




Kubernetes网络之三:容器网络基础
前两篇文章谈论了网络基础知识和Linux网络,本文我们讨论下如何在容器中实现网络。和网络历程一样,容器也有很长的发展历程。本文讨论运行容器的各种选项,以及可用的网络设置。目前,业界已经确定Docker作为容器运行时标准。在此基础上,我们将深入研究Docker网络模型,以及容器网络接口与Docker网络模型的不同之处,并以使用Docker容器的网络模式的示例结束本文。
容器简介
应用程序(Application)
运行应用程序总是有它的挑战。现在有许多方法可以为应用程序提供服务,包括云计算、on-prem,还有容器。库的版本、共享驱动器、部署和应用程序本身的版本只是其中的几个问题。在很长一段时间里,应用程序开发人员不得不处理这些问题。Bash脚本、部署工具都有各自的缺点和问题。每个新公司都有自己部署应用程序的方式,所以每个新开发人员都必须学习这些。职责分离、权限控制、维护系统稳定性,要求系统管理员限制开发人员的部署访问。系统管理员还管理同一主机上的多个应用程序,以提高该主机的效率。这样就在想要部署新特性的开发人员和想要维护整个生态系统稳定性的系统管理员之间产生了矛盾。
通用操作系统支持尽可能多的应用程序类型,因此它的内核包括所有类型的驱动程序、协议库和调度器。图1显示了一台机器,一个操作系统,但是有许多方法可以将应用程序部署到该主机上。应用程序部署是任何企业都试图解决的问题。

从网络的角度来看,对于一个操作系统,就有一个TCP/IP堆栈。这个堆栈会在主机上产生端口冲突的问题。系统管理员在同一台机器上托管多个应用程序,以提高机器的利用率,并且每个应用程序都必须在其端口上运行。因此,现在,系统管理员、应用程序开发人员和网络工程师必须协调所有这些工作。还要向部署清单、故障排除指南和所有IT请求中添加一个任务。管理程序成为一种提高一台主机的效率并消除一个操作系统和网络堆栈问题的方法。
Hypervisor
Hypervisor从主机模拟硬件资源、CPU、内存,以创建客户操作系统或虚拟机。2001年,VMware发布了x86 Hypervisor。2003年,第一个开源Hypervisor Xen发布了,2006年,基于内核的虚拟机KVM发布了。Hypervisor允许系统管理员与多个客户操作系统共享底层硬件;图2演示了这一点。这种资源共享提高了主机的效率。
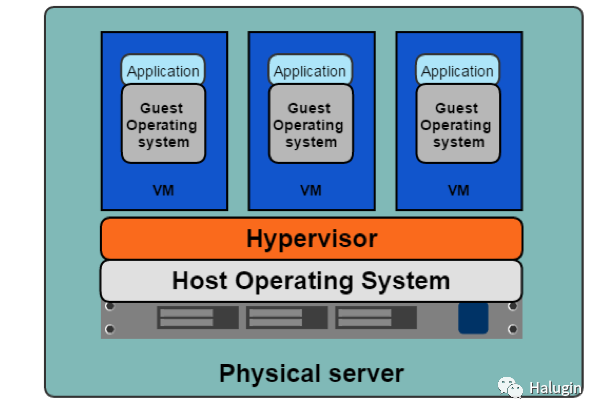
Hypervisor还为每个应用程序开发团队提供了一个独立的网络堆栈,消除了共享系统上的端口冲突问题。团队A的Tomcat应用程序可以在端口8080上运行,而团队B的Tomcat应用程序也可以在端口8080上运行,因为每个应用程序现在都可以拥有其带有独立网络堆栈的客户操作系统。对于应用程序开发人员来说,库版本、部署和其他问题仍然存在。他们如何在保持Hypervisor和Virtual Machines带来的效率的同时打包和部署应用程序所需的一切?这促进了container的发展。
容器(Containers)
在图3中,我们可以看到应用程序容器化的好处;每个容器都是独立的。应用程序开发人员可以使用任何他们需要的东西来运行他们的应用程序,而不需要依赖底层库或宿主操作系统。每个容器也有它的网络堆栈。容器允许开发人员打包和部署他们的应用程序,同时保持主机的效率。
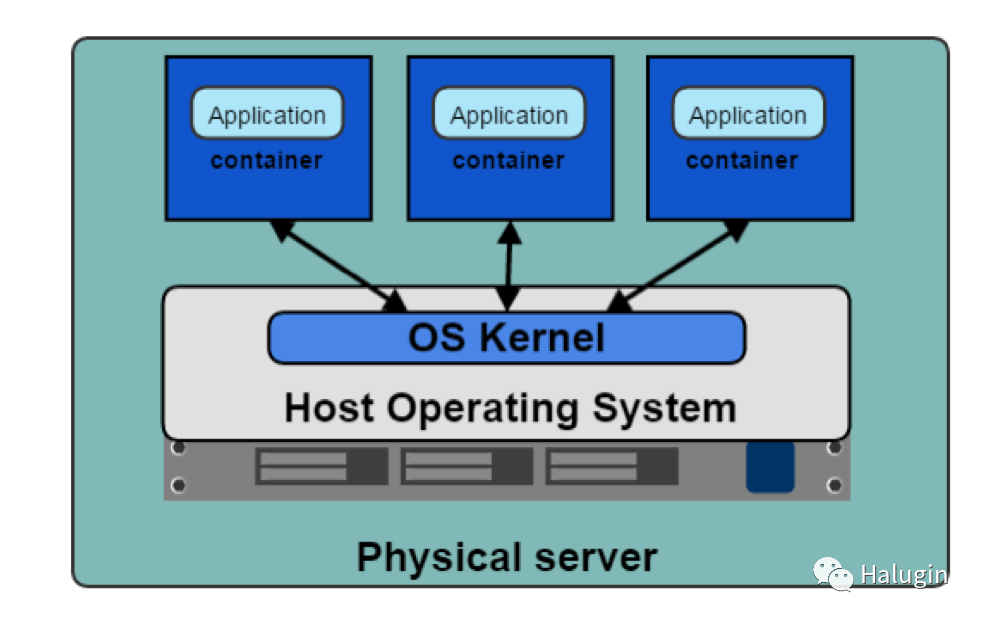
以下为容器的一些术语:
Container
正在运行的容器镜像。
Image
容器镜像是在启动容器时从Registry Server下拉并在本地用作挂载点的文件。
Container Engine
容器引擎是接受用户请求、命令行选项、提取图像并从终端用户的角度运行容器的软件部分。
Container Runtime
容器运行时是容器引擎中处理容器运行的底层软件。
Base Image
容器镜像的起点,为了减少构建镜像的大小和复杂性,用户可以从基本镜像开始,并在其上进行增量更改。
Image Layer
存储库通常被称为图像或容器图像,但实际上它们是由一个或多个层组成的。存储库中的图像层以父子关系连接在一起。每个图像层表示其自身和父层之间的变化。
Image Format
容器引擎有自己的容器格式、LXD、RKT和Docker。
Registry
Registry存储容器镜像,并允许用户上传、下载和更新容器镜像。
Repository
存储库可以等同于容器镜像。重要的区别是,存储库由关于图像的层和元数据组成,即清单。
Tag
标签是容器镜像不同版本的用户定义的名称。
Container Host
容器主机是使用容器引擎运行容器的系统。
Container Orchestration
这就是Kubernetes的功能,它为容器主机集群动态调度容器工作负载。
低级别功能的一个例子是为容器创建cgroups和命名空间,这是运行一个容器的最低要求。开发人员在使用容器时需要的不止这些。他们需要构建、测试和部署容器;这些被认为是高级别功能。每个容器运行时都提供不同级别的功能。下面是高功能和低功能的列表。
低级别容器运行功能:
- Creating containers
- Running containers
高级别容器运行功能:
- Container image format
- Building container images
- Managing container images
- Managing instances of containers
- Sharing container images
低级别的容器运行时:
- lxc-用于创建Linux容器的API
- runc-符合oci的容器的cli
高级别的容器运行时:
- containerd-容器运行时从Docker中分离出来,这是一个云原生计算基金会(CNCF)项目
- cri-o.-容器运行时接口使用开放容器OCI规范,孵化的CNCF项目
- Docker-开源容器平台
- lmctfy-谷歌容器化化平台
- rkt-CoreOs容器规范
OCI
开放容器标准(OCI)促进通用的、最小的、开放的容器技术标准和规范。
为容器镜像格式和运行时创建正式规范的想法允许容器可以跨所有主要操作系统和平台移植,以确保没有不必要的技术障碍。OCI的三个价值观是:
Composable
管理容器的工具应该有纯净的接口。它们也不应该被绑定到特定的项目、客户端或框架上,并且可以跨所有平台工作。
Decentralized
