




点击上方蓝字关注我们

导语
Empty your mind, be formless, shapeless — like water. Now you put water in a cup, it becomes the cup; You put water into a bottle it becomes the bottle; You put it in a teapot it becomes the teapot. Now water can flow or it can crash. Be water, my friend.
相信很多人都看过李小龙在1971年的那次采访,这段关于武术的理解精彩至极,境界之高让人叹服。水,无形而有万形,无物能容万物。数据就像水,利万物而不争。地球表面71%都被水覆盖,我们的世界也正在快速地被数据湮没。
01
数据的增长和蔓延
在《Data Age 2025》这份白皮书中,IDC提出了全球数据圈(Global Datasphere)的概念,把产生数据的场所分为三层:
核心(Core):包括企业和云服务提供商的专用计算数据中心。其中涵盖所有种类的云计算,包括公共云、私有云和混合云。此外还包括企业运营数据中心,如承载电网和电话网络的数据中心
边缘(Edge):指那些不在核心数据中心的企业加固型的服务器和设备。这包括服务器机房、位于一线的服务器,手机基站以及为了加快响应时间而分布在各个区域和偏远位置的较小的数据中心
终端(Endpoint):包括网络边缘的所有其他设备,包括电脑、电话、工业传感器、联网汽车和可穿戴设备
数据增长从未停止,并且会以更可怕的速度持续下去。根据IDC的预测,全球数据总量将从2019年的45ZB增长到2025年的175ZB,而中国将以每年约26%的增长速度,在2022年成为全球最大的数据圈。调查还发现,在接下去的两年时间里,企业中每年产生的数据会以42.2%的速率增长。增长的三大引擎主要来自于:
数据分析的更广泛使用
物联网设备的暴增
数据和应用上云的动力
那这些高速增长的数据从哪里来,又会存放在哪里呢?根据IDC最新的调查显示,下图是未来两年企业数据存放位置的分布情况
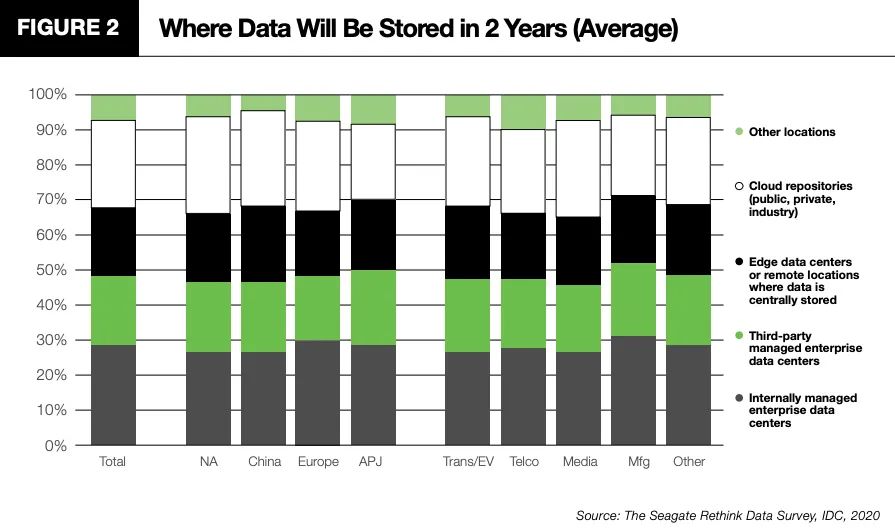
以中国为例,约27%的数据存放在内部的数据中心,约20%的数据存放在第三方托管的数据中心,约19%的数据存放在边缘数据中心,约24%的数据存放在各种形态的云上,剩下约10%的数据存放在其他场所。这种分散的情况至少在未来两年内不会发生明显的变化,这无疑给企业的数据管理带来了极大的挑战.
而这仅仅是其中的一个挑战...
