




点击上方蓝字关注我们





数据湖越来越被人们提起,即期待它带来的收益,但面对复杂的架构和很高的学习成本,又让人望而却步。今天介绍一种超级简单的数据湖方法实现。(一般人我不会告诉他那是我们生产方案)

Delta Lake
Delta Lake 在数据湖三剑客中备受受关注。是因为贡献公司Databricks 它就是那个Spark商业化公司,资料还是很全的。
https://delta.io/
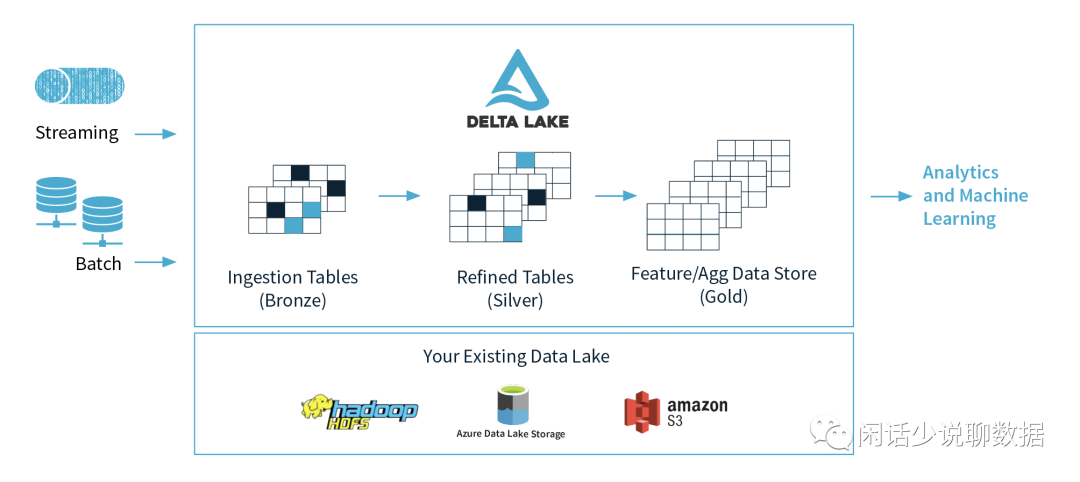
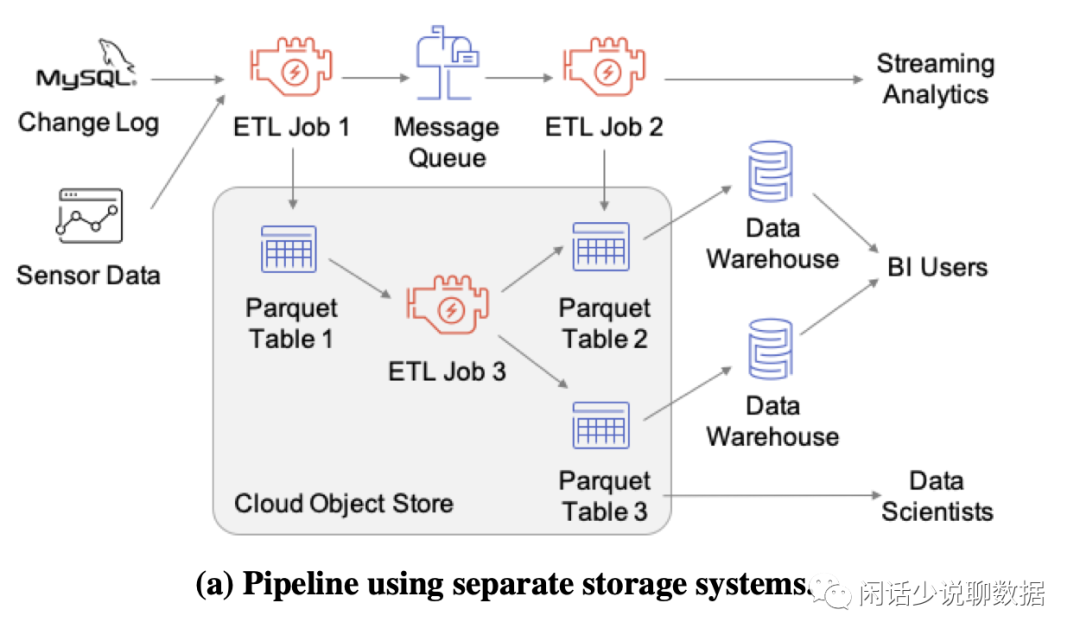
(a)做为一个单独的存储分支。湖->仓还是分开存储(今天主要讲它的实现)。