格式和运行时应该由社区(而不是一个组织)指定和开发,OCI项目的另一个目标是运行相同容器的工具的独立实现。
Minimalist
OCI规范努力做好几件事,做到最小和稳定,并支持创新和实验。
让我们看下几个早期的容器计划及其功能。
lxc
Linux容器(LXC)创建于2008年。LXC结合了cgroup和名称空间,为运行应用程序提供了一个独立的环境。LXC的目标是创建一个尽可能接近标准Linux的环境,而不需要单独的内核。LXC有独立的组件;liblxc库、几种编程语言绑定、python3/2、Lua、Go、Ruby、Haskell、一套标准工具和容器模板。
runc
Runc是最广泛使用的容器运行时,最初是作为Docker的一部分开发的,后来被提取为一个单独的工具和库。Runc是一个命令行工具,用于运行按照开放容器标准(Open Container Initiative)的OCI格式打包的应用程序,并且是符合OCI规范的实现。Runc使用libcontainer,这是驱动Docker引擎安装的同一个容器库。在版本1.11之前,Docker引擎用于管理卷、网络、容器、镜像等。现在,Docker架构有几个组件,runc特性包括:
- 完全支持Linux命名空间,包括用户命名空间
- Linux中所有可用的安全特性的原生支持:SELinux, Apparmor, seccomp, control groups, capability drop, pivot_root, uid/gid drop,等等
- 计划对整个硬件制造商生态系统的原生支持
- Windows 10容器的原生支持
- 一种正式指定的配置格式,由Linux基金会下的开放容器计划管理。
containerd
Containerd是从Docker中分离出来的高级运行时。Containerd是一个后台服务,充当各种容器运行时和操作系统的API。Containerd有各种提供高级功能的组件。Containerd是一个用于Linux和Windows的服务,它管理宿主系统的完整容器生命周期、镜像传输、存储、容器执行和网络连接。Containerd的客户端CLI工具是ctr
,它是用于开发和调试的,可以直接与Containerd通信。Containerd-shim是无守护容器的组件。它作为容器进程的父进程存在。Containerd允许运行时,即runc,在它启动容器后退出。这样,我们就不必为容器使用长时间运行的运行时流程。如果容器和Docker停止,它也会为容器保留标准的io和其他文件描述符。如果shim不运行,那么管道的父端将被关闭,容器将退出。Containerd-shim还允许容器的退出状态被报告回更高级别的工具,如Docker,而不需要容器的进程的实际父进程和await。
lmctfy
谷歌在2013年开始将lmctfy作为其开源Linux容器技术。Lmctfy是一个高级容器运行时,它提供了容器的创建和删除功能,但已不被积极维护,最后还被移植到libcontainer。Lmctfy提供了一个API驱动的配置,开发人员不必担心cgroups和内部命名空间的细节。
rkt
Rkt于2014年在CoreOS作为Docker的替代。它是用Go编写的,使用pod作为基本计算单元,并允许为应用程序提供一个自包含的环境。rkt的原生图像格式是应用容器图像(ACI),在应用容器规范中定义;为了支持OCI格式和规范支持,这种方式已被弃用。它支持CNI规范,可以运行Docker镜像和OCI镜像。
docker
Docker于2013年发布,解决了开发人员在端到端运行容器时遇到的许多问题。它为开发人员提供了创建、维护和部署容器的所有功能:
- Container image format
- Building container images
- Managing container images
- Managing instances of containers
- Sharing container images
- Running containers
图4向我们展示了Docker引擎及其各个组件的架构。Docker最初是一个整体应用程序,将上述所有功能构建到一个称为Docker引擎的二进制文件中。该引擎包含docker客户端或CLI,允许开发人员构建、运行和推送容器和镜像。Docker服务器作为守护进程运行,管理运行容器的数据卷和网络。客户端通过docker API与服务器通信。Containerd来管理容器的生命周期,然后runC来生成容器进程。
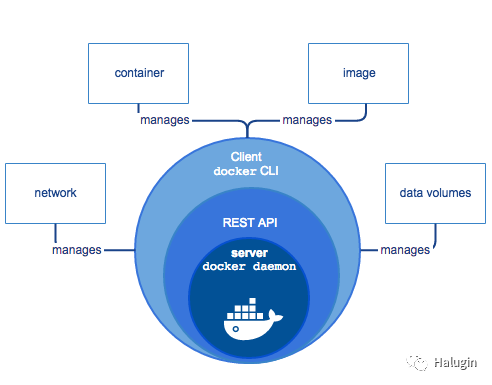
在过去的几年里,Docker已经将这个庞然大物分解成多个独立的组件。为了运行容器,Docker引擎创建镜像,并将其传递给containerd。Containerd调用使用runC运行容器的Containerd -shim。然后,containerd-shim允许在启动容器后退出运行时通过这种方式,我们可以运行无守护进程的容器,因为我们不必为容器使用长时间运行的运行时进程。
Docker为应用程序开发人员和系统管理员提供了关注点的分离。它允许开发者专注于构建他们的应用程序,而系统管理员专注于部署。Docker提供了一个快速的开发周期。Docker提供了在本地、云或任何其他数据中心之间运行的应用程序可移植性。他们的座右铭是“Build, ship, run anywhere”。一个新的容器可以快速提供可伸缩性,并在一台主机上运行更多的应用程序,从而提高机器的效率。
CRI-O
CRI-O是Kubernetes容器运行时接口的基于OCI的实现,而OCI是容器运行时引擎必须实现的一组规范。Redhat于2016年启动了容器运行时接口(CRI)项目,并于2019年向CNCF做出了贡献。CRI是一个插件接口,允许Kubernetes通过kubelet与任何满足CRI接口的容器运行时通信。在Kubernetes项目引入CRI之后,CRI-O于2016年开发,2017年发布了CRI-O 1.0。CRI-O是一个轻量级的CRI运行时,作为Kubernetes特定的高级运行时,构建在gRPC和Protobuf之上,通过Unix套接字。图5指出了CRI在Kubernetes架构中的位置。
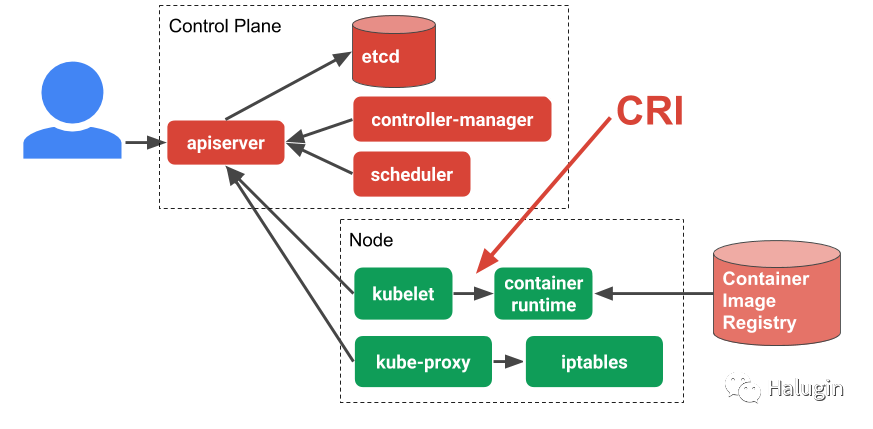
在容器领域已经有许多公司、技术和创新。行业已经开始确保容器世界保持开放,OCI项目,让所有人以各种方式运行容器。Kubernetes还通过对CRI-O接口的适应帮助形成了这种规范。理解容器的组件对于所有容器部署管理员和使用容器的开发人员都是至关重要的。
