本文是Datawhale知识图谱组队学习打卡笔记
学习资源地址:
https://github.com/datawhalechina/team-learning-nlp/tree/master/KnowledgeGraph_Basic
感谢Datawhale社区的无私分享
想学习的小伙伴可以一起来
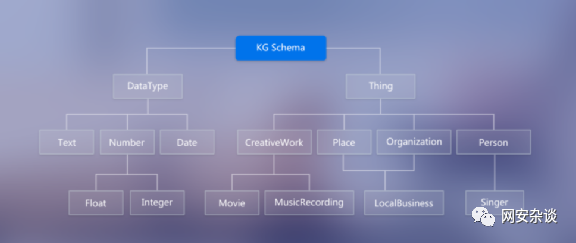
1.知识图谱
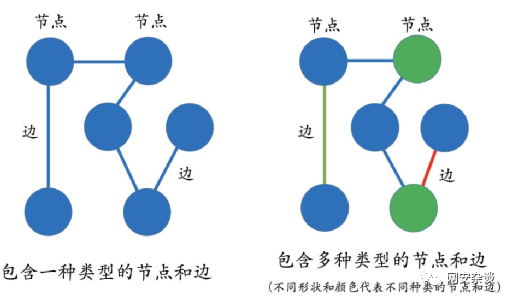
2.知识图谱构建
2.1数据来源
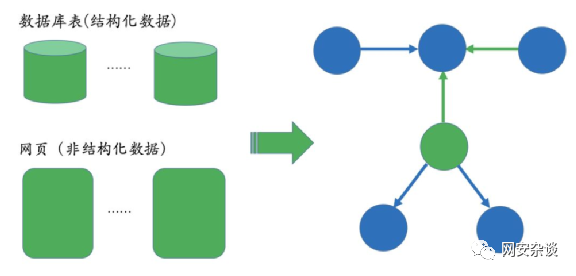
如下图所示,难点是非结构化数据的处理。
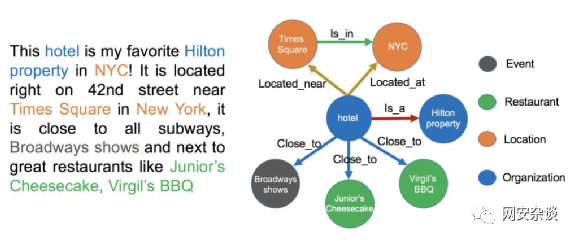 2.2处理技术
2.2处理技术
2.2.1实体命名识别(Name Entity Recognition)简称NER
2.2.2关系抽取(Relation Extraction)简称 RE
2.2.3实体统一(Entity Resolution)简称 ER

2.2.4指代消解(Coreference Resolution)

2.3知识图谱的存储

图数据库的比较:
Neo4j系统目前仍是使用率最高的图数据库,它拥有活跃的社区,而且系统本身的查询效率高,但唯一的不足就是不支持准分布式。相反,OrientDB和JanusGraph(原Titan)支持分布式,但这些系统相对较新,社区不如Neo4j活跃,这也就意味着使用过程当中不可避免地会遇到一些棘手的问题。如果选择使用RDF的存储系统,Jena或许一个比较不错的选择。
3.Neo4J环境配置
3.1下载
3.2Neo4J 安装
在Mac或者Linux中,安装好jdk后,直接解压下载好的Neo4J包,运行命令:
bin/neo4j start
windows系统下载好neo4j和jdk 1.8.0后,输入以下命令启动后neo4j:
neo4j.bat console(要设置好环境变量)

