




点击上方蓝字关注我们

导语
基于Prometheus 和 Alertmanager 搭建的告警平台市面上已经有很多了,对于这两者的痛点和使用姿势在各厂商中也摸索出了一套稳定的用法,本文将会介绍本套架构实现中的一些坑以及痛点解决思路。
01
基本监控架构
在漫谈架构痛点之前,首先我们需要了解使用这套架构完成一个什么样的产品?假设我们有N台主机及若干数据库,我们需要定期对这些实例的一些状态进行监控并制定相关的告警规则,当某些状态超过我们设定的阈值时,我们需要有一个途径向客户端告警,基于上述需求,可以总结出如下几点:
用于采集数据的Agent或Exporter
用于存储所有监控数据的数据库及告警配置、解析器
用于针对超过阈值的告警规则的告警组件
这里我们采用Prometheus中使用是pull模式定期获取所有监控实例中的数据,所以在第一点的选择中,我们无需部署agent来主动采集并推送数据,而是使用exporter实现监控接口对接所有监控实例,再由Prometheus来定时访问该接口来完成数据采集,上述可知我们的技术选型路线为 Exporter + Prometheus + Alertmanager,如下图所示:
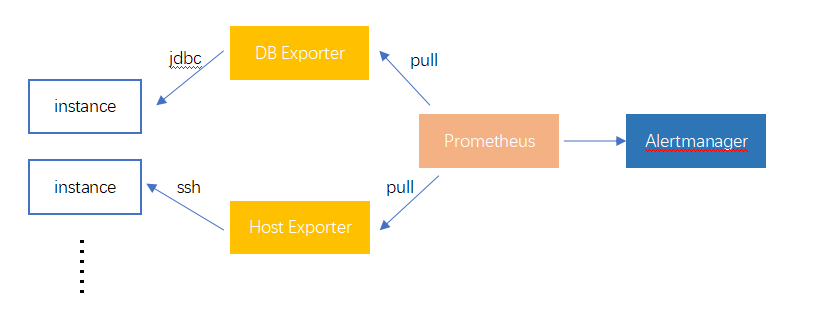
当然,这张图只是我们的一个大致的思路,从图中可以看出我们针对主机及数据库实现了两个exporter来采集他们的数据并且使用Prometheus提供的包来注册指标metrics,使用的方式是JDBC及SSH,这样的好处在于我们不需要在目标端部署agent加大实施难度,而所有的采集操作可以通过接口的RESTFUL API的方式暴露出来,至于采集的频率由Prometheus中配置的采集规则决定,只要按照配置文件中规定的采集频率来访问相应exporter中的接口并传入参数即可,这就是Prometheus中pull模式的由来,指的就是不需要采集端主动push数据且每次需要采集的数据的参数等都是由Prometheus提供,方便管理排查。
截止以上,我们对于整体的架构已经有了一个大致的了解,而截至目前为止我们对Prometheus的了解还是比较模糊的,并且最关键的一环还是在它身上,当然,在真正产品化之前,我们需要了解Prometheus的两个痛点:
监控数据可以持久化,但告警数据没有,也就是说本身没有实现告警历史
配置文件较为复杂,有一定的学习成本
针对以上两点,关于第一点的告警部分,我们需要结合Alertmanager来实现,我们放到后面来讲,重点在于,如何利用好Prometheus来归类整理我们从四面八方采集到的告警数据,这时候我们需要搞清楚两个点,Prometheus的告警配置文件中的参数含义都是什么,而又是如何结合这些配置来实现整体告警实现的?
02
Prometheus 配置解析
我们需要了解Prometheus的监控流程,才能更好地去运用其完成我们的需求,这里我们从三个方面入手,分别是监控配置文件、告警规则配置文件以及整体运转流程。
监控配置文件解析
这里我贴出一份简单的prometheus.yml文件,也就是配置文件,在该文件中主要声明对应实例采集的频率、review告警规则的时常等,这里我们一个个来看:
# global 全局配置 当scrape_configs 中没有对应配置会默认使用global:# scrape_interval 拉取数据的周期,这里我们规定一分钟scrape_interval: 1m# scrape_timeout 拉取数据时接口的超时时长scrape_timeout: 1m# evaluation_interval 这个参数比较有意思,规定为多久轮询一次所有的告警规则,这 里预设为10秒,这个参数我们后面会用一个案例来重点描述evaluation_interval: 10s# 告警配置 声明告警组件,这里我们选用alertmanager,并在配置中加入ip地址和端口alerting:alertmanagers:- static_configs:- targets:- localhost:9003scheme: httptimeout: 10sapi_version: v1rule_files:- rules/*.yml# 