Method: GET Path: /data Endpoint Selector: Match Labels: App: app Events: <none>
正如我们所看到的,/
和/data
是可用的,但/healthz
是不可用的,这正是我们对NetworkPolicy
的期望:
$ kubectl exec dnsutils -- wget -qO- 10.244.1.188:8080/data Database Connected$kubectl exec dnsutils -- wget -qO- 10.244.1.188:8080/ Hello $ kubectl exec dnsutils -- wget -qO- -T 5 10.244.1.188:8080/healthz wget: error getting response command terminated with exit code 1
这些小示例展示了Cilium网络策略在集群内加强网络安全方面的强大功能。强烈建议管理员选择支持网络策略的CNI,并强制开发人员使用网络策略。网络策略是有命名空间的,如果团队有类似的设置,集群管理员可以并且应该强制开发人员定义网络策略以增加安全性。
Selecting Pods
pod是不受限制的,直到它们被NetworkPolicy
选中。如果选中,CNI插件只在匹配规则允许的情况下允许pod进入或退出。NetworkPolicy
有一个spec.policyTypes
字段,该字段包含策略类型列表(ingress或engress)。例如,如果我们选择一个带有NetworkPolicy
的pod,它列出了入口但没有列出出口,那么入口将被限制,而出口将不被限制。
spec.podselector
字段将指定对哪些pod应用NetworkPolicy
。空label selector.(podSelector:{})
将选择命名空间中的所有pod。
NetworkPolicy
对象是具有名称空间的对象,这意味着它们存在于特定的名称空间中并应用于该名称空间。spec.podselector
字段只能在pod与NetworkPolicy
位于同一命名空间时选择它们。这意味着选择app: demo
将只应用于当前名称空间,而其他名称空间中带有app: demo
标签的任何pod将不受影响。
有多种方法可以实现默认防火墙行为,包括以下几种:
- 为每个名称空间创建一个拒绝所有的
NetworkPolicy
对象,这将要求开发人员添加额外的NetworkPolicy
对象来允许所需的流量。 - 添加一个定制的CNI插件,故意违反默认打开API的行为。多个CNI插件有一个额外的配置来公开这种行为。
- 创建允许策略以要求工作负载具有
NetworkPolicy
。
DNS
DNS是任何网络基础设施的关键部分,让我们讨论一下DNS在Kubernetes内部是如何工作的。
KubeDNS在Kubernetes的早期版本中使用。KubeDNS在一个pod中有几个容器:kube-dns
、dnsmasq
和sidecar
。kube-dns
容器监视Kubernetes API并基于Kubernetes DNS规范提供DNS记录,dnsmasq
提供缓存和存根域支持,sidecar
提供度量和健康检查。Kubernetes 1.13之后的版本现在使用单独的CoreDNS组件。
在CoreDNS和KubeDNS之间有几个区别:
- 为了简单起见,CoreDNS作为单个容器运行。
- CoreDNS是一个Go过程,复制并增强了Kube-DNS的功能。
- CoreDNS被设计成一个通用的DNS服务器,向后兼容Kubernetes,它的可扩展插件可以做的比Kubernetes DNS规范中提供的更多。
CoreDNS组件如图10所示。它运行一个默认副本为2的部署,为了运行它,CoreDNS需要访问API服务器,一个ConfigMap来保存它的Corefile,一个服务来使DNS对集群可用,以及一个部署来启动和管理它的pod。所有这些也与集群中的其他关键组件一起运行在kube-system
名称空间中。
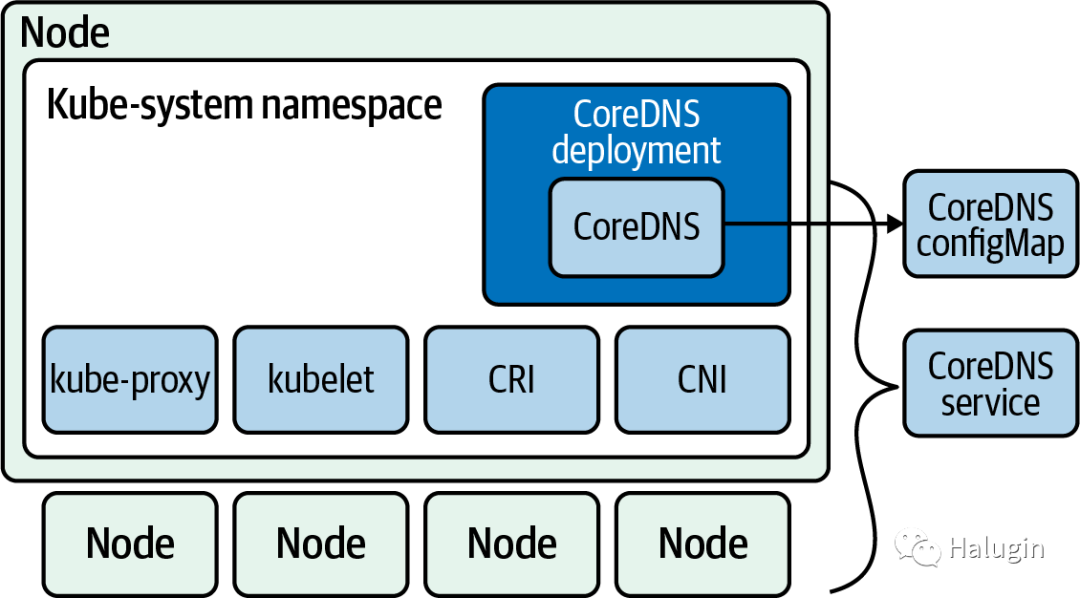
与大多数配置选项一样,pod如何进行DNS查询在pod规范的dnpolicy
属性中。
在示例5中,pod规范将ClusterFirstWithHostNet
作为dnpolicy