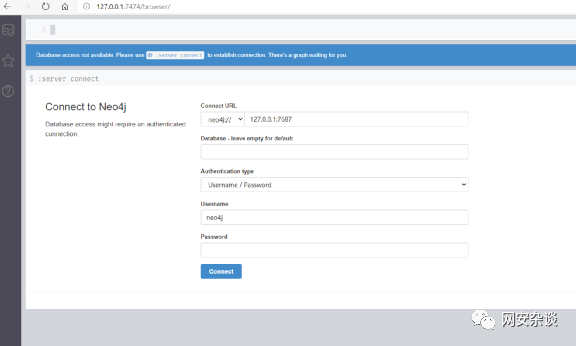
3.3 Cypher查询语言
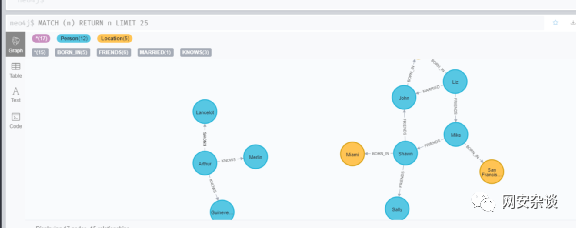
4.neo4j案例实战
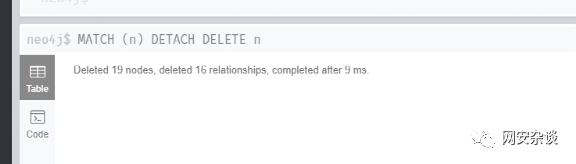
4.1. 清空数据库文件
MATCH (n) DETACH DELETE n
4.2创建节点
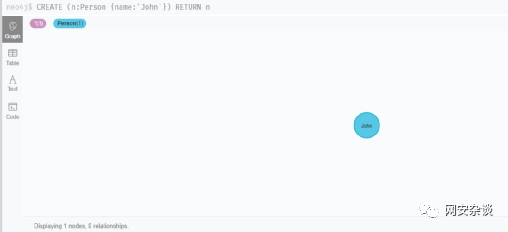
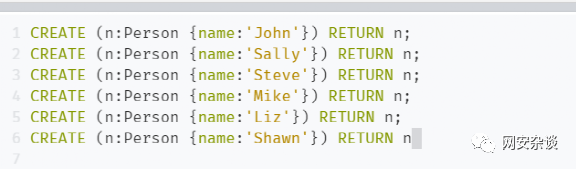
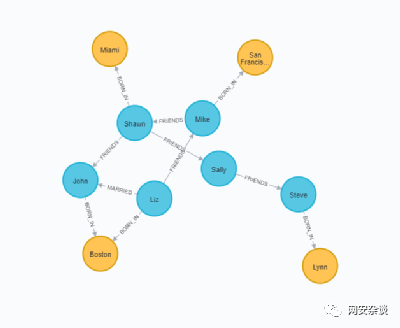
CREATE (n:Person {name:'Sally'}) RETURN nCREATE (n:Person {name:'Steve'}) RETURN nCREATE (n:Person {name:'Mike'}) RETURN nCREATE (n:Person {name:'Liz'}) RETURN nCREATE (n:Person {name:'Shawn'}) RETURN n
CREATE (n:Location {city:'Miami', state:'FL'})CREATE (n:Location {city:'Boston', state:'MA'})CREATE (n:Location {city:'Lynn', state:'MA'})CREATE (n:Location {city:'Portland', state:'ME'})CREATE (n:Location {city:'San Francisco', state:'CA'})

4.3创建关系
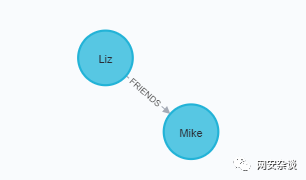
2.关系增加属性
MATCH (a:Person {name:'Shawn'}),(b:Person {name:'Sally'})
MERGE (a)-[:FRIENDS {since:2001}]->(b)
在关系中,同样的使用花括号{}来增加关系的属性,也是类似Python的字典,这里给FRIENDS关系增加了since属性,属性值为2001,表示他们建立朋友关系的时间。
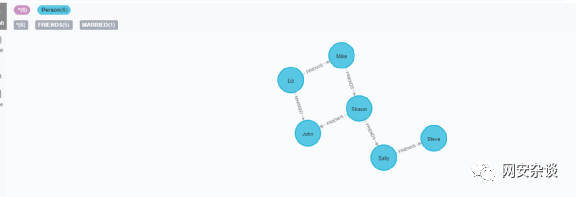
下面增加更多关系
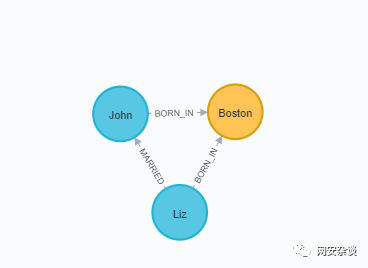
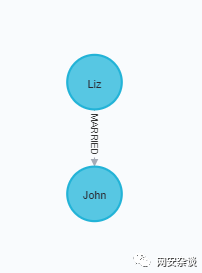
MATCH (a:Person {name:'Shawn'}), (b:Person {name:'John'}) MERGE (a)-[:FRIENDS {since:2012}]->(b)MATCH (a:Person {name:'Mike'}), (b:Person {name:'Shawn'}) MERGE (a)-[:FRIENDS {since:2006}]->(b)MATCH (a:Person {name:'Sally'}), (b:Person {name:'Steve'}) MERGE (a)-[:FRIENDS {since:2006}]->(b)MATCH (a:Person {name:'Liz'}), (b:Person {name:'John'}) MERGE (a)-[:MARRIED {since:1998}]->(b)
MATCH (a:Person {name:'Liz'}), (b:Location {city:'Boston'}) MERGE (a)-[:BORN_IN {year:1981}]->(b)MATCH (a:Person {name:'Mike'}), (b:Location {city:'San Francisco'}) MERGE (a)-[:BORN_IN {year:1960}]->(b)MATCH (a:Person {name:'Shawn'}), (b:Location {city:'Miami'}) MERGE (a)-[:BORN_IN {year:1960}]->(b)MATCH (a:Person {name:'Steve'}), (b:Location {city:'Lynn'}) MERGE (a)-[:BORN_IN {year:1970}]->(b)
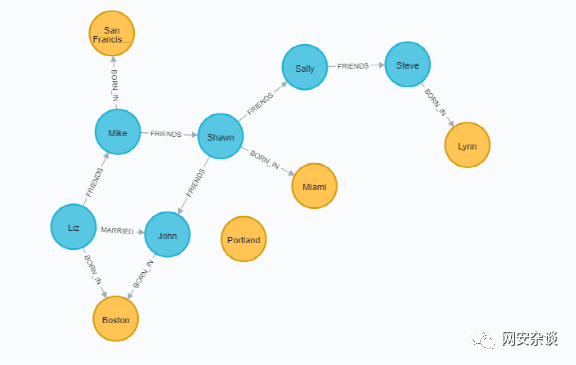
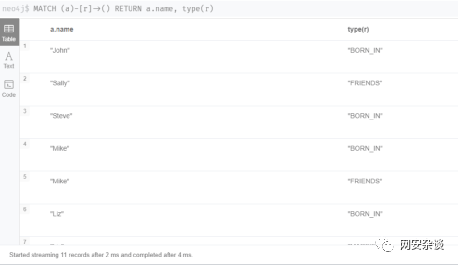
4.4.查询
4.5. 增/删/改
MATCH (a:Person {name:'Liz'}) SET a.age=34MATCH (a:Person {name:'Shawn'}) SET a.age=32MATCH (a:Person {name:'John'}) SET a.age=44MATCH (a:Person {name:'Mike'}) SET a.age=25