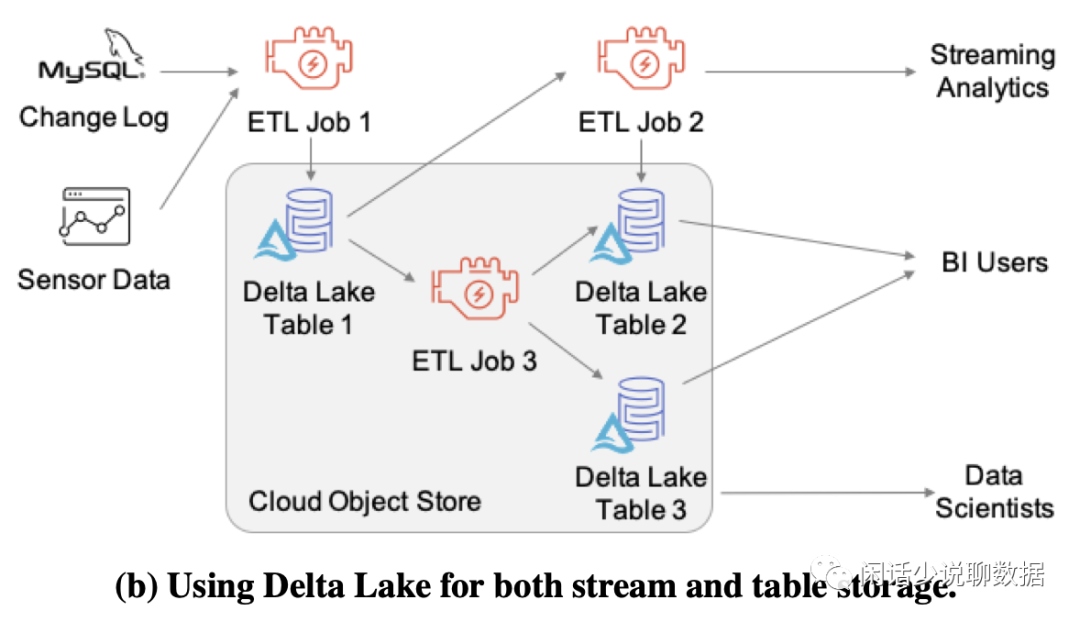
(b)做流和表的存储(批流合一,湖仓一体)

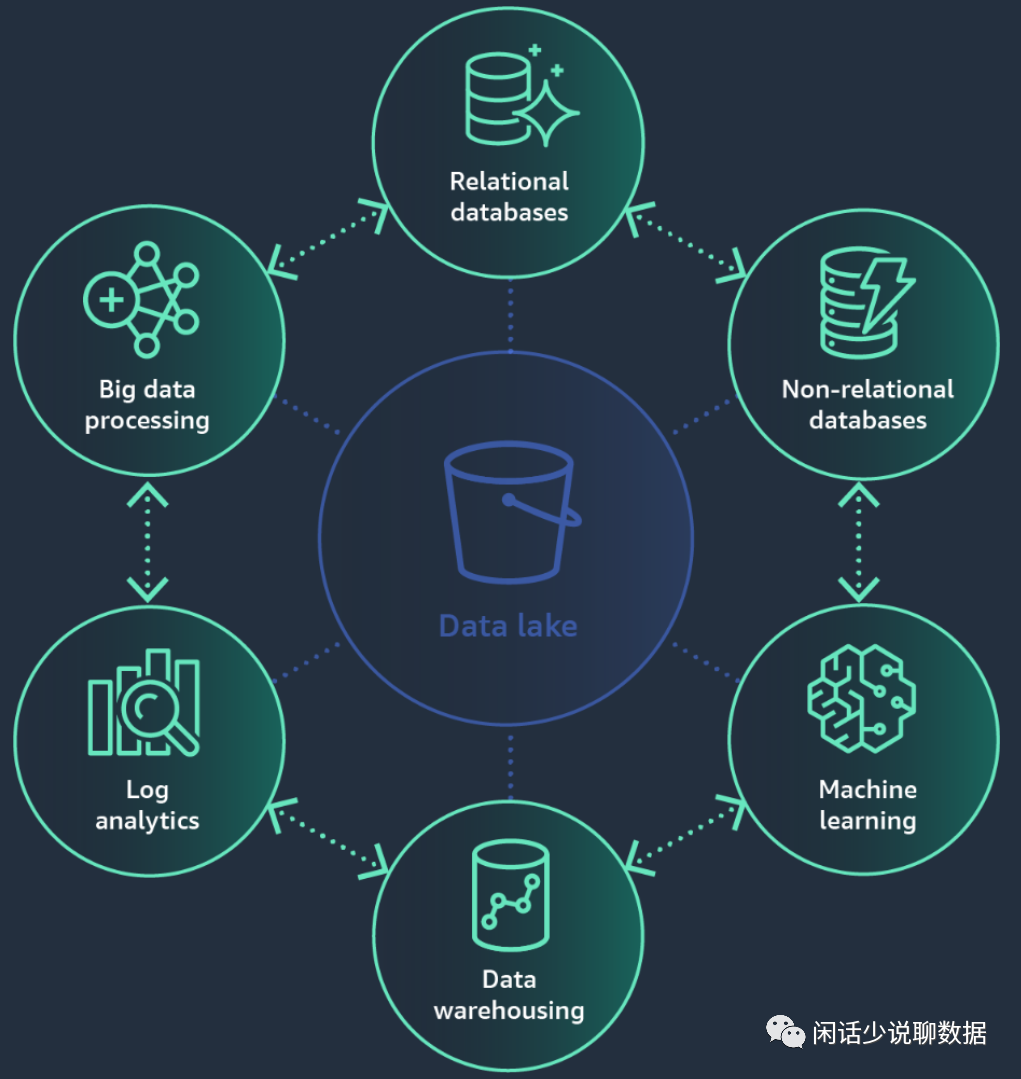
AWS数据湖关系图
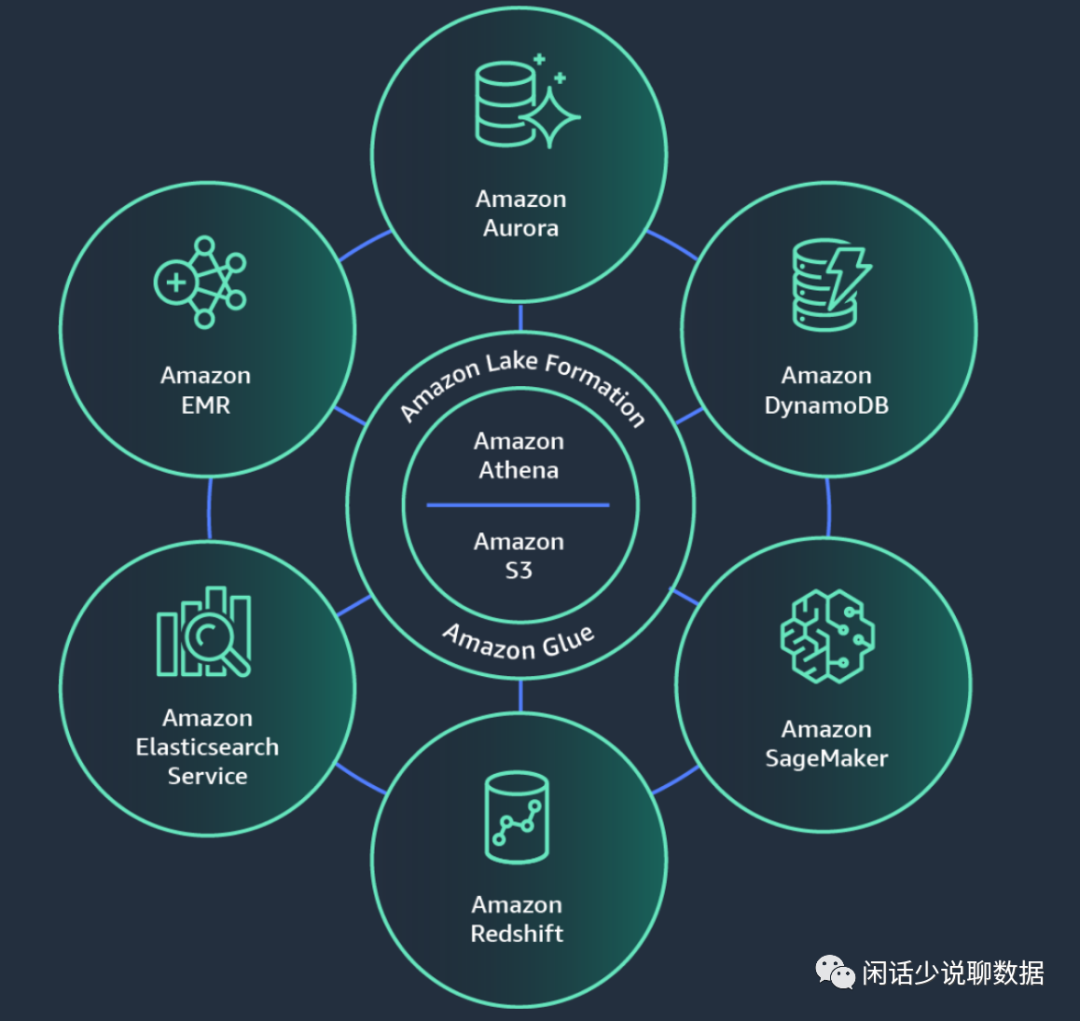
为了好理解数据湖,再上一个AWS商业产品。
https://aws.amazon.com/cn/big-data/datalakes-and-analytics/data-lake-house/?nc=sn&loc=11
(这段纯个人看图理解)数据湖和周边数据产品的关系和作用:
