




kubernetes网络之二:Linux网络
上一篇文章我们讲述了网络的基础知识,本文将概述Linux相关的网络栈,重点关注Kubernetes中值得注意的领域。
基础知识
让我们再次访问我们在上一篇文章中使用的Go web服务器。这个web服务器侦听端口8080,并返回“Hello”的HTTP请求到“/”。
特权端口
端口1-1023(也称为“知名端口”)需要root权限才能绑定。
程序应该总是被赋予运行所需的最少权限,这意味着一个典型的web服务不应该以根用户的身份运行。因此,许多程序将侦听1024或更高的端口(特别是端口8080是HTTP服务的常见选择)。在可能的情况下,侦听非特权端口,并使用基础设施重定向(负载均衡器转发、Kubernetes服务等)将外部可见的特权端口转发给侦听非特权端口的程序。
这样,即使黑客找到服务的漏洞也不会拥有过于广泛的可用权限。
package mainimport ( "fmt" "net/http")func hello(w http.ResponseWriter, _ *http.Request) { fmt.Fprintf(w, "Hello") }func main() { http.HandleFunc("/", hello) http.ListenAndServe("0.0.0.0:8080", nil) }
假设这个程序在Linux服务器机器上运行,一个外部客户端向/
发出请求。服务器上发生了什么?开始时,我们的程序需要侦听一个地址和端口。我们的程序为该地址和端口创建一个套接字,并与之绑定。套接字将接收到指定地址和端口的请求——在我们的示例中,端口为8080,地址为机器的任意IP地址。
IP地址通配符
IPv4中的
0.0.0.0
和IPv6中的[::]
是通配符地址。它们匹配各自协议的所有地址,因此,在用于套接字绑定时侦听所有可用的IP地址。
这对于公开服务是很有用的,而不需要事先知道运行该服务的机器将拥有什么IP地址。大多数网络公开的服务都是这样绑定的。
有多种方法可以检查套接字。例如,ls -lah proc//fd
将列出套接字。
内核将给定的包映射到特定的连接,并使用内部状态机来管理连接状态。与插座一样,连接也可以通过各种工具进行检查。Linux用一个文件表示每个连接。接受连接需要从内核向我们的程序发出通知,然后该程序就能够以流方式向文件传输内容。
回到golang web服务器,我们可以使用strace来显示服务器正在做什么。
$ strace ./main execve("./main", ["./main"], 0x7ebf2700 * 21 vars */) = 0brk(NULL) = 0x78e000 mmap2(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x76f1d000 [Content cut]
因为strace会捕获服务器发出的所有系统调用,所以会有大量输出。让我们将其减少到相关的网络系统调用。
openat(AT_FDCWD, "/proc/sys/net/core/somaxconn", O_RDONLY|O_LARGEFILE|O_CLOEXEC) = 3epoll_create1(EPOLL_CLOEXEC) = 4 ❶ epoll_ctl(4, EPOLL_CTL_ADD, 3, {EPOLLIN|EPOLLOUT|EPOLLRDHUP|EPOLLET, {u32=1714573248, u64=1714573248}}) = 0fcntl(3, F_GETFL) = 0x20000 (flags O_RDONLY|O_LARGEFILE) fcntl(3, F_SETFL, O_RDONLY|O_NONBLOCK|O_LARGEFILE) = 0read(3, "128\n", 65536) = 4read(3, "", 65532) = 0epoll_ctl(4, EPOLL_CTL_DEL, 3, 0x20245b0) = 0close(3) = 0socket(AF_INET, SOCK_STREAM|SOCK_CLOEXEC|SOCK_NONBLOCK, IPPROTO_TCP) = 3close(3) = 0socket(AF_INET6, SOCK_STREAM|SOCK_CLOEXEC|SOCK_NONBLOCK, IPPROTO_TCP) = 3 ❷ setsockopt(3, SOL_IPV6, IPV6_V6ONLY, [1], 4) = 0 ❸bind(3, {sa_family=AF_INET6, sin6_port=htons(0), inet_pton(AF_INET6, "::1", &sin6_addr), sin6_flowinfo=htonl(0), sin6_scope_id=0}, 28) = 0socket(AF_INET6, SOCK_STREAM|SOCK_CLOEXEC|SOCK_NONBLOCK, IPPROTO_TCP) = 5setsockopt(5, SOL_IPV6, IPV6_V6ONLY, [0], 4) = 0bind(5, {sa_family=AF_INET6, sin6_port=htons(0), inet_pton(AF_INET6, "::ffff:127.0.0.1", &sin6_addr), sin6_flowinfo=htonl(0), sin6_scope_id=0}, 28) = 0close(5) = 0close(3) = 0socket(AF_INET6, SOCK_STREAM|SOCK_CLOEXEC|SOCK_NONBLOCK, IPPROTO_IP) = 3setsockopt(3, SOL_IPV6, IPV6_V6ONLY, [0], 4) = 0setsockopt(3, SOL_SOCKET, SO_BROADCAST, [1], 4) = 0setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0bind(3, {sa_family=AF_INET6, sin6_port=htons(8080), inet_pton(AF_INET6, "::", &sin6_addr), sin6_flowinfo=htonl(0), sin6_scope_id=0}, 28) = 0 ❹ listen(3, 128) = 0epoll_ctl(4, EPOLL_CTL_ADD, 3, {EPOLLIN|EPOLLOUT|EPOLLRDHUP|EPOLLET, {u32=1714573248, u64=1714573248}}) = 0getsockname(3, {sa_family=AF_INET6, sin6_port=htons(8080), inet_pton(AF_INET6, "::", &sin6_addr), sin6_flowinfo=htonl(0), sin6_scope_id=0}, [112->28]) = 0accept4(3, 0x2032d70, [112], SOCK_CLOEXEC|SOCK_NONBLOCK) = -1 EAGAIN (Resource temporarily unavailable) epoll_wait(4, [], 128, 0) = 0epoll_wait(4, ❺
❶ 打开一个文件描述符来监听
❷ 创建用于IPv6连接的TCP套接字
❸ 关闭套接字IPV6_V6ONLY
。现在,它可以监听IPv4和IPv6
❹ 绑定IPv6套接字侦听端口8080(所有地址)
❺等待请求
一旦服务器启动,我们可以看到strace pause
在epoll_wait
上的输出。
此时,服务器正在侦听它的套接字,并等待内核通知它有关包的信息。当我们向侦听服务器发出请求时,我们会看到hello zhangge
消息。
root@gwz:/data/go# curl localhost:8080Hello zhangge
在strace中,我们从服务器进程中可以看到以下内容:
[{EPOLLIN, {u32=1714573248, u64=1714573248}}], 128, -1) = 1accept4(3, {sa_family=AF_INET6, sin6_port=htons(54202), inet_pton(AF_INET6, "::ffff:10.0.0.57", &sin6_addr), sin6_flowinfo=htonl(0), sin6_scope_id=0}, [112->28], SOCK_CLOEXEC|SOCK_NONBLOCK) = 5epoll_ctl(4, EPOLL_CTL_ADD, 5, {EPOLLIN|EPOLLOUT|EPOLLRDHUP|EPOLLET, {u32=1714573120, u64=1714573120}}) = 0getsockname(5, {sa_family=AF_INET6, sin6_port=htons(8080), inet_pton(AF_INET6, "::ffff:10.0.0.30", &sin6_addr), sin6_flowinfo=htonl(0), sin6_scope_id=0}, [112->28]) = 0setsockopt(5, SOL_TCP, TCP_NODELAY, [1], 4) = 0setsockopt(5, SOL_SOCKET, SO_KEEPALIVE, [1], 4) = 0setsockopt(5, SOL_TCP, TCP_KEEPINTVL, [180], 4) = 0setsockopt(5, SOL_TCP, TCP_KEEPIDLE, [180], 4) = 0accept4(3, 0x2032d70, [112], SOCK_CLOEXEC|SOCK_NONBLOCK) = -1 EAGAIN (Resource temporarily unavailable)
在检查套接字之后,服务器将响应数据(“Hello”包装在HTTP协议中)写入文件描述符。然后,Linux内核(和其他一些用户空间系统)将请求转换成包,并将这些包传输回curl客户机。
当服务器收到请求时,它做了如下操作:
- Epoll返回,并使程序恢复
- 服务器看到一个来自::ffff:10.0.0.57的连接
- 服务器检查套接字
- 服务器更改
keepalive
选项:打开keepalive
,并设置keepalive
间隔为180秒。
以上是从应用程序开发人员的角度来看Linux中的网络。接下来我们看看Linux中的网络细节。
网络接口(The Network Interface)
计算机使用网络接口与外界通信。网络接口可以是物理的(如以太网网络控制器)或虚拟的。虚拟网络接口并不对应物理硬件,而是由主机或管理程序提供的抽象接口。
为网络接口分配IP地址。一个典型的接口可以有1个IPv4地址和1个IPv6地址,但是同一个接口可以配置多个IPv4地址。
Linux本身有一个网络接口的概念,它可以是物理的(如以太网卡和端口),也可以是虚拟的。如果运行ifconfig
,你将看到所有网络接口及其配置(包括IP地址)的列表。
IP
ip
命令也可以用来检查网络接口。
环回接口是一种用于本机通信的特殊接口。127.0.0.1
为loopback
接口的标准IP地址。发送到loopback
接口的包不会离开主机,并且侦听127.0.0.1
的进程只能被同一主机上的其他进程访问。loopback
接口通常缩写为lo
。
示例2为ifconfig
的输出:
