




上一篇文章介绍了应用百度AI的文字识别功能对营业执照进行识别。
本文介绍应用百度AI的文字识别功能对身份证进行识别,感兴趣的朋友一起来看看效果吧。
安装baidu-aip模块
获取百度AI接口密钥
调用百度接口识别身份证

按win+R打开cmd,在里面输入
pip3 install baidu-aip
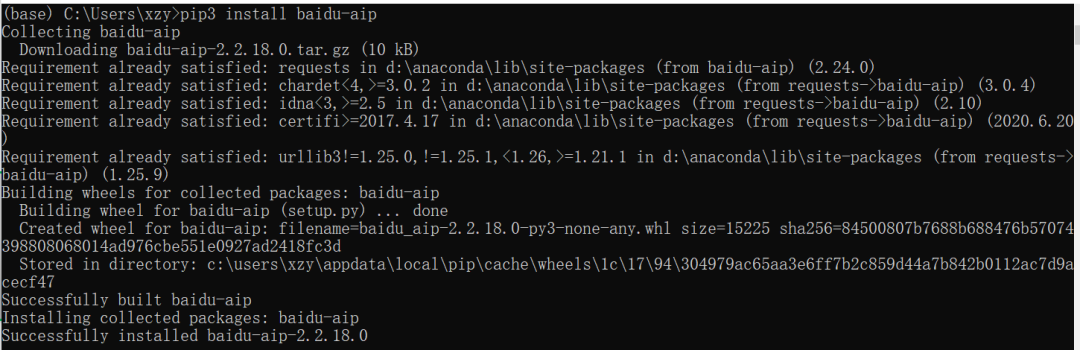
在应用python识别身份证的过程中,有三行代码使用了百度AI接口密钥,故先阐述如何获得该密钥。
首先,进入如下百度AI官方网站:
https://ai.baidu.com/tech/ocr
有百度账户的输入账户密码进行登录,没有的点击注册,按指示输入相关信息即可注册登录。
登录后找到文字识别中的产品列表,下方有卡证文字识别内容,点击了解详情。
可以发现卡证文字识别中包含了我们常见的一些证件的识别,比如身份证、银行卡、营业执照、户口本、护照等。
本文阐述营业执照的识别,感兴趣的同学可以自行研究其它证件的识别。
在卡证文字识别的详情中可以发现如下产品列表:
找到身份证识别,点击了解详情,即可进入如下界面:
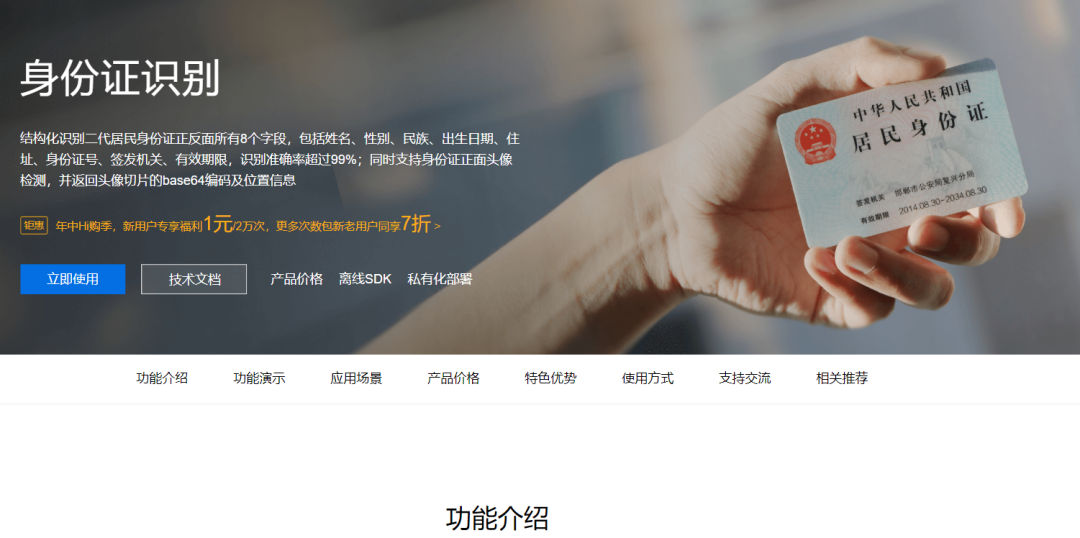
点击立即使用,就会出现如下服务协议:
