




1. List(列表)
Redis的列表相当于java语言里的linkedlist,注意它是链表而不是数组。这意味着list的插入和删除操作非常快,时间复杂度为O(1),但是索引定位很慢,时间复杂度为O(n)。
当列表弹出了最后一个元素之后,该数据结构自动被删除,内存被回收。
Redis的列表结构常用来做异步队列使用。将需要延后处理的任务结构体序列化成字符串塞进redis的列表,另一个线程从这个列表中轮询数据进行处理。
1.1. 基本操作
右边进左边出:队列
127.0.0.1:6379> rpush books python java golang (integer) 3 127.0.0.1:6379> llen books (integer) 3 127.0.0.1:6379> lpop books "python" 127.0.0.1:6379> lpop books "java" 127.0.0.1:6379> lpop books "golang" 127.0.0.1:6379> lpop books (nil) |
右边进右边出:栈
127.0.0.1:6379> rpush books python java golang (integer) 3 127.0.0.1:6379> rpop books "golang" 127.0.0.1:6379> rpop books "java" 127.0.0.1:6379> rpop books "python" 127.0.0.1:6379> rpop books (nil) |
慢操作
Index相当于Java链表的get(int index)方法,它需要对链表进行遍历,性能随着参数index增大而变差。
Ltrim和字面上的意思有点不一样,其实应该是lretain(保留)更合适一点,因为ltrim跟的两个参数start_index和end_index 定义了一个区间,在这个区间内的值是保留的,区间外的会被统统砍掉。我们可以通过ltrim来实现一个定长的列表,这一点非常有用。
Index可以为负数,-1表示最后一个元素,-2表示倒数第二个元素。
127.0.0.1:6379> rpush books python java golang (integer) 3 127.0.0.1:6379> lindex books 1 #O(n) 慎用 "java" 127.0.0.1:6379> lrange books 0 -1 #获取所有元素,O(n) 慎用 1) "python" 2) "java" 3) "golang" 127.0.0.1:6379> ltrim books 1 -1 #O(n) 慎用 OK 127.0.0.1:6379> lrange books 0 -1 1) "java" 2) "golang" 127.0.0.1:6379> llen books (integer) 2 127.0.0.1:6379> ltrim books 1 0 #其实是清空了整个列表,因为长度为负数 OK 127.0.0.1:6379> llen books (integer) 0 |
