




互联网 · 机器学习 · 产品分析
关注SeekJoy觅乐一网打尽
微信号:SeekJoyMillet
蓝字关注
最近实验室在构建一个有关于全国科研人员的知识图谱网络,以希望利用图方法分析科研人员的学术水平、合著网络、社群发现以及其他能够反映科研人员背景的功能,最终以Web的方式呈现各类分析和统计结果。
数据部分的关键就是将甲方提供的关系型数据(存储于Oracle
中),使用Nifi
对这些数据进行采集并存入Hive
数据库中。然后对Hive
中的数据进行清洗,按照文档设计要求以节点
和边
的形式导入Neo4j
创建图数据库。
将Hive的原始数据按照节点/边的形式导入Neo4j有两种方法:
1,使用Hive和Neo4j提供的JDBC,利用Java导入。
2,使用hive命令将Hive数据导出为csv
格式,在Neo4j的Web端利用Cypher语句直接load进Neo4j。
1, 使用Hive和Neo4j的JDBC驱动
配置maven依赖,主要依赖包:
创建节点的实例代码,边同理:(微信编辑的代码排版无法缩进,请参考原文链接)
这里注意:
Neo4j有两种写入方式,
CREATE
和MERGE
。官方文档的介绍是:
CREATE
: TheCREATE
clause is used to create graph elements — nodes and relationships.MERGE
: TheMERGE
clause ensures that a pattern exists in the graph. Either the pattern already exists, or it needs to be created.主要差别在于,如果遇到重复的节点(各种属性完全一致),
CREATE
依然会写入一个新的节点。而MERGE带有返回值,不会写入新的节点,会马上返回已存在的节点(如果你不用返回值,就可以当做什么都没发生),如果节点不存在,则会直接写入。所以MERGE
可以帮助去重。
2, 使用CSV文件导入Neo4j
由于使用JDBC的速度十分慢,如果数据是结构化的,可以将Hive中的数据导出为csv文件。然后利用Cypher语句load进入Neo4j。例如导入一个我们设计的边Fund,步骤如下:
这里注意:
USING PERIODIC COMMIT 10000
表示每读入10000条数据(边)写入一次Neo4j。如果没有这条语句,Neo4j只会在最后进行一次性提交,如果数据量较大一定要写这一条,否则内存会撑爆。使用csv导入的时间非常快,原始1300多万条的边数据,csv可以半个小时就导入完毕,如果使用JDBC则需要两天两夜。
一定局限:
逻辑比较复杂的数据清洗,以及需要对原始数据进行判断时,使用csv会出现一定的局限性,此时则需要使用JDBC。但是如果仔细思考,从hive和neo4j两头入手,也可以想办法规避这些局限性。(对neo4j的高级语法不是很熟悉)
3, Neo4j图数据库优点
3.1, 介绍
NoSQL
数据库相信大家都听说过。它们常常可以用来处理传统的关系型数据库所难以解决的一系列问题。通常情况下,这些NoSQL数据库分为Graph
,Document
,Column Family
以及Key-Value Store
等四种。这四种类型的数据库分别使用了不同的数据结构来记录数据。因此它们所适用的场景也不尽相同。
我们可以把Neo4j看作是一个高性能的图引擎,该引擎具有成熟和健壮的数据库
的所有特性。程序员工作在一个面向对象的、灵活的网络结构下,而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
3.2, 与传统关系型数据库的区别
图数据库相对于传统的关系型数据库的优点, 图形数据库Neo4J简介给出了很详细的阐述。
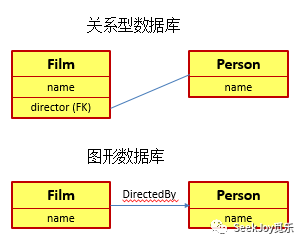
总的来说就是,传统的关系型数据库各种实体(例如Person/Course/Building)是一个单独的表
,实体与实体直接的关系
则需要大量的关联表
来记录这一系列复杂的关系,更多实体引入之后,我们将需要越来越多的关联表,从而使得基于关系型数据库的解决方案繁琐易错。
这一切的症结主要在于关系型数据库是以为实体建模这一基础理念设计的。该设计理念并没有提供对这些实体间关系
的直接支持。在需要描述这些实体之间的关系时,我们常常需要创建一个关联表
来记录这些数据之间的关联关系,而且这些关联表常常不用来记录除外键之外的其它数据
。也就是说,这些关联表也仅仅是通过关系型数据库所已有的功能来模拟实体之间的关系。这种模拟导致了两个非常糟糕的结果:
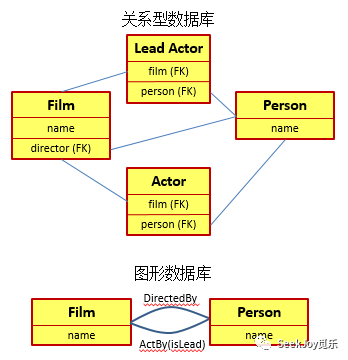
1, 数据库需要通过关联表间接地维护实体间的关系,导致数据库的执行效能低下;
2, 同时关联表的数量急剧上升。
同时:
更快的数据库操作。当然,有一个前提条件,那就是数据量较大,在MySql中存储的话需要许多表,并且表之间联系较多(即有不少的操作需要join表)。
数据更直观,相应的SQL语句也更好写(Neo4j使用Cypher语言,与传统SQL有很大不同)。
更灵活。不管有什么新的数据需要存储,都是一律的节点和边,只需要考虑节点属性和边属性。而MySql中即意味着新的表,还要考虑和其他表的关系。
数据库操作的速度并不会随着数据库的增大有明显的降低。这得益于Neo4j特殊的数据存储结构和专门优化的图算法。
对于底层存储可以参考:http://www.cnblogs.com/rubinorth/p/5846140.html

参考资料:
见原文链接。