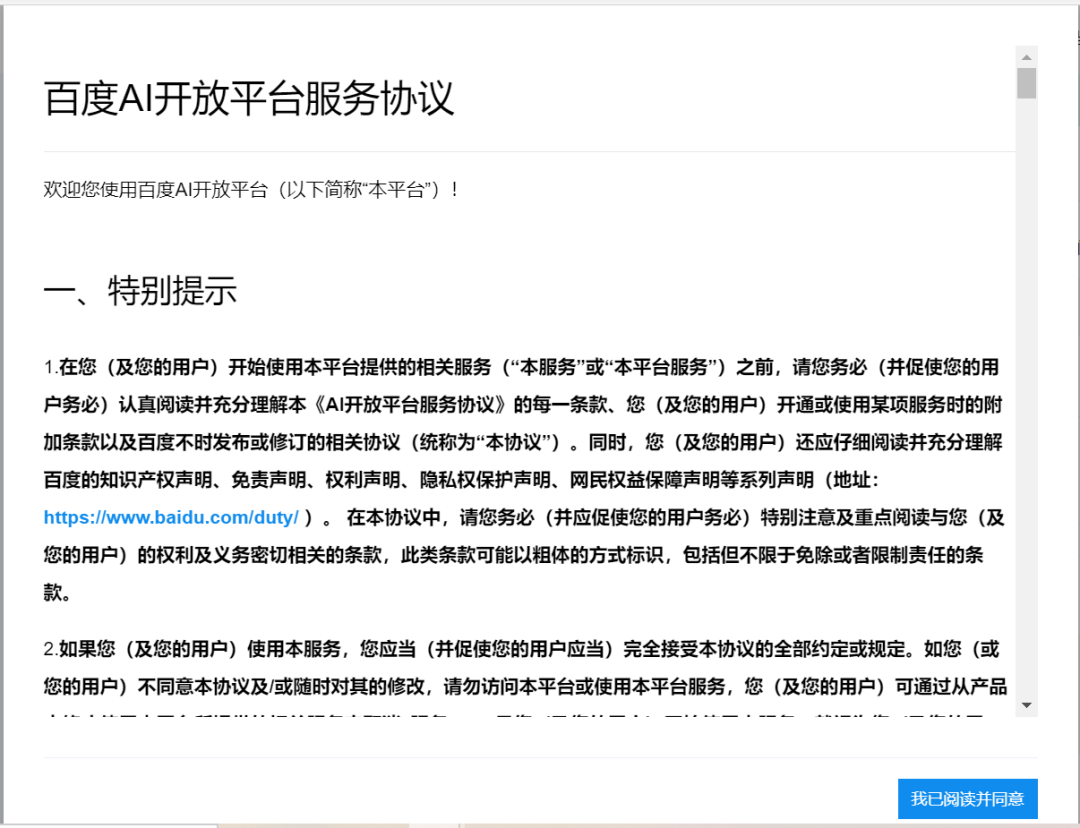
点击我已同意百度AI开放平台服务协议,就可以进入如下界面:
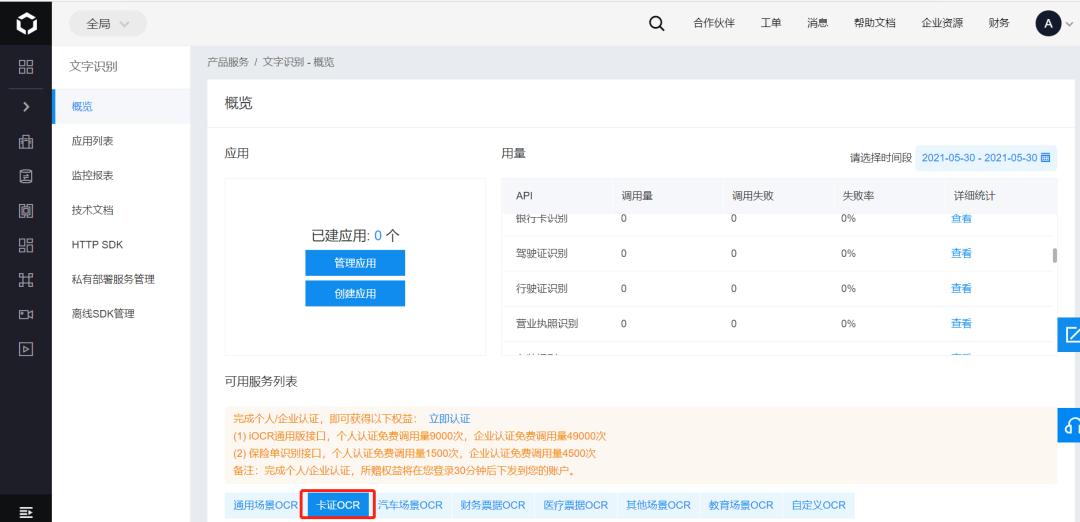
下滑后点击卡证OCR,就可以发现身份证别功能,点击开通按钮。
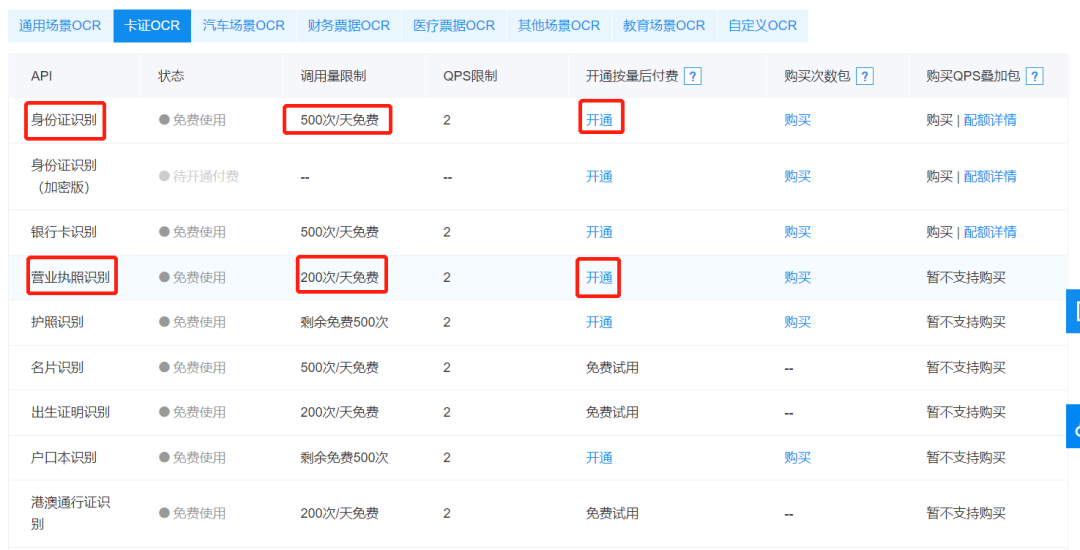
在确认开通之前,要先进行实名验证,按指示进行操作即可完成实名验证。
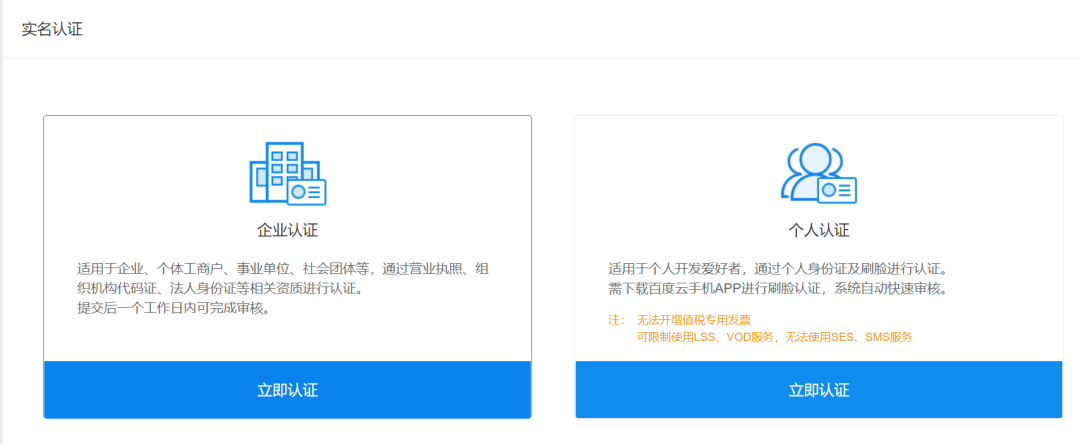
接着可以勾选要开通的识别功能,具体如下:
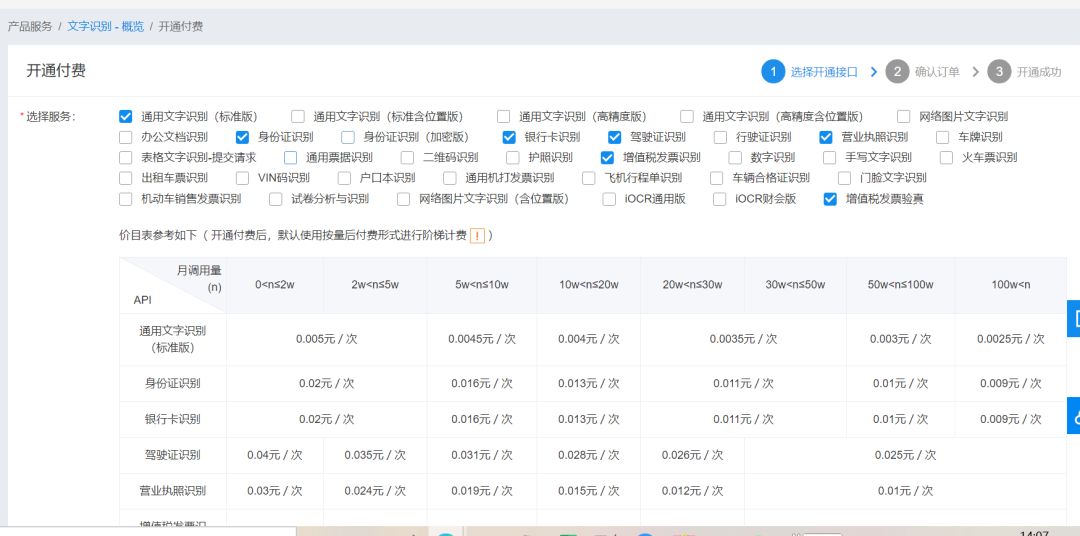
然后点击去支付,由于每天前多少次是免费的,且采取后付费模式,故不需提前付费。若开通成功,会出现如下界面:
开通成功后,点击概览中的创建应用。
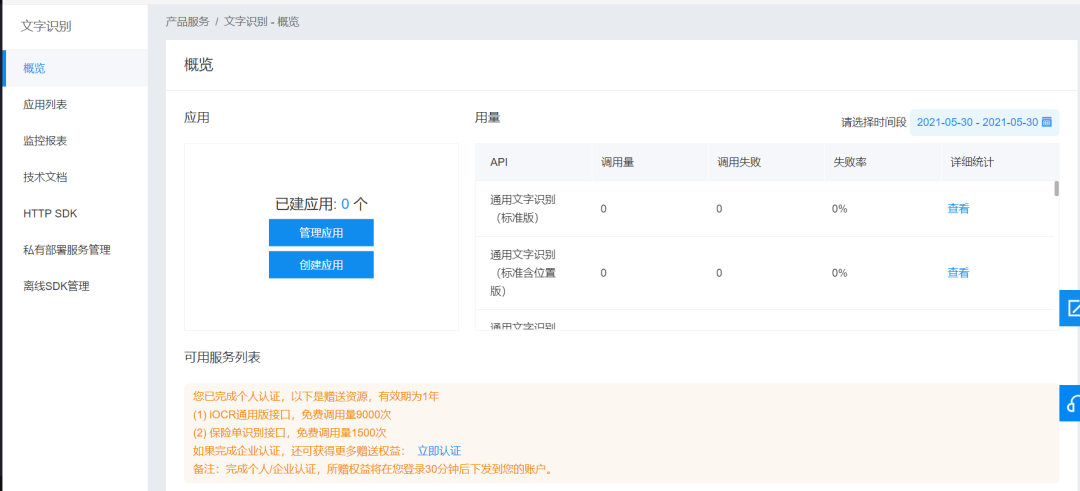
填写应用名称(自己想一个贴合自己应用场景的名字即可)、选择文字识别包名、选择应用归属、填写应用描述,点击立即创建即可。
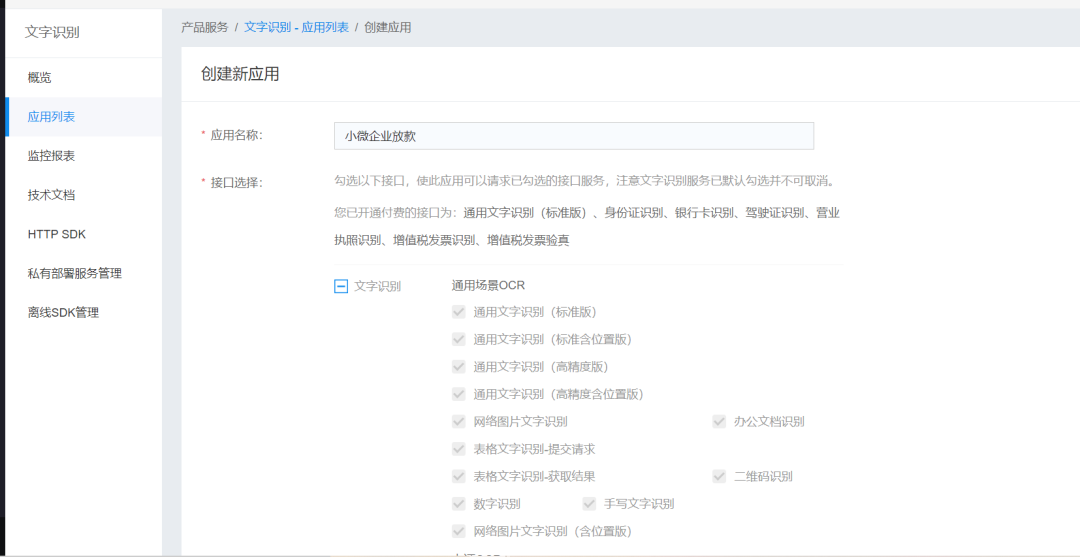
最后,点击应用详情,即可找到我们需要的接口密钥(红框对应的值)。
安装好baidu-aip模块,获取了百度AI接口密钥后,即可调用百度接口识别身份证了。