1.2. 快速列表
如果再深入一点,会发现redis底层存储的还不是一个简单的linkedlist,而是称为快速链表quicklist的一个结构。
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成quicklist。因为普通的链表需要的附加指针空间太大,会比较浪费空间,而且会加重内存的碎片化。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。所以redis将链表和ziplist结合起来组成了qicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
可以做一个实验
127.0.0.1:6379> rpush books go java python (integer) 3 127.0.0.1:6379> debug object books Value at:0x7f280348fd90 refcount:1 encoding:quicklist serializedlength:31 lru:3160199 lru_seconds_idle:7 ql_nodes:1 ql_avg_node:3.00 ql_ziplist_max:-2 ql_compressed:0 ql_uncompressed_size:29 |
观察上面输出字段encoding的值,quicklist是ziplist和linkedlist的混合体,它将linkedlist按段切分,每一段使用ziplist来紧凑存储,多个ziplist之间使用双向指针串接起来。
1.3. 数据结构
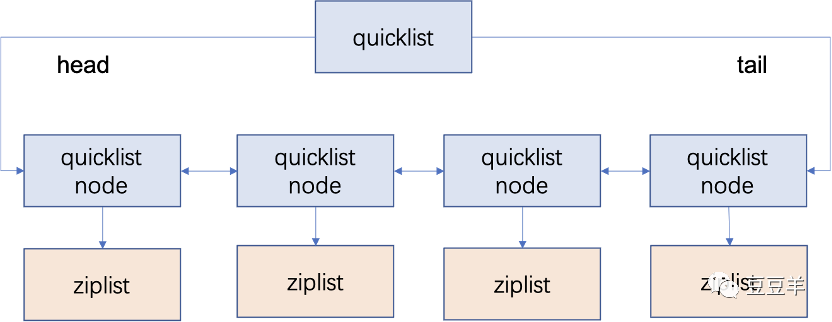

1.3.1. quicklist
quicklistNode *head; /* 头结点 */
quicklistNode *tail; /* 尾结点 */
unsigned long count; /* 在所有的ziplist中的entry总数 */
unsigned long len; /* quicklist节点总数 */
int fill : QL_FILL_BITS; /*每个节点的最大容量 */
unsigned int compress : QL_COMP_BITS; * quicklist的压缩深度,0表示所有节点都不压缩,否则就表示从两端开始有多少个节点不压缩 */
unsigned int bookmark_count: QL_BM_BITS; *bookmarks数组的大小,bookmarks是一个可选字段,用来quicklist重新分配内存空间时使用,不使用时不占用空间*/
