




数据库添加索引确实是解决数据库访问性能的一个利器,但是索引并不是越多越好,如果索引过多,应用程序的性能可能会受到影响,如果索引过少,查询性能又可能产生影响。所以找寻这个平衡点,就是我们需要特别注意的点。
很多程序员总是在事后才考虑添加索引。可问题是,事后把这个职责丢给DBA,DBA对业务数据流的理解肯定不会比开发更了解,他们需要耗费大量的时间和精力,应用各种监控,从大量的SQL语句中进行查找,来定位问题。这本省就是一个ROI比较低的策略。光靠慢查日志监控,不能解决根本问题,研发在事后永远不会对业务有更好的感知。并且也不一定能解决所有问题,会有遗漏的情况出现。因此,还是要要求研发的同学在设计表的时候就应该对数据的量级,关键的查询字段和查询模式有自己对业务的认知。
以前在一本书中看到这么一个场景,一台mysql的服务器iostat显示磁盘使用率一直处于100%,经过分析发现是因为开发人员添加了太多的索引,在删除一些不必要的索引后,磁盘使用率立马降到了20%。可见索引的添加也不是无限制的。
一、索引成本
既然要分析索引的构建如何才能算是合理,那么首先要做的就是先要知道构建索引会产生哪些成本。成本不清楚是无法知道边界的。那么构建索引的成本主要来自于三个方面。
1、 维护成本
2、 空间成本
3、 回表成本
先来看看维护成本。只要创建索引,就需要创建对应的B+树,新增数据时要同时修改聚簇索引,如果有二级索引,还要修改二级索引。这些都是维护代价。我们可以做一个实验,来看创建索引的代价。
/*创建了一个只含主键索引的表*/
CREATE TABLE `person` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`score` int(11) NOT NULL,
`create_time` timestamp NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
通过以下存储过程插入10W条测试数据
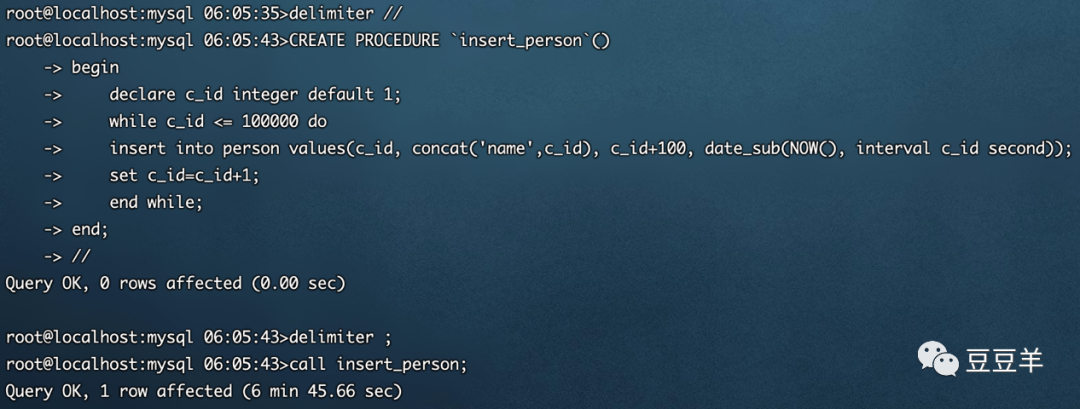
耗费了大约6分45秒。
/*删掉表,从新构建含两个索引的表,一个联合索引,一个单列索引*/
drop table person;
CREATE TABLE `person` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`score` int(11) NOT NULL,
`create_time` timestamp NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE INDEX `name_score` ON person(`name`,`score`)USING BTREE;