MATCH (a:Person {name:'Mike'}) SET a.test='test'MATCH (a:Person {name:'Mike'}) REMOVE a.test
MATCH (a:Location {city:'Portland'}) DELETE a
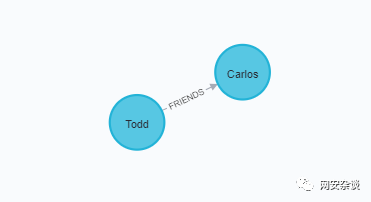
MATCH (a:Person {name:'Todd'})-[rel]-(b:Person) DELETE a,b,rel
5.1利用neo4j模块:执行CQL ( cypher ) 语句
安装neo4j模块(pip install neo4j)
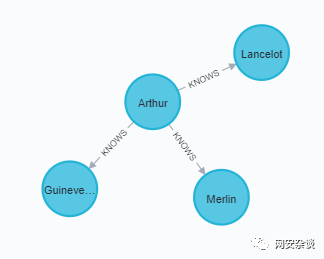
# step 1:导入 Neo4j 驱动包from neo4j import GraphDatabase# step 2:连接 Neo4j 图数据库driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "password")) # 添加 关系 函数def add_friend(tx, name, friend_name): tx.run("MERGE (a:Person {name: $name}) " "MERGE (a)-[:KNOWS]->(friend:Person {name: $friend_name})", name=name, friend_name=friend_name)# 定义 关系函数def print_friends(tx, name):for record in tx.run("MATCH (a:Person)-[:KNOWS]->(friend) WHERE a.name = $name ""RETURN friend.name ORDER BY friend.name", name=name):print(record["friend.name"])# step 3:运行with driver.session() as session:session.write_transaction(add_friend, "Arthur", "Guinevere")session.write_transaction(add_friend, "Arthur", "Lancelot")session.write_transaction(add_friend, "Arthur", "Merlin")session.read_transaction(print_friends, "Arthur")
5.2利用py2neo模块
安装py2neo模块
优点,模块符合python的习惯,可以完全不会CQL也能写。
基本用法参考:https://zhuanlan.zhihu.com/p/81175725
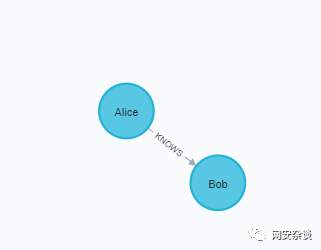
# step 1:导包from py2neo import Graph, Node, Relationship# step 2:构建图g = Graph("http://localhost:7474",auth=("neo4j","password"))# step 3:创建节点tx = g.begin()a = Node("Person", name="Alice")tx.create(a)b = Node("Person", name="Bob")# step 4:创建边ab = Relationship(a, "KNOWS", b)# step 5:运行tx.create(ab)tx.commit()
6.批量导入图数据