1)提供实时关系型时的数据。
2)提供实时非关系型数据。
3)提供实时的机器学习数据。
4)基于数据湖的数据分析。
5)基于数据湖的数仓仓库。
欣赏一下AWS全套的产品解决方案:
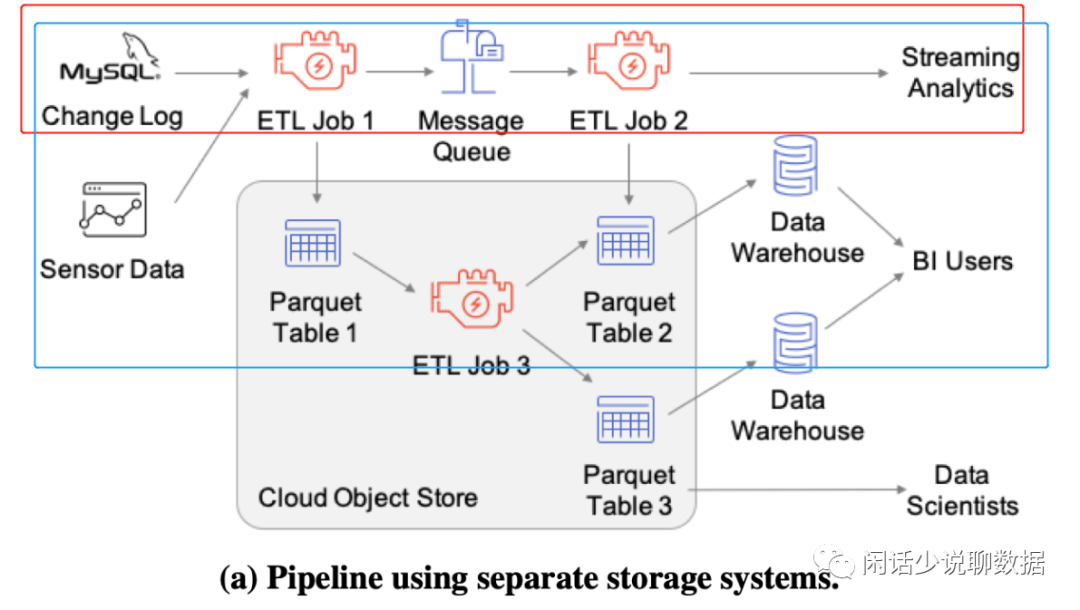
今天主要介绍一下,蓝色框从湖到仓的链路,红色框流链路也类似:
这里需要引入一个免费工具Streamsets (有需要可以详细出一篇)
(具体叫 StreamSets Data Collector 只有这个免费)能完成上图的蓝色框和红色框功能。
https://streamsets.com/products/dataops-platform/data-collector/