CREATE INDEX `create_time` ON person(`create_time`)USING BTREE;
重新调用存储过程,插入10W条测试数据

耗费时间提升到了大约6分55秒。在上一个文章《INNODB存储引擎和索引探秘》中我们知道,数据是以页的方式存储的,一页就是16K。现在新增记录就要往页中插入数据,现有的页满了就需要创建一个新的页,把现有页的部分数据转移过去,这就是页分裂。如果是删除了很多数据使得页比较空闲,那就还要进行页合并。页分裂和页合并都是有IO代价的,并且可能在操作中产生死锁。
我们可以看一下它插入10W条记录后,页分裂了多少出来。
初始化构建的时候

因为一页大小16K,16*1024=16384 B。所以初始化的时候总共是98304/6384=6(页)。
插入了10W条记录后,页大小发生了变化

22020096/16384=1344(页),页数扩大了224倍。
再来看空间成本,虽然二级索引不用保存原始数据,但是要保存索引列的数据,所以会占用更多的空间。

数据本身只占了4.7M,但是索引却占用了8.4M 。
最后来看一下回表成本,关于回表,在上一篇文章《INNODB存储引擎和索引探秘》中已经介绍了,我就不赘述了。主要是二级索引没有保存具体数据,只有找到主键后,再从聚簇索引中查找具体内容,如何免去回表是我们在设计时重点考虑的点。我们看一个例子。

从执行计划中可以看到这个sql用到了name_score索引,type表示访问方式,这里是 ref 说明是二级索引等值匹配。
如果我们把*改成name和score,再看一下执行计划

其他都跟*一样,但是extra不是null,而是using index,证明这次查询免去了回表,直接走的二级索引。为什么呢,其实我们可以再回顾一下《INNODB存储引擎和索引探秘》中介绍的二级索引的数据结构。
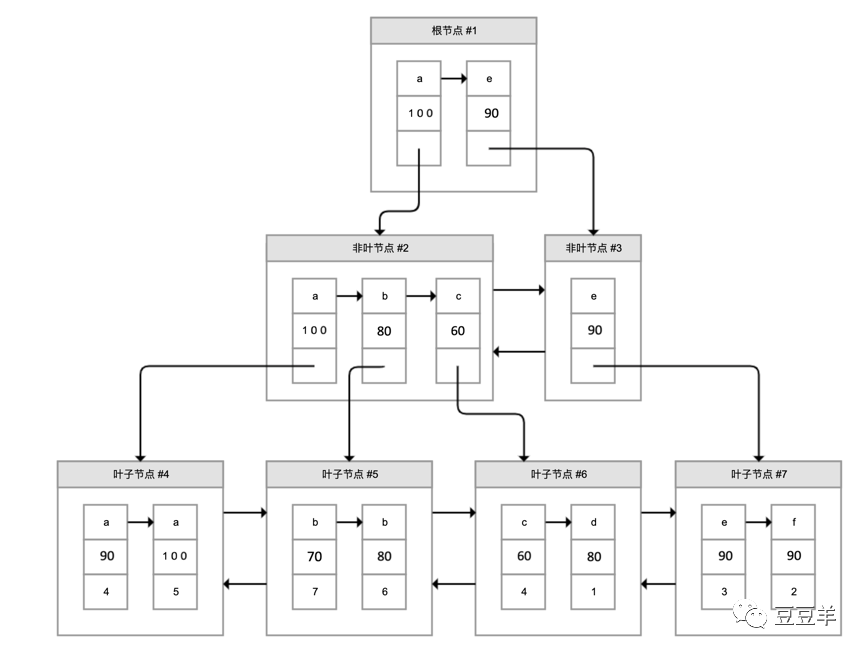
这个组合索引,按照构建语句的定义
CREATE INDEX `name_score` ON person(`name`,`score`)USING BTREE;
每个结点的第一个数据方块先按照name列的内容进行顺序记录,在name相同的时候,第二个数据方块顺序记录了score列的内容。很明显,name和score 在二级索引中都做了记录,因此 ,不需要再拿第三个数据方块记录的主键进行回表查询了。
总结一下索引开销: 1、 无需一开始就构建索引,等到数据量超过1W,查询变慢了,再针对需求,查询、排序或分组的字段来构建索引。 2、 尽量在轻量级的字段上构建索引,例如,能在int上构建索引,不要在varchar上构建。 3、 尽量不要在sql中使用select * ,而是select必要的字段。如果能针对查询字段做联合索引就更好了,能避免回表,降低IO开销。 |
二、索引生效问题
问题:是不是见了索引就一定能生效,到底是建联合索引还是独立索引好?