02
数据形态多样化
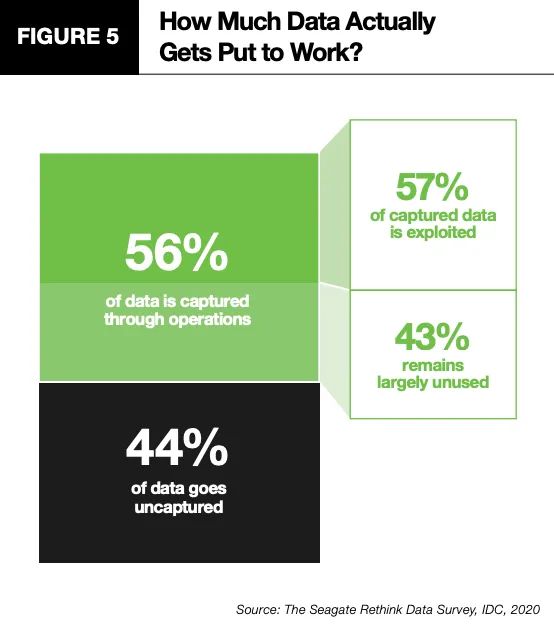
在DT(Data Technology数据处理技术)时代,我们要面对的不光是巨大的数据体量、分散的数据存放位置,还有杂乱的数据形态。静态来看,数据可以分为结构化数据(如关系型数据库中的数据),半结构化数据(日志、传感器数据、监控数据等),非结构化数据(如文档、图片、视频等);动态来看,又可以分成无界数据流(如信用卡事务数据)和有界数据流(门店订单数据)。对于有界数据流的处理,大家一定不陌生,企业中绝大部分ETL批处理流程就是用来处理这类数据的。它们有头有尾,可以等到所有数据传输完成后再进行处理。而无界数据流则不同,它有头无尾,持续生成,永远无法等到所有数据都传输完成。所以传统的批处理方式显然无法应对。这又是一个挑战。根据IDC的统计,目前企业中只有56%的数据被捕获,另外44%的数据都流逝掉了。而在这56%被捕获到的数据中,又只有57%为企业所用,这就意味着,企业实际上只利用了32%的数据,其余的68%并没有发挥价值。
03
传统ETL批处理
在过去,数据通常只在数据库、文件、数仓等载体之间流转,一天之内可能需要移动数次,复杂的工具、SQL脚本和存储过程充斥着整个ETL流程。当上游数据源和下游应用的数量增加时,这种架构就会变得极其复杂,无法管理。
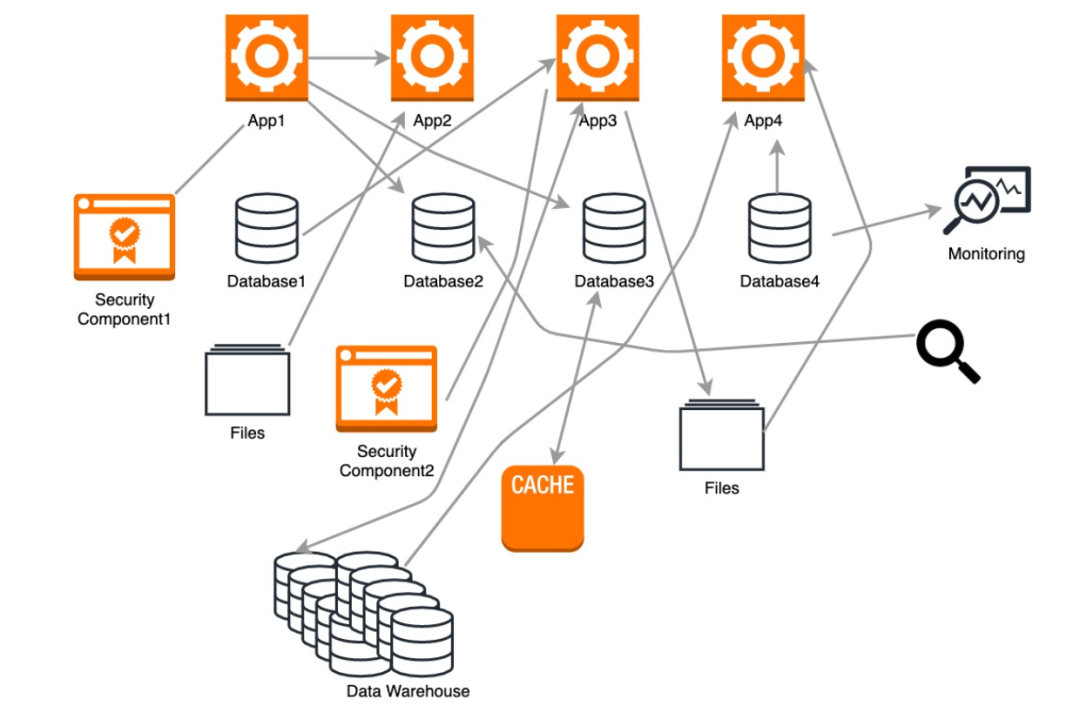
它带来的问题有:
系统之间的数据处理是以批处理的方式进行的,时效性较差
越来越多的公司希望能实时分析、处理数据,比如日志、传感器数据、监控数据等,但传统的ETL工具对这类数据的支持并不好
传统的ETL处理流程效率较低,并且很消耗资源
数据建模过程中很难创建一个全局统一的schema
数据处理的业务逻辑(SQL、存储过程等)和数据源耦合在一起,如有变更,可能影响整个ETL流程
04
流式ETL