Container Primitives
无论是使用Docker还是containerd, runc都会启动并管理它们的运行容器。我们从容器的角度看runc为开发人员所做的工作。我们的每个容器都有称为控制组和命名空间的Linux原语。图6展示了一个这样的示例,cgroups控制对内核中容器资源的访问,而名称空间是与根名称空间(即主机)分开管理的。

Control Groups(CGroups)
cgroups是Linux内核的一个特性,它限制、隔离资源使用。最初在Linux 2.6.24中发布,cgroups允许管理员控制不同的CPU系统和特定进程的内存。Cgroups是通过伪文件系统提供的,并在cgroupfs的核心内核代码中进行维护。在下面列出的内核中,不同的子系统维护不同的CGroups。
- CPU-保证进程的CPU共享数量
- memory-为进程设置内存限制
- disk I/O-其他设备通过设备组子系统进行控制
- network-为进程设置网络限制
lscgroup
是一个命令行工具,它列出当前系统中所有的cgroup。
[root@node02 ~]# lscgroup | morenet_cls,net_prio:/ net_cls,net_prio:/docker net_cls,net_prio:/docker/43704ddedd1966e3563ec1af9c5ea2444156c0e0947b1de4a1ffc705c4fd5a0b net_cls,net_prio:/docker/2f348273b032b84019c84e41fdf0512448d36eb70347559e6969287e8d5a26cb pids:/ pids:/docker pids:/docker/43704ddedd1966e3563ec1af9c5ea2444156c0e0947b1de4a1ffc705c4fd5a0b pids:/docker/2f348273b032b84019c84e41fdf0512448d36eb70347559e6969287e8d5a26cb pids:/system.slice pids:/system.slice/AssistDaemon.service pids:/system.slice/nginx.service pids:/system.slice/crond.service pids:/system.slice/run-docker-netns-0b9e5edbf5f8.mount pids:/system.slice/var-lib-docker-overlay2-533ec820b25ff1827909592d14f8bb7a60dee5e9282620a76e4cacad9c94b101-merged.mount ......
Runc会在创建时为容器创建cgroups。Cgroup控制容器可以使用多少资源,而名称空间控制容器内的进程可以看到什么。
Namespaces
名称空间是Linux内核的一个特性,它隔离和虚拟化一组进程的系统资源。虚拟化资源如下:
- PID namespace:进程ID,用于进程隔离。
- net namespace:管理网络接口和单独的网络堆栈。
- IPC namespace:管理进程间通信(IPC)资源的访问。
- mnt namespace:管理文件系统挂载点。
- uts namespace:UNIX分时,允许单个主机对不同的进程有不同的主机和域名。
- uid namespaces:通过单独的用户和组分配来隔离进程所有权。
在用户名称空间内部和外部,进程的用户和组id可以是不同的。进程可以在用户名称空间外部具有非特权用户ID,同时在容器用户名称空间内部具有用户ID为0的用户ID。进程具有在用户名称空间内执行的根特权,但对名称空间外的操作没有特权。
下面是一个如何检查进程名称空间的示例。在Linux中,进程的所有信息都在/proc文件系统中。PID 1的PID名称空间是4026531836
,列出了PID名称空间id匹配的所有名称空间。
[root@node02 ~]# ps -p 1 -o pid,pidns PID PIDNS 1 4026531836[root@node02 ~]# ls -l proc/1/ns总用量 0lrwxrwxrwx 1 root root 0 9月 2 09:58 ipc -> ipc:[4026531839] lrwxrwxrwx 1 root root 0 9月 2 09:58 mnt -> mnt:[4026531840] lrwxrwxrwx 1 root root 0 9月 2 09:58 net -> net:[4026531956] lrwxrwxrwx 1 root root 0 9月 2 09:58 pid -> pid:[4026531836] lrwxrwxrwx 1 root root 0 9月 2 09:58 user -> user:[4026531837] lrwxrwxrwx 1 root root 0 9月 2 09:58 uts -> uts:[4026531838]
图7显示了这两个Linux原语有效地允许应用程序开发人员控制和管理他们的应用程序独立于主机和其他应用程序(无论是在容器中还是在主机上本机运行)。

Setting up Namespaces
容器基本组网如图8所示。接下来,我们将介绍底层运行时为创建容器网络的所有Linux命令。
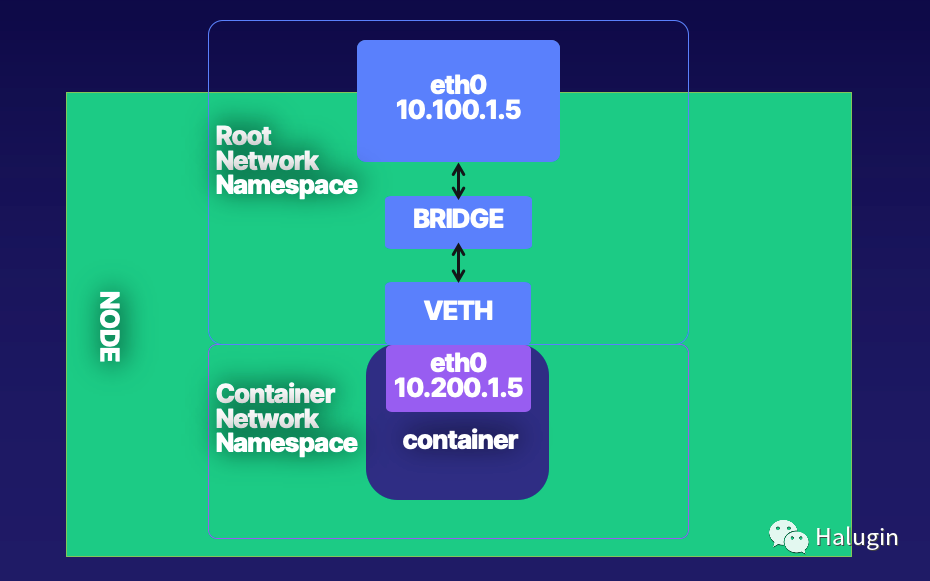
具体步骤如下:
- Create a host with a root network namespace.
- Create a new network namespace.
- Create a veth pair.
- Move one side of the veth pair into a new network namespace.
- Address side of the veth pair inside the new network namespace.
- Create a bridge interface.
- Address bridge interface.
- Attach bridge to the host interface.
- Attach one side of the veth pair to the bridge interface.
- Profit.
