




导库读取数据及可视化
PCA过程
PCA可视化
PCA背景及基本思想
我们是不是经常听到这样的对话,一位同学抱怨"这个模型的变量简直要爆炸了",然后旁边一小哥低声的说"你先PCA一下",小哥口中的PCA到底是什么呢?
现实生活中,我们需要把很多方面的因素组合在一起来综合探索他们对某一结果的影响,同时这些因素自身之间可能就存在一些相关性会相互排斥,于是,有人就想能不能抽离出一些综合性指标来代表所有因素,同时要求抽离出来的这些综合指标是相互独立的。这就有了PCA的最初思想,PCA是principal components analysis首字母的缩写,中文名字叫主成分分析,顾名思义是对所有变量分清主次然后把主要成分抽取出来从而达到降维的效果,同时考虑降维的会带来哪些好处,又会带来哪些后果。
奇异值分解定理
我们把PCA的基本思想用数学语言描述出来就是把高维线性空间的向量组进行某种线性变换到低维的正交的线性空间上去,从而达到用低维数据表示高维数据的目的,同时变换后的向量组是线性无关的。现在的问题关键是如何找这样的一个线性变换,这要用到代数里面的奇异值分解,所以,我们先介绍一下奇异值分解定理,下面讨论限定在数域K上进行的。
奇异值分解,英文名为singular value decomposition,简称SVD,是一种矩阵分解的方法。设是一个m×n的矩阵, 那么存在m阶正交矩阵P,n阶正交矩阵Q, m×n阶矩阵 使得
上式称为矩阵A的奇异值分解,其中P称为A的左奇异向量矩阵,Q称为A的右奇异向量矩阵,称为A的奇异值矩阵,对角线上的非零元称为A的奇异值。为了证明奇异值分解定理,先准备2个关键引理作为铺垫。
引理1 如果U为正交矩阵,那么,即正交矩阵的逆等于其转置。
证明:根据正交矩阵的定义 ,两边同时乘以得
引理2 特征分解定理
如果n维线性空间上非零向量满足
则称是矩阵的一个特征值,是矩阵A的特征值 所对应的特征向量。对于秩为k的矩阵来说,至少存在k个这样的等量关系
写成向量矩阵乘积的形式
将扩张成正交基,并简化成矩阵形式
等式两边左乘有
其中X为A的特征向量扩张正交基张成的正交矩阵。
有了前面2个引理的准备,下面来证明奇异值分解定理。
因为是一个秩为k的m×n的矩阵,那么是n×n的对称方阵。根据特征值分解定理存在n阶可逆矩阵V使得
其中V为n阶正交矩阵, 是由的特征值构成的n阶对角矩阵。
取V的k个线性无关的列向量组扩充成n维的正交基,那么
这说明 也做成正交基。令 有 , 单位化处理成标准正交基,记
那么 ,写成矩阵形式有, 其中 是由构成的对角矩阵。因此 就是A的奇异值分解。
PCA算法流程
因为PCA主要理论依据是奇异值分解,所以PCA有着比较标准的流程,具体的
对特征变量进行标准化处理; 计算特征变量的协方差矩阵; 对协方差矩阵进行奇异值分解; 取定最主要的K个特征向量作为主成分; 利用主成分对原特征向量进行线性变换。
PCA实例
本次以吴恩达机器学习第七次课的内容为蓝本实际操作一下PCA,看看PCA工程化过程。
导库读取数据及可视化
原数据只有2个特征,可以很好的进行二维平面可视化。
import numpy as np
import scipy.io as sio
import matplotlib.pyplot as plt
data = sio.loadmat(r"D:\项目\机器学习\吴恩达机器学习课件\CourseraML\ex7\data\ex7data1.mat") #读取数据
X = data["X"] #特征变量
fig = plt.figure(figsize=(6,4)) #新建画布
plt.scatter(X[:,0], X[:,1], color='w', marker='o', edgecolors='b', linewidths= 0.2) #样本散点图
plt.show()
从散点图可以看到数据大致可以投影到一条右上角倾斜的直线上,这条直线就是要找的低维投影空间。
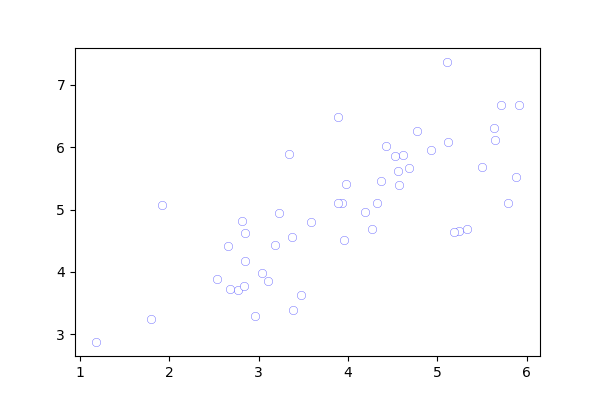
Figure_1 原散点图
PCA过程
按照PCA算法流程对样本数据进行PCA处理,同时记录原数据的均值,标准差,奇异值分解的特征向量和特征值,降维后的特征向量,投影误差等关键信息。
def run_pca(myX, K): #PCA过程
mean = np.mean(myX, axis = 0) #每个特征平均值
