




背景
我想很多人会有与我一样的经历,想复制百度文库的内容却发现要开会员,天下苦百度文库久矣,本是广大网友存放文档的地方,结果各种下载券,会员不胜其烦,那么能不能用技术手段避开这一结界呢?简化到只需要输入文档地址,然后文档就乖乖的保存到自己电脑上呢?想想就很巴适,利用python爬虫技术确实可以做到这一点。
想要破解百度的门禁在实际操作层面也是一件比较麻烦的事情,但好在天无绝人之路,哪里有加密哪里就有解密,先说一说博主的需求,博主主要是写数学讲义的时候,想收集一些经典习题,然后自己讲解并编辑排版,感兴趣的朋友可以关注微信公众号“三行科创”,而网上很大一部分素材都集中在百度文库,博主希望技术能够做到,当输入文档的地址后,能够把文档里面的文字内容原封不动的复制出来,并且文档里面的配图素材也能一并弄下来,这样就相当于素材收集齐全。
思路
downloadWenku实现文档下载; 调用fetch_text函数解析文档里文字内容,将文字内容统一格式写入word; 调用 fetch_image函数获取文档里插图素材,将图片内容保存到同名文件夹下;
预览效果
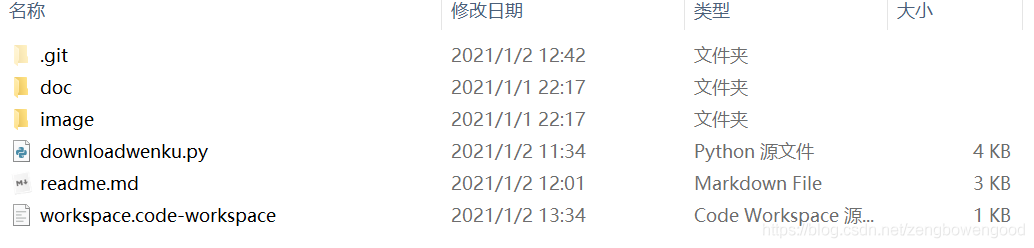 说明:其中downloadwenku.py文件为主程序,readme.md是这篇博客的原稿,doc文件夹下面存放同文档名的word文档,image存放同文档的图片素材文件夹;
说明:其中downloadwenku.py文件为主程序,readme.md是这篇博客的原稿,doc文件夹下面存放同文档名的word文档,image存放同文档的图片素材文件夹;
代码
import os
import re
import json
import requests
header = {'User-agent': 'Googlebot'} #构造请求头
def fetch_text(doc_id, title, doc_type): #获取文档的文字内容
abstract_url = 'https://wenku.baidu.com/api/doc/getdocinfo?callback=cb&doc_id=' + doc_id #构造摘要地址
abstract = requests.get(abstract_url, headers =header, timeout =30) #获取文档摘要信息,包括md5码,总页数,rsign等
md5 = re.findall(r'"md5sum":"(.*?)"', abstract.text)[0] #md5
pn = re.findall(r'"totalPageNum":"(.*?)"', abstract.text)[0] #页码
rsign = re.findall(r'"rsign":"(.*?)"', abstract.text)[0] #rsign
content_url = 'https://wkretype.bdimg.com/retype/text/' + doc_id + '?rn=' + pn + '&type=txt' + md5 + '&rsign=' + rsign #构造文档内容的地址
content = requests.get(content_url, headers = header, timeout =30) #对文档内容请求
page_contents = json.loads(content.text) #所有页的内容形成一个list
doc_path = r"D:\项目\百度文库下载与文本解析\doc"+ os.sep + title + ".doc" #选择要保存的本地doc文件名
with open(doc_path, mode = 'w+', encoding ='utf-8') as file: #打开文件
for page_content in page_contents: #每一页循环
lines = page_content['parags'][0]["c"].replace('\r','').replace('\\n','') #每一页的文字内容是一个整体
file.write(lines) #写入doc文档
file.close() #关闭doc
print("文本素材保存完毕")
def fetch_image(url, doc_id, title, doc_type):#获同篇文档里面的图片素材
image_path = r"D:\项目\百度文库下载与文本解析\image"+os.sep+title #保存图片的路径
if not os.path.exists(image_path): #创建同名文件夹保存图片
os.mkdir(image_path)
resource = requests.get(url).content.decode('utf-8', 'ignore')
image_urls = re.findall(r'(https:\\\\/\\\\/wkbjcloudbos.bdimg.com.+?0.png.+?\\")', resource) #正则图片素材地址
#print(len(image_urls))
for idx, image_url in enumerate(image_urls):
image_url = image_url.replace("\\", "").replace('\"', "")
if len(image_url)< 650:
img = requests.get(image_url, headers = header, timeout =30).content
with open(image_path+os.sep+str(idx)+".png", "wb") as f:
f.write(img)
f.close()
print("图片素材保存完毕")
def downloadWenku(url): #进入文档地址获取文档基础信息,包括文档id,文档标题,文档类型
html = requests.get(url, headers = header, timeout = 30)
html.raise_for_status()
html.encoding = 'gbk'
doc_id = re.findall(r"docId.*?:.*?\'(.*?)\'\,", html.text)[0] #docid
title = re.findall(r"title.*?\:.*?\'(.*?)\'\,", html.text)[0] #文档标题
doc_type = re.findall(r"docType.*?\:.*?\'(.*?)\'\,", html.text)[0] #文档类型
#print(doc_id, title, doc_type, doc_type)
fetch_text(doc_id, title, doc_type) #调用下载文字函数
fetch_image(url, doc_id, title, doc_type) #调用下载图片函数
if __name__ =="__main__":
url = input("\n请输入文档的地址, 回车键确认:")
downloadWenku(url)
代码解析
代码几乎都标有中文注释,如果还有不懂的欢迎来“三行科创”微信公众号交流群。
改进方向
1,保存为1997-2003以后的docx格式; 如果保存为doc格式,用2007以后的word软件打开会出现让你选择文档可读编码utf-8,这个最好在保存的同时处理掉;
2,将文档里面的图片有一部分可以显示,有一部分似乎不支持文件格式;
3,对PPT似乎无效;
参考资料
1, https://my.oschina.net/u/4579171/blog/4344181
2, https://www.cnblogs.com/LQ6H/p/12940524.html
免责申明
爬虫技术仅供技术交流使用,不得作为商业用途。
- - -The end- - -
交流群限时免费,入口见菜单栏
三行科创微信公众号欢迎投稿
稿件聚焦数学逻辑,数学工程,数学文化等领域
一经采用,我们将奉上酬劳
投稿邮箱:sanhang_kc@163.com
商务合作:17521754388