为了解决上述问题,出现了一些新的技术,比如Kafka、ActiveMQ、Spark、Flink等。我们可以使用它们来搭建一套高性能、易扩展、易管理的流式ETL平台。为了处理异构数据源所产生的不同结构的数据,我们再往上抽象一层,就会发现,其实对于大部分数据系统而言,每一次数据的CRUD操作都可以看做是一个事件,比如Oracle数据库的Redo Log,MySQL中的Binlog,都是用于记录每一次的数据变更。这也是近几年很火的事件流处理平台Kafka的核心思想。Kafka早在2011年就已经开源了,但一直被定义为是一个分布式的消息队列,因为所有的事件都被当做message保存在Kafka中,下游的报表、BI等传统应用想要消费其中的数据,还是需要先加载回数仓中进行转换操作才能使用。
不过,就像成人的世界不是非黑即白,技术世界中,很多东西的界限也变得很模糊。当Kafka Stream、Flink、Spark Stream这样的产品出来之后,Kafka本身就不再是一个单纯的消息队列了,而更像一个流式数据库,我们可以直接通过类SQL语言去做数据的聚合、过滤、排序等常见的转换,这样很多应用就可以直接使用转换后的数据了,真正地实现了流式ETL。
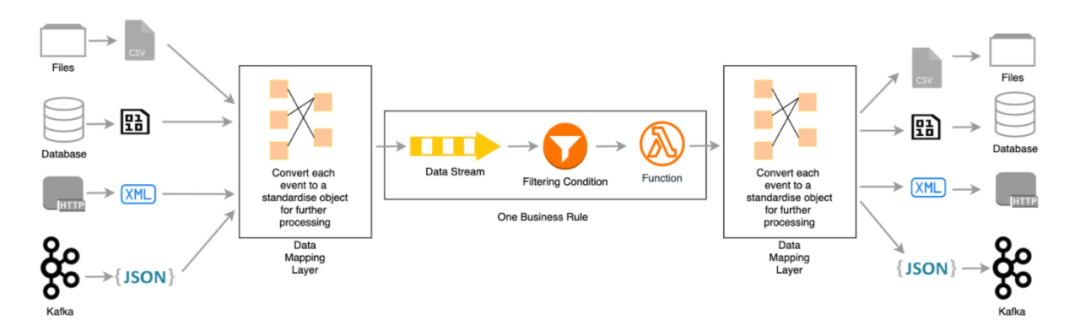
流式ETL平台的优势:
有统一清晰的数据总线,便于维护和监控管理
数据处理逻辑和源端、目标端解耦,通过事件将来自不同数据源的数据转换成统一的格式来存储、处理
通过单独的connector,可以连接各种不同的数据源,比如关系型数据库,文件,日志系统,HTTP请求等
提供了强大的类SQL语言,可以对数据进行实时的加工处理,比如关联,过滤,聚合,排序等操作
可以方便地在不影响现有组件的情况下,增加业务逻辑
05
结尾
当然,流式ETL平台并非完美的解决方案,它也有一些传统ETL方案中的问题需要解决,比如如何校验源端和目标端数据的准确性;异构数据源同步时schema的兼容性;如何应对数据源的表结构发生变化时的场景等等。云趣科技的技术团队正在全力攻克这些难题,非常期待我们的产品能够早日跟大家见面
古希腊哲学家泰勒斯曾说过:水是万物之源。流动的水才有灵性,数据亦如此。
作者:森叔
简介:云趣科技产品总监
出品:云趣科技


云趣 ,等你关注
