




gris 转载请注明原创出处,谢谢!
我们通常在写java程序时,不需要关心内存的分配和释放,这一切由JVM和GC帮我们完成。但是作为一个高性能的网络框架,一个高效的内存分配回收算法是不可或缺的,netty为我们提供了非常棒的内存管理,使用了全新的内存池来管理内存的分配和回收。
我们以创建一个池化的堆内ByteBuf对象为例,看下具体的内存分配过程,首先我们捋清楚PooledByteBufAllocator.DEFAULT.heapBuffer的调用链:
#1 PooledByteBufAllocator.DEFAULT.heapBuffer(int initialCapacity)
+--> #2 AbstractByteBufAllocator.heapBuffer(int initialCapacity, int maxCapacity)
+--> #3 PooledByteBufAllocator.newHeapBuffer(int initialCapacity, int maxCapacity)
+--> #4 PoolArena.allocate(PoolThreadCache cache, int reqCapacity, int maxCapacity)
+----------------------------------------------
| +--> #5 HeapArena.newByteBuf(int maxCapacity)
| +--> #6 PooledUnsafeHeapByteBuf.newUnsafeInstance(int maxCapacity)
| +--> #7 Recycler.get()
| +--> #8 Recycler.newObject(Handle<T> handle)
| +--> #9 new PooledUnsafeHeapByteBuf(Handle<PooledUnsafeHeapByteBuf> recyclerHandle, int maxCapacity)
+----------------------------------------------
+--> #10 PoolArena.allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity)
可以看到,第#4步的调用进入了一个叫PoolArena的类中,而从第#5步到第#9步都是ByteBuf对象的初始化的过程,第#10步中又返回到了PoolArena类中,对刚刚初始化完成的ByteBuf对象进行分配内存。由此我们可以锁定PoolArena类,也就是我们本次文章要详细分析的“内存竞技场”。
首先我们把PoolArena中内存分配的流程了解清楚,有个大概的概念,后面我们再来详细分析,整个流程可以用下面的这个图来表示:
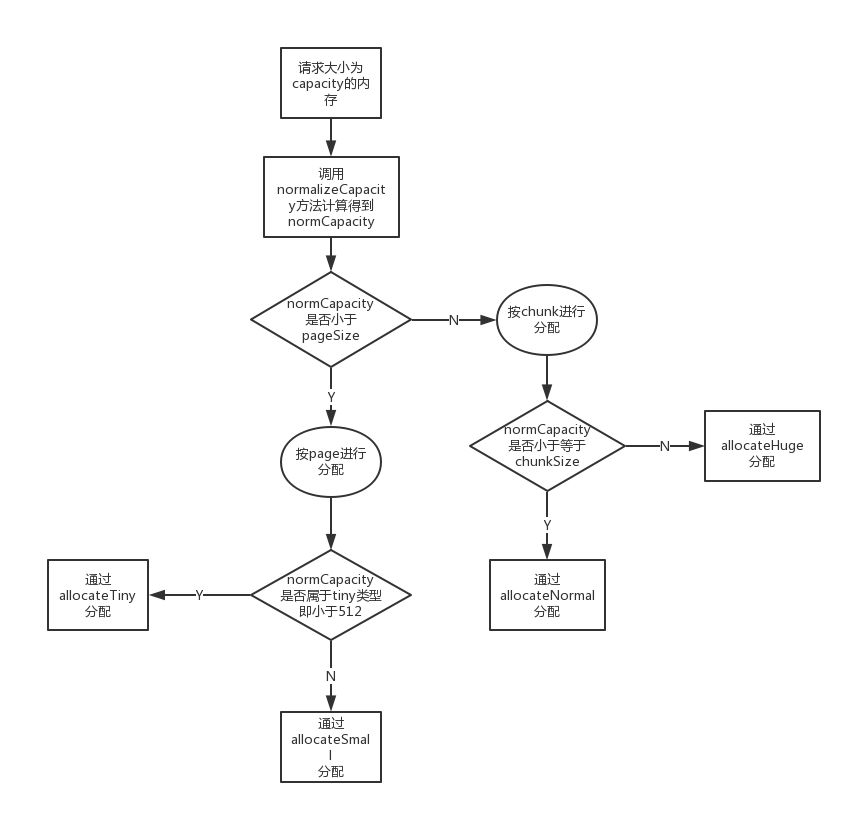
为了更高效的使用内存,使得内存利用率最大化,在netty内存分配竞技场(Arena)中定义了两种不同尺寸的内存单元: 一种是页(page),页是可分配的最小内存单元 一种是块(chunk),一个块是由多个(个数为2的marxOrder次幂)连续的页组成的一个更大的内存单元,他们所占的内存大小为:
// 页大小 默认8192(8K)
final int pageSize;
// 块大小 chunkSize=pageSize*2^maxOrder
// 其中maxOrder的大小不能小于30
final int chunkSize;
那么对这么多的内存页是怎么进行管理的呢?netty为我们提供了一个叫PoolChunk的类,该类主要是用来对内存页管理的,所有的内存的分配和回收都被委托给PoolChunk类。
PoolChunk
在初始化时netty总是一次性申请一大块连续的内存,内存的大小为chunkSize,然后划分成一个一个小的内存页,每个内存页的大小默认为8192(即8K)。当线程来申请一块内存时,netty需要在这块连续的内存中找到第一块连续的能满足大小的内存块,并返回一个包含着偏移量(offset)信息的handle(long类型)。 为了简单起见,所有返回的内存块的大小都是通过normalizeCapacity()方法处理过的,当请求的内存大于一个page的大小时,此时会返回比pageSize大的最近的一个2的幂次方的内存。 为了在chunk中快速的查找到满足条件的page,netty在PoolChunk中维护了一棵完全二叉树:memoryMap,这棵树是通过数组实现的。这棵树的节点个数,节点的深度和节点的容量可以用下面这张表进行描述:
| 节点深度 | 节点个数 | 每个节点大小 |
|---|---|---|
| 0 | 1 | chunkSize |
| 1 | 2 | chunkSize/2 |
| d | 2^d | chunkSize/2^d |
| ... | ... | ... |
| maxOrder | 2^maxOrder | chunkSize/2^maxOrder |