1、 索引只能匹配列前缀
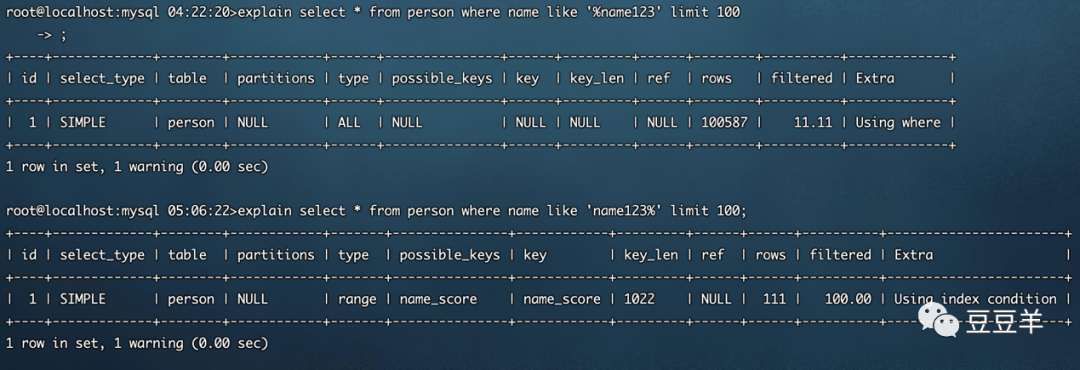
看一下这个like,模糊匹配在前面,则用不到索引,模糊匹配在后面,前缀是确定的,则能用到索引。这是为什么呢?
原因也很简单,索引B+树中数据按照索引值排序,只能根据前缀进行比较。
2、 条件涉及函数操作无法走索引

原因其实也和1是一样的,索引保存的是索引列的原始值,不是经过函数计算后的值,当然没法进行比较。
3、 联合索引只能匹配左边的列。

虽然对name和score建了联合索引,但是仅按照score列搜索无法走索引。原因也很简单,按照前面展现的联合索引的B+树的数据结构,它是先排序第一个列,再排序第二个列。我们不去查name,直接跳过它去找score,是不可能的。
如果我把搜索条件加入name列,让他强制先检索name,那么就能走name_score索引了。

这里需要注意的是,name检索放在score检索前面后面其实无所谓,因为通过查询优化器,都会转化为先按name进行检索。
总结一下: 1、 并不是建立了索引就一定能用的上,只有查询能符合索引的数据结构时,才能用上索引。 2、 如果搜索条件经常会针对多个字段进行检索,那么构建联合索引肯定是更好用的。毕竟能减少查询的次数,一个节点就能拿到需要检索的所有字段值。当然,也要正确的编写sql,做到字段顺序依赖才能保证用起来,如果出现字段跳跃式应用,或者缺失前序字段检索,那就算是构建了联合索引,还是用不起来的。