下面是创建网络名称空间、网桥、veth对并将它们连接在一起所需的所有Linux命令:
[root@node02 ~]# echo 1 > /proc/sys/net/ipv4/ip_forward[root@node02 ~]# sudo ip netns add net1[root@node02 ~]# sudo ip link add veth0 type veth peer name veth1[root@node02 ~]# sudo ip link set veth1 netns net1[root@node02 ~]# sudo ip link add veth0 type veth peer name veth1[root@node02 ~]# sudo ip netns exec net1 ip addr add 192.168.1.101/24 dev veth1[root@node02 ~]# sudo ip netns exec net1 ip link set dev veth1 up[root@node02 ~]# sudo ip link add br0 type bridge[root@node02 ~]# sudo ip link set dev br0 up[root@node02 ~]# sudo ip link set eth1 master br0[root@node02 ~]# sudo ip link set veth0 master br0[root@node02 ~]# sudo ip netns exec net1 ip route add default via 192.168.1.100
ip_forward
是操作系统的一种能力,它可以在一个接口上接收传入的网络包,将它们识别为另一个接口,并相应地将它们传递到该网络。当启用时,“IP转发”允许Linux机器接收并转发传入的数据包。默认情况下,它是关闭的;让我们在主机中启用它。
[root@localhost network-scripts]# sysctl net.ipv4.ip_forwardnet.ipv4.ip_forward = 0[root@localhost network-scripts]# echo 1 > /proc/sys/net/ipv4/ip_forward[root@localhost network-scripts]# sysctl net.ipv4.ip_forwardnet.ipv4.ip_forward = 1
在示例主机中,可以看到现在没有任何额外的网络名称空间,所以我们可以创建一个:
ip netns
允许我们控制服务器上的名称空间。创建一个非常简单,输入ip netns add net1
即可。
[root@zhangge ~]# ip netns list[root@zhangge ~]# ip netns add net1[root@zhangge ~]# ip netns listnet1
现在容器有了新的网络名称空间,需要一个veth对来在根网络名称空间和容器网络名称空间net1之间进行通信。
使用ip
命令创建veth对。veth成对出现,充当网络名称空间之间的管道,从一端发送的数据包自动转发到另一端。
[root@zhangge ~]# ip link add veth0 type veth peer name veth1
ip link list
命令用来验证是否创建了veth对。
[root@zhangge ~]# ip link list1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:002: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:ad:f0:f5 brd ff:ff:ff:ff:ff:ff3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:ad:f0:15 brd ff:ff:ff:ff:ff:ff4: eth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:ad:f0:25 brd ff:ff:ff:ff:ff:ff7: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether ee:bd:c4:32:78:88 brd ff:ff:ff:ff:ff:ff8: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 26:97:c8:24:8e:7a brd ff:ff:ff:ff:ff:ff
现在让我们将veth1移动到前面创建的新网络名称空间中。
[root@zhangge ~]# ip link set veth1 netns net1
ip netns exec
命令。Netns exec允许验证网络名称空间的配置。输出验证veth1现在在网络名称空间net中。
[root@zhangge ~]# ip netns exec net1 ip link list1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:007: veth1@if8: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether ee:bd:c4:32:78:88 brd ff:ff:ff:ff:ff:ff link-netnsid 0
在Linux内核中,网络名称空间是完全独立的TCP/IP堆栈。作为一个新的接口和一个新的网络名称空间,veth接口需要IP寻址,以便将数据包从net1名称空间传送到根名称空间和主机之外。
[root@zhangge ~]# ip netns exec net1 ip addr add 192.168.1.100/24 dev veth1
与主机网络接口一样,它们需要开启。
[root@zhangge ~]# ip netns exec net1 ip link set dev veth1 up
状态现在已经转换为LOWERLAYERDOWN
。状态为NO-CARRIER
。以太网需要一根电缆连接;我们的上游veth对也还没有启动。veth1接口已启动并被处理,但实际上仍然“未插电”。
[root@zhangge ~]# ip netns exec net1 ip link list veth17: veth1@if8: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state LOWERLAYERDOWN mode DEFAULT group default qlen 1000 link/ether ee:bd:c4:32:78:88 brd ff:ff:ff:ff:ff:ff link-netnsid 0
现在启动veth0:
[root@zhangge ~]# ip link set dev veth0 up[root@zhangge ~]# ip link list1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:002: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:ad:f0:f5 brd ff:ff:ff:ff:ff:ff3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:ad:f0:15 brd ff:ff:ff:ff:ff:ff4: eth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:ad:f0:25 brd ff:ff:ff:ff:ff:ff8: veth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether 26:97:c8:24:8e:7a brd ff:ff:ff:ff:ff:ff link-netnsid 0
现在,net1命名空间内的veth对是up
状态。
[root@zhangge ~]# ip netns exec net1 ip link list1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:007: veth1@if8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether ee:bd:c4:32:78:88 brd ff:ff:ff:ff:ff:ff link-netnsid 0
我们需要将根名称空间veth端连接到桥接接口。
[root@zhangge ~]# ip link add br0 type bridge[root@zhangge ~]# ip link set dev br0 up[root@zhangge ~]# ip link set eth1 master br0[root@zhangge ~]# ip link set veth0 master br0
我们可以看到eth1和veth0是桥接br0接口的一部分,主br0状态为up
。
接下来,我们测试到网络名称空间的连通性。