身份证识别每天有5百次的免费调用机会,首先来看下今天要识别的身份证。

这张身份证是在百度上下载的一张虚拟身份证,如有侵权,请联系我删除。
识别该身份证的具体python代码如下:
import reimport osimport timefrom aip import AipOcros.chdir(r'F:\公众号\27.证件识别')#设置证件存放的路径APP_ID = 'XXX'API_KEY = 'XXXXXXXX'SECRET_KEY = 'XXXXXXXXXXXX'#百度账号和密钥,需替换成你的picture = open('2_身份证_v3.jpg', 'rb')img = picture.read()#读取图片idCardSide = 'front' #身份证正面#idCardSide = 'back' #身份证反面options = {}options['detect_direction'] = 'true' #是否检测图像朝向,默认不检测options['detect_risk'] = 'false' #是否开启身份证风险类型client = AipOcr(APP_ID, API_KEY, SECRET_KEY)text = client.idcard(img, idCardSide, options)#识别图片中的信息concat_text = []if isinstance(text, dict):words = text['words_result']for k, v in words.items():print(u'{k}:{v}'.format(k=k, v=v['words']))tt = u'{k}:{v}'.format(k=k, v=v['words'])concat_text.append(tt)#把字典解析成我们熟悉的形式
注:其中os.chdir中的内容应该替换成你存储图片的地址,APP_ID、API_KEY、SECRET_KEY应该替换成第二章末尾你获取的百度密钥。
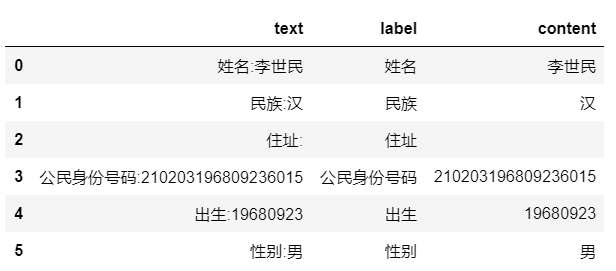
得到结果如下:

对比原始图片可以发现,出生是直接从身份证号码中截取的,住址的信息可能由于反光没有识别出来,结果为空。
这里有个小插曲,我之前一直使用png格式的身份证图片进行调用识别,但一直报如下错误:
ConnectionError: ('Connection aborted.', ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None))
后面调整为jpg图片后,就没有出现该问题了,所以建议在进行身份证识别时最好把图片的格式设置为jpg。
为进一步规范输出成标准格式,通过如下代码进行规范化:
import pandas as pddate_concat_text = pd.DataFrame(concat_text)date_concat_text.columns =['text']df = date_concat_text["text"].str.split(':',expand=True)date_concat_text['label'] = df.iloc[:,0]date_concat_text['content'] = df.iloc[:,1]date_concat_text.to_csv("id_card_to_text.csv")
得到结果如下:
至此,调用百度接口识别身份证已讲解完毕,感兴趣的朋友自己实现一遍吧。
https://www.pianshen.com/article/7641312664/https://www.cnblogs.com/z-x-h/p/12116453.htmlhttps://www.cnblogs.com/zh-1721342390/p/9318619.htmlhttps://blog.csdn.net/zhyl4669/article/details/88947571


扫一扫关注我
13162366985
投稿微信号、手机号