监控实例配置scrape_configs:# 这里我们根据不同采集频率来划分不同采集指标,采集频率相同的指标将会被放入一个job中# 在之后的参数中可以重复声明global中的参数来达到覆盖效果,例如我们在interval-1s的job中规定的scrape_interval值就是1s# 在file_sd_configs 参数中我们可以传入自定义的json文件,在该文件中我们可以声明采集目标端的label及必要参数,例如采集端的ip,数据库类型,实例名称、id等,这样就可以实现多个实例配置享用一个采集job- job_name: interval1shonor_timestamps: truescrape_interval: 1sscrape_timeout: 1smetrics_path: metricsscheme: httpfile_sd_configs:- files:- servers/*1s.jsonrefresh_interval: 5mrelabel_configs:- source_labels: [instance]separator: ;regex: instance-(.*)target_label: __param_idreplacement: $1action: replace- separator: ;regex: (.*)target_label: __param_intervalreplacement: 1saction: replace- job_name: interval5shonor_timestamps: truescrape_interval: 5sscrape_timeout: 5smetrics_path: metricsscheme: httpfile_sd_configs:- files:- servers/*5s.jsonrefresh_interval: 5mrelabel_configs:- source_labels: [instance]separator: ;regex: instance-(.*)target_label: __param_idreplacement: $1action: replace- separator: ;regex: (.*)target_label: __param_intervalreplacement: 5saction: replac
告警配置文件解析
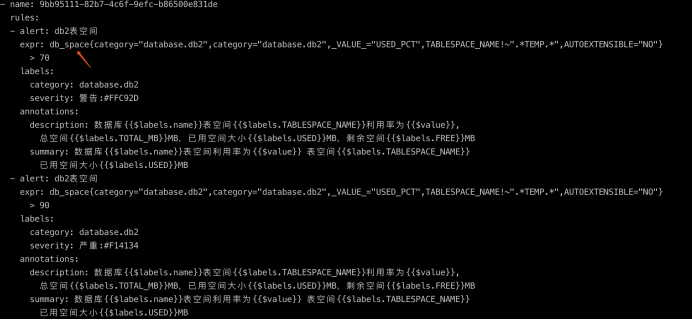
如上文所说,我们已经建立了采集端与Prometheus端的监控数据联系,我们通过metrics + label的特性来确定某一具体的监控指标,这里我们可以建立一个rules.yml文件来声明各指标具体的告警规则,这里每一类的告警我们使用了一个随机的uuid去生成,在这里告警规则之下我们可以插入好几个不同阈值或不同类型的告警规则,这里我们一一讲解:
alert 告警名称
expr promql表达式,在上述采集、监控的配置中,我们已经建立了metrics + label的模式来确定每一个具体的监控指标,prometheus实现了一个sql表达式来方便我们从它的时序性数据库中去读取这些监控数据,并且该表达式还能做到一定程度的数据聚合、计算等功能。在图例中我们通过db_space指标,并且在{}中指定其特定的label后,可以获得一个唯一的value,最后对这个值进行判断就是是否触发告警的条件
for 这里图中有一个参数没有标出,该参数意味着如果在当前时间点触发了告警,那么在未来时间内如果持续触发,则会将该告警发出,相当于给当前指标判了一个死缓,不会立即触发
labels 触发告警后携带的条件,由于这条告警下我们配置了两种不同类型的阈值,所以这里可以看到在serverity标签下我们做了一些区别
anntations 告警描述,值得注意的是这里可以读取该指标中的值进行拼接
Prometheus工作流程
现在我们已经差不多了解Prometheus如何存储、分类数据,如何针对于这些数据实现告警,我们来捋一下大致的结构:
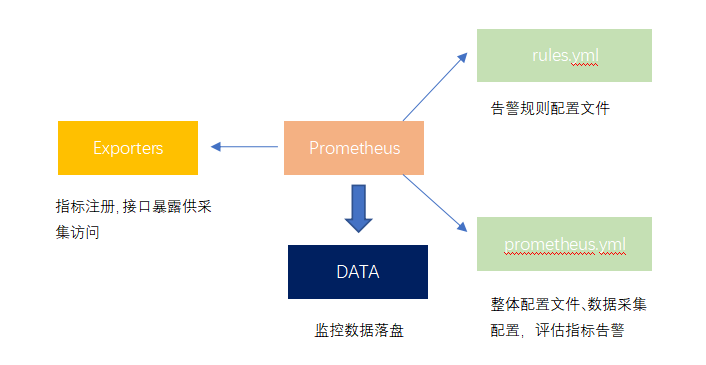