[root@zhangge ~]# ping 192.168.1.100 -c 4PING 192.168.1.100 (192.168.1.100) 56(84) bytes of data. From 192.168.1.10 icmp_seq=1 Destination Host Unreachable From 192.168.1.10 icmp_seq=2 Destination Host Unreachable From 192.168.1.10 icmp_seq=3 Destination Host Unreachable From 192.168.1.10 icmp_seq=4 Destination Host Unreachable --- 192.168.1.100 ping statistics ---4 packets transmitted, 0 received, +4 errors, 100% packet loss, time 6043ms
我们新的网络名称空间没有默认路由,因此它不知道将ping请求的包路由到哪里。添加路由如下:
[root@zhangge ~]$ ip netns exec net1 ip route add default via 192.168.1.100[root@zhangge ~]$ ip netns exec net1 ip route default via 192.168.1.100 dev veth1192.168.1.0/24 dev veth1 proto kernel scope link src 192.168.1.100
重新ping
一下:
[root@zhangge ~]$ ping 192.168.1.100 -c 4PING 192.168.2.100 (192.168.1.100) 56(84) bytes of data.64 bytes from 192.168.1.100: icmp_seq=1 ttl=64 time=0.018 ms64 bytes from 192.168.1.100: icmp_seq=2 ttl=64 time=0.028 ms64 bytes from 192.168.1.100: icmp_seq=3 ttl=64 time=0.036 ms64 bytes from 192.168.1.100: icmp_seq=4 ttl=64 time=0.043 ms --- 192.168.2.100 ping statistics ---4 packets transmitted, 4 received, 0% packet loss, time 2997ms
如上,我们已经创建了桥接接口,veth对,将一个迁移到新的网络名称空间,并测试了连接性。所以的命令汇总如下:
[root@node02 ~]# echo 1 > /proc/sys/net/ipv4/ip_forward[root@node02 ~]# sudo ip netns add net1[root@node02 ~]# sudo ip link add veth0 type veth peer name veth1[root@node02 ~]# sudo ip link set veth1 netns net1[root@node02 ~]# sudo ip link add veth0 type veth peer name veth1[root@node02 ~]# sudo ip netns exec net1 ip addr add 192.168.1.101/24 dev veth1[root@node02 ~]# sudo ip netns exec net1 ip link set dev veth1 up[root@node02 ~]# sudo ip link add br0 type bridge[root@node02 ~]# sudo ip link set dev br0 up[root@node02 ~]# sudo ip link set eth1 master br0[root@node02 ~]# sudo ip link set veth0 master br0[root@node02 ~]# sudo ip netns exec net1 ip route add default via 192.168.1.100
每个容器创建和删除的网络名称空间都需要这些命令。命名空间创建是容器运行时的任务。Docker以自己的方式为我们管理这一切。容器网络接口,CNI,项目标准化了所有系统的网络创建。与OCI非常相似,CNI是开发人员对特定任务进行标准化和优先级排序的一种方法,用于管理容器生命周期的各个部分。
容器网络基础知识
以上使用了桥接的方式创建网络,还有其他的容器网络模式。下面我们部署几个docker容器,并观察它们的网络,以及容器如何与主机进行外部通信以及彼此之间如何通信。
先了解下处理容器时使用的几种网络“模式”:
None
禁用容器的联网。当容器不需要网络访问时,使用此模式。
Bridge
桥接网络—容器运行在主机内部的私有网络中。与网络中其他容器的通信是开放的。在退出主机之前,与主机外的服务进行通信需要经过网络地址转换(NAT)。当没有指定
--net
选项时,网桥模式是网络的默认模式。Host
在主机模式中,容器与主机共享相同的IP地址和网络命名空间。在此容器中运行的进程具有与直接在主机上运行的服务相同的网络功能。当容器需要访问主机的网络资源时,使用该模式。容器在这种网络模式下失去了网络隔离的好处。
Macvlan
macvlan使用父接口。该接口可以是主机接口(如eth0)、子接口,甚至是绑定主机适配器(将以太网接口捆绑到单个逻辑接口中)。与所有Docker网络一样,MACVLAN网络是相互隔离的,提供网络内部的访问,而不是网络之间的访问。Macvlan允许一个物理接口通过Macvlan子接口拥有多个mac和ip地址。Macvlan有四种类型:
Private、VEPA、Bridge
(Docker默认使用的)和pass
。使用网桥,使用NAT进行外部连接。使用macvlan,由于主机直接映射到物理网络,外部连接可以使用同主机一样的DHCP服务器和交换机完成。IPvlan
IPvlan与macvlan类似,但有很大区别。在创建子接口时,不为其分配MAC地址。所有子接口共享父接口的MAC地址,但使用不同的IP地址。IPvlan有L2和L3两种模式。在IPvlan中,L2二层模式与macvlan网桥模式类似。IPvlan L3三层模式在子接口和父接口之间伪装成三层设备。
Overlay
Overlay允许在容器集群中的主机上扩展相同的网络。Overlay网络实际上位于底层/物理网络之上。
Custom
自定义网桥网络与网桥网络相同,但使用为该容器显式创建的网桥。使用这种方法的一个例子是在数据库桥接网络上运行的容器。一个单独的容器可以在默认情况下有一个接口和数据库桥接器,这样它就可以根据需要与这两个网络通信。
容器定义的网络允许一个容器共享另一个容器的地址和网络配置。这种共享支持容器之间的进程隔离,其中每个容器运行一个服务,但服务仍然可以在127.0.0.1上相互通信。
使用Docker介绍下三种网络类型:Bridge、Host和None,如下:
[root@node02 ~]# docker network lsNETWORK ID NAME DRIVER SCOPE ce07943ba561 bridge bridge local e71f406580b1 host host local9cda54cf669b none null local
默认是docker桥接,容器被附加到桥接网口,并在172.17.0.0/16默认子网中提供一个IP地址。如下是Linux默认接口和docker安装的视图,为主机创建了docker0
桥接接口。
[root@node02 ~]# ip a1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:16:3e:06:b0:ba brd ff:ff:ff:ff:ff:ff inet 172.31.146.11/20 brd 172.31.159.255 scope global dynamic eth0 valid_lft 306396820sec preferred_lft 306396820sec inet6 fe80::216:3eff:fe06:b0ba/64 scope link valid_lft forever preferred_lft forever3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:87:d6:a0:a3 brd ff:ff:ff:ff:ff:ff inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0 valid_lft forever preferred_lft forever inet6 fe80::42:87ff:fed6:a0a3/64 scope link valid_lft forever preferred_lft forever
使用docker run
命令启动一个busybox容器,请求docker返回该容器的ip地址。Docker默认的Nat地址是172.17.0.0/16,而我们的busybox容器获取的是172.17.0.4。