例如:索引X构建顺序是A,B,C。结果where条件是A,C(C,A)【跳跃】,或者B,C(C,B)【前置缺失】,都是没办法用到这个索引X的。那么,如果搜索条件仅仅是针对某一个字段进行检索,那使用单列索引是比较合适的,因为毕竟联合索引还是会多处一部分不必要字段的存储开销。 |
三、数据库基于成本决定是否走索引
我们发现,其实有一些时候,即使数据库可以走索引,但是它偏偏没有走。这是为啥呢。
其实,MYSQL在查询数据之前,会先对可能的方案做执行计划,然后依据成本决定走那个执行计划。这里的成本,包括IO成本和CPU成本。
1、IO成本,是从磁盘把数据加载到内存的成本。默认情况下,读取数据页的IO成本常数是1
2、CPU成本,是检测数据是否满足条件和排序等CPU操作的成本。默认情况下,检测记录的成本是0.2
全表扫描,就是把聚簇索引中的记录依次和给定的搜索条件做比较,把符合搜索条件的记录加入结果集的过程。那么,要计算全表扫描的代价需要两个信息:
1、 聚簇索引占用的页面数,用来计算读取数据的IO成本
2、 表中的记录数,用来计算搜索的CPU成本
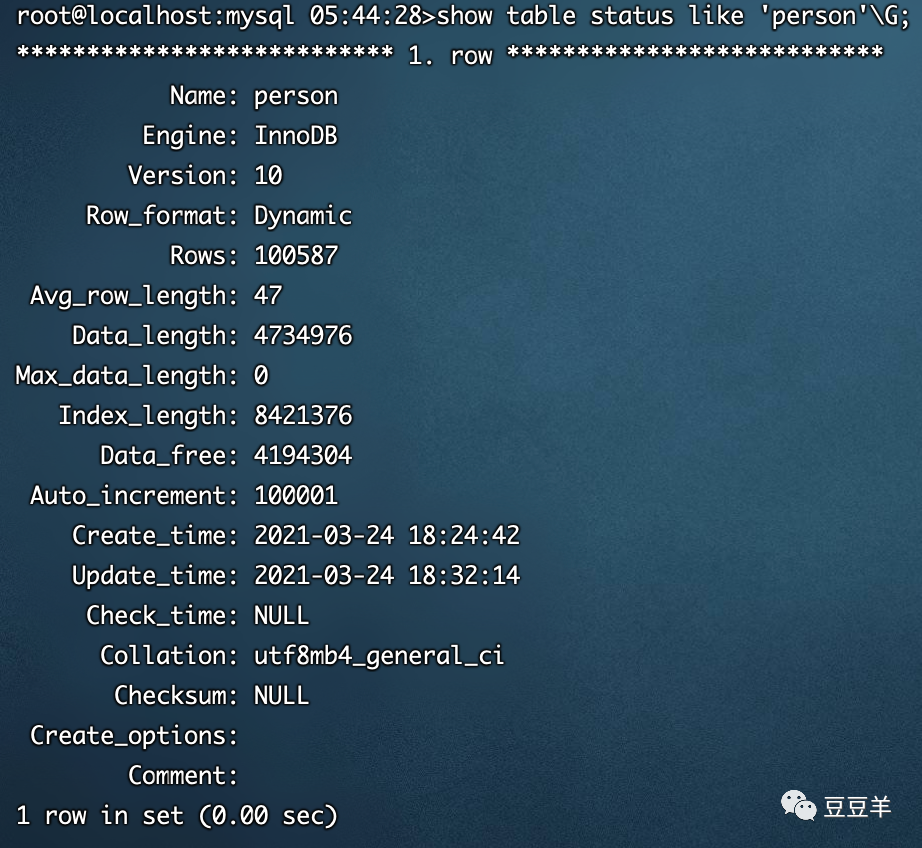