quicklistBookmark bookmarks[];
我们来看一下源码中对节点定义的填充容量、quicklist的压缩深度,以及bookmarks数组的大小的分配值。
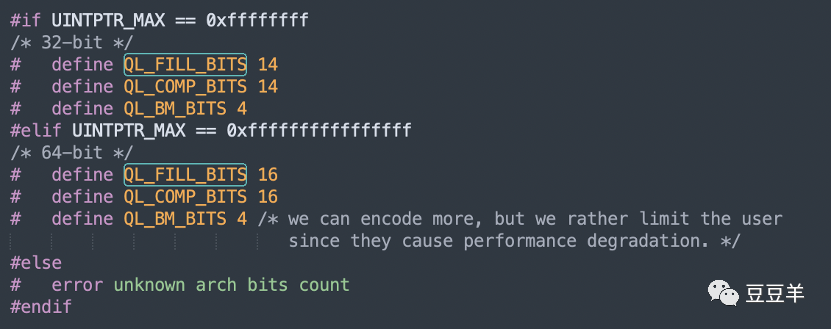
如果是32位的系统:
quicklist每个节点的填充容量是14,压缩深度是14,bookmarks大小是4;
如果是64位的系统:
quicklist每个节点的填充容量是16,压缩深度是16,bookmarks大小是4;
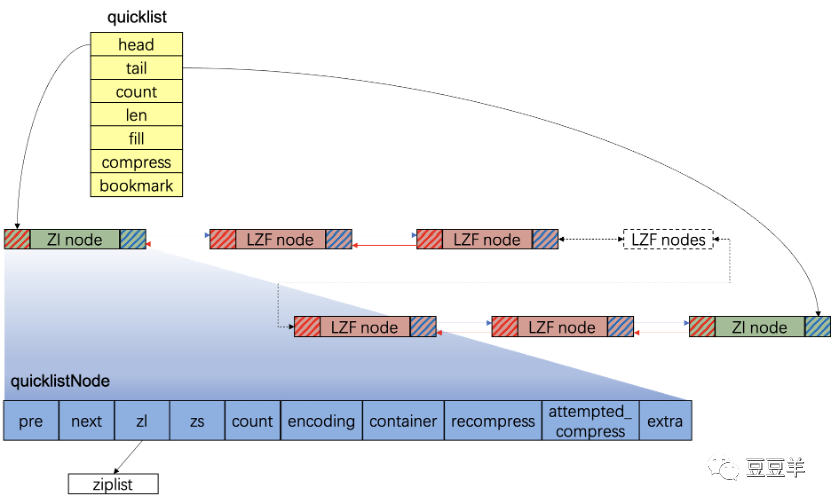
以上是我根据数据结构梳理出来的quicklist结构图,可以看出它其实就是简单的双向链表。其中绿色的是普通的ziplist节点,红色的是被压缩后的ziplist节点(LZF),LZF是一种无损压缩算法。Redis为了节省内存空间,会将quicklist的节点用LZF压缩后存储,但这里不是全部压缩,可以配置compress的值(看一下quicklist的数据结构)。如果compress为0表示所有节点都不压缩,否则就表示从两端开始有多少个节点不压缩。以上图为例,压缩深度为1,也就是首尾两个节点不压缩,如果是2,则是首第1,2个和尾第1,2个节点不压缩。compress在quicklist创建的时候,默认是不压缩的。

具体可以根据业务实际场景进行配置。那么为什么不全部节点都压缩,而是流出compress这个口子来配置呢?其实可以预估知道,list两端的数据变更最频繁,像lpush,rpush,lpop,rpop等命令都是在两端操作,如果频繁压缩或解压缩会造成不必要的性能损耗。从这里可以看出redis其实并不是一味追求性能,它也在努力减少存储占用,在存储和性能之间做到平衡。
这里还有个fill字段,它的含义是每个quicklist的节点最大容量,不同的数值有不同的含义,默认是-2,当然也可以配置为其他数值,具体数值含义如下:
-1:每个quicklistNode节点的ziplist所占字节数不能超过4kb(建议配置)
-2:每个quicklistNode节点的ziplist所占字节数不能超过8kb(默认配置&建议配置)
-3:每个quicklistNode节点的ziplist所占字节数不能超过16kb
-4:每个quicklistNode节点的ziplist所占字节数不能超过32kb
-5:每个quicklistNode节点的ziplist所占字节数不能超过64kb
任意正数:表示ziplist结构所最多包涵的entry个数,最大个数要看操作系统的位数,如果是32位的操作系统,最多8191个,如果是64位的操作系统,最多32767个。
为了证明以上结论,我们查看一下数值在源码中的定义:
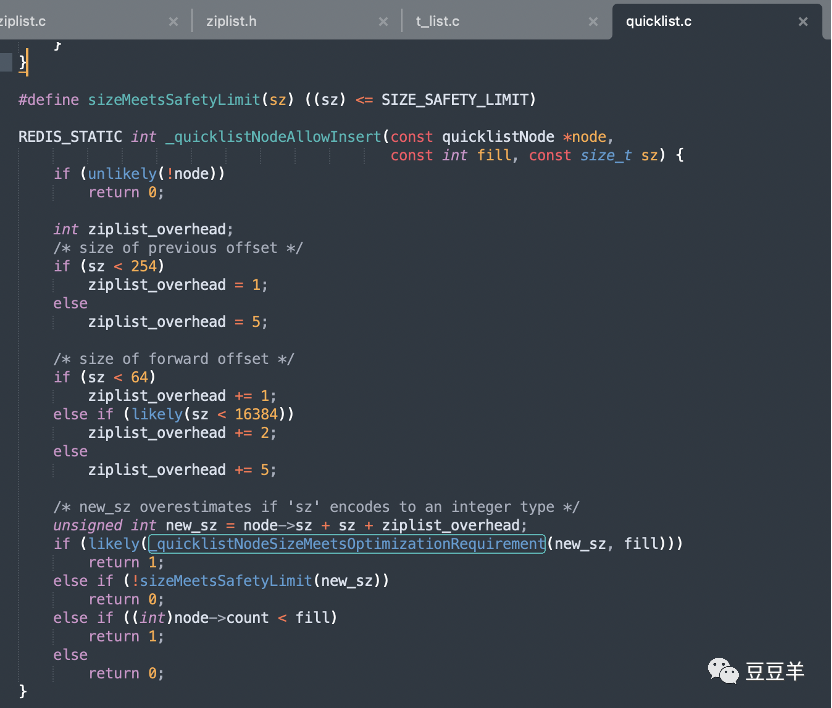