std = np.std(myX, axis= 0, ddof = 1) #每个特征的标准差,ddof = 1 表示在标准差计算分母是n-1
myX_norm = (myX-mean)/std #标准化处理
cov_mat = np.dot(myX_norm.T, myX_norm) #协方差矩阵
U, S, V = np.linalg.svd(cov_mat) #奇异值分解
U_reduced = U[:,:K] #取前K列的特征向量
myZ = np.dot(myX_norm, U_reduced) #投影到K维空间
myX_rec = np.dot(myZ, U_reduced.T)*std + mean #back计算特征的近似值
proj_error = np.linalg.norm(myX-myX_rec) #计算投影误
return mean, std, U, S, V, myX_rec, proj_error
PCA可视化
将二维数据PCA投影到一维空间,那么是可以找出对应关系的。
def visual_pca(myX, K): #可视化pca
mean, std, U, S, V, myZ, myX_rec, proj_error = run_pca(myX, K)
proj_x ,proj_y = [myX_rec[0,0], myX_rec[-1,0]], [myX_rec[0,1], myX_rec[-1,1]] #投影空间的基向量
ortho_x, ortho_y = [myX_rec[0,1], myX_rec[-1,1]], [myX_rec[0,1], myX_rec[-1,1]]
plt.figure(figsize=(6,4)) #新建画布
plt.scatter(myX[:,0], myX[:,1], color='w', marker='o', edgecolors='b', linewidths= 0.2, label = "origin dots") #原数据散点图
plt.plot(proj_x ,proj_y, color = 'b', linewidth = 1, label = "proj_base_line") #投影空间的基向量
#plt.plot(ortho_x, ortho_y)
plt.scatter(myX_rec[:,0], myX_rec[:,1], color ='w', marker='o', edgecolor = 'r', linewidths=0.2, label = "proj dots") #投影空间散点
for i in range(len(myX)): #对应关系
plt.plot([myX[i,0], myX_rec[i,0]], [myX[i,1], myX_rec[i,1]], 'k--', linewidth = 0.4)
plt.axis("equal")
plt.grid()
plt.legend()
plt.show()
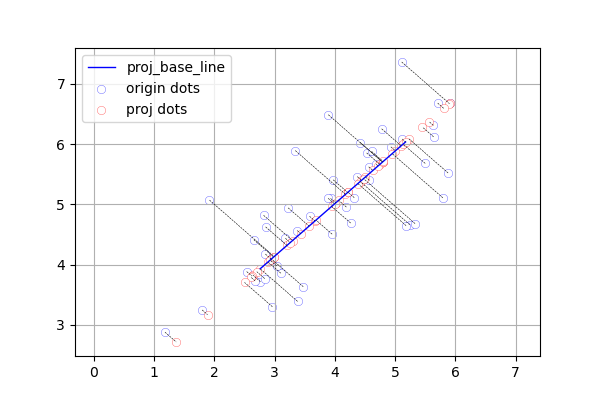
Figure_2 PCA对应
PCA优缺点
(1) 理论基础好,流程清晰,操作简单
(2) 可能会与实际业务有偏差
这里奇异值还是根据数据的变异情况来定主成分的,有时候定的主成分并非业务上的主要成分,还要联系实际情况。
(3) 会丢掉部分信息
极端的情况,如果我们保留所有特征向量,进行投影的话,不会损失信息,但同时又达不到数据压缩的目的,所以要在在信息丢失有限的情况下,选择尽可能小的主成分数,假设希望损失的信息不超过1%,那么在选择主成分数的时候可以去计算特征值矩阵S的迹占比
让k从1取到m, 看下面式子什么时候能满足,找出最小的k值。
(4) PCA之后的特征代表的意义不明确,不易于解释。
PCA应用场景
PCA能够将重点因素突出,不明显的因素隐藏掉,做到主谓分明,主要用于数据降维处理,对数据压缩去噪去冗余,还可以用在推荐系统里面。
参考文献
1,https://www.cnblogs.com/pinard/p/6251584.html
2, A Singularly Valuable Decomposition: The SVD of a Matrix
- - -The end- - -
交流群限时免费,入口见菜单栏
三行科创微信公众号欢迎投稿
稿件聚焦数学逻辑,数学工程,数学文化等领域
一经采用,我们将奉上酬劳
投稿邮箱:sanhang_kc@163.com
商务合作:17521754388