root@gwz:~# ifconfigenp1s0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 ether 20:6a:8a:e1:d5:24 txqueuelen 1000 (以太网) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (本地环回) RX packets 10472 bytes 1154991 (1.1 MB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 10472 bytes 1154991 (1.1 MB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0virbr0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.122.1 netmask 255.255.255.0 broadcast 192.168.122.255 ether 52:54:00:b3:11:00 txqueuelen 1000 (以太网) RX packets 30687 bytes 905192 (905.1 KB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 931 bytes 85270 (85.2 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0vnet0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet6 fe80::fc54:ff:fe5a:19d9 prefixlen 64 scopeid 0x20<link> ether be:fe:d8:22:60:53 txqueuelen 1000 (以太网) RX packets 30687 bytes 1334810 (1.3 MB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 8812 bytes 499394 (499.3 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0wlp2s0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.43.193 netmask 255.255.255.0 broadcast 192.168.43.255 inet6 2409:891e:1b80:242f:1d11:92a6:444b:b783 prefixlen 64 scopeid 0x0<global> inet6 2409:891e:1b80:242f:760b:d9bd:eedb:d578 prefixlen 64 scopeid 0x0<global> inet6 fe80::b517:9a4d:f312:8fa3 prefixlen 64 scopeid 0x20<link> ether 74:29:af:80:2f:6f txqueuelen 1000 (以太网) RX packets 105598 bytes 104430783 (104.4 MB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 90617 bytes 19700178 (19.7 MB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
网桥接口(The Bridge Interface)
通过桥接接口(如图1所示),系统管理员可以在一台主机上创建多个二层网络。换句话说,网桥的功能就像主机上网络接口之间的网络交换机,无缝连接它们。
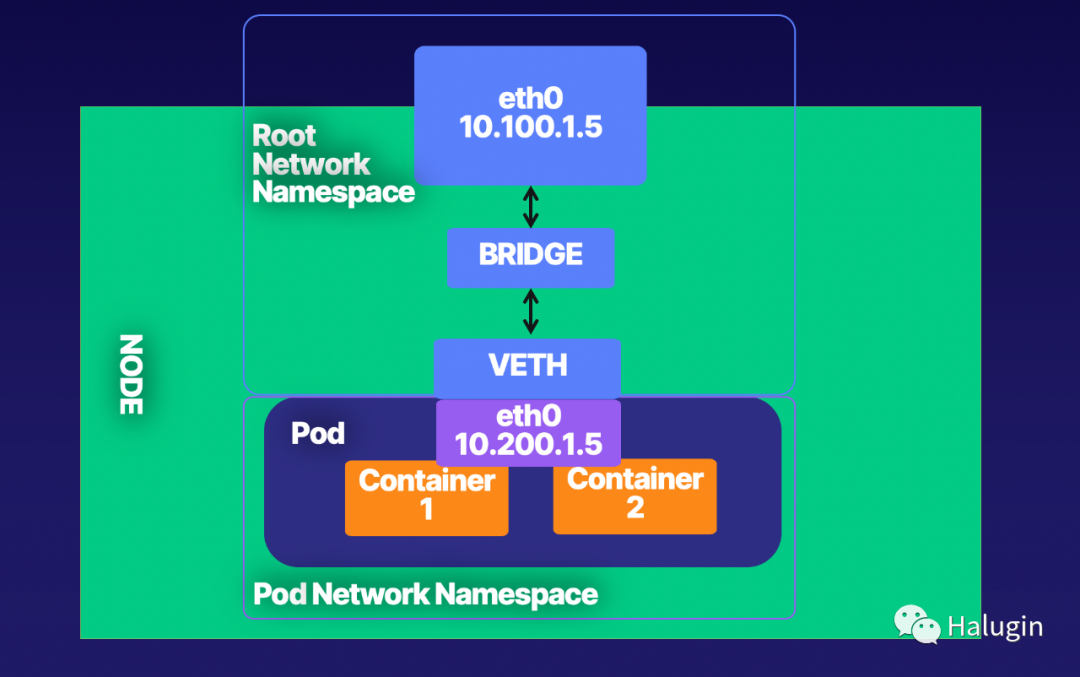
在示例3中,创建一个名为br0的网桥设备,并连接一个VETH设备veth
和一个物理设备eth0
。
# # Add a new bridge interface named br0.# ip link add br0 type bridge# # Attach eth0 to our bridge.# ip link set eth0 master br0# # Attach veth to our bridge.# ip link set veth master br0
可以使用brctl
命令管理和创建网桥。如下(示例4)显示了brctl
的一些可用选项:
root@gwz:~# brctl Usage: brctl [commands] commands: addbr <bridge> add bridge delbr <bridge> delete bridge addif <bridge> <device> add interface to bridge delif <bridge> <device> delete interface from bridge hairpin <bridge> <port> {on|off} turn hairpin on/off setageing <bridge> <time> set ageing time setbridgeprio <bridge> <prio> set bridge priority setfd <bridge> <time> set bridge forward delay sethello <bridge> <time> set hello time setmaxage <bridge> <time> set max message age setpathcost <bridge> <port> <cost> set path cost setportprio <bridge> <port> <prio> set port priority show [ <bridge> ] show a list of bridges showmacs <bridge> show a list of mac addrs showstp <bridge> show bridge stp info stp <bridge> {on|off} turn stp on/off
VETH (virtual Ethernet)设备是一个本端以太网隧道。VETH设备成对创建,如图1所示,其中pod看到的是VETH的eth0接口。在一对设备中,一台设备发送的报文会立即被另一台设备接收到。当其中一台设备down时,表示链路状态为down。可以使用brctl
命令或ip
向Linux添加桥接。当名称空间需要与主机名称空间通信或彼此之间通信时,使用VETH配置。
如下(示例5)显示了VETH如何配置:
# ip netns add net1# ip netns add net2# ip link add veth1 netns net1 type veth peer name veth2 netns net2
在示例5中,我们展示了创建两个网络名称空间、net1和net2以及一对VETH设备的步骤,其中veth1分配给名称空间net1, veth2分配给名称空间net2。这两个名称空间通过这个VETH对连接。只要分配一对IP地址,就可以ping通两个名称空间并进行通信。
Linux内核中的包处理
Linux内核负责包之间的转换,以及程序的数据流处理。我们将讨论内核如何处理连接,如路由和防火墙等,它们依赖于Linux的底层包管理。
Netfilter
Netfilter,从2.3开始就包含在Linux中,是包处理的一个关键组件。Netfilter是一个内核钩子框架,它允许用户空间程序代表内核处理数据包。简而言之,一个程序注册到一个特定的netfilter钩子,内核在适用的包上调用该程序。该程序可以告诉内核对数据包做一些事情(比如丢弃它),或者它可以向内核发送一个修改过的数据包。这样,开发人员就可以构建在用户空间中运行的普通程序,并处理包。Netfilter与iptables共同协作,以分离内核和用户空间代码。
Netfilter有5个钩子,如表1所示。Netfilter在数据包通过内核的特定阶段触发每个钩子。理解netfilter的钩子是理解iptables的关键,因为iptables直接将链的概念映射到netfilter钩子上。
| Netfilter Hook | Iptables Chain Name | Description |
|---|---|---|
| NF_IP_PRE_ROUTING | PREROUTING | Triggers when a packet arrives from an external system. |
| NF_IP_LOCAL_IN | INPUT | Triggers when a packet’s destination IP address matches this machine. |
| NF_IP_FORWARD | NAT | Triggers for packets where neither source nor destination. match the machine’s IP addresses (in other words, packets that this machine is routing on behalf of other machines). |
| NF_IP_LOCAL_OUT | OUTPUT | Triggers when a packet, originating from the machine, is leaving the machine. |
| NF_IP_POST_ROUTING | POSTROUTING | Triggers when any packet (regardless of origin) is leaving the machine. |
由于netfilter在数据包处理的特定阶段会触发每个钩子,在特定的条件下,我们可以用流程图来可视化netfilter钩子,如图2所示:

可以从流程图推断,对于任何给定的数据包,只有特定的netfilter钩子才会被调用。例如,来自本地进程的包总是触发NF_IP_LOCAL_OUT
钩子,然后是NF_IP_POST_ROUTING
钩子。特别地,数据包的netfilter钩子的流取决于两个因素:数据包的源是否为主机,以及数据包的目的地是否为主机。注意,如果进程发送一个到同一主机的数据包,它会在“重新进入”系统之前触发NF_IP_LOCAL_OUT
和NF_IP_POST_ROUTING
钩子,并触发NF_IP_PRE_ROUTING
和NF_IP_LOCAL_IN
钩子。在某些系统中,可以通过写一个虚假的源地址(即,欺骗一个包的源地址和目的地址为127.0.0.1
)。Linux通常会在这个包到达外部接口时过滤它。更广泛地说,当信息包到达某个接口,而该信息包的源地址在该网络中不存在时,Linux会对信息包进行过滤。在Linux中可以禁用对包的过滤。但是,如果主机上的任何服务都假设来自本地主机的流量比外部流量“更值得信任”,那么这样做会带来很大的风险。这是一个常见的假设,例如在没有强身份验证的情况下将API或数据库公开给主机。
表2列出了各种不同包源和目的地的netfilter钩子顺序。
| Packet source | Packet destination | Hooks (in order) |
|---|---|---|
| Local machine | Local machine | NF_IP_LOCAL_OUT, NF_IP_LOCAL_IN |
| Local machine | External machine | NF_IP_LOCAL_OUT, NF_IP_POST_ROUTING |
| External machine | Local machine | NF_IP_PRE_ROUTING, NF_IP_LOCAL_IN |
| External machine | External machine | NF_IP_PRE_ROUTING, NF_IP_FORWARD, NF_IP_POST_ROUTING |