我们可以看到mysql其实已经维护了这些统计信息,并不是实时计算出来的。这里的Rows:100587是总行数。有同学可能会疑问,为什么不是10W整,这里涉及到mysql内部的一些算法,我们可以近似认为是OK的,不用太过纠结。
由此,我们可以得到CPU成本:100587*0.2=20117 |
Index_length: 4734976是聚簇索引所占用的空间,聚簇索引占用的空间/每个页面的大小=聚簇索引页面数量,4734976/16384=289(页)。
由此,我们可以得到IO成本:289*1=289 |
因此,全表扫描的总成本就等于20117+289=20406
OK,知道了成本如何计算,我们来看一下下面这个例子:
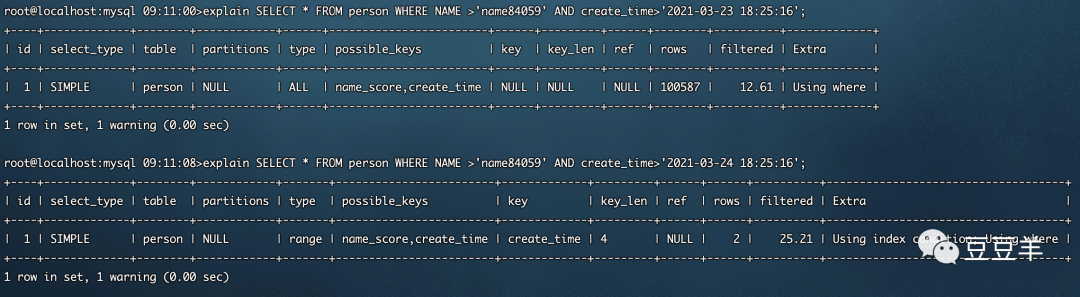
同样的查询列,name列在我的联合索引 name_score申明内,且是第一个列,create_time在我的二级索引create_time申明中。为啥仅仅是查询时间的不一样,而导致一个用到了索引,一个没有用到索引。
我们查看一下这个create_time到底是怎么存的。
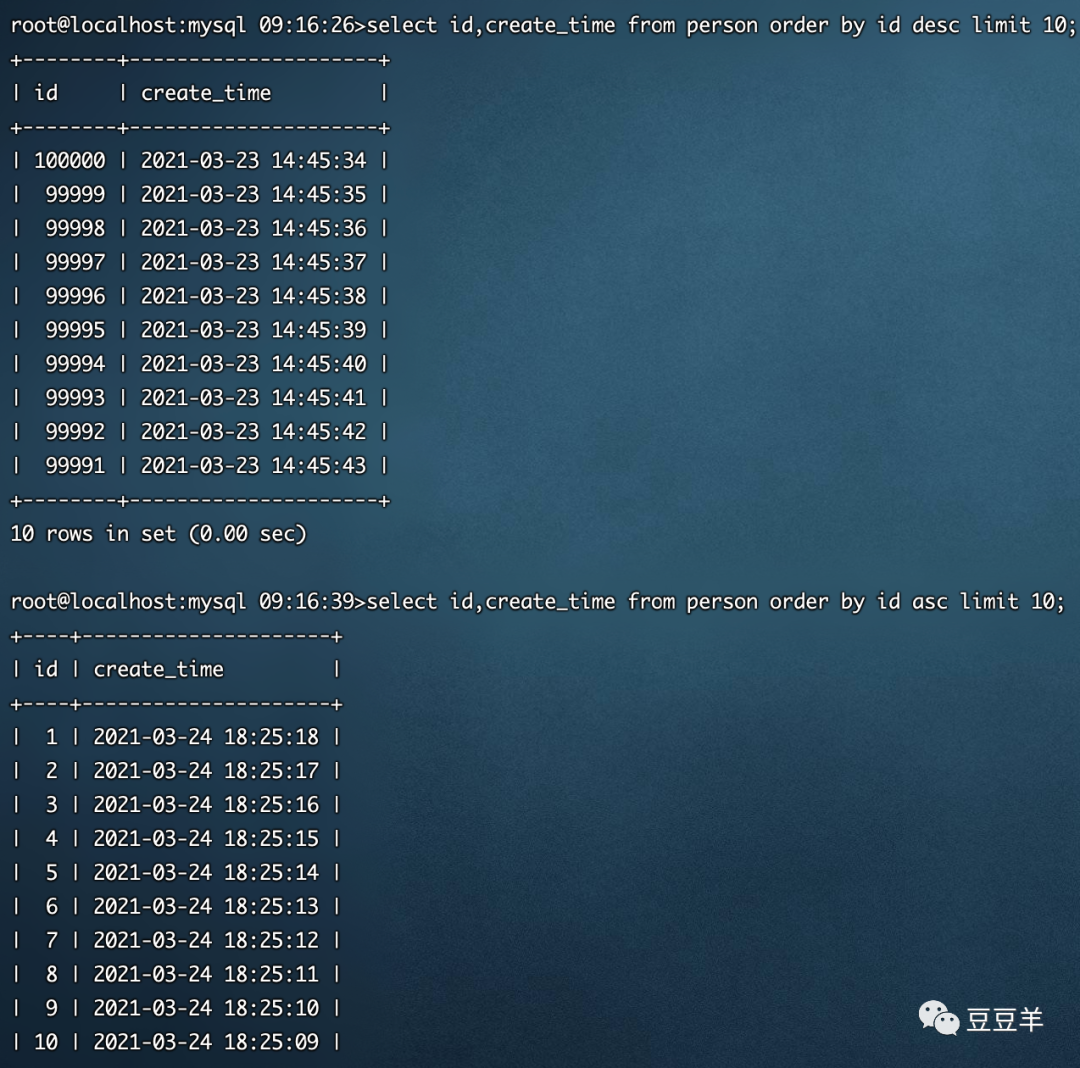
从这里可以看到是从id为1开始,创建时间取2021-03-24 18:25:18 。ID每+1,创建时间减少1秒。
这说明什么问题?如果我用第一个查询条件,create_time>'2021-03-23 18:25:16',那我可能要筛选80%的结果,这个成本跟全表扫没啥区别。如果用第二查询条件,create_time>'2021-03-24 18:25:16',那其实只需要扫3行出来就OK了,明显索引的成本更低。
