2019 年 12 月 7 日,由华为云举办的「DevRun Summit:Login 2020」正式登陆「751 D•PARK 北京时尚设计广场 79 罐」。
本次活动内容主要设置了「技术分享」与「互动体验」两大部分;其中,来自华为、哔哩哔哩、差评等企业的技术大咖纷纷加入了这 8 大交流分享会中。
技术专场一:新计算架构与开源实践
近两年来,随着社会对技术领域中计算架构的认知逐步加深,多元架构也是华为所倡导的业界主流共识。但我们所知道的也仅仅只是鲲鹏和昇腾已经发布,而它们神秘的面纱似乎一直从未揭开。正因如此,这次活动特意为「鲲鹏」处理器、「昇腾」开发工具链及它们的开源实践设置了专场,为好奇的开发者们提供了最直观、最全面的展示。
鲲鹏大数据高级工程师顾刚老师为大家带来了题为《构建基于鲲鹏处理器的高性能开源大数据计算平台》的报告。她谈到了尽管当下 AI+5G+IoT 带来了各种应用和商业模式创新,但这巨大的数据体量的背后,也暗藏着计算性能不足、分析周期长、资源扩展性差等问题。
而鲲鹏的大数据基础设施解决方案正是为此量身打造。它结合了华为云丰富的大数据平台和基础云服务经验,包括了:开源 Apache、HDP/CDH 等大数据平台,成熟完备的大数据组件,以及加速特性、编译器、操作系统、硬件基础等丰富的生态。可有效展开高性能、高可靠的大数据业务,并帮助企业快速实现数据化以及智能化转型。
昇腾 AI 工程师谭涛带来了《从神经网络到硬件,昇腾开发工具链全流程应用实践》到主题报告,详细讲解了昇腾开发工具链,并展示了新版本开发工具以及基于 Atlas 产品的成型项目,从而让参会者能够直观地感受到昇腾处理器专用开发工具的独特魅力。

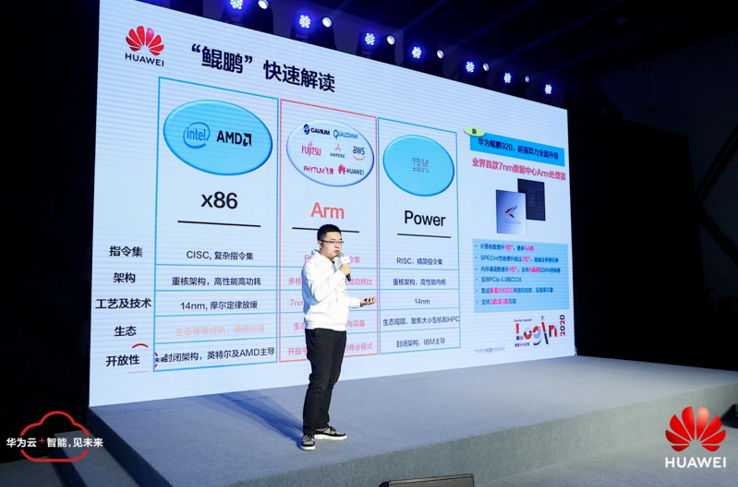
孙庚泽将「鲲鹏」处理器与市面上常见的数据中心处理器在指令集、架构、工艺及技术、生态以及开放性这 5 个方面的对比,从产品的角度为参会者再次解读了「鲲鹏」。数据显示,鲲鹏 920 超强算力全面升级,它的计算核数提升了 1 倍,最多可达 64 倍;SPECint 性能提升超过 2 倍,并超越了业界原有记录。
技术专场二:AI Everywhere——全栈全场景的人工智能
要实现 AI 无处不在的愿景,除了解决算力、算法、数据的三大挑战之外,还面临着成本、复杂性、可扩展性、数据隐私等多重挑战。AI 应用的大规模落地更是需要全栈 AI 能力的整合、全场景的最佳实践以及全栈 AI 开发经验的支撑。
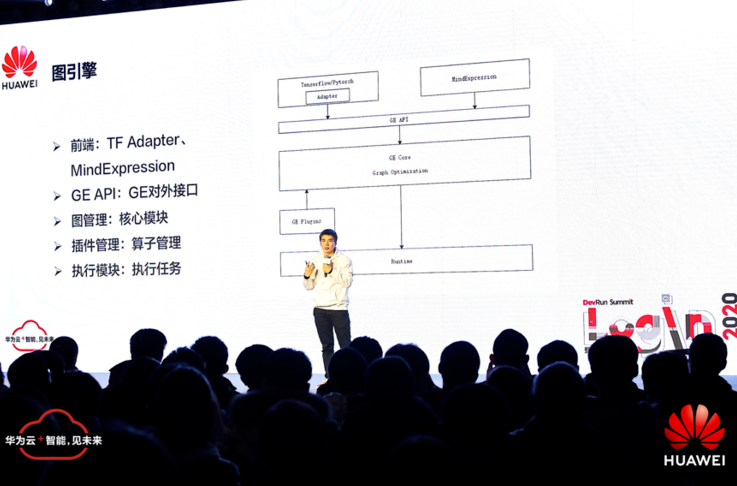
华为的全栈全场景 AI 则对这些问题进行了全方位覆盖,解决方案包括了:Ascend(昇腾)系列芯片、芯片算子库和高度自动化算子开发工具——CANN;AI 框架——MindSpore;以及提供全流程服务的一站式 AI 开发平台——ModelArts。在今天的技术专场,来自华为云的工程师们也为大家逐一解读了这些工具背后的技术实践。
MindSpore 高级工程师王俊向我们详细介绍了这款 AI 计算框架。该框架不仅支持终端、边缘计算、云全场景需求以及协同的统一训练与推理;而且在使用体验方面也非常出色。相比于 TensorFlow,MindSpore 框架可更有效地降低 AI 开发门槛,让深度学习的速度更快、成本更低,为广大的开发者提供强大的全场景 AI 的模型开发、模型运行以及模型端到端部署能力。
ModelArts 高级工程师杜奇则提出了 AI 需要的十大改变,其中也包括了将「一项需要高级工程师完成的工作」向「一站式平台提供基本技能」方向转变,这正是研发该 AI 开发平台的意义之一。