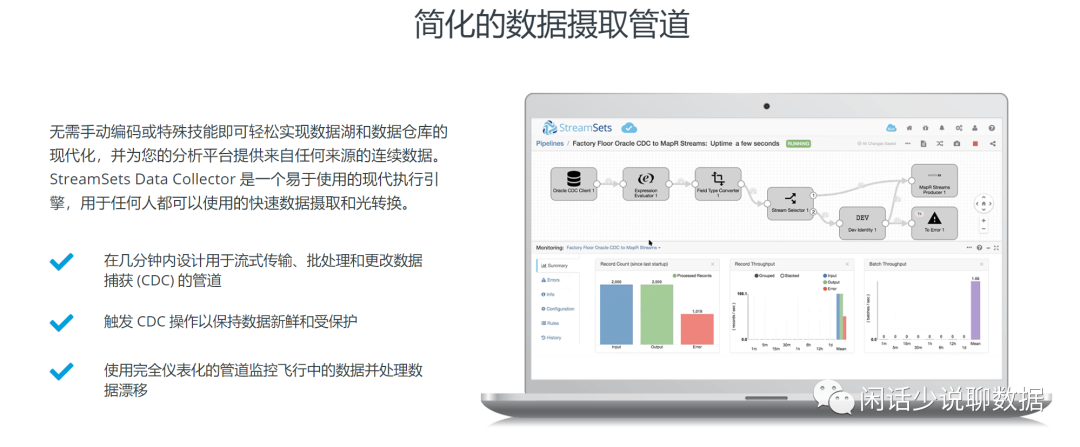
目前我们生产上是这个3个Pipeline,介绍第一种配置。
1)Mysql bin-log -> Streamsets处理 -> Kudu (也可以替换Hudi,Delta Lake)
2)Mysql bin-log -> Streamsets处理 -> MQ(Kafka)
3)MQ -> Streamsets处理 -> Hive
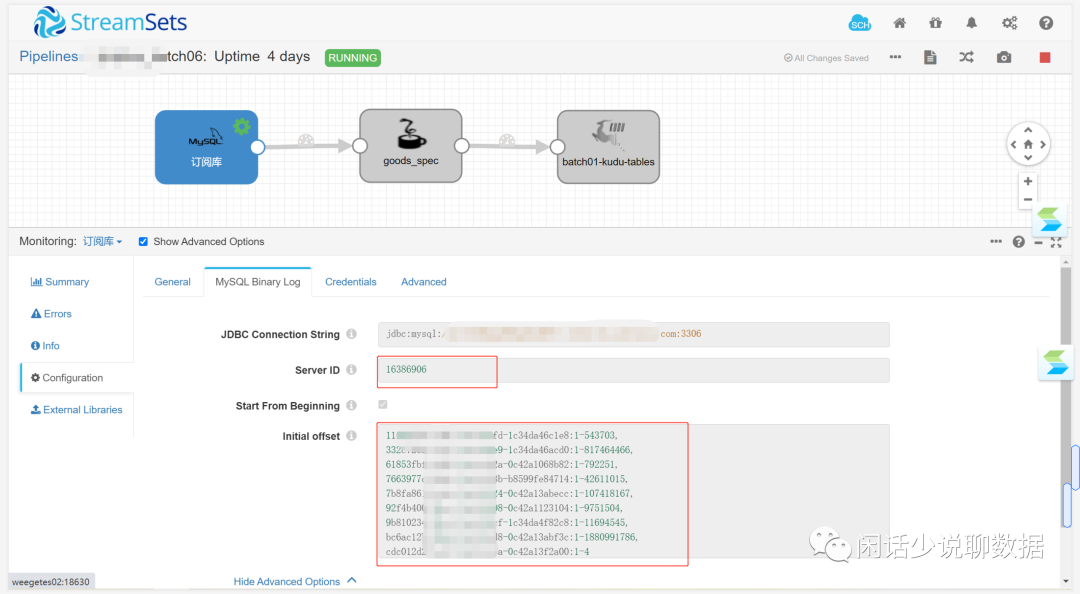
1、源端配置用 MySQL Binary Log
这里使用有几个坑,先简单提一下,如果有需要我后面再展开来讲:
1)Mysql binlog开了GTID,需要走GTID的同步方式,不会走binlog。
2)GTID将所有的都贴上,并修改使用的GTID文件偏移量。
3)ServerID其实不是主服务的ID,只要是唯一不重复就行。
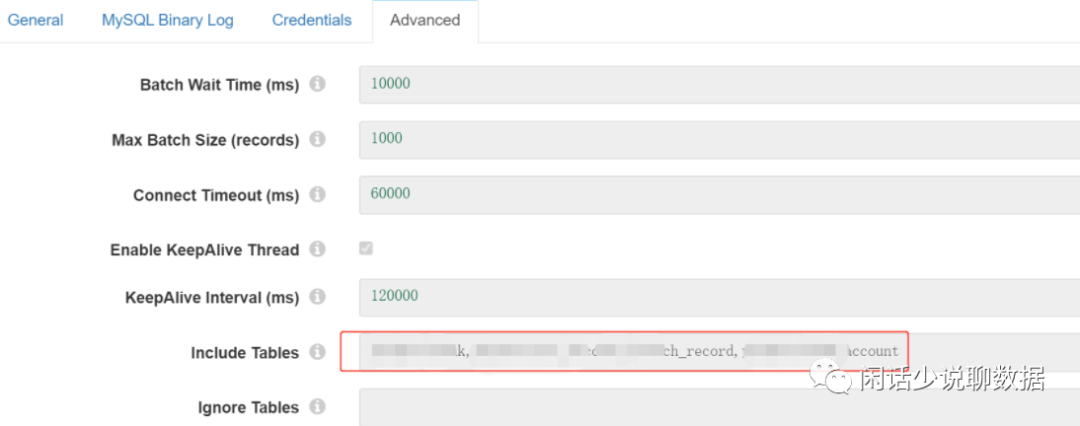
4)可以指定Include Table做初步binlog的过滤(只关心你想同步的表)
指定只处理哪些表:
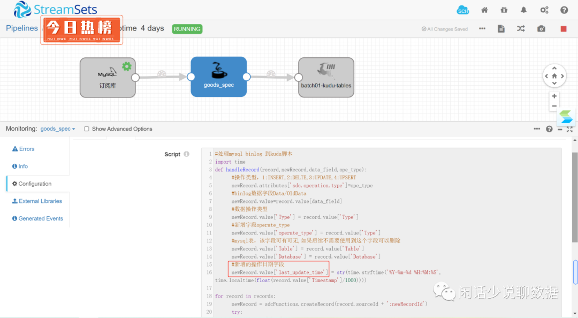
2、数据处理逻辑
为了解决到数仓增量同步的问题,我们在所有的源系统表都加上了last_update_time,业务系统的都是大爷他们改不得。我们也不想入侵业务,这是个好方法。