可以看到如果是负数则进行了阶梯映射,4096b=1024*4=4kb,同理,-1到-5对应着4kb,8kb,16kb,32kb和64kb。
再看一下最大上限的定义:
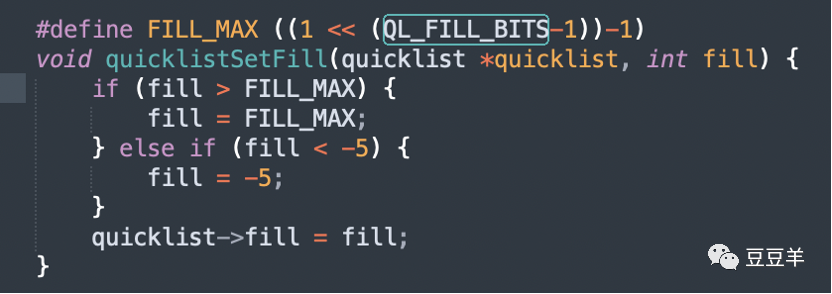
#if UINTPTR_MAX == 0xffffffff /* 32-bit */ # define QL_FILL_BITS 14 # define QL_COMP_BITS 14 # define QL_BM_BITS 4 #elif UINTPTR_MAX == 0xffffffffffffffff /* 64-bit */ # define QL_FILL_BITS 16 # define QL_COMP_BITS 16 # define QL_BM_BITS 4 * we can encode more, but we rather limit the user since they cause performance degradation. */ |
这里的逻辑是1左移动QL_FILL_BITS-1位,然后再减1,所以,如果是32位的操作系统,最多1《(14-1)-1=8191个,如果是64位的操作系统,最多1《(16-1)-1=32767个。关于最大压缩深度compress和bookmarks最大节点数bookmark_count,逻辑和fill一致,这里就不赘述了。
1.3.2. quicklistnode
quicklistNode就是双链表的节点封装了,除了前后节点的指针外,这里还包含一些本节点的其他信息。比如是否是LZF压缩的节点等等,看一下源码中的声明。
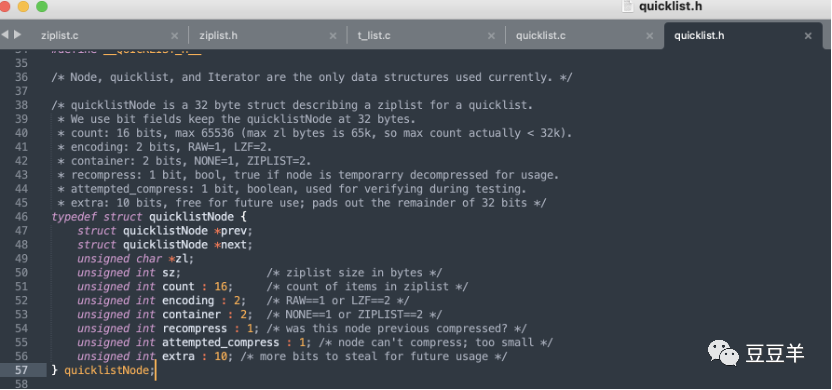
struct quicklistNode *prev; struct quicklistNode *next; unsigned char *zl; * quicklist节点对应的ziplist */ unsigned int sz; * ziplist的字节数 */ unsigned int count : 16; /* ziplist的item数*/ unsigned int encoding : 2; /* 数据类型,RAW==1 or LZF==2 */ unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */ unsigned int recompress : 1; /* 这个节点以前压缩过吗?*/ unsigned int attempted_compress : 1; * 节点太小,不能压缩*/ unsigned int extra : 10; /* 未使用到的10位 */ |
1.3.3. quicklist的操作
1.3.3.1. 创建