真实情况是不是这样的呢?我们开启一下mysql的optimizer_trace来跟踪一下优化器的执行过程。
1、先开启追踪
root@localhost:mysql 06:22:04>set optimizer_trace="enabled=on";
2、再执行要监测的SQL
oot@localhost:mysql 06:22:05>SELECT * FROM person WHERE NAME >'name84059' AND create_time>'2021-03-23 18:25:16';
3、再查一下追踪器看结果
root@localhost:mysql 06:15:39>select * from information_schema.optimizer_trace\G;
因为返回结果太长,我截取最重要的点来分析。
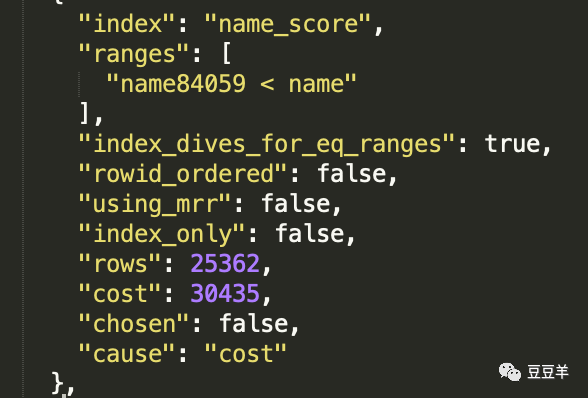
这个是走name_score索引的成本分析,扫描行数25362,成本是30435。这个cost就是将IO成本和CPU成本加在一起得出来的。
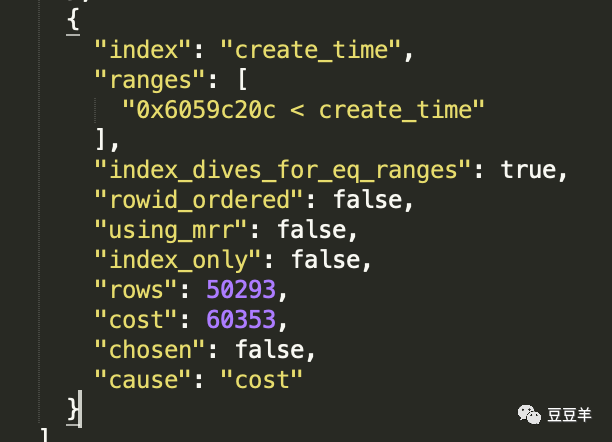