当然,这里你可以写你的各个数据转换支撑各种语言:python,javascript等。
关键的代码是这几句(python):
#新增的操作日期字段newRecord.value['last_update_time'] = str(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(float(record.value['Timestamp']/1000))))
3、目标表的配置
Sink的时候可按表名自动匹配,不用再拉一个过滤器
(kudu目标表命名需要有规律:如sods.源数据库名_源表名)
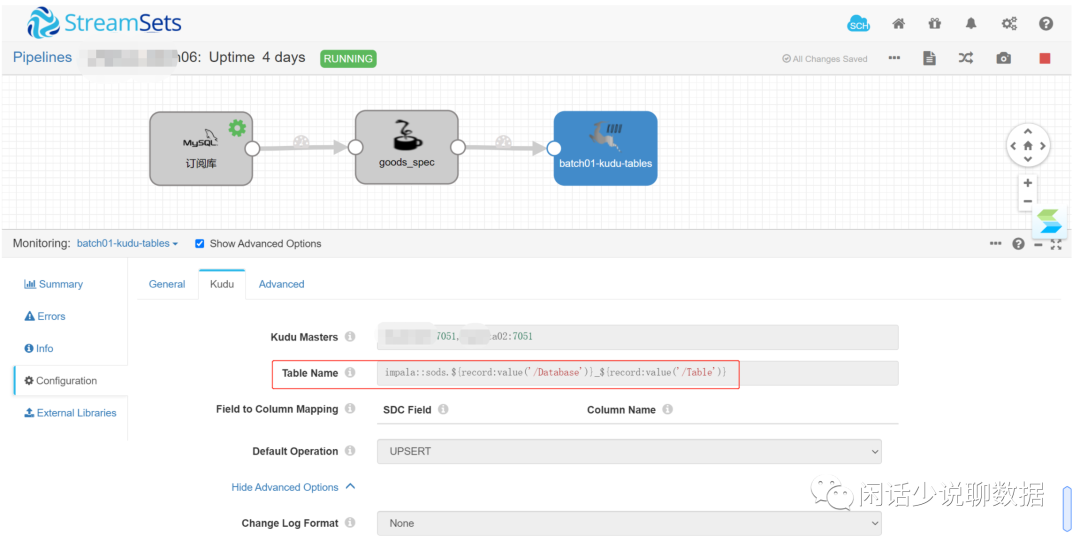