前面讲quicklist数据结构的时候已经深入探讨过,这里不赘述了。
1.3.3.2. 头插和尾插
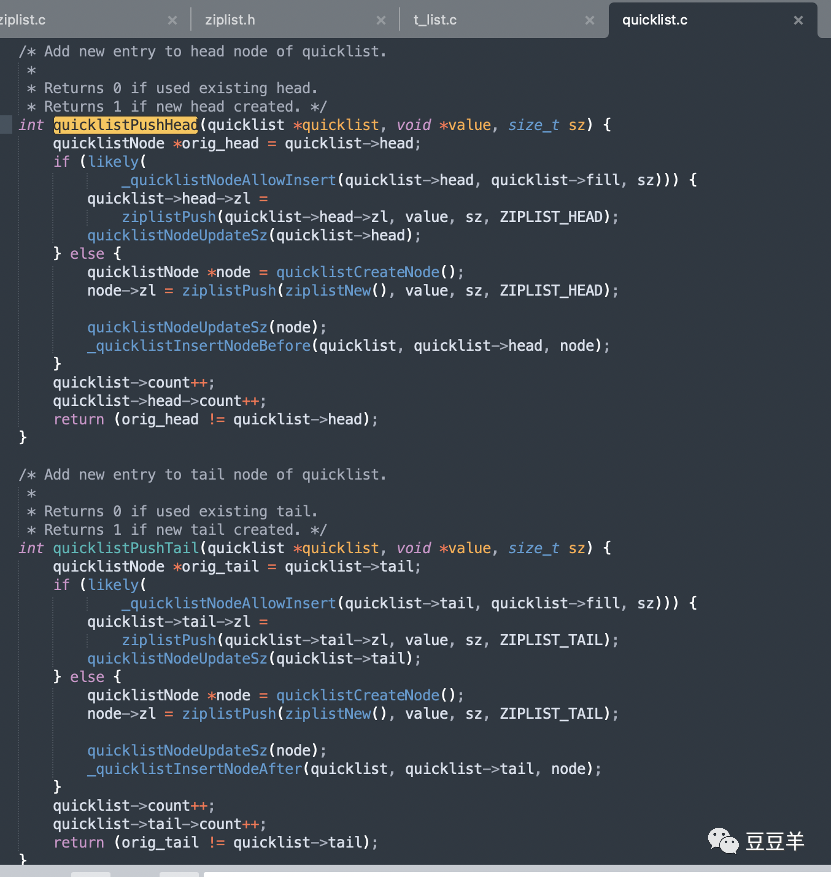
头插和尾插都调用了_quicklistNodeAllowInsert先判断了是否能直接在当前头|尾节点能插入,如果能就直接插入到对应的ziplist里,否则就需要新建一个新节点再操作了。还记得上文中我们说的fill字段吗,_quicklistNodeAllowInsert其实就是根据fill的具体值来判断是否已经超过最大容量。这一段的具体逻辑解释在前面有深入讲过,这里就不赘述了。
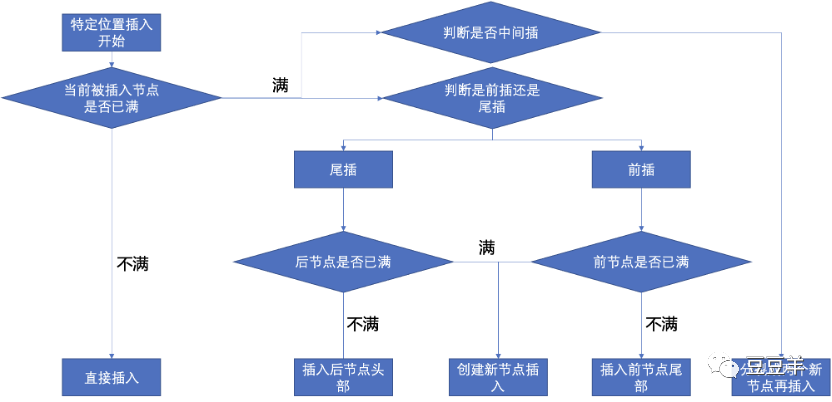
1.3.3.3. 特定位置插入
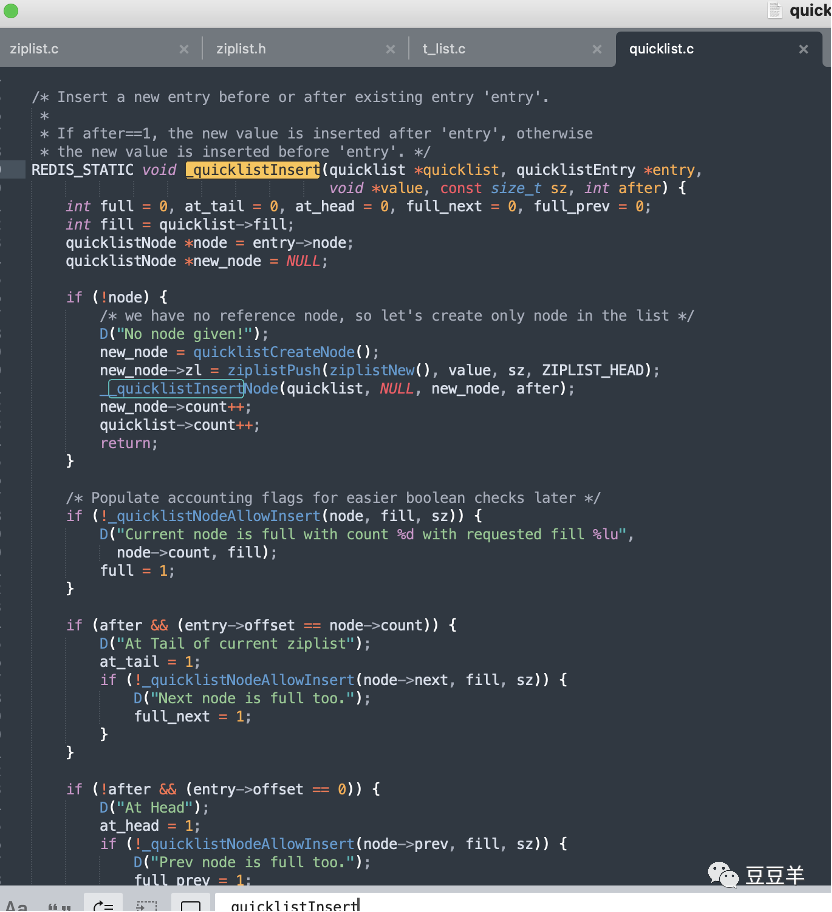
代码较长,总结一下:
1、如果当前被插入节点不满,直接插入。
2、如果当前被插入节点是满的,要插入的位置是当前节点的尾部,且后一个节点有空间,那就插到后一个节点的头部。
3、如果当前被插入节点是满的,要插入的位置是当前节点的头部,且前一个节点有空间,那就插到前一个节点的尾部。
4、如果当前被插入节点是满的,前后节点也都是满的,要插入的位置是当前节点的头部或者尾部,那就创建一个新的节点插进去。
5、否则,当前节点是满的,且要插入的位置在当前节点的中间位置,我们需要把当前节点分裂成两个新节点,然后再插入。
1.3.3.4. 删除
删除较简单,没有插入这么复杂,先删索引,再删节点,不存在什么合并操作。
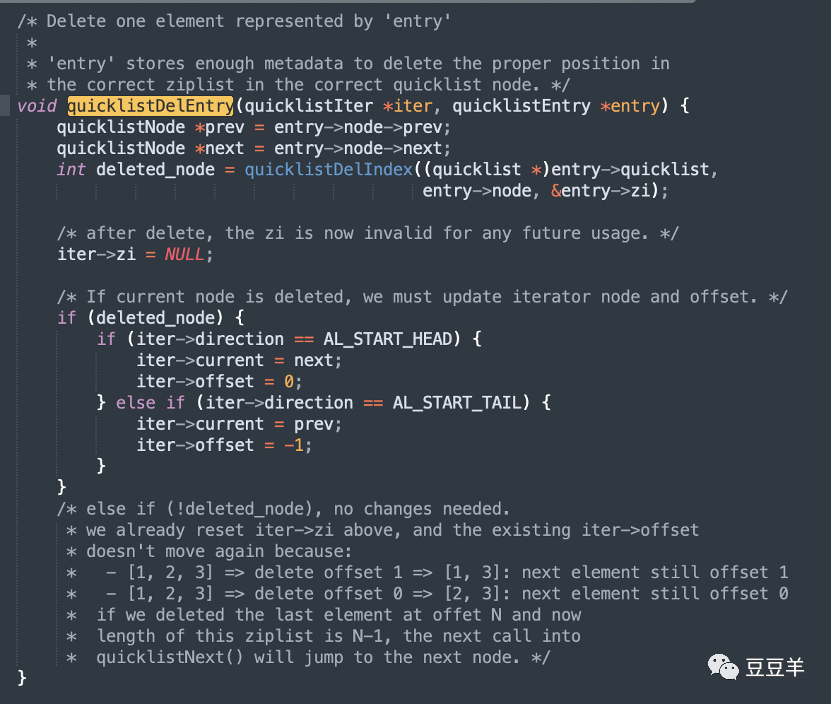

直接删除就完了,所以quicklist里只有最大容量限制,没有最小容量限制。
1.3.4. ziplist
压缩列表(ziplist)本质上就是一个字节数组,是redis为了节约内存而设计的一种线性数据结构,可以包含任意多个元素,每个元素可以是一个字节数组或一个整数。
Redis的有序集合、哈希以及列表都直接或间接使用了压缩列表。当有序集合或哈希的元素数目比较少,且元素都是短字符串时,redis便使用压缩列表作为其底层数据存储方式。列表使用快速链表数据结构存储,而快速链表就是双向链表与压缩列表的组合。
我们可以做一个测试。

以上图为例,可以看到我们构建的hash键它的存储值就是一个压缩列表。
1.3.4.1. 数据结构
Redis使用字节数组表示一个压缩列表,字节数组逻辑划分为多个字段。如图所示:

各字段含义如下:
1、zlbytes:压缩列表的字节长度,占4个字节,因此压缩列表最长(2^32)-1字节;
2、zlhead:压缩列表首元素相对于压缩列表起始地址的偏移量,占4个字节;
3、zltail:压缩列表尾元素相对于压缩列表起始地址的偏移量,占4个字节;