从机器发送到自身的数据包将触发NF_IP_LOCAL_OUT
和NF_IP_POST_ROUTING
,然后“离开”网络接口。它们将“重新进入”,并被视为来自任何其他来源的数据包。
NAT(网络地址转换)只影响NF_IP_PRE_ROUTING
和NF_IP_LOCAL_OUT
钩子中的本地路由决策(例如,内核在包到达NF_IP_LOCAL_IN
钩子后不做路由决策)。源和目的NAT只能在特定的钩子/链中执行。
程序可以通过调用带有处理函数的nf_register_net_hook
(在Linux 4.13之前的nf_register_hook
)来注册一个钩子。每次数据包匹配时,钩子都会被调用。
根据返回值,netfilter钩子可以触发以下几个动作:
- Accept:继续包处理
- Drop:丢弃数据包,不进行进一步处理
- Queue:将数据包传递给用户空间程序
- Stolen:不执行进一步的钩子,并允许用户空间程序获得包的所有权
- Repeat:使数据包“重新进入”钩子并被重新处理
Conntrack
Conntrack是netfilter的一个组件,用于跟踪与机器之间的连接状态。连接跟踪直接将数据包与特定的连接关联起来。如果没有连接跟踪,数据包的流就不透明得多。Conntrack可能是一种负担,也可能是一种有价值的工具,或者两者都是,这取决于它的使用方式。一般来说,conntrack在处理防火墙或NAT的系统上很重要。
连接跟踪允许防火墙区分响应任意数据包。防火墙可以配置为允许属于现有连接部分的入站包,但不允许不属于连接部分的入站包。举个例子,可以允许程序建立出站连接并执行HTTP请求,否则远程服务器就不能发送数据或发起入站连接。
NAT依赖于conntrack功能。Iptables将NAT分为两种类型:SNAT(源NAT, Iptables重写源地址)和DNAT(目的NAT, Iptables重写目的地址)。NAT是非常常见的——你的家庭路由器使用SNAT和DNAT来增加你的IPv4地址。通过连接跟踪,数据包可以自动与它们的连接关联,并且可以轻松地用相同的SNAT/DNAT更改进行修改。例如将负载平衡器中的连接“固定”到特定的后端或机器。
Conntrack通过一个元组来标识连接,元组由源地址、源端口、目的地址、目的端口和L4协议组成。这5条信息是识别任何给定的L4连接所需的最小标识符。所有L4连接在连接的每一边都有一个地址和端口;毕竟,Internet使用地址进行路由,计算机使用端口号进行应用程序映射。最后一部分是L4协议,因为程序将以TCP或UDP模式绑定到端口。Conntrack将这些连接称为流。流包含关于连接及其状态的元数据。
Conntrack将流存储在哈希表中,如图3所示,使用连接元组作为键。键空间的大小是可配置的。更大的键空间需要更多的内存来保存底层数组,但将导致更少的流散列到相同的键并被链接到链表中,从而导致更快的流查找时间。流的最大数量也是可配置的。可能发生的一个严重问题是,当conntrack耗尽连接跟踪空间时,无法建立新的连接。还有其他配置选项,比如连接超时。在典型的系统中,默认设置就足够了。然而,一个系统如果经历了大量的连接,就会耗尽空间。
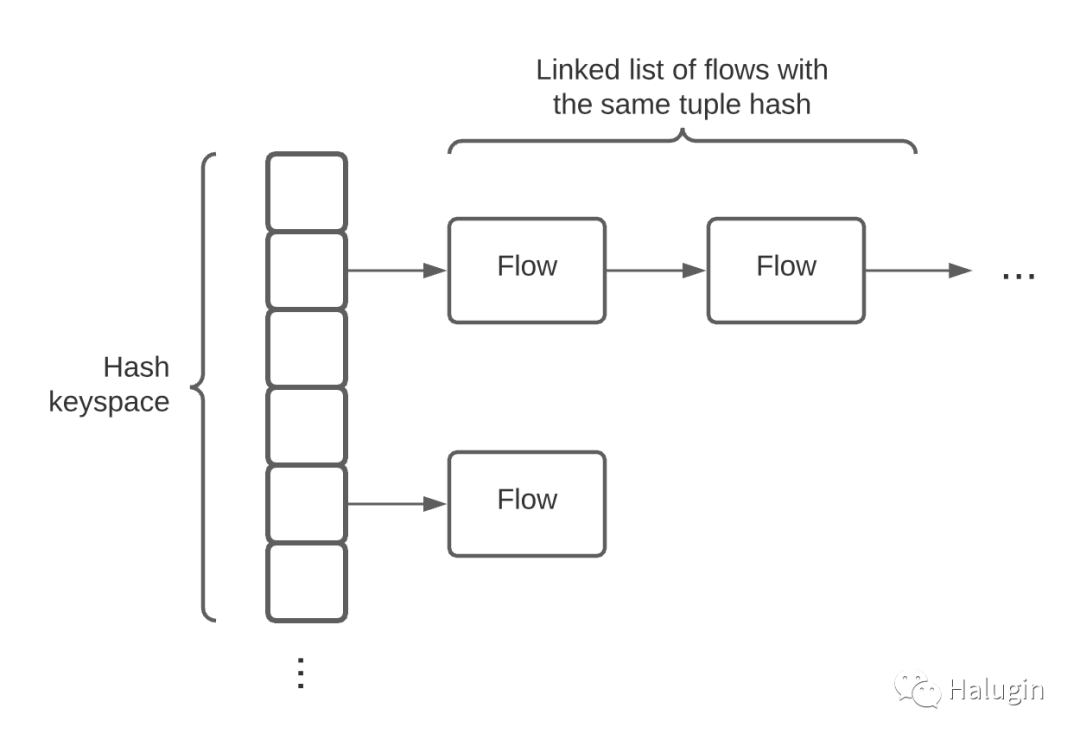
Contact的最大大小一般在/proc/sys/net/nf_conntrack_max
中设置,哈希表大小一般在/sys/module/nf_conntrack/parameters/hashsize
中设置。
Conntrack条目包含一个连接状态,它是四种状态之一。需要注意的是,作为第3层(网络层)工具,conntrack状态与第4层(协议层)状态是不同的。四种状态如表3所示。
| State | Description | Example |
|---|---|---|
| NEW | A valid packet is sent or received, with no response seen. | TCP SYN received. |
| ESTABLISHED | Packets observed in both directions. | TCP SYN received, and TCP SYN/ACK sent. |
| RELATED | An additional connection is opened, where metadata indicates that it is “related” to an original connection. Related connection handling is complex. | A ftp program, with an ESTABLISHED connection, opens additional data connections. |
| INVALID | The packet itself is invalid, or does not properly match another conntrack connection state. | TCP RST received, with no prior connection. |
虽然conntrack
内置在内核中,但它在你的系统上可能不是活动的。必须加载某些内核模块,并且必须有相关的iptables规则(实际上,如果没有什么需要,conntrack通常是不活动的)。Conntrack要求内核模块nf_conntrack_ipv4
处于活动状态。lsmod | grep nf_conntrack
将显示模块是否已加载,sudo modprobe nf_conntrack
将加载它。你可能还需要安装conntrack
CLI以查看conntrack的状态。
当conntrack激活时,conntrack -L
显示所有的流。附加的conntrack
标志将过滤显示的流。
conntrack流,如下所示。
udp 17 11 src=127.0.0.1 dst=127.0.0.53 sport=41440 dport=53 src=127.0.0.53 dst=127.0.0.1 sport=53 dport=41440 [ASSURED] mark=0 use=1udp 17 11 src=192.168.43.193 dst=192.168.43.1 sport=36087 dport=53 src=192.168.43.1 dst=192.168.43.193 sport=53 dport=36087 mark=0 use=1udp 17 11 src=127.0.0.1 dst=127.0.0.53 sport=51757 dport=53 src=127.0.0.53 dst=127.0.0.1 sport=53 dport=51757 mark=0 use=1tcp 6 37 TIME_WAIT src=192.168.43.193 dst=35.224.170.84 sport=40484 dport=80 src=35.224.170.84 dst=192.168.43.193 sport=80 dport=40484 [ASSURED] mark=0 use=1udp 17 1 src=192.168.43.193 dst=192.168.43.1 sport=59830 dport=53 src=192.168.43.1 dst=192.168.43.193 sport=53 dport=59830 mark=0 use=1udp 17 11 src=192.168.43.193 dst=192.168.43.1 sport=34026 dport=53 src=192.168.43.1 dst=192.168.43.193 sport=53 dport=34026 mark=0 use=1tcp 6 15 TIME_WAIT src=192.168.43.193 dst=103.72.47.240 sport=42770 dport=80 src=103.72.47.240 dst=192.168.43.193 sport=80 dport=42770 [ASSURED] mark=0 use=1udp 17 11 src=192.168.43.193 dst=192.168.43.1 sport=55976 dport=53 src=192.168.43.1 dst=192.168.43.193 sport=53 dport=55976 mark=0 use=1tcp 6 431996 ESTABLISHED src=192.168.43.193 dst=151.101.77.132 sport=58392 dport=443 src=151.101.77.132 dst=192.168.43.193 sport=443 dport=58392 [ASSURED] mark=0 use=1tcp 6 431924 ESTABLISHED src=192.168.43.193 dst=34.215.244.109 sport=44348 dport=443 src=34.215.244.109 dst=192.168.43.193 sport=443 dport=44348 [ASSURED] mark=0 use=1tcp 6 431992 ESTABLISHED src=192.168.43.193 dst=52.35.164.79 sport=47258 dport=443 src=52.35.164.79 dst=192.168.43.193 sport=443 dport=47258 [ASSURED] mark=0 use=1tcp 6 431955 ESTABLISHED src=192.168.43.193 dst=151.101.77.132 sport=58378 dport=443 src=151.101.77.132 dst=192.168.43.193 sport=443 dport=58378 [ASSURED] mark=0 use=1tcp 6 431904 ESTABLISHED src=192.168.43.193 dst=183.192.169.15 sport=52994 dport=80 src=183.192.169.15 dst=192.168.43.193 sport=80 dport=52994 [ASSURED] mark=0 use=1tcp 6 431994 ESTABLISHED src=192.168.43.193 dst=44.237.29.232 sport=55404 dport=443 src=44.237.29.232 dst=192.168.43.193 sport=443 dport=55404 [ASSURED] mark=0 use=1tcp 6 54 TIME_WAIT src=192.168.43.193 dst=103.72.47.240 sport=42774 dport=80 src=103.72.47.240 dst=192.168.43.193 sport=80 dport=42774 [ASSURED] mark=0 use=1tcp 6 426044 ESTABLISHED src=192.168.43.193 dst=47.104.16.145 sport=47352 dport=22 src=47.104.16.145 dst=192.168.43.193 sport=22 dport=47352 [ASSURED] mark=0 use=1udp 17 1 src=127.0.0.1 dst=127.0.0.53 sport=33814 dport=53 src=127.0.0.53 dst=127.0.0.1 sport=53 dport=33814 [ASSURED] mark=0 use=1conntrack v1.4.6 (conntrack-tools): 17 flow entries have been shown.