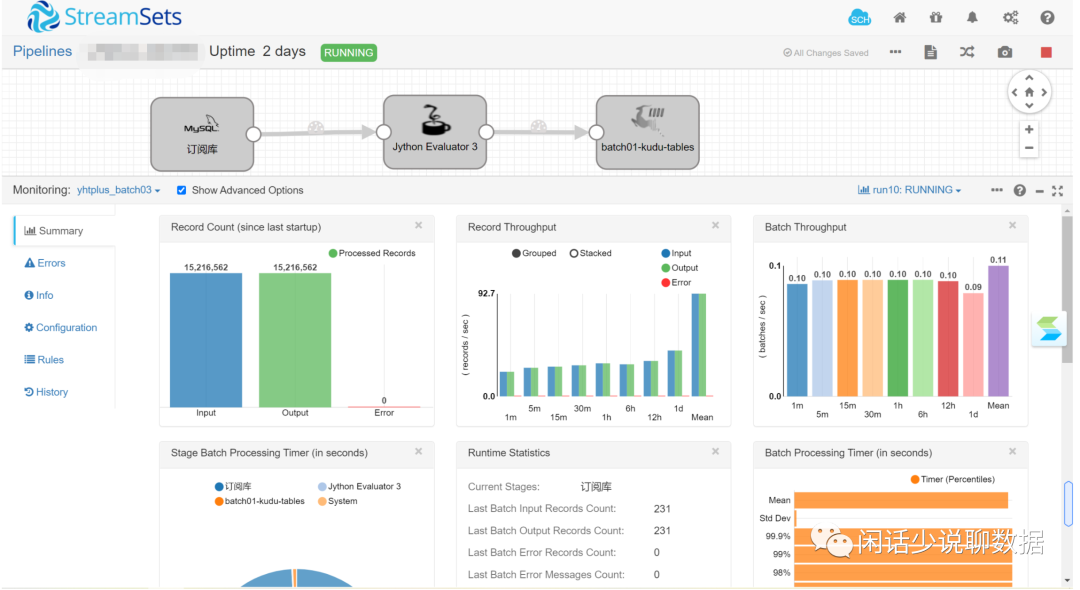
跑起来的图
4、后续。。。。:
你会惊奇的发现,目标里面也包含有这个组件:Delta Lake,意味着你可以以很小的代价,切换到合适的湖。当然你需要上传相关的Delta Lake的包。
也可以实现另外两条链路,还能支持目前呼声很高的:Pulsar。有需求的再出一个对Kafka和Pulsar的链路。
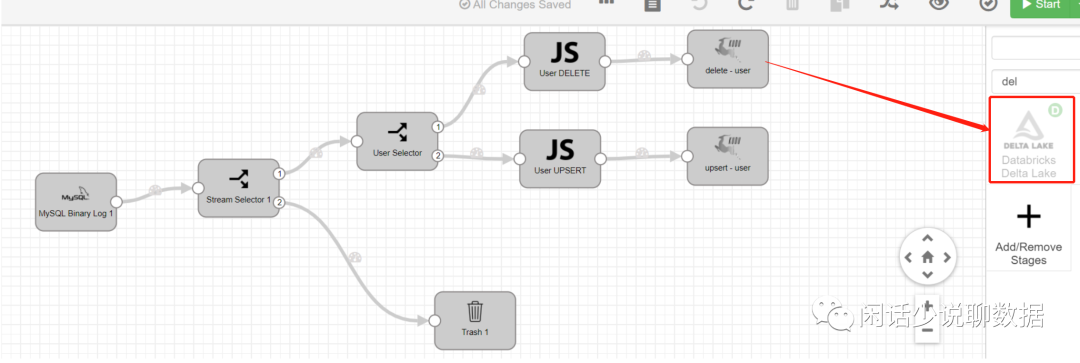
总结起来,使用Streamset,简单3个步骤就能实现高大上的数据湖的方案了,有兴趣同学留言一起交流起来吧。

点个在看你最好看