4、zllen:压缩列表的元素数目,占两个字节;那么当压缩列表的元素数目超过(2^16)-1怎么处理呢?此时通过zllen字段无法获得压缩列表的元素数目,必须遍历整个压缩列表才能获取到元素数目;
5、entryX:压缩列表存储的若干个元素,可以为字节数组或者整数;entry的编码结构后面详述;
6、zlend:压缩列表的结尾,占一个字节,恒为0xFF。
假设char * zl指向压缩列表首地址,Redis通过以下宏定义实现了压缩列表各个字段的操作存取:
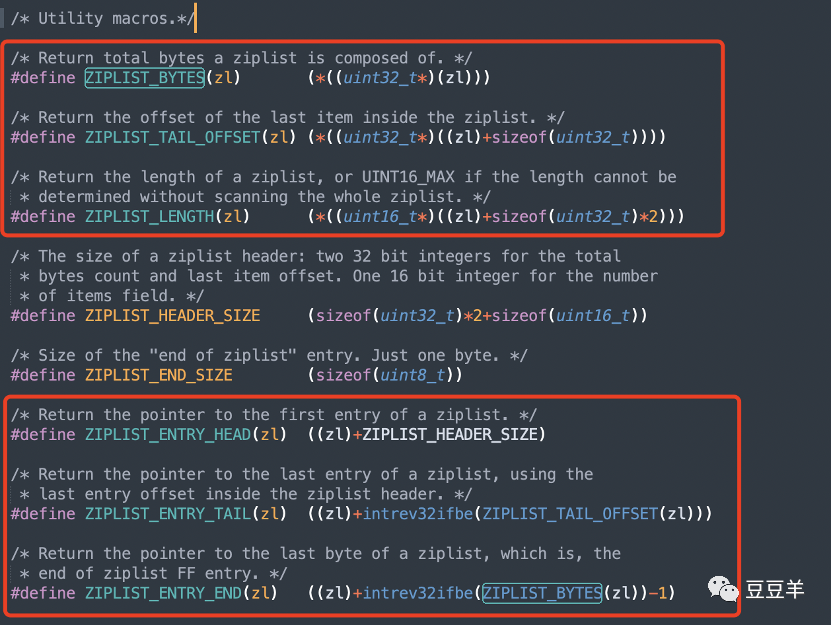
//zl指向zlbytes字段 #define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
//zl+4指向zltail字段 #define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
//zl+8指向zllen字段 #define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
//zl+ ZIPLIST_HEADER_SIZE指向首元素首地址; #define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE))
//zl+zltail指向尾元素首地址;intrev32ifbe使得数据存取统一按照小端法 #define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
//压缩列表最后一个字节即为zlend字段 #define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1) |
1.3.4.2. 结构体entry
上一节分析了压缩列表的底层存储结构。但是我们发现对于任意的压缩列表元素,获取前一个元素的长度,判断存储的数据类型,获取数据内容,都需要经过复杂的解码运算才行,那么解码后的结果应该被缓存起来,为此定义了结构体zlentry,用于表示解码后的压缩列表元素:
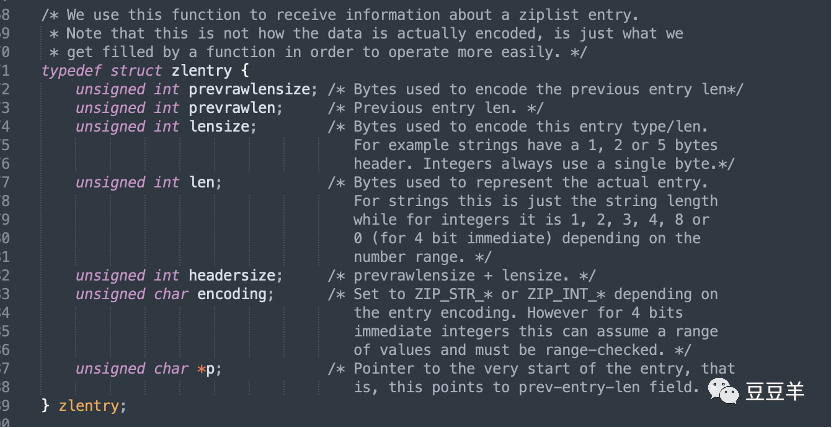
Entry数据结构如下图所示:

previous_entry_length:表示前一个元素的字节长度,占1个或者5个字节。当前一个元素的长度小于254(0X FE)时,使用一个字节表示,如果达到或超出254(0X FE)时,那就用5个字节表示,其中第一个字节是0X FE,剩余四个字节表示字符串长度。

encoding:表示当前元素的编码,即content字段存储的数据类型(整数或者字节数组),数据内容存储在content字段。