[root@node02 ~]# docker run -it busybox ip aUnable to find image 'busybox:latest' locally latest: Pulling from library/busybox8ec32b265e94: Pull complete Digest: sha256:b37dd066f59a4961024cf4bed74cae5e68ac26b48807292bd12198afa3ecb778 Status: Downloaded newer image for busybox:latest1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever29: eth0@if30: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue link/ether 02:42:ac:11:00:04 brd ff:ff:ff:ff:ff:ff inet 172.17.0.4/16 brd 172.17.255.255 scope global eth0 valid_lft forever preferred_lft forever
如下示例Host模式显示容器与主机共享相同的网络命名空间。我们可以看到,这些接口与主机的接口是一样的,在容器ip a
的命令输出中有eth0和docker0。
[root@node02 ~]# docker run -it --net=host busybox ip a1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast qlen 1000 link/ether 00:16:3e:06:b0:ba brd ff:ff:ff:ff:ff:ff inet 172.31.146.11/20 brd 172.31.159.255 scope global dynamic eth0 valid_lft 306396347sec preferred_lft 306396347sec inet6 fe80::216:3eff:fe06:b0ba/64 scope link valid_lft forever preferred_lft forever3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue link/ether 02:42:87:d6:a0:a3 brd ff:ff:ff:ff:ff:ff inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0 valid_lft forever preferred_lft forever inet6 fe80::42:87ff:fed6:a0a3/64 scope link valid_lft forever preferred_lft forever
相比与前面设置的veth桥接示例中,Docker为我们管理网络时变得简单多了。为了查看这个,我们需要一个进程来保持容器运行。下面的命令启动一个busybox容器并进入sh命令行。
[root@node02 ~]# docker run -it --rm busybox /bin/sh/ #
我们有一个环回接口lo
和一个连接到veth的以太网接口eth0
, docker的默认ip地址为172.17.0.4。由于我们之前的命令只输出ip a
结果,并且容器随后退出,Docker对正在运行的busybox容器重用了ip地址172.17.0.4。
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever31: eth0@if32: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue link/ether 02:42:ac:11:00:04 brd ff:ff:ff:ff:ff:ff inet 172.17.0.4/16 brd 172.17.255.255 scope global eth0 valid_lft forever preferred_lft forever
在容器网络名称空间中运行ip route
,我们可以看到容器路由表也自动设置好了。
/ # ip routedefault via 172.17.0.1 dev eth0 172.17.0.0/16 dev eth0 scope link src 172.17.0.4
docker ps
我们可以看到运行中的容器:
[root@node02 ~]# docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c4022bdd21e6 busybox "/bin/sh" 22 minutes ago Up 22 minutes charming_archimedes
我们可以看到容器veth3004e92@if31
的veth接口docker设置在同一个主机的网络名称空间上。它是docker0的桥的一个成员,并且在master docker0 state UP
时被打开。
[root@node02 ~]# ip a1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:16:3e:06:b0:ba brd ff:ff:ff:ff:ff:ff inet 172.31.146.11/20 brd 172.31.159.255 scope global dynamic eth0 valid_lft 306394324sec preferred_lft 306394324sec inet6 fe80::216:3eff:fe06:b0ba/64 scope link valid_lft forever preferred_lft forever3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:87:d6:a0:a3 brd ff:ff:ff:ff:ff:ff inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0 valid_lft forever preferred_lft forever inet6 fe80::42:87ff:fed6:a0a3/64 scope link valid_lft forever preferred_lft forever27: veth0@if26: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether 8e:c0:b9:89:66:a6 brd ff:ff:ff:ff:ff:ff link-netnsid 228: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000 link/ether 76:9d:a6:8a:21:d6 brd ff:ff:ff:ff:ff:ff inet6 fe80::749d:a6ff:fe8a:21d6/64 scope link valid_lft forever preferred_lft forever32: veth3004e92@if31: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default link/ether 52:59:57:bf:ab:56 brd ff:ff:ff:ff:ff:ff link-netnsid 3 inet6 fe80::5059:57ff:febf:ab56/64 scope link valid_lft forever preferred_lft forever
主机的路由表显示了Docker到达主机上运行的容器的路由:
[root@node02 ~]# ip routedefault via 172.31.159.253 dev eth0 169.254.0.0/16 dev eth0 scope link metric 1002 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 172.31.144.0/20 dev eth0 proto kernel scope link src 172.31.146.11
从ip命令中列出docker网络名称空间需要三个步骤。
- 获取运行容器的PID
- 将网络命名空间从
/proc/PID/net
软链接到/var/run/netns - 列出网络名称空间
docker inspect
用来解析输出并获取主机进程的PID。如果我们在主机PID命名空间上运行ps -p
,我们可以看到它正在运行sh
,它跟踪我们的docker run
命令。
[root@node02 ~]# docker inspect -f '{{.State.Pid}}' c4022bdd21e631037
c4022bdd21e6
是容器id, 31037
是运行sh的busybox容器的PID,现在我们可以用下面的命令为Docker创建的容器的网络名称空间创建一个符号链接到ip所期望的位置。
[root@node02 ~]# ln -sfT /proc/31037/ns/net /var/run/netns/c4022bdd21e6
现在,ip netns exec
命令返回与docker exec
命令相同的ip地址172.17.0.4。