这里是走create_time索引的开销,扫描行数5W,但是成本是60353。我们刚才计算出来走全表扫描用到的成本是20406,因此无论是走name_score索引的30435,还是走明显走create_time索引的60353,全表扫描成本会更低。那最终MYSQL是不是选择走全表扫描的呢。继续往下看
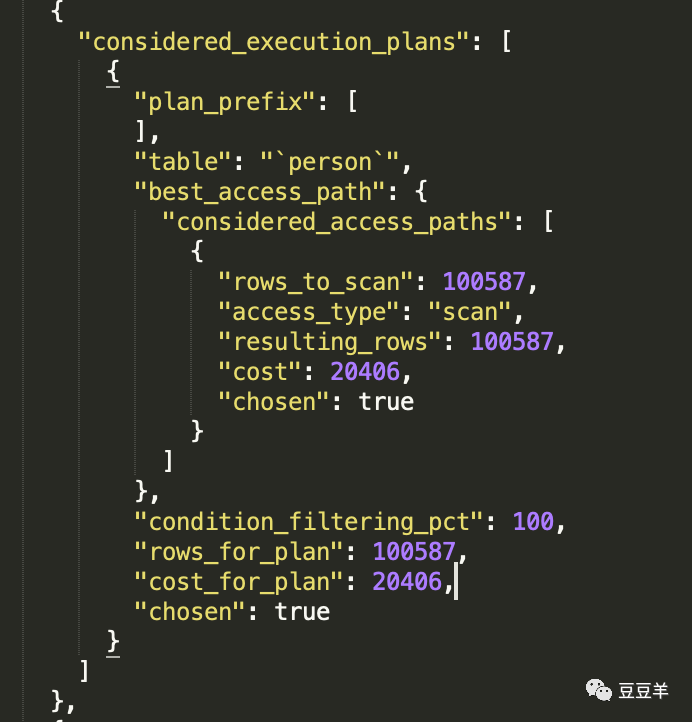
可以看到最终还是选择了走全表扫描做为执行计划,扫描100587行,开销是20406,跟我们刚才用公式计算出来的结果一致。
同理,如果我们把create_time的条件改成了create_time>'2021-03-24 18:25:16'
再进行一次追踪,我们发现。
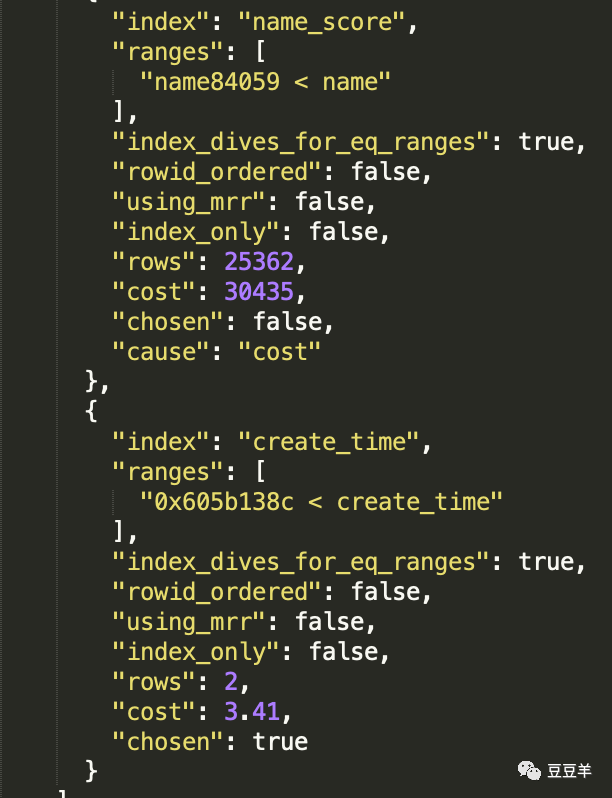
看到了吧,create_time索引的开销变成了3.41,扫描行是2 。非常nice。
再看最终的执行计划是怎么选择的。
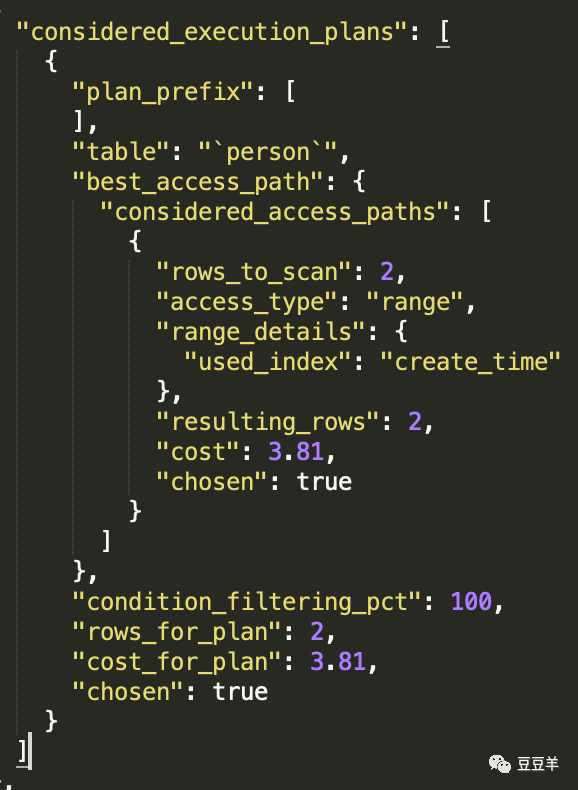
OK了。非常正确的选择。仅使用了二级索引 create_time。
总结: 1、 构建索引的时候需要考虑到索引的维护代价,空间代价和回表代价。不能认为索引越多越好。 2、 不能认为建了索引就一定有用。要根据索引数据结构,表查询是否发生数据偏移,以及通过各种成本分析来评判是走全表划算还是走索引划算。 |