unsigned int prevrawlensize; /* previous_entry_length字段的长度*/ unsigned int prevrawlen; * previous_entry_length字段存储的内容*/ unsigned int lensize; /* encoding字段的长度*/ unsigned int len; /*数据内容长度*/ unsigned int headersize; /*当前元素的首部长度,即previous_entry_length字段长度与encoding字段长度之和*/ unsigned char encoding; /*数据类型*/ unsigned char *p; /*数据内容指针*/ |
1.3.4.3. 基本操作
1.3.4.3.1. 创建压缩列表
创建空的压缩列表,只需要分配初始存储空间(11=4+4+2+1个字节),并对zlbytes、zltail和zllen字段初始化即可。
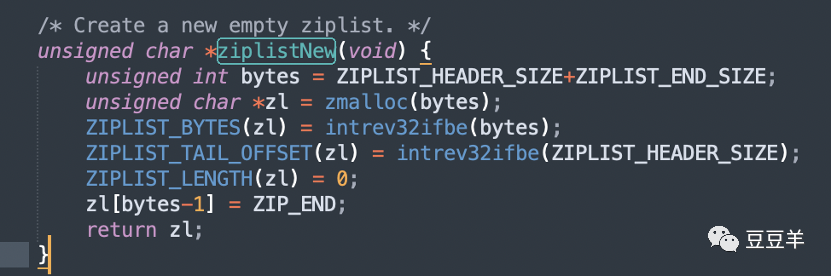
1.3.4.3.2. 插入元素
压缩列表插入元素,源码如下,由于太多,就先截取一部分。参数zl表示压缩列表首地址,p指向新元素的插入位置,s表示数据内容,slen表示数据长度,返回参数为压缩列表首地址。
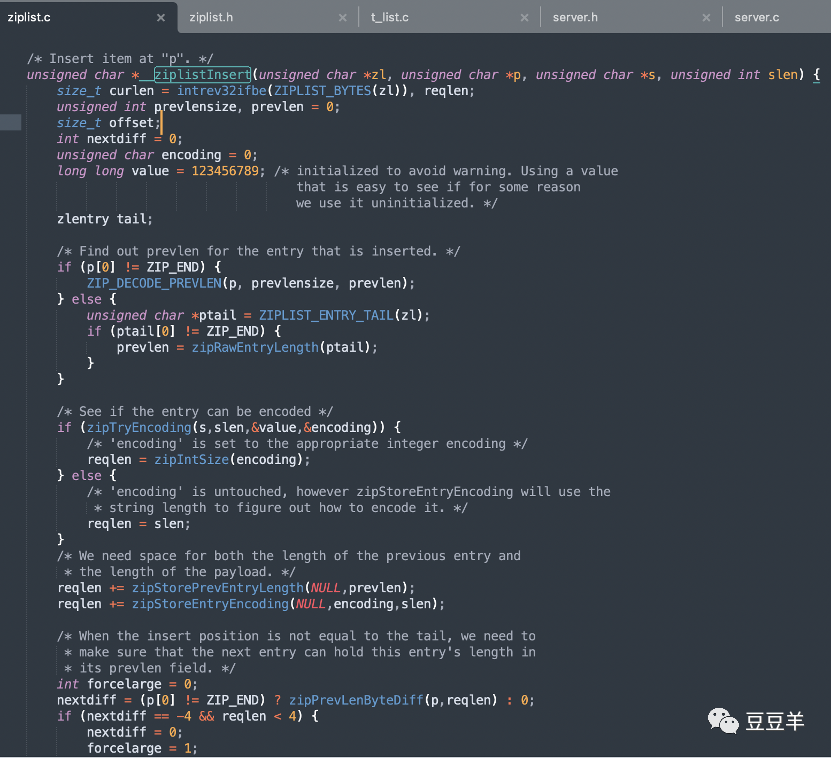
简要概括,插入元素时,可以分为三个步骤:
1、需要将元素内容编码为压缩列表的元素。
2、重新分配空间
3、拷贝数据
我们逐层分析一下每个步骤的实现逻辑。
1)编码
编码即计算previous_entry_length字段、encoding字段和content字段的内容。如何获取前一个元素的长度呢?这时候就需要根据插入元素的位置分情况讨论了,如图所示:
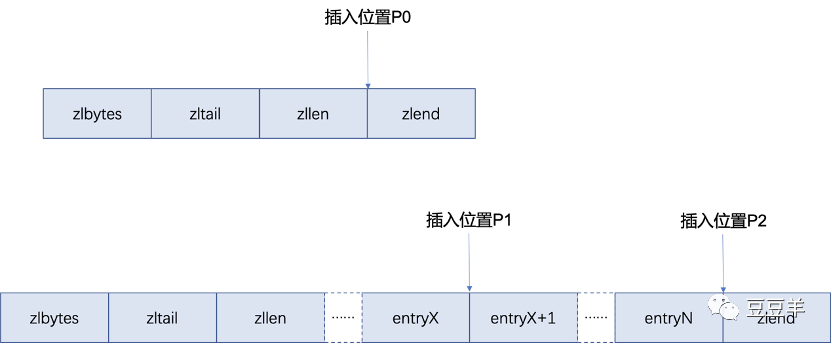
当压缩列表为空插入位置为P0时,此时不存在前一个元素,所以前一个元素的长度为0;
当插入位置为P1时,此时需要获取entry X元素的长度,而entry X+1元素的previous_entry_length字段存储的就是entry X元素的长度,比较容易获取;
当插入位置为P2时,此时需要获取entry N元素的长度,而entry N是压缩元素的尾元素,计算其元素长度需要将其三个字段prevlensize + lensize + len长度相加,这个前面讲过就不赘述了。
2)重新分配空间

由于新插入元素,压缩列表所需空间增大,因此需要重新分配存储空间。那么空间大小是否是添加元素前的压缩列表长度与新添加元素元素长度之和呢?并不完全是,如图中所示的例子。
插入元素前,entryX元素长度为128字节,entryX+1元素的previous_entry_length字段占1个字节;添加元素entryNEW元素,元素长度为1024字节,此时entryX+1元素的previous_entry_length字段需要占5个字节;即压缩列表的长度不仅仅是增加了1024字节,还有entryX+1元素扩展的4字节。我们很容易知道,entryX+1元素长度可能增加4字节,也可能减小4字节,也可能不变。而由于重新分配空间,新元素插入的位置指针P会失效,因此需要预先计算好指针P相对于压缩列表首地址的偏移量,待分配空间之后再偏移即可。