期望的返回数据包的形式为<源ip> <源端口> 。
像grep这样的工具对于检查conntrack状态和特别统计信息很有用,如:
grep ESTABLISHED proc/net/ip_conntrack | wc -l
Routing
当处理任何数据包时,内核必须决定将该数据包发送到哪里。在大多数情况下,目标计算机不在同一个网络中。例如,假设你正试图从你的个人计算机连接到1.2.3.4
。1.2.3.4
不在你的网络上;你的计算机所能做的就是将它传递给另一个接近1.2.3.4
的主机。路由表就是为此服务的,它将已知的子网映射到网关IP地址和接口。你可以用route
(或者route -n
来显示原始IP地址而不是主机名)列出已知的路由。一个典型的机器将有一条本地网络的路由,以及一条0.0.0.0/0的路由。子网可以表示为CIDR(例如,10.0.0.0/24)或IP地址和掩码(例如,10.0.0.0和255.255.255.0)。
下面是一个典型的本地网络上的路由表,可以访问internet。
# routeKernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface0.0.0.0 10.0.0.1 0.0.0.0 UG 303 0 0 eth010.0.0.0 0.0.0.0 255.255.255.0 U 303 0 0 eth0
在上面的例子中,对1.2.3.4
的请求将被发送到eth0
接口上的10.0.0.1
,因为1.2.3.4
在第一条规则(0.0.0.0/0)描述的子网中,而不在第二条规则(10.0.0.0/24)描述的子网中。
Linux更倾向通过匹配最小规则来路由数据包,然后是通过权重(路由输出中的“度量”)。我们的示例中,地址为10.0.0.1
的包总是被发送到网关0.0.0.0
,因为该路由匹配更小的地址集。如果我们有两条具有相同的路线,那么带有较低metric
的路线将是首选。
kubernetes中的CNI插件大量使用路由表。
High Level Routing
Linux具有复杂的包管理能力。这些工具允许Linux用户创建防火墙、记录流量、路由包,甚至实现负载均衡。Kubernetes使用其中一些工具来处理节点和pod连接,以及管理Kubernetes服务。
iptables
一直以来,Iptables一直是Linux系统管理员的必要工具。Iptables可用于创建防火墙和审计日志、更改和重路由数据包。Iptables使用netfilter,它允许Iptables拦截和改变数据包。
Iptables规则可能会变得极其复杂。有许多工具为管理iptables规则提供了一个更简单的界面——例如,像ufw
和firewald
这样的防火墙。Kubernetes组件(特别是kubelet和kube-proxy)以这种方式生成iptables规则。在大多数集群中,理解iptables对于理解pod和节点的访问和路由非常重要。
iptables中有3个关键概念:表、链和规则。它们本质上被认为是分层的:表包含链,链包含规则。
表根据规则所具有的类型来组织规则。Iptables具有广泛的功能,可以将表分组在一起。三个最常用的表是:filter(用于防火墙相关的规则),nat(用于nat相关的规则)和mangle(用于非nat的包变化规则)。Iptables以特定的顺序执行表。
链包含一个规则列表。当包执行链时,链中的规则将按顺序执行。链存在于一个表中,并根据netfilter钩子组织规则。有5个内置的顶级链,每个链对应一个Netfilter钩子。因此,对插入规则的链的选择决定了该规则是否/何时对给定数据包进行评估。
规则是一个组合条件和动作。例如,“如果一个数据包的地址是端口22,那么就放弃它”。Iptables对单个数据包进行操作,尽管链和表规定了对哪个数据包对规则进行操作。
Iptables Tables
iptables中的表映射到特定的功能集,其中每个表“负责”特定类型的操作。更具体地说,一个表只能包含特定的目标类型,许多目标类型只能在特定的表中使用。Iptables共有5个表,如表4所示。
| Table | Purpose |
|---|---|
| Filter | The filter table handles acceptance and rejection of packets. |
| NAT | The NAT table is used to modify the source or destination IP addresses. |
| Mangle | The mangle table can perform general-purpose editing of packet headers, but it is not intended for NAT. It can also “mark” the packet with iptables-only metadata. |
| Raw | The raw table allows for packet mutation, before connection tracking and other tables are handled. Its most common use is to disable connection tracking for some packets. |
| Security | SELinux uses the security table for packet handling. It is not applicable on a machine that is not using SELinux. |
Iptables以特定的顺序执行表:raw, mangle, nat, filter
。然而,这种执行顺序被链打破了。Linux用户普遍接受“表包含链”的说法,但可能会有误导的感觉。执行顺序是链,然后是表。因此,例如,一个包将触发raw PREROUTING
、mangle PREROUTING
、nat PREROUTING
,然后在INPUT
或FORWARD
链中触发mangle表。
Iptables Chains
Iptables的链是一系列规则。当信息包触发或通过链时,将依次计算每个规则,直到信息包匹配“终止目标”(如DROP),或信息包到达链的末端。
内置的“顶级”链是PREROUTING
、INPUT
、NAT
、OUTPUT
和POSTROUTING
。它们由netfilter
钩子提供。每个链对应一个钩子—下面是一个链和钩子映射表。链和钩子对如表5所示。还有用户定义的子链,它们的存在是为了帮助组织规则。
| Iptables Chain | Netfilter Hook |
|---|---|
| PREROUTING | NF_IP_PRE_ROUTING |
| INPUT | NF_IP_LOCAL_IN |
| NAT | NF_IP_FORWARD |
| OUTPUT | NF_IP_LOCAL_OUT |
| POSTROUTING | NF_IP_POST_ROUTING |
一个给定数据包的iptables链执行顺序如图4所示:

像netfilter一样,一个包可以遍历这些链的方法也很有限(假设这个包在途中没有被拒绝或丢弃)。使用一个包含3台机器的示例,它们的IP地址分别是10.0.0.1
、10.0.0.2
和10.0.0.3
。我们将从机器1 (IP地址为10.0.0.1)的角度展示一些路由场景,如表6所示。
| Packet Description | Packet Source | Packet Destination | Tables Processed |
|---|---|---|---|
| An inbound packet, from another machine. | 10.0.0.2 | 10.0.0.1 | PREROUTING, INPUT |
| An inbound packet, not destined for this machine. | 10.0.0.2 | 10.0.0.3 | PREROUTING, NAT, POSTROUTING |
| An outbound packet, originating locally, destined for another machine. | 10.0.0.1 | 10.0.0.2 | OUTPUT,POSTROUTING |
| A packet from a local program is destined for the same machine. | 127.0.0.1 | 127.0.0.1 | OUTPUT, POSTROUTING (then PREROUTING, INPUT as the packet re-enters via the loopback interface) |
当一个包触发一个链时,iptables按照以下顺序执行每个表中的规则:
- Raw
- Mangle
- NAT
- Filter
大多数链并不包含所有的表,但是相对的执行顺序是相同的。这是一个减少冗余的设计决策。例如,原始表的存在是为了操作数据包“进入”iptables
,因此只有PREROUTING
和OUTPUT
链,这与netfilter
的数据包流是一致的。
表7展示了iptables
表分别包含哪些链:
| raw | mangle | nat | filter | |
|---|---|---|---|---|
| PREROUTING | ✓ | ✓ | ✓ | |
| INPUT | ✓ | ✓ | ✓ | |
| FORWARD | ✓ | ✓ | ||
| OUTPUT | ✓ | ✓ | ✓ | ✓ |
| POSTROUTING | ✓ | ✓ |
可以使用iptables -L -t <table>
列出机器上的表对应的链:
root@gwz:~# iptables -L -t filterChain INPUT (policy ACCEPT) target prot opt source destination LIBVIRT_INP all -- anywhere anywhere Chain FORWARD (policy ACCEPT) target prot opt source destination LIBVIRT_FWX all -- anywhere anywhere LIBVIRT_FWI all -- anywhere anywhere LIBVIRT_FWO all -- anywhere anywhere Chain OUTPUT (policy ACCEPT) target prot opt source destination LIBVIRT_OUT all -- anywhere anywhere Chain LIBVIRT_FWI (1 references) target prot opt source destination ACCEPT all -- anywhere 192.168.122.0/24 ctstate RELATED,ESTABLISHED REJECT all -- anywhere anywhere reject-with icmp-port-unreachable Chain LIBVIRT_FWO (1 references) target prot opt source destination ACCEPT all -- 192.168.122.0/24 anywhere REJECT all -- anywhere anywhere reject-with icmp-port-unreachable Chain LIBVIRT_FWX (1 references) target prot opt source destination ACCEPT all -- anywhere anywhere Chain LIBVIRT_INP (1 references) target prot opt source destination ACCEPT udp -- anywhere anywhere udp dpt:domain ACCEPT tcp -- anywhere anywhere tcp dpt:domain ACCEPT udp -- anywhere anywhere udp dpt:bootps ACCEPT tcp -- anywhere anywhere tcp dpt:67Chain LIBVIRT_OUT (1 references) target prot opt source destination ACCEPT udp -- anywhere anywhere udp dpt:domain ACCEPT tcp -- anywhere anywhere tcp dpt:domain ACCEPT udp -- anywhere anywhere udp dpt:bootpc ACCEPT tcp -- anywhere anywhere tcp dpt:68
对于NAT表:DNAT只能在PREROUTING或OUTPUT中执行,SNAT只能在INPUT或POSTROUTING中执行。
举个例子,假设我们有一个以主机为目的地的入站包。执行顺序如下:
- PREROUTING:raw-→mangle-→nat
- INPUT:managle-→nat-→filter
我们已经理解了netfilter钩子、表和链,让我们来看一下通过iptables
的数据包流,如图5所示。
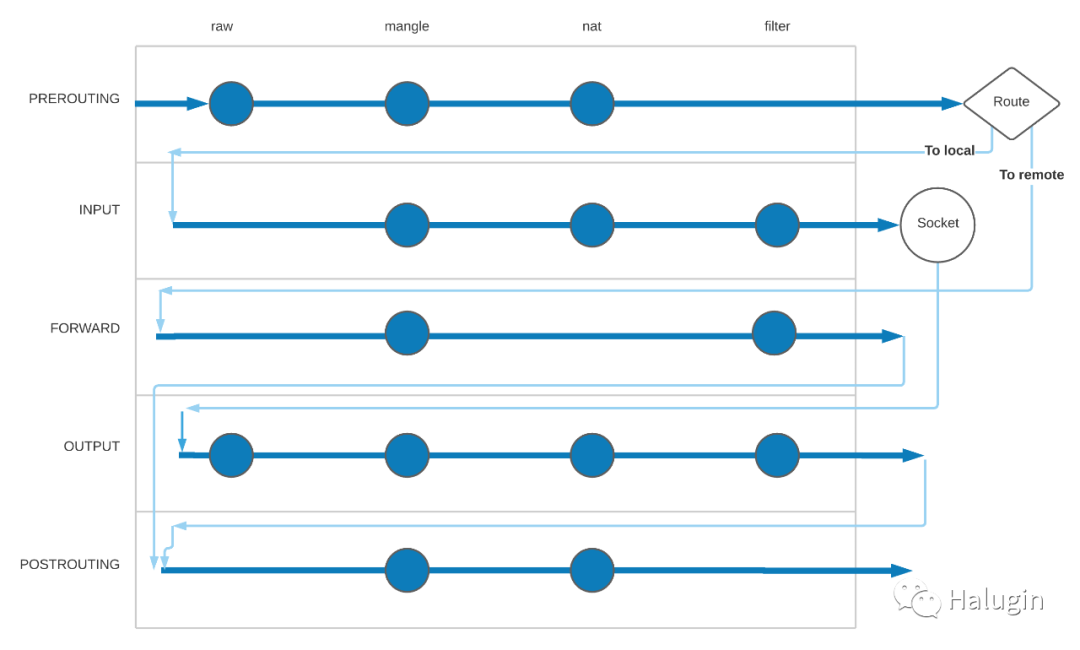
所有iptables
规则都属于一个表和链,它们的可能组合在我们的流程图中以点表示。Iptables
根据数据包触发的netfilter
钩子的顺序执行链(以及链中的规则)。对于给定的链,iptables
在它所在的每个表中计算该链(注意,有些链/表组合不存在,例如filter/POSTROUTING
)。如果我们跟踪一个来自本地主机的数据包的流,我们会看到以下表/链的顺序:
- raw/OUTPUT
- mangle/OUTPUT
- nat/OUTPUT\
- filter/OUTPUT
- mangle/POSTROUTING
- nat/POSTROUTING
Subchains
上述链是顶级链,内置链。用户也可以定义自己的子链,并使用JUMP
目标执行它们。Iptables
以相同的方式执行这样的链—一个目标一个目标,直到一个终止的目标匹配为止。这可以用于逻辑分离,或重用一系列可以在多个上下文中执行的目标(例如,类似于我们为什么要将代码组织成函数)。这种跨链的规则组织可能会对性能产生重大影响。Iptables
实际上是对进出系统的每个包运行数十条、数百条或数千条if
语句。这对包延迟、cpu
使用和网络吞吐量有一定的影响。一组组织良好的链通过有效地消除冗余检查或操作来减少这种开销。在Kubernetes中,对于包含许多pod
的服务,iptables
的性能仍然是一个问题,这使得其他使用较少或不使用iptables
的解决方案(如IPVS
或eBPF
)更有吸引力。
实例6展示了如何创建新的链:
# Create incoming-ssh chain.$ iptables -N incoming-ssh# Allow packets from specific IPs.$ iptables -A incoming-ssh -s 10.0.0.1 -j ACCEPT $ iptables -A incoming-ssh -s 10.0.0.2 -j ACCEPT# Log the packet.$ iptables -A incoming-ssh -j LOG --log-level info --log-prefix "ssh-failure "# Drop packets from all other IPs.$ iptables -A incoming-ssh -j DROP# Evaluate the incoming-ssh chain, if the packet is an inbound TCP packet addressed to port 22.$ iptables -A INPUT -p tcp --dport 22 -j incoming-ssh
这个示例创建了一个新的链incoming-ssh
,将对端口22
上的任何入站TCP
包进行匹配。该链允许来自2个特定IP地址的数据包,而来自其他地址的数据包将被记录并丢弃。
filter
链以一个默认动作结束,例如,如果没有先前的目标匹配,DROP
数据包。如果没有指定默认值,chain
将默认为ACCEPT
。可以使用iptables -P
设置默认值。
Iptables Rules
规则由两部分组成:一个匹配条件和一个动作(称为目标)。匹配条件用来描述报文的属性。如果报文匹配,则执行该动作。如果数据包不匹配,iptables
将移动到下一个规则。
匹配条件检查给定的数据包是否满足某些条件—例如,如果数据包具有特定的源地址。表/链的操作顺序很重要,因为之前的操作可能会影响包常见的匹配类型如表8所示。
| Match Type | Flag(s) | Description |
|---|---|---|
| Source | -s, --src, --source | Matches packets with the specified source address. |
| Destination | -d, --dest, --destination | Matches packets with the destination source address. |
| Protocol | -p, --protocol | Matches packets with the specified protocol. |
| In Interface | -i, --in-interface | Matches packets that entered via the specified interface. |
| Out Interface | -o, --out-interface | Matches packets that are leaving the specified interface. |
| State | -m state --state <states> | Matches packets from connections that are in one of the comma-separated states. This uses the conntrack states (NEW, ESTABLISHED, RELATED, INVALID). |
Iptables
支持匹配“扩展”使用
-m
或--match
,iptables
可以使用扩展作为匹配条件。扩展范围很广,如在单个规则中指定多个端口(multiport
),以及更复杂的功能,如eBPF
交互。
有两种目标操作:终止和非终止。终止目标将阻止iptables
检查链中的后续目标,这实际上是一个最终决定。一个非终止的目标将允许iptables继续检查链中的后续目标。ACCEPT
、DROP
、REJECT
和RETURN
都是终止目标。注意,ACCEPT
和RETURN
仅在其链内终止。也就是说,如果一个包命中了子链中的ACCEPT目标,父链将继续处理,并可能DROP
或拒绝目标。示例7显示了一组规则,这些规则将拒绝数据包到端口80
,尽管在某个点匹配了ACCEPT
。
root@gwz:~# iptables -L --line-numbersChain INPUT (policy ACCEPT) num target prot opt source destination1 accept-all all -- anywhere anywhere2 REJECT tcp -- anywhere anywhere tcp dpt:80 reject-with icmp-port-unreachable Chain accept-all (1 references) num target prot opt source destination1 all -- anywhere anywhere ```
表2-9包含了常见目标类型及其行为。
| Target Type | Applicable Tables | Description |
|---|---|---|
| AUDIT | All | Records data about accepted, dropped, or rejected packets. |
| ACCEPT | filter | Allows the packet to continue, unimpeded and without further modification. |
| DNAT | nat | Modifies the destination address. |
| DROPs | filter | Discards the packet. To an external observer, it will appear as though the packet was never received. |
| JUMP | All | Executes another chain. Once that chain finishes executing, execution of the parent chain will continue. |
| LOG | all | Logs the packet contents, via the kernel log. |
| MARK | All | Sets a special integer for the packet, used as an identifier by netfilter. The integer can be used in other iptables decisions, and is not written to the packet itself. |