AI 高级解决方案架构师魏振强则带来了题为《HiLens & ModelArts:人工智能开发最佳启动路径》的演讲。他向我们阐述了作为多模态 AI 开发套件,HiLens 与 ModelArts 结合的详细内容。

技术专场三:企业级应用高效开发实践——利用云平台加速开发过程
专场的第一个报告《云原生开发的分层分级测试和质量保障》,由华为云 DevCloud 工程师夏东冉分享。他指出,对于创新创业来讲,新的商业模式往往需要小步快跑、快速试错,而通常的瀑布开发不仅历时较长,并且所得的产品不一定可正常工作;这时,敏捷开发就能很好的解决这一问题。
而 DevOps 的出现,又进一步搭建了开发和运维组织之间的桥梁,调和了迭代与稳定两者的矛盾。同时,在敏捷和 DevOps 开发模式下,CI/CD 持续自动化测试可实现高效的测试反馈,保障了产品随时发布的质量。因此报告显示,DevOps 目前已经成为企业软件研发的主流,被众多企业所采用。

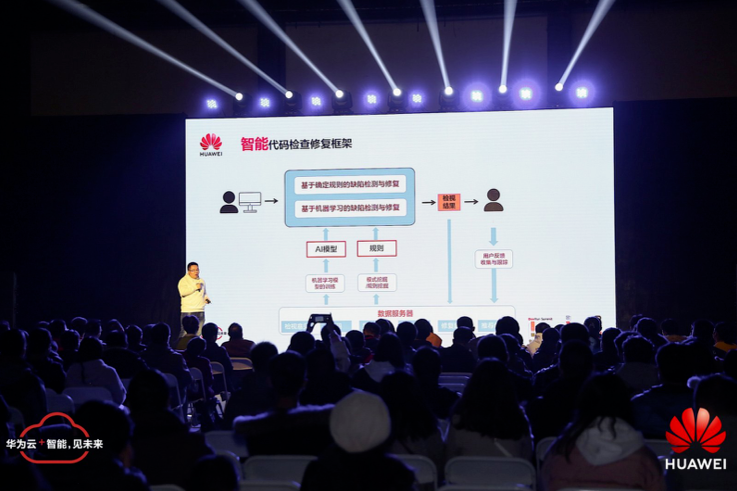
在第二个报告《持续构建可信代码检查服务》中,华为云软件分析实验室工程师郭东硕做了细致的介绍。演讲过程中,郭东硕反复强调,在云原生作为云计算的发展趋势的大背景下,应用的测试与质量保障则变得更加重要了。
一方面,大数据时代下的代码内容繁杂,因而错误也更多样;而另一方面,往往这些错误产生之后,很难采用「重启」等操作进行复原,甚至带来不可估量的损失。因此,在整个华为内部的日常开发工作中,他们采用了一种智能代码检测修复框架,该框架采用了基于确定规则与机遇机器学习双重保险的缺陷检测与修复机制。它能够保证代码在任意情况下的安全检测机制中,都具有安全可靠性。
据数据统计显示,已有超过 170 个国家与地区、300 多万的企业用户和开发者、5 亿多名终端云用户运用到了这一工具。目前,这一多语言代码检测框架也已经部分向大众开放,可直接在平台上运用,进而提高开发者的代码编写效率。
除了常见的开发安全与质量保障,华为对于近期火热的区块链领域也早有洞见。区块链架构师薛腾飞也向我们展示了利用技术裂变抓住机遇,构建高效构建可信、共享、安全的区块链的应用实践。其中涉及到的技术包括了:华为云安全、华为云大数据分析、自动运维等内容。

技术专场四:云原生加速 AI 应用创新与落地
现阶段,随着深度学习技术发展速度的放缓,以大数据为根本支撑的人工智能似乎也深受其影响,陷入了一定的瓶颈期。而紧跟着云原生为代表的「新生代」技术逐渐成长起来,以 Kubernetes 为核心的「云原生」运动正在不断扩大化,并且已经被业内广泛认同为云计算的未来趋势。那在这样的大背景下,开发者如何更好的实现云原生与 AI 的融合?
华为云高级工程师 / KubeEdge 项目核心成员徐飞老师,通过《基于 KubeEdge 的边云协同 AI 实践》的分享给出了他的答案。徐飞表示,云原生领域下,边缘计算是非常重要的一部分,而云原生边缘计算则可以让边缘也具备像云一样的「弹性」,让应用可以「顺滑」的部署到边缘,保持应用在边缘与云端的一致性。

华为云高级工程师 / Volcano Init Maintainer/Committer 李明哲分享了他《Volcano: 在 Kubernetes 中运行高性能 AI 作业》主题报告。他表示,随着容器化以及容器编排技术的普及,越来越多的上层业务正开始拥抱 K8s 生态。而华为作为云原生领域的领导者之一,今年 6 月则正式开源了面向高性能计算的云原生任务批量计算处理平台 Volcano。
Volcano 提供了一整套目前 Kubernetes 在批量和弹性工作负载处理中缺失的机制,包括:机器学习/深度学习、生物信息学/基因组学、其他「大数据」应用。这些类型的应用程序通常运行在 Volcano 集成的 Tensorflow,Spark,PyTorch,MPI 等通用域框架上。