3)拷贝数据
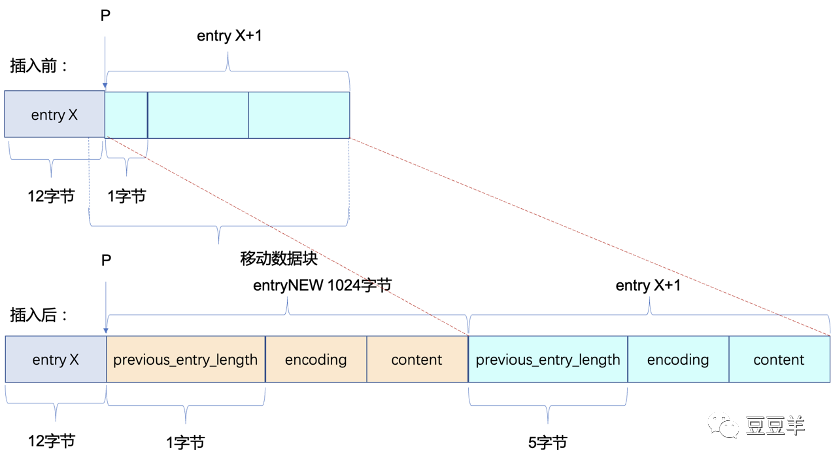
重新分配空间之后,需要将位置P后的元素移动到指定位置,将新元素插入到位置P。我们假设entryX+1元素的长度增加4(即nextdiff等于4),此时数据拷贝示意图如上图所示,位置P后的所有元素都需要移动,移动的偏移量是插入元素entryNew的长度,移动的数据块长度是位置P后所有元素长度之和再加上nextdiff的值,数据移动之后还需要更新entryX+1元素的previous_entry_length字段。
总结:
因为 ziplist 都是紧凑存储,没有冗余空间 (对比一下 Redis 的字符串结构)。意味着插入一个新的元素就需要调用 realloc 扩展内存。取决于内存分配器算法和当前的 ziplist 内存大小,realloc 可能会重新分配新的内存空间,并将之前的内容一次性拷贝到新的地址,也可能在原有的地址上进行扩展,这时就不需要进行旧内容的内存拷贝。
如果 ziplist 占据内存太大,重新分配内存和拷贝内存就会有很大的消耗。所以 ziplist 不适合存储大型字符串,存储的元素也不宜过多。
1.3.4.4. 级联更新
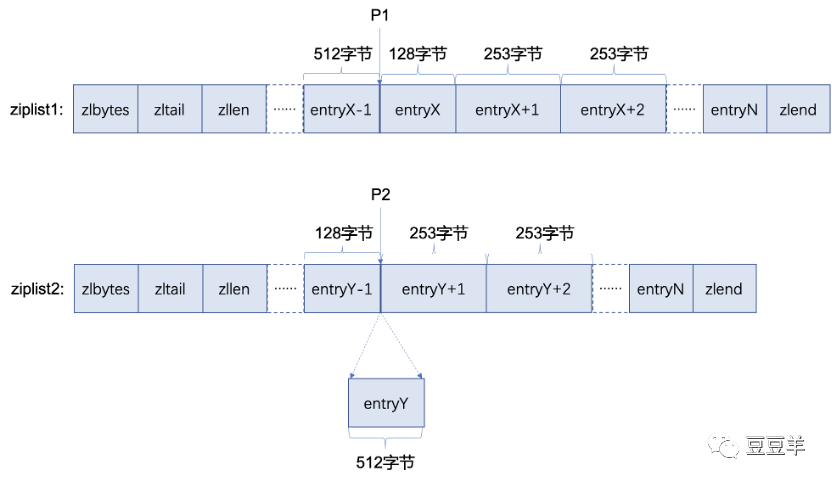
前面提到了一些插入和新增基本操作会带来很大的开销,这在ziplist内部有一个说法叫做级联更新,上面是我举的两个例子来说明一下这个机制,其中一个是删除压缩列表ziplist1位置P1的元素entry X,另一个是在压缩列表ziplist2位置P2插入元素entry Y。
压缩列表ziplist1,元素entry X之后的所有元素entry X+1,entry X+2等长度都是253字节,显然这些元素的previous_entry_length字段的长度都是1字节。当删除元素entry X时,元素entry X+1的前驱节点改为元素entry X-1,长度为512字节,此时元素entry X+1的previous_entry_length字段需要5字节才能存储元素entry X-1的长度,则元素entry X+1的长度需要扩展至257字节;而元素entry X+1长度的增加,元素entry X+2的previous_entry_length字段同样需要改变。以此类推,由于删除了元素entry X,之后的所有元素entry X+1,entry X+2等长度都必须扩展,而每次元素的扩展都将导致重新分配内存,效率是很低下的。压缩列表ziplist2,插入元素entry Y同样会产生上面的问题。