| MASQUERADE | nat | Modifies the source address of the packet, replacing it with the address of a specified network interface. This is similar to SNAT, but does not require the machine’s IP address to be known in advance. |
| REJECT | filter | Discards the packet, and sends a rejection reason. |
| RETURN | All | Stops processing the current chain (or sub-chain). Note that this is not a terminating target, and if there is a parent chain, that chain will continue to be processed. |
| SNAT | nat | Modifies the source address of the packet, replacing it with a fixed address. See also: MASQUERADE. |
每个目标类型可能有特定的选项,例如应用于规则的端口或日志字符串。命令示例及解释如表10所示。
| Command | Explanation |
|---|---|
| iptables -A INPUT -s 10.0.0.1 | 如果源地址为10.0.0.1,则接受入站数据包。 |
| iptables -A INPUT -p ICMP | 接受所有入方向的ICMP报文。 |
| iptables -A INPUT -p tcp —dport 443 | 接受所有入站的TCP数据包到端口443。 |
| iptables -A INPUT -p tcp —dport 22 -j DROP | 删除所有入站TCP端口到端口22。 |
一个目标同时属于一个表和一个链,对于给定的数据包,它控制着iptables何时(如果有的话)执行前面提到的目标。
Iptables实践
iptables
和ip6tables
规则是完全独立的。本文只介绍iptables
和IPv4地址。
Iptables
规则不会在重启时持久保存。Iptables
提供了iptables -save
和iptables -restore
工具,这些工具可以手动使用,也可以通过简单的自动化来捕获或重新加载规则。大多数防火墙工具在每次系统启动时都会自动创建自己的iptables
规则。
可以使用iptables -L
显式iptables
链。
$ iptables -L Chain INPUT (policy ACCEPT) target prot opt source destination Chain FORWARD (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination
--line-numbers
显示链中每个规则的数字。这在插入或删除规则时很有帮助。-I
在指定的行号插入一个规则,在该行的前一个规则之前。
iptables
命令格式为:iptables [-t table] {-A|-C|-D} chain rule-specification
其中-A
表示追加,-C
表示检查,-D
表示删除。
iptables
可以伪装连接,使数据包看起来像是来自它自己的IP地址。一个常见的用例是为通信提供一个已知的主机,作为安全堡垒,或者为第三方提供一组可预测的IP地址。在Kubernetes中,伪装可以使pod
使用其节点的IP地址,尽管pod
有唯一的IP地址。在许多设置中,这对于在集群外部进行通信是必要的,在这些设置中,pod
具有不能直接与Internet通信的内部IP地址。MASQUERADE
目标类似于SNAT,但是它不需要预先知道和指定--source-address
,它使用指定接口的地址。
$iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
iptables
可以执行连接级负载平衡。这种技术依赖于DNAT规则和随机选择(以防止每个连接被路由到第一个DNAT目标)。
$ iptables -t nat -A OUTPUT -p tcp --dport 80 -d $FRONT_IP -m statistic \ --mode random --probability 0.5 -j DNAT --to-destination $BACKEND1_IP:80$ iptables -t nat -A OUTPUT -p tcp --dport 80 -d $FRONT_IP \ -j DNAT --to-destination $BACKEND2_IP:80
在上面的例子中,有50%的机会路由到第一个后端。否则,数据包将继续执行下一个规则,该规则保证将连接路由到第二个后端。
Chain KUBE-SVC-I7EAKVFJLYM7WH25 (1 references) target prot opt source destination KUBE-SEP-LXP5RGXOX6SCIC6C all -- anywhere anywhere statistic mode random probability 0.25000000000KUBE-SEP-XRJTEP3YTXUYFBMK all -- anywhere anywhere statistic mode random probability 0.33332999982KUBE-SEP-OMZR4HWUSCJLN33U all -- anywhere anywhere statistic mode random probability 0.50000000000KUBE-SEP-EELL7LVIDZU4CPY6 all -- anywhere anywhere
当Kubernetes为一个服务使用iptables
负载平衡时,它会创建一个类似于上面的链。
使用DNAT进行负载平衡有几个注意事项。它对给定后端的加载没有反馈,并且总是将同一连接上的应用程序级查询映射到同一后端。由于DNAT结果持续连接的生命周期,如果长生命周期的连接是常见的,许多下游客户端可能会坚持使用相同的上游后端。举一个Kubernetes的例子,假设一个gRPC
服务只有2个副本,然后额外的副本可以扩展。gRPC
重用相同的HTTP/2
连接,因此现有的下游客户端(使用Kubernetes服务,而不是gRPC
负载均衡)将保持与最初的2个副本的连接,从而改变gRPC
后端之间的负载配置。因此,许多开发人员使用更智能的客户端(例如使用gRPC
的客户端负载平衡),强制服务器或客户端定期重新连接,或者使用服务网格来外部化问题。
尽管iptables
在Linux中被广泛使用,但由于存在大量的规则,它可能会变得很慢,并且提供非常有限的负载平衡功能。接下来介绍IPVS
,这是一种更适合负载平衡的替代方案。
IPVS
IPVS (IP Virtual Server)是一个Linux连接(L4-4层)负载均衡器。图6显示了IPVS在路由报文中的角色示意图。

iptables可以通过随机路由连接来实现简单的L4负载平衡,其随机性由单个DNAT规则上的权重决定。与iptables不同,IPVS支持多种负载均衡模式,如表11所示。这使得IPVS比iptables更有效地分担负载,这取决于IPVS的配置和流量模式。
| Name | Shortcode | Description |
|---|---|---|
| Round-robin | rr | Sends subsequent connections to the “next” host in a cycle. This increases the time between subsequent connections sent to a given host, compared to random routing like iptables enables. |
| Least connection | lc | Sends connections to the host that currently has the least open connections. |
| Destination hashing | dh | Sends connections deterministically to a specific host, based on the connection’s destination addresses. |
| Source hashing | sh | Sends connections deterministically to a specific host, based on the connections’ source addresses. |
| Shortest expected delay | sed | Sends connections to the host with the lowest connections to weight ratio. |
| Never queue | nq | Sends connections to any host with no existing connections, otherwise uses “shortest expected delay” strategy. |
IPVS支持报文转发方式如下:
- NAT-重写源地址和目的地址
- DR-在IP数据报中封装IP数据报
- IP Tunneling-通过将数据帧的MAC地址改写为所选后端服务器的MAC地址,将报文直接路由到后端服务器。
iptables作为负载平衡器的问题时,有三个方面需要考虑。
集群内节点数量
尽管Kubernetes在v1.6版中已经支持5000个节点,但是kube-proxy和iptables仍然是集群扩展到5000个节点的瓶颈。一个例子是,在一个5000节点的集群中使用NodePort Service,如果我们有2000个服务,每个服务有10个pod,这将导致每个工作节点上至少有20000个iptables记录,这会导致内核非常繁忙。
时间
当有5k服务(40k规则)时,添加一条规则花费的时间:11分钟;20k服务(160k规则)时需要花费的时间:5小时。
延迟(Latency)
访问服务的延迟(路由延迟),每个包必须遍历iptables列表,直到匹配完成。
IPVS还支持会话保持性,这是Services (service.spec.