。
apiVersion: v1 kind: Pod metadata: name: busybox namespace: default spec: containers: - image: busybox:1.28 command: - sleep - "3600" imagePullPolicy: IfNotPresent name: busybox restartPolicy: Always hostNetwork: true dnsPolicy: ClusterFirstWithHostNet
dnpolicy
有四个选项,它们会显著影响DNS解析在pod中的工作方式:
Default
:pod从运行pod的节点继承名称解析配置。ClusterFirst
:任何与集群域名后缀不匹配的DNS查询,如www.kubernetes.io,都被发送到从该节点继承的上游名称服务器。ClusterFirstWithHostNet
:对于使用hostNetwork
运行的pod,管理员应该将DNS策略设置为ClusterFirstWithHostNet
。None
:所有DNS设置都使用pod规范中的dnsConfig
字段。
如果设置为None
,开发人员将必须在pod规范中指定名称服务器(nameservers:
)。最多可以指定3个IP地址。是用于在pod中查找主机名的DNS搜索域的列表。Kubernetes最多允许6个搜索域。
apiVersion: v1 kind: Pod metadata: namespace: default name: busybox spec: containers: - image: busybox:1.28 command: - sleep - "3600" imagePullPolicy: IfNotPresent name: busybox dnsPolicy: "None" dnsConfig: nameservers: - 1.1.1.1 searches: - ns1.svc.cluster-domain.example - my.dns.search.suffix
其他的在options
字段中,这是一个对象列表,其中每个对象可能有一个name
属性和一个value
属性(可选)。
所有这些生成的属性都与DNS策略中的resolv.conf
合并。常规查询选项有CoreDNS通过以下搜索路径:
<service>.default.svc.cluster.local ↓ svc.cluster.local ↓ cluster.local ↓ The host search path
主机搜索路径来自pod DNS策略或CoreDNS策略。
在Kubernetes中查询DNS记录会导致许多请求,并增加等待DNS请求的应用程序的延迟。CoreDNS有一个解决方案叫做Autopath。Autopath允许服务器端搜索路径完成。通过剥离集群搜索域,在CoreDNS服务器上进行查找,缩短了客户端搜索路径解析;当它找到一个答案时,它将结果存储为CNAME并返回一个查询,而不是五个。
然而,使用Autopath确实会增加CoreDNS上的内存使用量。确保根据集群的大小扩展CoreDNS副本的内存。请确保为CoreDNS pod设置适当的内存和CPU请求。为了监控CoreDNS,它导出了它公开的几个指标:
- coredns build info
- dns request count total
- dns request duration seconds
- dns request size bytes
- coredns plugin enabled
通过结合pod指标和CoreDNS指标,插件管理员将确保CoreDNS保持健康并在集群中运行。
总结
Kubernetes网络模型是网络如何在集群中工作的基础。在节点上运行的CNI实现了Kubernetes网络模型中提出的原则。该模型没有定义网络安全;Kubernetes的可扩展性使得CNI可以通过网络策略实现网络安全。
选择正确的CNI需要从开发人员和管理员的角度进行评估。需要列出要求并测试CNIs。如果不讨论网络安全和支持它的CNI,集群是不完整的。
DNS是至关重要的;一个完整的设置和一个平稳运行的网络需要网络和集群管理员能够熟练地在他们的集群中扩展CoreDNS。异常数量的Kubernetes问题源于DNS和CoreDNS的错误配置。
感兴趣的关注如下公众号!