[root@node02 ~]# ip netns exec c4022bdd21e6 ip a1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever31: eth0@if32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:ac:11:00:04 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 172.17.0.4/16 brd 172.17.255.255 scope global eth0 valid_lft forever preferred_lft forever
我们可以用docker exec
进行验证,并在运行的容器中执行ip a
。IP地址、mac地址和网络接口都匹配。
[root@node02 ~]# docker exec c4022bdd21e6 ip a1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever31: eth0@if32: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue link/ether 02:42:ac:11:00:04 brd ff:ff:ff:ff:ff:ff inet 172.17.0.4/16 brd 172.17.255.255 scope global eth0 valid_lft forever preferred_lft forever
Docker启动我们的容器,创建网络名称空间、veth对、docker0桥,并在一个命令中为每个容器的创建和删除添加。从应用程序开发人员的角度来看,这是非常强大的。不需要记住所有的Linux命令,也不需要破坏主机上的网络。
Docker网络模型
Libnetwork是Docker的容器网络,其设计理念体现在容器网络模型CNM中。Libnetwork实现了容器网络模型,有三个组件Sandbox,Endpoint和Network。Sandbox实现了对主机上运行的所有容器的Linux网络名称空间的管理。Network组件是同一网络上的端点的集合。Endpoint是网络上的主机。网络控制器通过Docker引擎中的api管理所有这些。
在Endpoint上,Docker使用iptables进行网络隔离。容器发布一个要从外部访问的端口。容器不接收公共IPv4地址;他们会收到一个私有RFC地址。在容器上运行的服务必须逐个端口开放,并且容器端口必须映射到主机端口,以避免冲突。当Docker启动时,它在主机上创建一个虚拟桥接接口docker0,并从私有地址范围内随机分配一个IP地址。这个网桥在两个连接的设备之间传递数据包,就像物理网桥一样。每个新的容器都有一个自动附加到docker0桥的接口;图9表明了这一点:
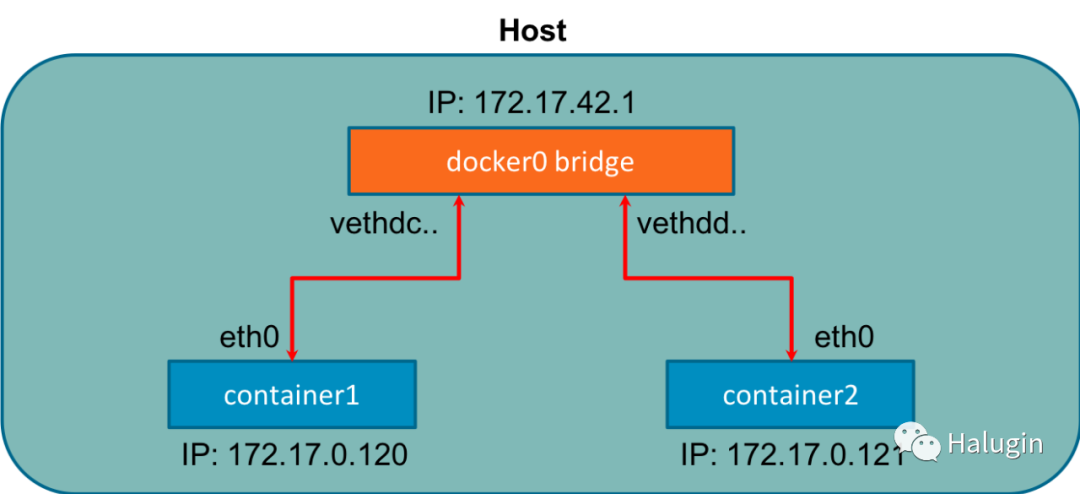
CNM将网络模式映射到我们已经讨论过的驱动器。下面是网络模式和Docker引擎等效的列表。
- Bridge-默认Docker桥
- Custom or Remote -用户定义的桥,或允许用户创建或使用他们的插件
- Overlay-覆盖
- Null-没有网络配置
桥接网络用于运行在同一主机上的容器。与运行在不同主机上的容器通信可以使用overlay网络。Docker使用了本地驱动和全局驱动的概念。例如,本地驱动程序(桥接)是以主机为中心的,不进行跨节点协调。全局驱动程序依赖于libkv(键值存储抽象)来跨机器进行协调。CNM不提供键值存储,因此需要像consul、etcd和zookeeper这样的外部存储。
Overlay网络
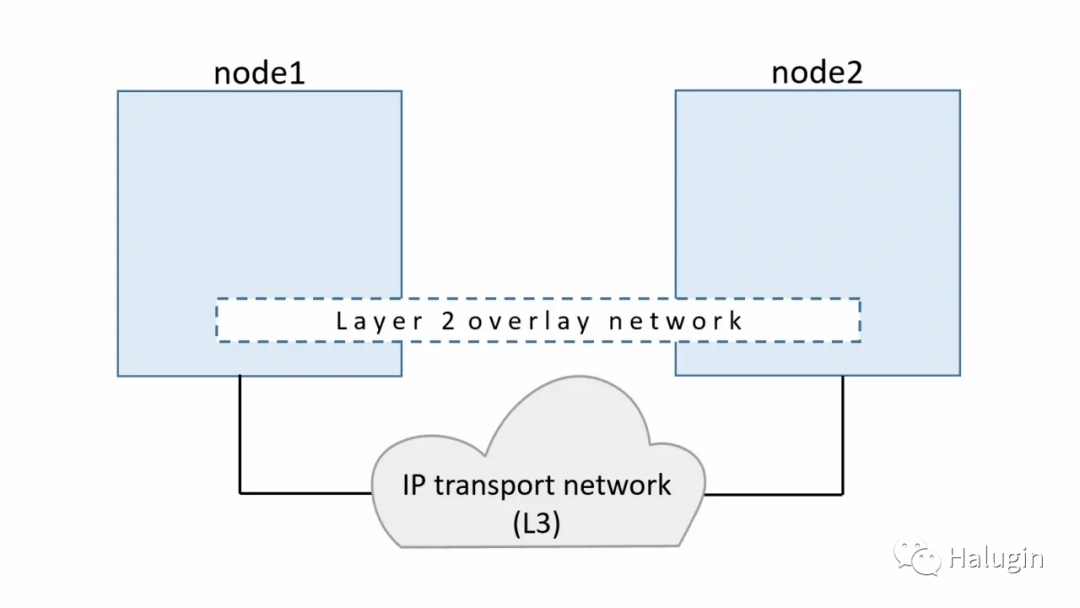
目前为止,我们的示例都是在单个主机上运行的,但是大规模的生产应用程序并不在单个主机上运行。对于在独立节点上的容器中运行的应用程序进行通信,需要解决几个问题。如何协调主机之间的路由信息,端口冲突,ip地址管理等。一种帮助在主机之间路由容器的技术是虚拟可扩展局域网(VXLAN)。在图10中,我们可以看到创建了一个二层覆盖网络,VXLAN运行在物理的L3网络上,因此命名为覆盖。
VXLAN是VLAN协议的扩展,可以创建1600万个唯一标识符。根据IEEE 802.1Q,一个以太网网络上的最大vlan数目是4,094。物理数据中心网络上的传输协议是IP和UDP。VXLAN定义了一种MAC-in-UDP封装方案,在最初的二层帧中,VXLAN头被包裹在UDP IP报文中。UDP封装的IP报文及其报头如图11所示。

VXLAN报文是一种MAC-in-UDP封装报文。第二层帧添加了VXLAN报头,放在UDP-IP包中。VXLAN标识符为24位。这就是VXLAN能够支持1600万段的原因。
如图11,我们在两台主机上都有VXLAN隧道端点(VTEP),它们连接到主机的网桥接口上,以及连接到网桥上的容器。VTEP对数据帧进行封装解封装。VTEP对交互确保数据被转发到相关的目标容器地址。离开容器的数据被封装成VXLAN信息,通过VXLAN隧道由对端VTEP进行解封装。
Overlay网络允许容器在网络上跨主机通信。CNM还有其他问题使它与Kubernetes不相容。Kubernetes的维护者决定使用CoreOS开始的容器网络接口项目。它比CNM简单,不需要守护进程,而且是跨平台的。
Container Network Interface(CNI)
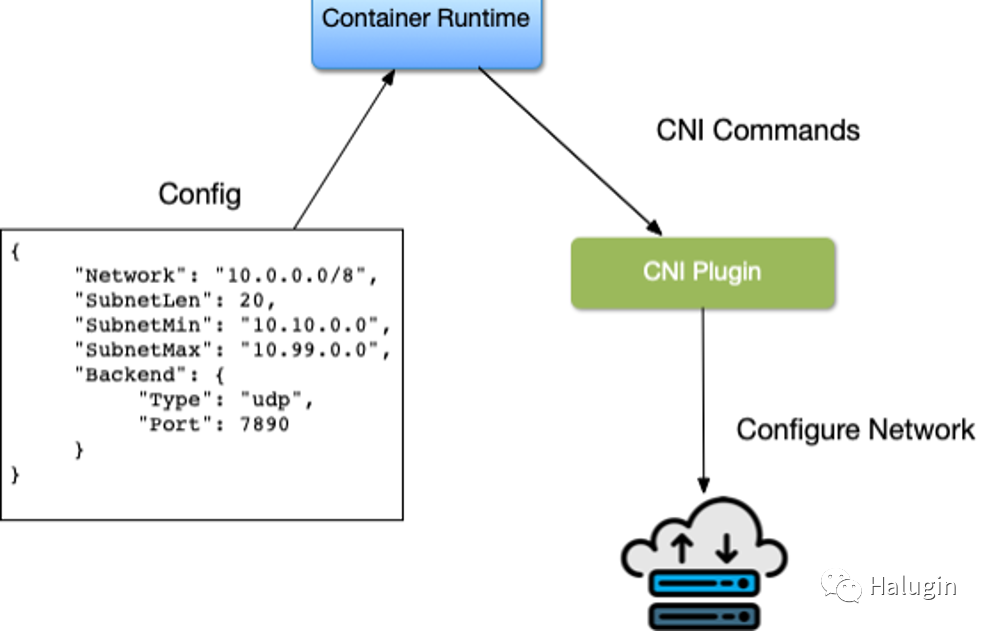
容器网络接口(CNI)是容器运行时与网络实现之间的软件接口。在实现CNI时,有许多选项可供选择。作为Rkt项目的一部分,CNI最早由CoreOS开发维护;它现在是一个云原生计算基金会(CNCF)项目。CNI项目由一个规范和库组成,用于开发在Linux容器中配置网络接口的插件。CNI关心容器的网络连通性,它在创建容器时分配资源,在删除容器时删除资源。CNI插件负责将网络接口与容器网络名称空间相关联,并对主机进行任何必要的更改。然后,它将IP分配给接口,并为接口建立路由。CNI架构如图12所示。容器运行时为主机的网络信息使用配置文件;在Kubernetes中,kubelet也使用这个配置文件。CNI和Container运行时相互通信。
有几个开源项目实现了具有各种特性和功能的CNI插件。下面列出几个常用的插件:
Cilium是用于确保应用程序容器之间的网络连接的开源软件。Cilium是L7/HTTP感知的CNI,可以使用与网络寻址分离的基于身份的安全模型在L3-L7上执行网络策略。
Flannel是一种为Kubernetes设计的三层网络通信的简单配置方式。Flannel使用Kubernetes集群现有的etcd数据存储来存储其状态信息,以避免提供专用的数据存储。
Calico结合了灵活的网络能力和随处运行的安全强制措施,提供了具有本地Linux内核性能和真正的云原生可伸缩性的解决方案。它有全网络政策支持,并与其他CNI合作良好。Calico不使用Overlay网络。相反,Calico配置了一个三层网络,使用BGP路由协议在主机之间路由数据包。Calico还可以与Istio(服务网格)集成,在服务网格和网络基础设施层解释和执行集群内工作负载的策略。
对于CNI还有很多选择,这取决于Cluster管理员、Network管理员和应用程序开发人员来地决定哪个CNI解决了他们的业务需求。
Container connectivity
我们使用Go最小web服务器来看容器的连接。当我们在主机上通过容器部署web服务器时,看下在容器级别上都发生了什么。
我们将介绍两种网络场景:
- Docker主机上容器与容器间的通信
- 不同主机上容器间的通信
Golang web服务器代码如下:
package mainimport ( "fmt" "net/http")func hello(w http.ResponseWriter, _ *http.Request) { fmt.Fprintf(w, "Hello") }func main() { http.HandleFunc("/", hello) http.ListenAndServe("0.0.0.0:8080", nil) }
为了提供最小的golang web服务器,我们需要在dockerfile中创建它。dockerfile是指定在构建镜像时要做什么的指令。它从FROM
指令开始,并指定基本镜像是什么。RUN
指令指定要执行的命令。注释以#
开头。记住,Dockerfile
中的每一行如果改变了图像的状态,就会创建一个新层。开发人员需要在为图像创建大量层和Dockerfile的可读性之间找到正确的平衡。
FROM golang:1.15 AS builder ➊ WORKDIR /opt ➋ COPY web-server.go . ➌ RUN CGO_ENABLED=0 GOOS=linux go build -o web-server . ➍ FROM golang:1.15 ➎ WORKDIR /opt ➏ COPY --from=0 /opt/web-server . ➐ CMD ["/opt/web-server"] ➑
➊ 因为我们的web服务器是用golang编写的,所以我们可以在容器中编译go服务器,从而将图像的大小减少到只有编译后的go二进制文件。我们从1.15版本的golang基础镜像开始。
➋ WORKDIR
为所有要运行的后续命令设置工作目录。
➌ COPY
复制web服务器。将文件定义到工作目录中.