)中的一个选项。sessionAffinity
和service.spec.sessionAffinityConfig
)。在会话关联时间窗口内的重复连接将路由到相同的主机。这对于最小化缓存丢失等场景非常有用。它还可以使任何模式下的路由有效地有状态(通过将连接从相同的地址无限地路由到相同的主机),但是在Kubernetes中,路由粘性不是绝对的,在Kubernetes中,各个pod来去不定。
执行命令ipvsadm -A -t -s
,创建两个相同权重的基本负载均衡器。-A、-E、-D
分别用于添加、编辑、删除虚拟服务。-a、-e、-d
分别用于添加、编辑和删除主机后端。
# ipvsadm -A -t 1.1.1.1:80 -s lc# ipvsadm -a -t 1.1.1.1:80 -r 2.2.2.2 -m -w 100# ipvsadm -a -t 1.1.1.1:80 -r 3.3.3.3 -m -w 100
可以使用-L
列出所有IPVS主机。每个虚拟服务器(一个唯一的IP地址和端口组合)及其后端都会显示出来。
# ipvsadm -LIP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 1.1.1.1.80:http lc -> 2.2.2.2:http Masq 100 0 0 -> 3.3.3.3:http Masq 100 0 0
-L
支持多个选项,例如--stats
来显示额外的连接统计信息。
网络故障诊断工具
网络故障排查至关重要,我们将介绍一些关键的网络故障排除工具,以及它们的使用基础(表12提供了工具和适用用例)。
| Case | Tools |
|---|---|
| Checking connectivity | Traceroute, Ping, Telnet, Netcat |
| Port scanning | Nmap |
| Checking DNS records | Dig, commands mentioned in “Checking connectivity” |
| Checking HTTP/1 | Curl, Telnet, Netcat |
| Checking HTTPS | OpenSSL, Curl |
| Checking listening programs | Netstat |
所描述的一些网络工具可能不会预先安装在你选择的发行版中,但所有这些工具都应该可以通过你的发行版的包管理器获得。
Ping
Ping是一个简单的程序,它向网络设备发送ICMP ECHO_REQUEST
报文。这是测试从一个主机到另一个主机的网络连通性的一种常见、简单的方法。
ICMP是一种第4层协议,类似于TCP和UDP。Kubernetes服务支持TCP和UDP,不支持ICMP。这意味着对Kubernetes服务的ping总是会失败。需要使用telnet或更高级别的工具(如curl)来检查到服务的连通性。根据不同的网络配置,仍然可以通过ping访问单个pod。
ping的基本用途ping <address>
。地址可以是IP,也可以是域。当响应或超时发生时,Ping将发送一个包、等待并报告该请求的状态。
默认情况下,ping将一直发送数据包,必须手动停止(例如,使用ctrl-c
)。-c
将使命令在关闭之前执行固定数量的ping。停止时,ping还打印一个摘要。
root@gwz:~# ping -c 5 k8s.ioPING k8s.io(2600:1901:0:26f3:: (2600:1901:0:26f3::)) 56 data bytes64 bytes from 2600:1901:0:26f3:: (2600:1901:0:26f3::): icmp_seq=1 ttl=51 time=69.6 ms64 bytes from 2600:1901:0:26f3:: (2600:1901:0:26f3::): icmp_seq=2 ttl=51 time=110 ms64 bytes from 2600:1901:0:26f3:: (2600:1901:0:26f3::): icmp_seq=3 ttl=51 time=90.4 ms64 bytes from 2600:1901:0:26f3:: (2600:1901:0:26f3::): icmp_seq=4 ttl=51 time=82.6 ms64 bytes from 2600:1901:0:26f3:: (2600:1901:0:26f3::): icmp_seq=5 ttl=51 time=82.4 ms --- k8s.io ping statistics ---5 packets transmitted, 5 received, 0% packet loss, time 8198ms rtt min/avg/max/mdev = 69.574/86.909/109.624/13.173 ms
ping的常用选项如表13所示:
| Option | Description |
|---|---|
| -c | Sends the specified number of packets. Exits after the final packet is received or times out. |
| -i | Sets the wait interval between sending packets. Defaults to 1 second. Extremely low values are not recommended, as ping can flood the network. |
| -o | Exit after receiving 1 packet. Equivalent to -c 1. |
| -S | Uses the specified source address for the packet. |
| -W | Sets the wait interval to receive a packet. If ping receives the packet later than the wait time, it will still count towards the final summary. |
Traceroute
Traceroute显示从一个主机到另一个主机的网络路由。验证和调试从一台机器到另一台机器的路由(或路由失败的地方)。
Traceroute发送带有特定IP生存时间值的报文。每个处理数据包的主机将数据包上的生存时间(TTL)值减1,因此限制了可以处理请求的主机数量。当主机收到一个数据包时,将TTL减为0,发送一个TIME_EXCEEDED数据包,丢弃原来的数据包。TIME_EXCEEDED响应包包含包超时所在机器的源地址。traceroute从TTL为1开始,并将每个包的TTL增加1,就能从路由的每台主机获得到目的地址的响应。
Traceroute从第一台外部主机开始,逐行显示主机。每一行包含主机名(如果可用)、IP地址和响应时间。
root@gwz:~# traceroute k8s.iotraceroute to k8s.io (34.107.204.206), 30 hops max, 60 byte packets 1 _gateway (192.168.43.1) 3.950 ms 6.660 ms 8.209 ms 2 * * * 3 localhost (172.20.11.33) 44.779 ms 44.796 ms 44.788 ms 4 * * * 5 . (117.135.57.49) 45.822 ms 45.800 ms 45.780 ms 6 . (117.135.41.57) 44.651 ms . (117.135.41.65) 34.513 ms 36.162 ms 7 111.24.4.105 (111.24.4.105) 48.819 ms 111.24.3.117 (111.24.3.117) 33.243 ms 49.880 ms 8 221.183.89.37 (221.183.89.37) 50.519 ms 221.183.89.1 (221.183.89.1) 50.504 ms 111.24.4.70 (111.24.4.70) 50.416 ms 9 221.176.22.14 (221.176.22.14) 49.477 ms 221.176.22.34 (221.176.22.34) 49.429 ms 221.183.89.34 (221.183.89.34) 54.590 ms10 221.183.25.194 (221.183.25.194) 51.878 ms 39.119 ms 221.183.25.190 (221.183.25.190) 36.737 ms11 223.120.3.193 (223.120.3.193) 66.040 ms 221.183.55.49 (221.183.55.49) 39.564 ms 38.831 ms12 223.120.12.25 (223.120.12.25) 333.983 ms 223.120.15.29 (223.120.15.29) 334.670 ms 223.120.15.89 (223.120.15.89) 334.634 ms13 142.250.161.154 (142.250.161.154) 331.748 ms 223.120.10.198 (223.120.10.198) 331.679 ms 223.119.17.154 (223.119.17.154) 79.006 ms14 108.170.242.225 (108.170.242.225) 315.210 ms 216.239.41.149 (216.239.41.149) 295.791 ms 209.85.244.23 (209.85.244.23) 67.743 ms15 216.239.41.53 (216.239.41.53) 269.268 ms 216.239.41.149 (216.239.41.149) 271.056 ms 142.251.65.137 (142.251.65.137) 227.234 ms16 172.253.65.211 (172.253.65.211) 265.567 ms 142.251.54.47 (142.251.54.47) 301.841 ms 206.204.107.34.bc.googleusercontent.com (34.107.204.206) 94.169 ms
如果traceroute在超时之前没有收到来自给定跳的响应,它打印一个*
。一些主机可能会拒绝发送TIME_EXCEEDED
数据包,或者沿途的防火墙可能会阻止成功的传递。
traceroute常用选项如表14所示。
| Option | Syntax | Description |
|---|---|---|
| First TTL | -f <TTL>, -M <TTL> | Set the starting IP TTL (default value: 1). Setting the TTL to nwill cause traceroute to not report the first n-1hosts en-route to the destination. |
| Max TTL | -m <TTL> | Set the maximum TTL, i.e., the maximum number of hosts that traceroute will attempt to route through. |
| Protocol | -P <protocol> | Send packets of the specified protocol (TCP, UDP, ICMP, and sometimes other options). UDP is default. |
| Source Address | -s <address> | Specify the source IP address of outgoing packets. |
| Wait | -w <seconds> | Set the time to wait for a probe response. |
Dig
Dig是一个DNS查找工具。可以使用它从命令行进行DNS查询,并显示结果。
root@gwz:~# dig k8s.io; <<>> DiG 9.16.8-Ubuntu <<>> k8s.io ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 53887;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 65494;; QUESTION SECTION: ;k8s.io. IN A ;; ANSWER SECTION: k8s.io. 2665 IN A 34.107.204.206;; Query time: 3 msec ;; SERVER: 127.0.0.53#53(127.0.0.53);; WHEN: 三 9月 01 14:10:01 CST 2021;; MSG SIZE rcvd: 51
执行dig
(或dig -t
)命令,查询特定类型的DNS记录。
root@gwz:~# dig k8s.io TXT; <<>> DiG 9.16.8-Ubuntu <<>> k8s.io TXT ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 58141;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 65494;; QUESTION SECTION: ;k8s.io. IN TXT ;; ANSWER SECTION: k8s.io. 3600 IN TXT "v=spf1 include:_spf.google.com ~all"k8s.io. 3600 IN TXT "google-site-verification=RJbZ_ganmSWvslSKOBG-QHv62XTjJZcigpWIFttStFs";; Query time: 495 msec ;; SERVER: 127.0.0.53#53(127.0.0.53);; WHEN: 三 9月 01 14:11:56 CST 2021;; MSG SIZE rcvd: 164
Dig的选项如表15所示:
| Option | Syntax | Description |
|---|---|---|
| IPv4 | -4 | Use IPv4 only. |
| IPv6 | -6 | Use IPv6 only. |
| Address | -b <address>[#<port>] | Specify the address to make a DNS query to. Port can optionally be included, preceded by #. |
| Port | -p <port> | Specify the port to query, in case DNS is exposed on a nonstandard port. Default is 53, the DNS standard. |
| Domain | -q <domain> | The domain name to query. The domain name is usually specified as a positional argument. |