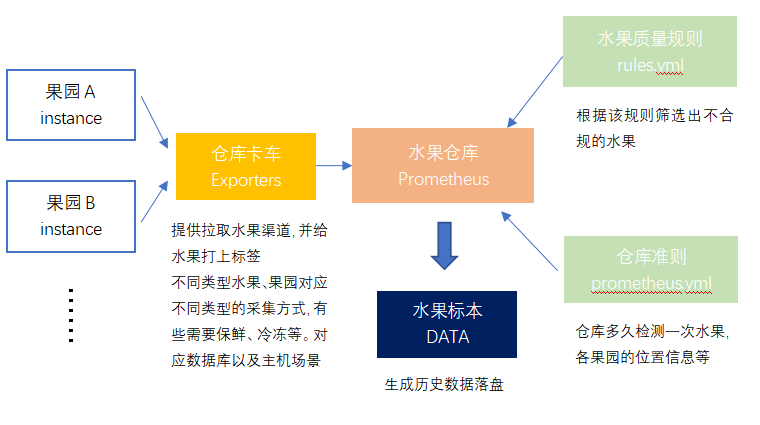
我们来打个比喻,这里我们把Prometheus比做一个水果仓库,我们需要定期检测各个果园中的水果质量,但每个果园我们都需要制定一份不同的标准,例如A果园我们一天拉取一次它的水果们,B果园我们每小时都需要拉取,这里就对应Prometheus的pull模式,每一次都是主动去拉取而不是等果园把水果运过来。这些拉取过来的水果身上都会有一个时间戳并存储进我们的水果仓库中,这时候我们需要制定一个规则判定,哪些水果烂了,我们就需要通知我们的下游,也就是销售商这个水果不能售卖了有问题,而如何判定水果烂的程度或者说怎么样才算需要告警的烂法,这里就对应rules.yml文件取声明,而我们多久检测一次所有的水果,对应的参数就是evaluation_interval,意思就是每隔十秒钟,我们就会使用rules.yml中的promql表达式针对所有实例都跑一遍,看看谁触发了告警规则。而定期我们就会对仓库中的水果做成标本,对应落盘生成历史监控数据,对应关系图如下:
03
Alertmanager告警接入
首先,我们需要明确为什么需要一个专门的告警组件接入。Prometheus自身针对每个监控指标生成告警,从告警规则解析来看,我们可以针对同一个告警指标指定若干告警阈值,例如设置当值大于20时发出警告级别告警,大于60时发出严重级别告警,Prometheus会认为这是两条告警同时发出,而不会认为这是一个只需要保留后者的唯一告警。这时候我们就会遇到一个问题,我们容易接收到冗余、无用的告警,而Alertmanager就是为了对这些告警数据进行清洗、聚合之后再统一发出,避免产生邮件风暴等现象。
04
未解决的问题
告警恢复
从Prometheus的角度看,我们每个指标都设定了一个采集频率,每次采集回来的数据都会被Prometheus打上一个时间戳之后存入自身的tsdb中,但我们刚才说到,Prometheus每隔10s就会检查一次自己所有的告警项是否已经触及到阈值而触发告警,这样就会造成两个问题
在检查时如果那个时间点没有监控数据会怎么判定?
Prometheus在生成一个告警项之后会自动推算一个告警结束时间( resend_delay(默认1m) + evaluation_interval ) * 3 + time.Now,那么在这个时间内没有新的监控数据来维持该告警,是否会判断达到预期恢复时间,出现误恢复情况?
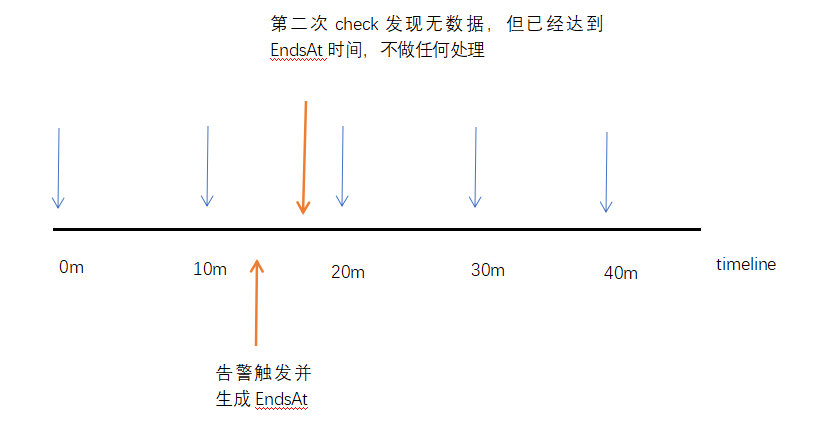
在Prometheus每次运行promql时,如果当前点无监控数据,那么Prometheus不会去寻找最近一个点的监控数据,在UI界面上也可以看到,会返回一个no data point的结果,生成出的graph也会呈现一个断断续续的效果,由于Prometheus在告警发生后会自动生成一个告警结束时间,也会导致alertmanager中的全局配置resolve_timeout失效。为了解决这个问题,Prometheus建议采集频率最好不要大于3m来保证不会触发这种现象。但针对于某些数据库的指标采集,过于频繁的采集会影响数据库的性能,为了权衡,我们需要让某一些时间点采集回来的数据持久化,希望Prometheus在未来半小时甚至一小时都使用这个时间点采集到的数据,这时候我们可以改变Prometheus中的启动参数query.lookback-delta来控制数据持久化时间,而这个参数可以根据平台中采集频率最长的一个指标来制定。比如我们采集频率最长的一个指标是一小时一次,那么这个参数可以设定为61m。
告警历史统计
无论是Prometheus还是Alertmanager都没有提供存储所有告警历史的功能,但这里我们可以利用alertmanager主动发出告警所提供的webhook来触发我们自身的业务逻辑,将这一部分的告警数据写入我们自己的数据库中,Prometheus为每条告警提供了一个唯一的fingerpoint值也可以让我们识别新的告警是否已经发出过,从而达到建立每次告警触发时间以及恢复时间的时间轴。
作者:钟灵
简介:云趣科技全栈工程师
出品:云趣科技


云趣 ,等你关注