➍ RUN
命令docker在构建器容器中编译golang应用程序。
➎ 现在我们运行我们的应用程序,我们为应用程序的基础图像定义了FROM
,同样是golang:1.15
,我们可以通过使用其他最小的图像,如alpine
,进一步最小化。
➏ 作为一个新容器,我们再次将工作目录设置为/opt
。
➐ COPY
将编译后的go二进制文件从构建器容器复制到应用程序容器中。
➑ CMD
指明docker运行我们的应用程序的命令是启动我们的web服务器。
在容器化应用程序时,有一些Dockerfile的最佳实践是开发者和管理员应该遵循的。
- 每个Dockerfile都有一个ENTRYPOINT, ENTRYPOINT或者CMD告诉Docker在运行的容器中启动了什么进程,所以应该只有一个正在运行的进程。
- 为了减少容器层,开发人员应该使用“& &”和“\”将类似的命令组合成一个命令。dockerfile中的每一个新命令都会向Docker容器镜像添加一层,从而增加它的存储空间。
- 使用缓存系统来改善容器的构建时间。如果没有改变一个层,它应该在dockerfile的顶部。添加最不可能首先更改的文件和最可能最后更改的文件。
- 使用多阶段构建。
- 请勿安装不必要的工具和包。
我们构件下这个web-server镜像,docker build
指明docker从Dockerfile指令构建镜像。
[root@node02 go-web]# docker build .Sending build context to Docker daemon 3.072kB Step 1/8 : FROM golang:1.15 AS builder1.15: Pulling from library/golang627b765e08d1: Pull complete c040670e5e55: Pull complete 073a180f4992: Pull complete bf76209566d0: Pull complete 6182a456504b: Pull complete 73e3d3d88c3c: Pull complete 5946d17734ce: Pull complete Digest: sha256:ea080cc817b02a946461d42c02891bf750e3916c52f7ea8187bccde8f312b59f Status: Downloaded newer image for golang:1.15 ---> 40349a2425ef Step 2/8 : WORKDIR /opt ---> Running in 753d2b53a86f Removing intermediate container 753d2b53a86f ---> 726b3e4b44c9 Step 3/8 : COPY web-server.go . ---> 9a2c29eb0feb Step 4/8 : RUN CGO_ENABLED=0 GOOS=linux go build -o web-server . ---> Running in f548ccef375e Removing intermediate container f548ccef375e ---> 920191334236Step 5/8 : FROM golang:1.15 ---> 40349a2425ef Step 6/8 : WORKDIR /opt ---> Using cache ---> 726b3e4b44c9 Step 7/8 : COPY --from=0 /opt/web-server . ---> eabec8522603 Step 8/8 : CMD ["/opt/web-server"] ---> Running in 6e2fc5463308 Removing intermediate container 6e2fc5463308 ---> 10e3b6dfdb8c Successfully built 10e3b6dfdb8c
我们测试的golang最小web服务器的容器id是10e3b6dfdb8c
,不好记忆,所以我们可以使用docker tag
命令给它打个标签。
[root@node02 go-web]# docker tag 10e3b6dfdb8c go-web:v0.0.1
docker images
返回要运行的本地可用镜像列表。
[root@node02 go-web]# docker imagesREPOSITORY TAG IMAGE ID CREATED SIZE go-web v0.0.1 10e3b6dfdb8c 3 minutes ago 846MB <none> <none> 920191334236 3 minutes ago 858MB busybox latest 42b97d3c2ae9 12 days ago 1.24MB golang 1.15 40349a2425ef 3 weeks ago 840MB
docker ps
列出了主机上运行的容器。在我们的环境中,我们仍然有一个运行中的busybox容器。
[root@node02 go-web]# docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c4022bdd21e6 busybox "/bin/sh" 2 hours ago Up 2 hours charming_archimedes
docker log
将打印出该容器从标准输出产生的任何日志。
[root@node02 go-web]# docker logs c4022bdd21e6/ # ip a1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever31: eth0@if32: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue link/ether 02:42:ac:11:00:04 brd ff:ff:ff:ff:ff:ff inet 172.17.0.4/16 brd 172.17.255.255 scope global eth0 valid_lft forever preferred_lft forever / # ip routedefault via 172.17.0.1 dev eth0 172.17.0.0/16 dev eth0 scope link src 172.17.0.4
docker exec
允许开发人员和管理员在Docker容器中执行命令。
[root@node02 go-web]# docker exec c4022bdd21e6 ifconfigeth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:04 inet addr:172.17.0.4 Bcast:172.17.255.255 Mask:255.255.0.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:8 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:656 (656.0 B) TX bytes:0 (0.0 B) lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
docker pull image_name
-镜像名称将从镜像仓库中复制docker镜像到本地docker文件系统中。
[root@node02 ~]# docker pull gwzhangge/dnsutils:1.31.3: Pulling from gwzhangge/dnsutils Digest: sha256:cfd57a02bf2250b32df20fc2120f08f2930aa7506a5eb726cbbe53a771ca15e7 Status: Downloaded newer image for gwzhangge/dnsutils:1.3docker.io/gwzhangge/dnsutils:1.3
既然我们的golang应用程序可以作为容器运行,那么我们可以研究容器联网的场景。
Container to Container
首先我们看下运行在同一主机上的两个容器之间的通信。
[root@node02 ~]# docker run -it gwzhangge/dnsutils:1.3 /bin/sh/
默认的docker网络设置使dnsutils镜像连接到Internet。
/ # ping www.baidu.com -c 4PING www.baidu.com (110.242.68.3): 56 data bytes64 bytes from 110.242.68.3: seq=0 ttl=50 time=17.492 ms64 bytes from 110.242.68.3: seq=1 ttl=50 time=17.528 ms64 bytes from 110.242.68.3: seq=2 ttl=50 time=17.502 ms64 bytes from 110.242.68.3: seq=3 ttl=50 time=17.557 ms --- www.baidu.com ping statistics ---4 packets transmitted, 4 packets received, 0% packet loss round-trip min/avg/max = 17.492/17.519/17.557 ms
运行我们的golang web-server服务器:
[root@node02 ~]# docker run -it -d -p 80:8080 go-web:v0.0.14feab8959adb23f797c580135b9c1b2c9671293b614861cd384eb30ce80f15ae
-it
选项用于交互进程(例如shell),以便为容器进程分配一个TTY。-d
,在分离模式下运行容器(后台运行);这允许我们继续使用终端并输出完整的docker容器id。-p
是网络的基本选项;这个创建了主机和容器之间的端口映射;我们的golang web服务器运行在8080端口上,并在主机的80端口上公开该端口。
docker ps
可以看到我们现在有两个运行的容器,一个是go-web server容器,在主机端口80上暴露了8080端口,另一个是在dnsutils容器中运行的shell。
[root@node02 ~]# docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES4feab8959adb go-web:v0.0.1 "/opt/web-server" 2 minutes ago Up 2 minutes 0.0.0.0:80->8080/tcp, :::80->8080/tcp quizzical_chatterjee89bcbfc94186 gwzhangge/dnsutils:1.3 "/bin/sh" 8 minutes ago Up 8 minutes zealous_perlman
让我们使用docker inspect命令来获取golang webserver容器的docker IP地址。
[root@node02 ~]# docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' 4feab8959adb172.17.0.3
在dnsutils容器中,我们可以使用golang webserver的docker网络地址172.17.0.3
,以及容器端口8080。
/ # wget 172.17.0.3:8080Connecting to 172.17.0.3:8080 (172.17.0.3:8080) index.html 100% |*******************************| 5 0:00:00 ETA / # cat index.htmlHello/ #
每个容器都可以通过docker0桥和容器端口到达另一个容器,因为它们在同一个docker主机和相同的网络上。docker主机有到容器ip地址的路由,以便通过其ip地址和端口到达容器。
[root@node02 ~]# curl 172.17.0.3:8080Hello
但不是来自docker run
命令的docker ip地址和主机端口。
[root@node02 ~]# curl 172.17.0.3:80curl: (7) Failed connect to 172.17.0.3:80; 拒绝连接 [root@node02 ~]# curl 172.17.0.3:8080Hello
现在反过来,使用环回接口,我们演示主机只能到达主机端口暴露80上的web服务器,而不能到达docker端口8080。
[root@node02 ~]# curl 172.17.0.3:8080Hello[root@node02 ~]# curl localhost:80Hello[root@node02 ~]# curl localhost:8080curl: (7) Failed connect to localhost:8080; 拒绝连接
现在回到dnsutils,同样的,dnsutils镜像在docker网络上,使用go-web容器的docker ip地址只能使用docker端口8080,而不是暴露的主机端口80。
[root@node02 ~]# docker exec -it 89bcbfc94186 /bin/sh/ # wget 172.17.0.3:8080 -qO-Hello/ # WGET 172.17.0.3:80 -qO-/ # wget 172.17.0.3:80 -qO-wget: can't connect to remote host (172.17.0.3): Connection refused
为了显示它是一个完全独立的堆栈,让我们访问dnsutils环回地址和docker端口,以及暴露的主机端口。
/ # wget localhost:80 -qO-wget: can't connect to remote host (127.0.0.1): Connection refused / # wget localhost:8080 -qO- wget: can't connect to remote host (127.0.0.1): Connection refused
未达到预期的效果;dnsutils镜像有一个独立的网络堆栈,并且不共享go-web服务器的网络名称空间。了解为什么它不能工作对Kubernetes来说至关重要,因为pod是共享相同网络名称空间的容器集合。
不同主机上的容器间的网络通信,将在kubernetes网络的相关部分学习。
以上便是容器网络相关的基础知识点。
感兴趣的关注如下公众号!