| Record Type | -t <type> | The DNS record type to query. The record type can alternatively be specified as a positional argument. |
Telnet
Telnet既是一种网络协议,也是使用该协议的工具。Telnet曾经用于远程登录,其方式类似于SSH。由于具有更好的安全性,SSH已经成为主流,但是telnet对于调试使用基于文本协议的服务器仍然非常有用。使用telnet,可以连接到HTTP/1服务器并手动向它发出请求。
telnet的基本语法是telnet <address> <port>
。建立一个连接,并提供一个交互式命令行接口。按两次回车键将发送一个命令,这可以轻松地编写多行命令。按ctrl-]
退出会话。
root@gwz:/data/go# telnet ali 8080Trying 47.104.16.145... Connected to ali. Escape character is '^]'. HEAD / HTTP/1.1Host: ali HTTP/1.1 200 OK Date: Wed, 01 Sep 2021 06:43:26 GMT Content-Length: 5Content-Type: text/plain; charset=utf-8
要充分利用telnet,需要了解正在使用的应用程序协议是如何工作的。Telnet是调试运行HTTP、HTTPS、POP3、IMAP
等服务器的经典工具。
Nmap
Nmap是一个端口扫描器,用来探测和检查网络上的服务。
nmap的一般语法为nmap [options] <target>
,其中target为域、IP地址或IP CIDR。Nmap的默认选项将给出一个主机上开放的端口。
root@gwz:/data/go# nmap aliStarting Nmap 7.80 ( https://nmap.org ) at 2021-09-01 14:46 CST Nmap scan report for ali (47.104.16.145) Host is up (0.057s latency). Not shown: 993 closed ports PORT STATE SERVICE22/tcp open ssh135/tcp filtered msrpc139/tcp filtered netbios-ssn445/tcp filtered microsoft-ds593/tcp filtered http-rpc-epmap4444/tcp filtered krb5248080/tcp open http-proxy
在上面的例子中,nmap检测到多个开放的端口,并描述每个端口上运行的是哪个服务。
Nmap有很多可用选项,可以改变扫描行为和提供的细节级别。
Nmap的可用选项如表16所示:
| Option | Syntax | Description |
|---|---|---|
| Additional detection | -A | Enable OS detection, version detection, and more. |
| Decrease Verbosity | -d | Decrease the command verbosity. Using multiple ds (e.g., -dd) increases the effect. |
| Increase Verbosity | -v | Increase the command verbosity. Using multiple vs (e.g., -vv) increases the effect. |
Netstat
Netstat可以显示关于计算机网络堆栈和连接的信息。
root@gwz:~# netstat | more激活Internet连接 (w/o 服务器) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 gwz:48746 ali:ssh ESTABLISHED tcp 0 0 gwz:37724 112.25.104.13:http TIME_WAIT tcp 0 0 gwz:52554 ec2-35-161-228-11:https ESTABLISHED tcp 0 0 gwz:35700 103.72.47.241:http TIME_WAIT tcp 0 0 gwz:52714 .:http-alt ESTABLISHED tcp 0 0 gwz:58938 ec2-44-240-60-232:https ESTABLISHED tcp 0 0 gwz:56316 151.101.77.132:https ESTABLISHED tcp 0 0 gwz:34430 ec2-35-164-243-16:https ESTABLISHED udp 0 0 gwz:bootpc _gateway:bootps ESTABLISHED 活跃的UNIX域套接字 (w/o 服务器) Proto RefCnt Flags Type State I-Node 路径 unix 2 [ ] 数据报 31278 /run/user/0/systemd/not ify unix 2 [ ] 数据报 27414 /run/wpa_supplicant/wlp2s0
不带其他参数调用netstat将显示计算机上所有连接的套接字。输出包括连接两端的地址(IP地址和端口)。
我们可以使用-a
标志来显示所有连接,或者使用-l
标志来只显示正在监听的连接。
root@gwz:~# netstat -a激活Internet连接 (服务器和已建立连接的) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:8680 0.0.0.0:* LISTEN tcp 0 0 view-localhost:37065 0.0.0.0:* LISTEN tcp 0 0 gwz:domain 0.0.0.0:* LISTEN tcp 0 0 localhost:domain 0.0.0.0:* LISTEN tcp 0 0 view-localhost:ipp 0.0.0.0:* LISTEN tcp 0 0 gwz:48746 ali:ssh ESTABLISHED tcp 0 0 gwz:56386 151.101.77.132:https ESTABLISHED
netstat的一个常见用途是检查哪个进程正在侦听特定的端口。为此,我们运行sudo netstat -lp -l
表示“listening”,p表示“program”。为了让netstat查看所有程序信息,Sudo可能是必要的。l
的输出显示服务正在侦听哪个地址(例如,0.0.0.0或127.0.0.1)
当我们寻找一个特定的结果时,我们可以使用像grep
这样的简单工具从netstat获得一个清晰的输出。
root@gwz:~# netstat -tnl | grep 8080tcp6 0 0 :::8080 :::* LISTEN
netstat常用选项如表17所示:
| Option | Syntax | Description |
|---|---|---|
| Show all sockets | netstat -a | Show all sockets, not only open connections. |
| Show statistics | netstat -s | Shows networking statistics. By default, netstat shows stats from all protocols. |
| Show listening sockets | netstat -l | Shows sockets that are listening. This is an easy way to find running services. |
| TCP | netstat -t | The -tflag shows only TCP data. It can be used with other flags, e.g., -lt(show sockets listening with TCP). |
| UDP | netstat -u | The -uflag shows only UDP data. It can be used with other flags, e.g., -lu(show sockets listening with UDP). |
Netcat
Netcat是一个用于连接、发送数据或在套接字上监听的多用途工具。它可以作为一种“手动”运行服务器或客户机的方法,以更详细地检查发生了什么。
当调用Netcat 时,Netcat可以连接到服务器。Netcat有一个交互式的标准输入,它允许手动输入数据,或通过管道将数据输入Netcat。
root@gwz:~# echo -e "GET / HTTP/1.1\nHost: localhost\n" > cmdroot@gwz:~# nc localhost 8080 < cmdHTTP/1.1 200 OK Date: Wed, 01 Sep 2021 07:04:50 GMT Content-Length: 13Content-Type: text/plain; charset=utf-8hello zhangge
openssl
OpenSSL的大多数繁重工作都是通过语言绑定完成的,它也有一个用于操作任务和调试的CLI。openssl可以做一些事情,比如创建密钥和证书、签名证书,以及测试TLS/SSL连接。许多其他工具都可以测试TLS/SSL连接。然而,OpenSSL以其丰富的特性和详细程度脱颖而出。
命令通常采用openssl [sub-command] [arguments] [options]
的形式。Openssl有大量的子命令(例如,Openssl rand
生成伪随机数据)。要了解更多关于单个子命令的信息,可以查看openssl --help
。
root@gwz:~# openssl --helpStandard commands asn1parse ca ciphers cms crl crl2pkcs7 dgst dhparam dsa dsaparam ec ecparam enc engine errstr gendsa
openssl s_client -connect
将连接到服务器,并显示关于服务器证书的详细信息。
root@gwz:~# openssl s_client -connect k8s.io:443CONNECTED(00000003) depth=2 C = US, O = Google Trust Services LLC, CN = GTS Root R1 verify return:1depth=1 C = US, O = Google Trust Services LLC, CN = GTS CA 1D4 verify return:1depth=0 CN = k8s.io verify return:1--- Certificate chain 0 s:CN = k8s.io i:C = US, O = Google Trust Services LLC, CN = GTS CA 1D4 1 s:C = US, O = Google Trust Services LLC, CN = GTS CA 1D4 i:C = US, O = Google Trust Services LLC, CN = GTS Root R1 2 s:C = US, O = Google Trust Services LLC, CN = GTS Root R1 i:C = BE, O = GlobalSign nv-sa, OU = Root CA, CN = GlobalSign Root CA --- subject=CN = k8s.io issuer=C = US, O = Google Trust Services LLC, CN = GTS CA 1D4 --- No client certificate CA names sent Peer signing digest: SHA256 Peer signature type: RSA-PSS Server Temp Key: X25519, 253 bits --- SSL handshake has read 5586 bytes and written 378 bytes Verification: OK --- New, TLSv1.3, Cipher is TLS_AES_256_GCM_SHA384 Server public key is 2048 bit Secure Renegotiation IS NOT supported Compression: NONE Expansion: NONE No ALPN negotiated Early data was not sent Verify return code: 0 (ok) ---
如果你正在使用自签名CA,则可以使用-CAfile <path>
来使用该CA。这将允许你根据自签名证书建立和验证连接。
Curl
Curl是一个支持多种协议的数据传输工具,主要支持HTTP和HTTPS。
Curl命令的格式为curl [options] url
。Curl将URL的内容打印到stdout,默认行为是发出HTTP GET请求。
root@gwz:~# curl ali<html>章哥kubernetes学堂,www.zhanggek8s.com</html>
默认情况下,curl不执行重定向,例如HTTP 301或协议升级。-L
标志(或--location
)将启用以下重定向。
root@gwz:~# curl kubernetes.io Redirecting to https://kubernetes.io/ root@gwz:~# curl -L kubernetes.io<!doctype html><html lang="en" class=" no-js"> <head><script async src="https://www.googletagmanager.com/gtag/js?id=UA-36037335-10"></script><script>......
使用-X
选项来执行一个特定的HTTP操作,例如curl -X DELETE foo/bar
来发出一个DELETE请求。
可以通过以下几种方式提供数据(用于POST、PUT等):
- Urlencoded:
-d "key1=value1&key2=value2" - JSON:
-d '{"key1":"value1", "key2":"value2"}' - As a file in either format:
-d @data.txt
-h
选项添加了一个显式的头文件,content-type这样的基本头文件是自动添加的。
-H "Content-Type: application/x-www-form-urlencoded"
curl更多的功能,可以使用man curl
查看。
总结
以上为Linux网络的基础内容,深入学习请参考书籍《深入理解Linux网络内幕》。
感兴趣的关注如下公众号!