树的最大的深度为maxOrder,默认maxOrder的值为11,因此一个chunk中默认有2^11=2048个page。因此当线程请求一个chunkSize/2^k大小的内存时,只需要在树的第k层中从左往右找到一个满足条件的节点即可,什么是满足条件的呢,就是当前该节点和该节点的所有子节点都是可分配的状态。 让我们结合一个简单的图来描述一下这棵完全二叉树的结构
+-------------------------------------------+ | [...] | 9 +[512] [...] | | | 10 +[1024] [1025]+ [...] | | | 11 +[2048] [2049]+ +[2050] [2051]+ [...] | +-------------------------------------------+ | [p0] [p1] [...] [p2047] | +-------------------------------------------+
PS:上图中+在左边表示是一个左子节点,+在右边表示是一个右子节点。 上图在手机上可能效果不好,可以在电脑上查看。
我们从树的第9层往下开始看,上面省略树的第0到第8层。从上面的表中可以得知,第9层共有2^9个节点,最左边的节点编号为512,这个编号也就是对应的memoryMap数组的下标。最下面的一层也就是树的第11层共有2048个节点,每个节点就是chunk中分配的最小的内存单元:page。
下面详细描述下内存分配的过程:
1.如果请求的内存介于(0,pageSize]之间,通过normalizeCapacity()方法最终计算出capacity为一个pageSize的大小,那么只需要在第11层从左往右找到第一个可以分配的page就可以了,此时找到第2048个节点正好符合要求,直接将2048节点分配出去,此时需要将2048节点标记为已分配,并递归将2048节点的父节点标记为有部分子节点已分配
2.此时如果再来请求一个内存介于(pageSize,2*pageSize]之间,则计算出来的capacity为2*pageSize。那么需要到第10层去查找,而此时发现1024节点有一个左子节点已经被分配了,导致1024节点的容量达不到2*pageSize,所以1024节点无法分配,继续往后查找。这时发现1025节点的容量正好为2*pageSize(因为1025节点的两个子节点都没有被分配出去)符合要求,所以直接将1025节点分配出去,注意此时需要将1025节点的两个子节点也标记为已分配,因为他们是由他们的父节点分配出去的
那系统是如何知道哪些节点是可分配的,哪些节点不可分配呢?问题的关键就在memoryMap中,memoryMap数组的大小是完全二叉树中节点的个数,默认的节点个数为4096,看一下memoryMap的初始化:
// maxOrder默认为11
// maxSubPageAllocs为一个chunk中page的个数,默认为2048个page
maxSubpageAllocs = 1 << maxOrder;
// 初始化memoryMap数组,大小为4096
memoryMap = new byte[maxSubpageAllocs << 1];
depthMap = new byte[memoryMap.length];
int memoryMapIndex = 1;
for (int d = 0; d <= maxOrder; ++ d) { // move down the tree one level at a time
int depth = 1 << d;
for (int p = 0; p < depth; ++ p) {
// memoryMap中每个节点的值表示该节点在树中的深度
memoryMap[memoryMapIndex] = (byte) d;
depthMap[memoryMapIndex] = (byte) d;
memoryMapIndex ++;
}
}
memoryMap数组就用来标识每一个节点当前是否可以被分配:
1.memoryMap[node_x] = depth_of_node_x
如果节点x的值正好等于x的深度,则说明该节点还未被分配,可以用来分配
2.memoryMap[node_x] > depth_of_node_x
如果节点x的值大于x的深度,则说明该节点至少有一个子节点已经被分配了,所以该节点不能用来分配
3.memoryMap[node_x] = maxOrder+1
如果节点x的值为树的总深度+1,则说明该节点的所有子节点都已经被分配了,因此该节点不能用来分配
本文我们通过调用PooledByteBufAllocator.DEFAULT.heapBuffer对堆内内存的分配,从他的调用栈中窥探到netty中用来分配内存的PoolChunk类。并捋清楚了netty的内存竞技场中对于各个不同尺寸内存的分配的流程,还了解了PoolChunk中用来管理内存分配和回收的数据结构:memoryMap,一棵完全二叉树,并理解了如何对于不同尺寸的内存进行分配的。下一篇文章中,我将会通过具体的代码继续深入了解PoolChunk内存分配的过程。

